
Rumah >Peranti teknologi >AI >Kertas Cemerlang ICRA 2022: Menukar imej 2D pemanduan autonomi kepada pandangan mata, ketepatan pengecaman model meningkat sebanyak 15%
Kertas Cemerlang ICRA 2022: Menukar imej 2D pemanduan autonomi kepada pandangan mata, ketepatan pengecaman model meningkat sebanyak 15%

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-04-09 19:51:141242semak imbas
Banyak tugas dalam pemanduan autonomi lebih mudah dilakukan dari perspektif atas ke bawah, peta atau pandangan mata burung (BEV). Memandangkan banyak topik pemanduan autonomi dihadkan kepada satah darat, paparan atas ialah perwakilan dimensi rendah yang lebih praktikal dan sesuai untuk navigasi, menangkap halangan dan bahaya yang berkaitan. Untuk senario seperti pemanduan autonomi, peta BEV yang dibahagikan secara semantik mesti dijana sebagai anggaran serta-merta untuk mengendalikan objek bergerak bebas dan pemandangan yang dilawati sekali sahaja.
Untuk membuat kesimpulan peta BEV daripada imej, seseorang perlu menentukan kesesuaian antara elemen imej dan kedudukannya dalam persekitaran. Sesetengah penyelidikan terdahulu menggunakan peta kedalaman padat dan peta pembahagian imej untuk membimbing proses penukaran ini, dan penyelidikan lain melanjutkan kaedah menghurai kedalaman dan semantik secara tersirat. Sesetengah kajian mengeksploitasi prior geometri kamera tetapi tidak mempelajari secara eksplisit interaksi antara elemen imej dan satah BEV.
Dalam kertas kerja baru-baru ini, penyelidik dari Universiti Surrey memperkenalkan mekanisme perhatian untuk menukar imej 2D pemanduan autonomi kepada pandangan mata burung, meningkatkan ketepatan pengecaman model 15%. Penyelidikan ini memenangi Anugerah Kertas Cemerlang pada persidangan ICRA 2022 yang berakhir tidak lama dahulu.

Pautan kertas: https://arxiv.org/pdf/2110.00966.pdf

Berbeza daripada kaedah sebelumnya, kajian ini menganggap penukaran BEV sebagai masalah penukaran "Imej-ke-Dunia" , yang matlamatnya adalah untuk mempelajari penjajaran antara garis imbasan menegak dalam imej dan sinar kutub dalam BEV. Oleh itu, geometri unjuran ini tersirat kepada rangkaian.
Dalam model penjajaran, penyelidik menggunakan Transformer, struktur ramalan jujukan berasaskan perhatian . Dengan memanfaatkan mekanisme perhatian mereka, kami secara eksplisit memodelkan interaksi berpasangan antara garis imbasan menegak dalam imej dan unjuran BEV polar mereka. Transformer sangat sesuai untuk masalah terjemahan imej-ke-BEV kerana mereka boleh membuat alasan tentang saling bergantung antara objek, kedalaman dan pencahayaan pemandangan untuk mencapai perwakilan yang konsisten secara global.
Para penyelidik membenamkan model penjajaran berasaskan Transformer ke dalam formula pembelajaran hujung ke hujung yang mengambil imej monokular dan matriks intrinsiknya sebagai input, dan kemudian Ramalkan pemetaan BEV semantik bagi kelas statik dan dinamik.
Kertas kerja ini membina seni bina yang membantu meramalkan peta BEV semantik daripada imej monokular di sekeliling model penjajaran. Seperti yang ditunjukkan dalam Rajah 1 di bawah, ia mengandungi tiga komponen utama: tulang belakang CNN standard untuk mengekstrak ciri spatial pada satah imej sebuah Transformer pengekod-penyahkod untuk menukar ciri pada satah imej kepada BEV dan akhirnya rangkaian segmentasi Decode ciri BEV; ke dalam peta semantik.
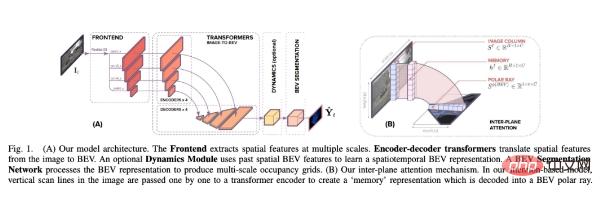

Secara khusus, sumbangan utama kajian ini ialah:
- (1) Hasilkan imej BEV daripada imej menggunakan set penukaran jujukan jujukan 1D
- (2) Bina subjek Data terhad yang cekap; Rangkaian pengubah dengan kesedaran spatial;
- Gabungan (3) formula dan perhatian monoton dalam bidang bahasa menunjukkan bahawa untuk pemetaan yang tepat, mengetahui apa yang berada di bawah titik adalah lebih penting daripada mengetahui apa yang ada di atasnya, walaupun menggunakan kedua-duanya akan menghasilkan prestasi yang terbaik; -hasil seni pada tiga set data berskala besar.
- Hasil eksperimen
Eksperimen Ablasi
Seperti yang ditunjukkan dalam bahagian pertama Jadual 2 di bawah, penyelidik membandingkan perhatian lembut (melihat kedua-dua arah), perhatian monotonik melihat ke belakang di bahagian bawah imej (memandang ke bawah), perhatian monotonik melihat kembali ke bahagian atas imej (menoleh ke atas).
Ternyata melihat ke bawah dari satu titik dalam imej adalah lebih baik daripada melihat ke atas.Sepanjang isyarat tekstur tempatan - ini konsisten dengan cara manusia cuba menentukan jarak objek dalam persekitaran bandar, menggunakan jarak objek dari persimpangan satah tanah lokasi. Keputusan juga menunjukkan bahawa pemerhatian dalam kedua-dua arah meningkatkan lagi ketepatan, menjadikan inferens dalam lebih diskriminatif.

