
Rumah >Peranti teknologi >AI >Tan Zhongyi: Daripada Model-Centric kepada Data-Centric MLOps membantu AI dilaksanakan dengan lebih pantas, lebih kos efektif
Tan Zhongyi: Daripada Model-Centric kepada Data-Centric MLOps membantu AI dilaksanakan dengan lebih pantas, lebih kos efektif

- PHPzke hadapan
- 2023-04-09 19:51:111493semak imbas
Tetamu: Tan Zhongyi
Disusun oleh: Qianshan
Enda Ng telah banyak kali menyatakan bahawa AI telah berubah daripada paradigma penyelidikan berpusatkan model kepada paradigma penyelidikan berpusatkan data , data adalah cabaran terbesar untuk pelaksanaan AI. Cara memastikan bekalan data yang berkualiti tinggi ialah isu utama Untuk menyelesaikan masalah ini, kita perlu menggunakan amalan dan alatan MLOps untuk membantu AI melaksanakan dengan cepat, mudah dan kos efektif.
Baru-baru ini, di Persidangan Teknologi Kecerdasan Buatan Global AISummit yang dihoskan oleh 51CTO, Tan Zhongyi, Naib Pengerusi TOC Yayasan Atom Terbuka, memberikan ucaptama "Dari Model -Centric to Data-Centric - MLOps membantu AI melaksanakan dengan lebih pantas, lebih menjimatkan kos", dan menumpukan pada perkongsian dengan peserta definisi MLOps, masalah yang boleh diselesaikan oleh MLOps, projek MLOps biasa dan cara menilai keupayaan dan tahap MLOps. pasukan AI.
Kandungan ucapan kini disusun seperti berikut, dengan harapan dapat memberi inspirasi kepada anda.
Daripada Model-Centric kepada Data-Centric
Pada masa ini, terdapat trend dalam industri AI - "daripada Model-Centric kepada Data-Centric". Apa sebenarnya maksudnya? Mari kita mulakan dengan beberapa analisis dari sains dan industri.
- Saintis AI Andrew NG menganalisis bahawa kunci kepada pelaksanaan AI semasa ialah cara untuk meningkatkan kualiti data.
- Jurutera dan penganalisis industri telah melaporkan bahawa projek AI sering gagal. Sebab-sebab kegagalan patut diterokai lebih lanjut.
Andrew Ng pernah berkongsi ucapannya "MLOps: From Model-centric to Data-centric", yang menyebabkan kesan hebat di Silicon Valley. Dalam ucapannya, beliau percaya bahawa "AI = Kod + Data" (di mana Kod termasuk model dan algoritma), dan menambah baik sistem AI dengan menambah baik Data dan bukannya Kod.
Secara khusus, kaedah Model-Centric digunakan, yang bermaksud memastikan data tidak berubah dan sentiasa melaraskan algoritma model, seperti menggunakan lebih banyak lapisan rangkaian, lebih banyak pelarasan hiperparameter, dsb. dan menggunakan kaedah Data-Centric , iaitu, memastikan model tidak berubah dan meningkatkan kualiti data, seperti menambah baik label data, meningkatkan kualiti anotasi data, dsb.
Untuk masalah AI yang sama, kesannya adalah berbeza sama ada menambah baik kod atau menambah baik data.
Bukti empirikal menunjukkan bahawa ketepatan boleh dipertingkatkan dengan berkesan melalui pendekatan Data-centric, tetapi sejauh mana ketepatan boleh dipertingkatkan dengan menambah baik atau menggantikan model adalah amat terhad. Sebagai contoh, dalam tugas pengesanan kecacatan plat keluli berikut, kadar ketepatan garis dasar ialah 76.2%. Selepas pelbagai operasi menukar model dan melaraskan parameter, kadar ketepatan hampir tidak bertambah baik. Walau bagaimanapun, pengoptimuman set data meningkatkan ketepatan sebanyak 16.9%. Pengalaman projek lain juga membuktikannya.
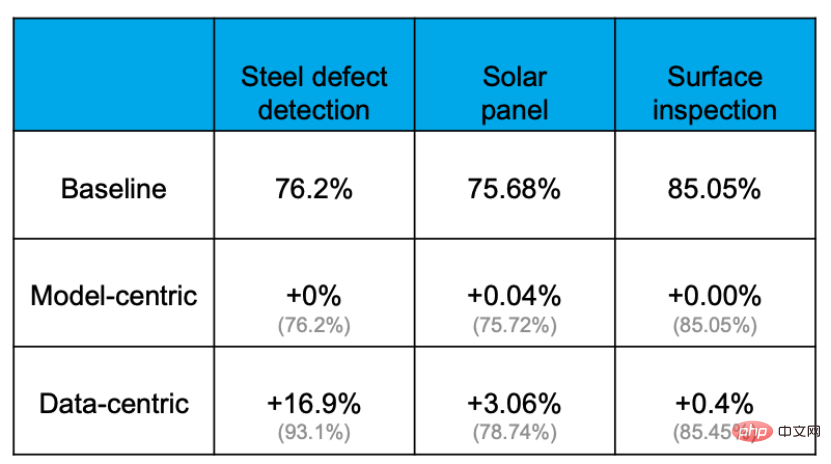
Sebab mengapa ini berlaku adalah kerana data lebih penting daripada yang dibayangkan. Semua orang tahu bahawa "Data adalah Makanan untuk AI". Dalam aplikasi AI sebenar, kira-kira 80% masa digunakan untuk memproses kandungan berkaitan data, dan baki 20% digunakan untuk melaraskan algoritma. Proses ini seperti memasak. 80% masa dihabiskan untuk menyediakan bahan, memproses dan menyesuaikan pelbagai bahan, tetapi memasak sebenar mungkin hanya mengambil masa beberapa minit apabila tukang masak memasukkan periuk ke dalam periuk. Boleh dikatakan bahawa kunci untuk menentukan sama ada hidangan itu lazat terletak pada ramuan dan pemprosesannya.
Pada pandangan Ng, tugas paling penting MLOps (iaitu “Kejuruteraan pembelajaran mesin untuk Pengeluaran”) adalah pada semua peringkat kitaran hayat pembelajaran mesin, termasuk penyediaan data, latihan model, model dalam talian dan pembangunan model . Bekalan data berkualiti tinggi sentiasa dikekalkan semasa pelbagai peringkat seperti pemantauan dan latihan semula.
Perkara di atas ialah pengetahuan saintis AI tentang MLOps. Seterusnya, mari kita lihat beberapa pandangan daripada jurutera AI dan penganalisis industri.
Pertama sekali, dari perspektif penganalisis industri, kadar kegagalan semasa projek AI adalah sangat tinggi. Tinjauan oleh Penyelidikan Dimensi pada Mei 2019 mendapati bahawa 78% projek AI akhirnya tidak masuk dalam talian pada Jun 2019, laporan VentureBeat mendapati bahawa 87% projek AI tidak digunakan dalam persekitaran pengeluaran. Dalam erti kata lain, walaupun saintis AI dan jurutera AI telah melakukan banyak kerja, mereka akhirnya tidak menjana nilai perniagaan.
Mengapakah keputusan ini berlaku? Makalah "Hutang Teknikal Tersembunyi dalam Sistem Pembelajaran Mesin" yang diterbitkan di NIPS pada tahun 2015 menyebut bahawa sistem AI dalam talian sebenar termasuk pengumpulan data, pengesahan, pengurusan sumber, pengekstrakan ciri, pengurusan proses, pemantauan dan banyak kandungan lain . Tetapi kod yang sebenarnya berkaitan dengan pembelajaran mesin hanya menyumbang 5% daripada keseluruhan sistem AI, dan 95% ialah kandungan berkaitan kejuruteraan dan kandungan berkaitan data. Oleh itu, data adalah yang paling penting dan paling terdedah kepada ralat.
Cabaran data kepada sistem AI sebenar terutamanya terletak pada perkara berikut:
- Skala: Membaca data secara besar-besaran adalah satu cabaran; Dunia sebenar sentiasa berubah, cara menangani pengecilan kesan model; untuk latihan dan ramalan adalah tidak konsisten.
- Yang disenaraikan di atas ialah beberapa cabaran yang berkaitan dengan data dalam pembelajaran mesin. Selain itu, dalam kehidupan sebenar, data masa nyata menimbulkan cabaran yang lebih besar.
- Jadi, untuk perusahaan, bagaimana AI boleh dilaksanakan secara berskala? Mengambil perusahaan besar sebagai contoh, ia mungkin mempunyai lebih daripada 1,000 senario aplikasi dan lebih daripada 1,500 model berjalan dalam talian pada masa yang sama Bagaimana untuk menyokong begitu banyak model? Bagaimanakah kita secara teknikal boleh mencapai pelaksanaan AI yang "lebih, lebih cepat, lebih baik dan lebih murah"?