Penukaran imej-ke-BEV di sini dilakukan sebagai satu set penukaran jujukan-ke-jujukan 1D, jadi satu persoalan ialah apa yang berlaku apabila keseluruhan imej ditukar kepada BEV. Pendekatan ini sangat mahal memandangkan masa pengiraan sekunder dan memori yang diperlukan untuk menjana peta perhatian. Walau bagaimanapun, faedah kontekstual menggunakan keseluruhan imej boleh dianggarkan dengan menggunakan perhatian paksi mendatar pada ciri satah imej. Dengan perhatian paksi melalui garis imej, piksel dalam garis imbasan menegak kini mempunyai konteks mendatar jarak jauh, dan kemudian konteks menegak jarak jauh disediakan dengan beralih antara jujukan 1D seperti sebelumnya. Seperti yang ditunjukkan di bahagian tengah Jadual 2,
penggabungan konteks tahap jujukan panjang tidak memberi manfaat kepada modelmalah mempunyai sedikit kesan buruk kesan. Ini menggambarkan dua perkara: pertama, setiap sinar yang diubah tidak memerlukan maklumat tentang lebar keseluruhan imej input, atau sebaliknya, konteks jujukan panjang tidak memberikan sebarang maklumat tambahan berbanding dengan konteks yang telah diagregatkan oleh belitan bahagian hadapan . Ini menunjukkan bahawa menggunakan keseluruhan imej untuk melakukan transformasi tidak akan meningkatkan ketepatan model melebihi formula kekangan garis dasar di samping itu, kemerosotan prestasi yang disebabkan oleh pengenalan perhatian paksi mendatar bermakna kesukaran menggunakan perhatian untuk melatih jujukan lebar imej; seperti yang dapat dilihat, Ia akan menjadi lebih sukar untuk melatih menggunakan keseluruhan imej sebagai urutan input.
Polar-agnostik vs polar-adaptive Transformers: Jadual 2 Bahagian terakhir membandingkan Po-Ag lwn. Po -Variasi Iklan. Model Po-Ag tidak mempunyai maklumat kedudukan polarisasi, Po-Ad bagi satah imej termasuk pengekodan kutub yang ditambahkan pada pengekod Transformer, dan untuk satah BEV, maklumat ini ditambahkan pada penyahkod. Menambah pengekodan kutub pada mana-mana satah adalah lebih berfaedah daripada menambahkannya pada model agnostik, dengan kelas dinamik menambah paling banyak. Menambahnya pada kedua-dua pesawat akan menguatkuasakan lagi perkara ini, tetapi mempunyai kesan yang paling besar pada kelas statik. Perbandingan dengan kaedah SOTA
Para penyelidik membandingkan kaedah ini dengan beberapa kaedah SOTA.
Seperti yang ditunjukkan dalam Jadual 1 di bawah, prestasi model spatial adalah lebih baik daripada kaedah SOTA termampat semasa STA-S, dengan purata peningkatan relatif sebanyak 15%. Pada kelas dinamik yang lebih kecil, peningkatan adalah lebih ketara, dengan ketepatan pengesanan bas, trak, treler dan halangan semuanya meningkat secara relatif 35-45%. Keputusan kualitatif yang diperolehi dalam Rajah 2 di bawah juga menyokong kesimpulan ini Model dalam kertas kerja ini menunjukkan persamaan struktur yang lebih besar dan deria bentuk yang lebih baik. Perbezaan ini boleh dikaitkan sebahagiannya kepada lapisan bersambung sepenuhnya (FCL) yang digunakan untuk pemampatan: apabila mengesan objek kecil dan jauh, kebanyakan imej adalah konteks berlebihan. Selain itu, pejalan kaki dan objek lain sering sebahagiannya dihalang oleh kenderaan. Dalam kes ini, lapisan yang bersambung sepenuhnya akan cenderung untuk mengabaikan pejalan kaki dan sebaliknya mengekalkan semantik kenderaan. Di sini, kaedah perhatian menunjukkan kelebihannya kerana setiap kedalaman jejari boleh diperhatikan secara bebas daripada imej - supaya kedalaman yang lebih dalam dapat menjadikan badan pejalan kaki kelihatan, manakala kedalaman sebelumnya hanya dapat melihat kenderaan. Keputusan pada dataset Argoverse dalam Jadual 3 di bawah menunjukkan corak yang sama, di mana kaedah kami bertambah baik sebanyak 30% berbanding PON [8]. Seperti yang ditunjukkan dalam Jadual 4 di bawah, kaedah kami berprestasi lebih baik daripada LSS [9] dan FIERY [20] pada nuScenes dan Lyft. Perbandingan sebenar adalah mustahil di Lyft kerana ia tidak mempunyai pemisahan kereta api/val berkanun, dan tiada cara untuk mendapatkan pemisahan digunakan oleh LSS. Untuk butiran penyelidikan lanjut, sila rujuk kertas asal. 



Atas ialah kandungan terperinci Kertas Cemerlang ICRA 2022: Menukar imej 2D pemanduan autonomi kepada pandangan mata, ketepatan pengecaman model meningkat sebanyak 15%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Pemantauan AI adalah yang paling ketat! Piala Dunia Qatar menggunakan 22,000 mata elektronik untuk mengesan peminat yang membuat masalah dengan tepat
- Apakah sebenarnya maksud ChatGPT untuk perusahaan?
- Apa dan mengapa analisis carian pemprosesan bahasa semula jadi dan bagaimana ia boleh membantu perniagaan anda
- Lapan teknologi digital baharu yang mengubah operasi rantaian bekalan
- Pengembangan teknologi aplikasi TensorFlow—pengkelasan imej