- Banyak: Pelbagai senario perlu dilaksanakan di sekitar proses perniagaan utama, yang mungkin mengikut urutan 1,000 atau bahkan puluhan ribu untuk perusahaan besar.
- Pantas: Masa pelaksanaan setiap adegan hendaklah pendek dan kelajuan lelaran hendaklah pantas. Sebagai contoh, dalam senario yang disyorkan, selalunya perlu melakukan latihan penuh sekali sehari dan latihan tambahan setiap 15 minit atau setiap 5 minit.
Baik: Kesan pelaksanaan setiap adegan mesti memenuhi jangkaan, sekurang-kurangnya lebih baik daripada sebelum ia dilaksanakan.
Penjimatan: Kos pelaksanaan setiap senario adalah agak menjimatkan, selaras dengan jangkaan.
Untuk benar-benar mencapai "lebih, lebih pantas, lebih baik dan lebih murah", kami memerlukan MLOps.
Dalam bidang pembangunan perisian tradisional, kami menggunakan DevOps untuk menyelesaikan masalah yang serupa seperti pelancaran perlahan dan kualiti yang tidak stabil. DevOps telah meningkatkan kecekapan pembangunan dan pelancaran perisian dengan pesat, serta menggalakkan lelaran dan pembangunan perisian moden yang pesat. Apabila menghadapi masalah dengan sistem AI, kita boleh belajar daripada pengalaman matang dalam bidang DevOps untuk membangunkan MLOps. Jadi seperti yang ditunjukkan dalam rajah, "Pembangunan pembelajaran mesin + pembangunan perisian moden" menjadi MLOps. Apakah sebenarnya MLOps?Pada masa ini tiada definisi standard dalam industri untuk apa itu MLOps.
mengekalkan model pembelajaran mesin dalam pengeluaran yang boleh dipercayai dan cekap.
Definisi daripada awan Google: MLOps ialah budaya dan amalan kejuruteraan pembelajaran mesin yang direka bentuk untuk menyatukan pembangunan dan operasi sistem pembelajaran mesin.
Definisi daripada Microsoft Azure: MLOps boleh membantu saintis data dan jurutera aplikasi menjadikan model pembelajaran mesin lebih berkesan dalam pengeluaran.
- Pernyataan di atas agak berbelit-belit Pemahaman peribadi saya tentang perkara ini agak mudah: MLOps ialah penyepaduan berterusan, penggunaan berterusan, latihan berterusan dan pemantauan berterusan "Kod+Model+Data".
- Gambar di atas menunjukkan adegan kehidupan pembelajaran mesin biasa. Selepas mentakrifkan fasa projek, kami mula mentakrifkan dan mengumpul data pemprosesan. Kami perlu memerhati data apakah yang membantu dalam menyelesaikan masalah semasa? Cara memproses, cara melakukan kejuruteraan ciri, cara menukar dan menyimpan.
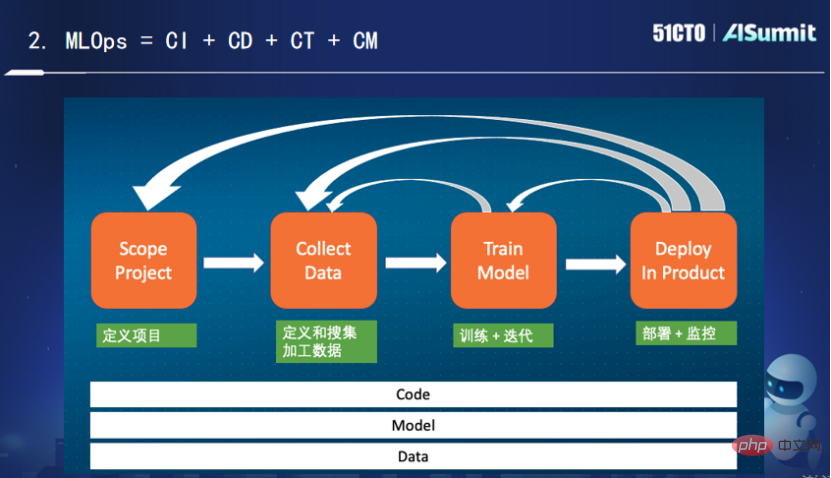 Seperti yang anda lihat, keseluruhan proses adalah proses berulang. Untuk amalan kejuruteraan, kami memerlukan penyepaduan berterusan, penggunaan berterusan, latihan berterusan dan pemantauan berterusan. Antaranya, latihan berterusan dan pemantauan berterusan adalah unik untuk MLOps. Peranan latihan berterusan ialah walaupun model kod tidak berubah, ia perlu dilatih secara berterusan untuk perubahan dalam datanya. Peranan pemantauan berterusan adalah untuk sentiasa memantau sama ada terdapat masalah dengan pemadanan antara data dan model. Pemantauan di sini merujuk kepada bukan sahaja memantau sistem dalam talian, tetapi juga memantau beberapa penunjuk yang berkaitan dengan sistem dan pembelajaran mesin, seperti kadar ingatan semula, kadar ketepatan, dsb. Kesimpulannya, saya fikir MLOps sebenarnya ialah penyepaduan berterusan, penggunaan berterusan, latihan berterusan dan pemantauan berterusan kod, model dan data.
Seperti yang anda lihat, keseluruhan proses adalah proses berulang. Untuk amalan kejuruteraan, kami memerlukan penyepaduan berterusan, penggunaan berterusan, latihan berterusan dan pemantauan berterusan. Antaranya, latihan berterusan dan pemantauan berterusan adalah unik untuk MLOps. Peranan latihan berterusan ialah walaupun model kod tidak berubah, ia perlu dilatih secara berterusan untuk perubahan dalam datanya. Peranan pemantauan berterusan adalah untuk sentiasa memantau sama ada terdapat masalah dengan pemadanan antara data dan model. Pemantauan di sini merujuk kepada bukan sahaja memantau sistem dalam talian, tetapi juga memantau beberapa penunjuk yang berkaitan dengan sistem dan pembelajaran mesin, seperti kadar ingatan semula, kadar ketepatan, dsb. Kesimpulannya, saya fikir MLOps sebenarnya ialah penyepaduan berterusan, penggunaan berterusan, latihan berterusan dan pemantauan berterusan kod, model dan data.
Sudah tentu, MLOps bukan sekadar proses dan Saluran Paip, ia juga merangkumi kandungan yang lebih besar dan lebih banyak. Contohnya:
(1) Platform storan: Penyimpanan dan pembacaan ciri dan model
(2) Platform pengkomputeran: Penstriman dan pemprosesan kelompok untuk pemprosesan ciri
(3) Baris gilir mesej: digunakan untuk menerima data masa nyata
(4) Alat penjadualan: penjadualan pelbagai sumber (pengkomputeran/storan)
(5) Kedai Ciri: pendaftaran , Temui dan kongsi pelbagai ciri
(6) Kedai Model: Ciri model
(7) Kedai Penilaian: Pemantauan/pengujian AB model
Kedai Ciri, Kedai model dan gedung Penilaian ialah aplikasi dan platform baru muncul dalam bidang pembelajaran mesin, kerana kadangkala berbilang model dijalankan dalam talian pada masa yang sama Untuk mencapai lelaran yang pantas, infrastruktur yang baik diperlukan untuk mengekalkan maklumat ini, untuk menjadikan lelaran lebih cekap . Aplikasi Baharu dan platform baharu ini muncul mengikut kehendak masa.
Projek unik MLOps - Kedai Ciri
Berikut ialah pengenalan ringkas kepada Kedai Ciri, platform ciri. Sebagai platform unik dalam bidang pembelajaran mesin, Feature Store mempunyai banyak ciri.
Pertama, adalah perlu untuk memenuhi keperluan latihan model dan ramalan pada masa yang sama. Enjin storan data ciri mempunyai keperluan aplikasi yang berbeza sama sekali dalam senario yang berbeza. Latihan model memerlukan kebolehskalaan yang baik dan ruang storan yang besar perlu memenuhi keperluan prestasi tinggi dan kependaman yang rendah.
Kedua, masalah ketidakkonsistenan antara pemprosesan ciri semasa latihan dan peringkat ramalan mesti diselesaikan. Semasa latihan model, saintis AI biasanya menggunakan skrip Python, dan kemudian menggunakan Spark atau SparkSQL untuk melengkapkan pemprosesan ciri. Latihan jenis ini tidak sensitif kepada kelewatan dan kurang cekap apabila berurusan dengan perniagaan dalam talian Oleh itu, jurutera akan menggunakan bahasa berprestasi tinggi untuk menterjemah proses pemprosesan ciri. Walau bagaimanapun, proses penterjemahan adalah sangat menyusahkan, dan jurutera perlu berulang kali menyemak dengan saintis untuk melihat sama ada logiknya selaras dengan jangkaan. Selagi ia sedikit tidak konsisten dengan jangkaan, ia akan membawa masalah ketidakkonsistenan antara dalam talian dan luar talian.
Ketiga, masalah penggunaan semula dalam pemprosesan ciri perlu diselesaikan untuk mengelakkan pembaziran dan perkongsian dengan cekap. Dalam aplikasi AI perusahaan, situasi ini sering berlaku: ciri yang sama digunakan oleh jabatan perniagaan yang berbeza, sumber data berasal dari fail log yang sama, dan logik pengekstrakan yang dilakukan di tengah juga serupa, tetapi kerana ia berada di jabatan yang berbeza. Atau digunakan dalam senario yang berbeza, ia tidak boleh digunakan semula, yang bersamaan dengan logik yang sama dilaksanakan N kali, dan fail log adalah besar, yang merupakan pembaziran besar sumber storan dan sumber pengkomputeran.
Ringkasnya, Kedai Ciri digunakan terutamanya untuk menyelesaikan storan dan perkhidmatan ciri berprestasi tinggi, latihan model dan ramalan model, ketekalan data ciri, penggunaan semula ciri dan isu lain saintis Data boleh menggunakan Gedung Ciri untuk penggunaan dan perkongsian .
Produk platform ciri arus perdana yang kini berada di pasaran boleh dibahagikan secara kasar kepada tiga kategori.
- Setiap syarikat AI menjalankan penyelidikannya sendiri. Selagi perniagaan memerlukan latihan masa nyata, syarikat ini pada asasnya akan membangunkan platform ciri yang serupa untuk menyelesaikan tiga masalah di atas. Tetapi platform ciri ini sangat terikat dengan perniagaan.
- Produk SAAS atau sebahagian daripada platform pembelajaran mesin yang disediakan oleh vendor awan. Contohnya, SageMaker disediakan oleh AWS, Vertex disediakan oleh Google dan platform pembelajaran mesin Azure yang disediakan oleh Microsoft. Mereka akan mempunyai platform ciri terbina dalam platform pembelajaran mesin untuk memudahkan pengguna mengurus pelbagai ciri kompleks.
- Sesetengah produk sumber terbuka dan komersial. Untuk memberikan beberapa contoh, Feast, produk Kedai Ciri sumber terbuka Tecton menyediakan produk platform ciri komersial sumber terbuka yang lengkap, OpenMLDB, produk Kedai Ciri sumber terbuka.
Model Kematangan MLOps
Model kematangan digunakan untuk mengukur matlamat keupayaan sistem dan satu set peraturan Dalam medan DevOps, model kematangan sering digunakan untuk menilai keupayaan DevOps. Terdapat juga model kematangan yang sepadan dalam bidang MLOps, tetapi ia masih belum diseragamkan. Berikut ialah pengenalan ringkas kepada model kematangan Azure tentang MLOps.
Mengikut tahap automasi keseluruhan proses pembelajaran mesin, model matang MLOps dibahagikan kepada (0, 1, 2, 3, 4) tahap, yang mana 0 bermakna tiada automasi. (1,2,3) ialah automasi separa, dan 4 adalah sangat automatik. Peringkat ini bermakna penyediaan data adalah manual, latihan model juga manual, dan penggunaan latihan model juga manual. Semua kerja dilakukan secara manual, yang sesuai untuk sesetengah jabatan perniagaan yang menjalankan projek perintis inovatif pada AI.
Tahap kematangan ialah 1, iaitu, terdapat DevOps tetapi tiada MLOps. Penyediaan datanya dilakukan secara automatik, tetapi latihan model dilakukan secara manual. Selepas saintis mendapat data, mereka membuat pelbagai pelarasan dan latihan sebelum melengkapkannya. Penggunaan model juga dilakukan secara manual. 
Tahap kematangan ialah 4, yang bermaksud latihan semula automatik dan penggunaan. Ia sentiasa memantau model dalam talian Apabila didapati bahawa keupayaan model dalam talian Model DK telah merosot, ia secara automatik akan mencetuskan latihan berulang. Seluruh proses adalah automatik sepenuhnya, yang boleh dipanggil sistem yang paling matang.
Untuk kandungan yang lebih menarik, sila layari laman web rasmi persidangan: Klik untuk melihat
Atas ialah kandungan terperinci Tan Zhongyi: Daripada Model-Centric kepada Data-Centric MLOps membantu AI dilaksanakan dengan lebih pantas, lebih kos efektif. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI