
Rumah >Peranti teknologi >AI >Cara mudah untuk memproses set data pembelajaran mesin yang besar dalam Python
Cara mudah untuk memproses set data pembelajaran mesin yang besar dalam Python

- 王林ke hadapan
- 2023-04-09 19:51:011811semak imbas
Sasarkan khalayak untuk artikel ini:
- Orang yang ingin melakukan operasi Pandas/NumPy pada set data yang besar.
- Orang yang ingin menggunakan Python untuk melaksanakan tugas pembelajaran mesin pada data besar.

Artikel ini akan menggunakan fail format .csv untuk menunjukkan pelbagai operasi python, serta format lain seperti tatasusunan, fail teks, dsb.
Mengapa kita tidak boleh menggunakan panda untuk set data pembelajaran mesin yang besar?
Kami tahu bahawa Pandas menggunakan memori komputer (RAM) untuk memuatkan set data pembelajaran mesin anda, tetapi jika komputer anda mempunyai 8 GB memori (RAM), maka mengapa panda masih tidak boleh memuatkan set data 2 GB Kain Woolen? Sebabnya ialah memuatkan fail 2 GB menggunakan Pandas memerlukan bukan sahaja 2 GB RAM, tetapi lebih banyak memori kerana jumlah keperluan memori bergantung pada saiz set data dan operasi yang akan anda lakukan pada set data tersebut.
Berikut ialah perbandingan pantas set data bersaiz berbeza yang dimuatkan ke dalam memori komputer:
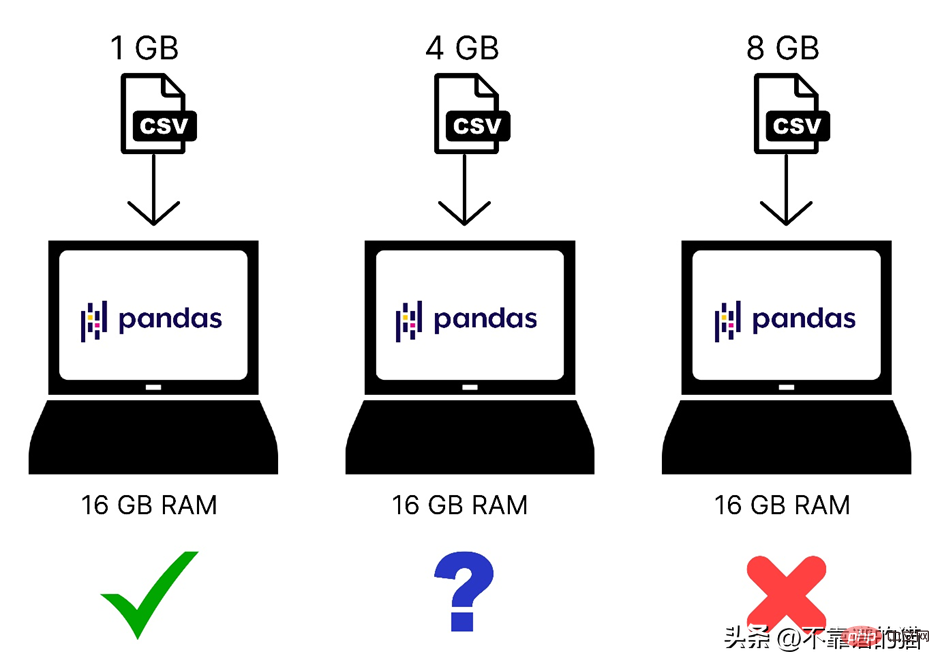
Selain itu, Pandas hanya menggunakan satu teras sistem pengendalian, yang Membuat pemprosesan lambat sangat. Dalam erti kata lain, kita boleh mengatakan bahawa panda tidak menyokong paralelisme (memecahkan masalah kepada tugas yang lebih kecil).
Dengan mengandaikan bahawa komputer mempunyai 4 teras, rajah berikut menunjukkan bilangan teras yang digunakan oleh panda semasa memuatkan fail CSV:
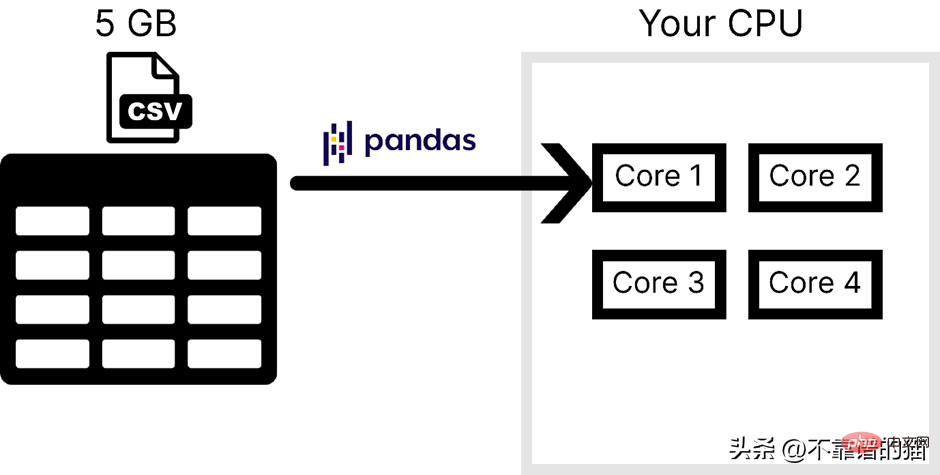
Panda biasanya tidak digunakan untuk mengendalikan pembelajaran mesin berskala besar Sebab utama set data adalah dua perkara berikut, satu ialah penggunaan memori komputer, dan satu lagi adalah kekurangan keselarian. Dalam NumPy dan Scikit-learn, masalah yang sama dihadapi untuk set data yang besar.
Untuk menyelesaikan dua masalah ini, anda boleh menggunakan perpustakaan python yang dipanggil Dask, yang membolehkan kami melakukan pelbagai operasi seperti panda, NumPy dan ML pada set data yang besar.
Bagaimana Dask berfungsi?
Dask memuatkan set data anda dalam partition, manakala panda biasanya menggunakan keseluruhan set data pembelajaran mesin sebagai bingkai data. Dalam Dask, setiap partition set data dianggap sebagai bingkai data panda.
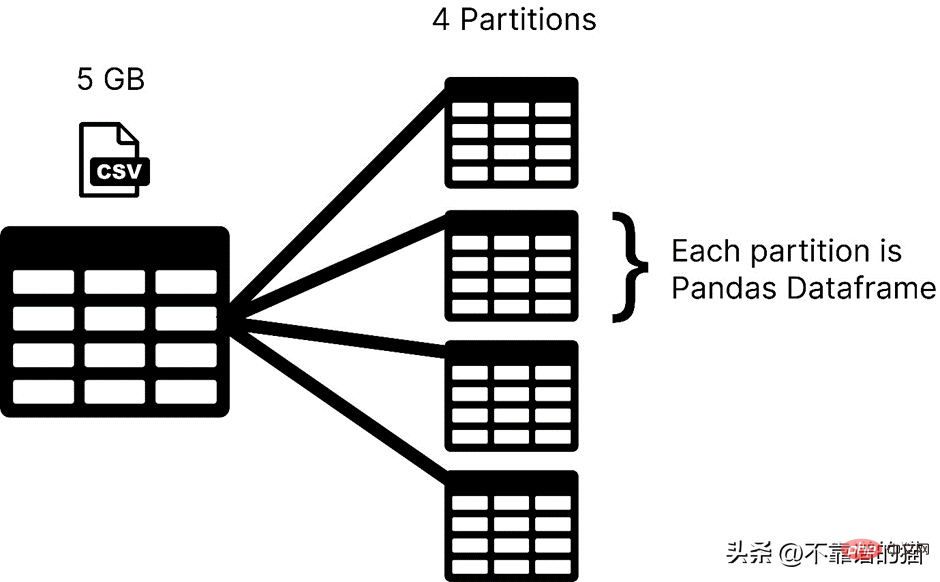
Dask memuatkan satu partition pada satu masa, jadi anda tidak perlu risau tentang ralat peruntukan memori.
Berikut ialah perbandingan penggunaan dask untuk memuatkan set data pembelajaran mesin dengan saiz yang berbeza dalam ingatan komputer:
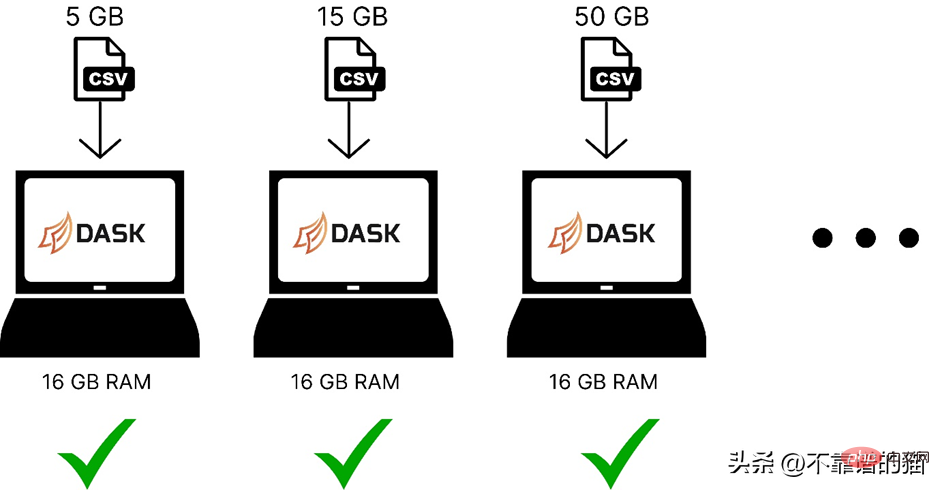
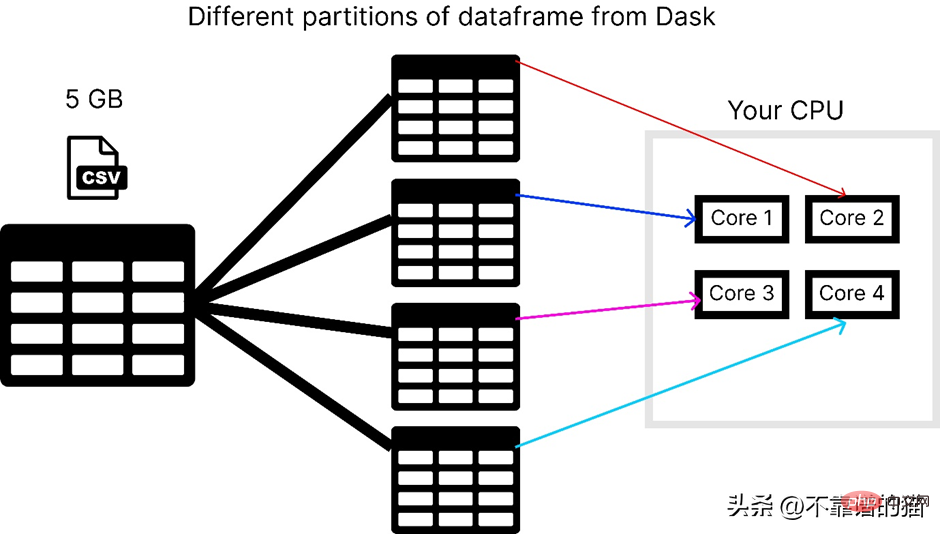
Dask menyelesaikan masalah selari kerana ia akan data dibahagikan kepada berbilang partition, setiap satu menggunakan teras yang berasingan, yang menjadikan pengiraan pada set data lebih cepat.
Dengan mengandaikan komputer mempunyai 4 teras, berikut ialah cara dask memuatkan fail csv 5 GB:
Untuk menggunakan perpustakaan dask anda boleh menggunakan Perintah berikut untuk memasang:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>
Dask mempunyai beberapa modul seperti dask.array, dask.dataframe dan dask.distributed, hanya selepas anda memasang perpustakaan yang sepadan seperti NumPy, panda dan Tornado masing-masing Untuk berfungsi.
Bagaimana untuk menggunakan dask untuk memproses fail CSV yang besar?
dask.dataframe digunakan untuk memproses fail csv yang besar, mula-mula saya cuba mengimport set data bersaiz 8 GB menggunakan panda.
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)
Ia menyebabkan ralat peruntukan memori dalam komputer riba 16 GB RAM saya.
Sekarang, cuba import data 8 GB yang sama menggunakan dask.dataframe
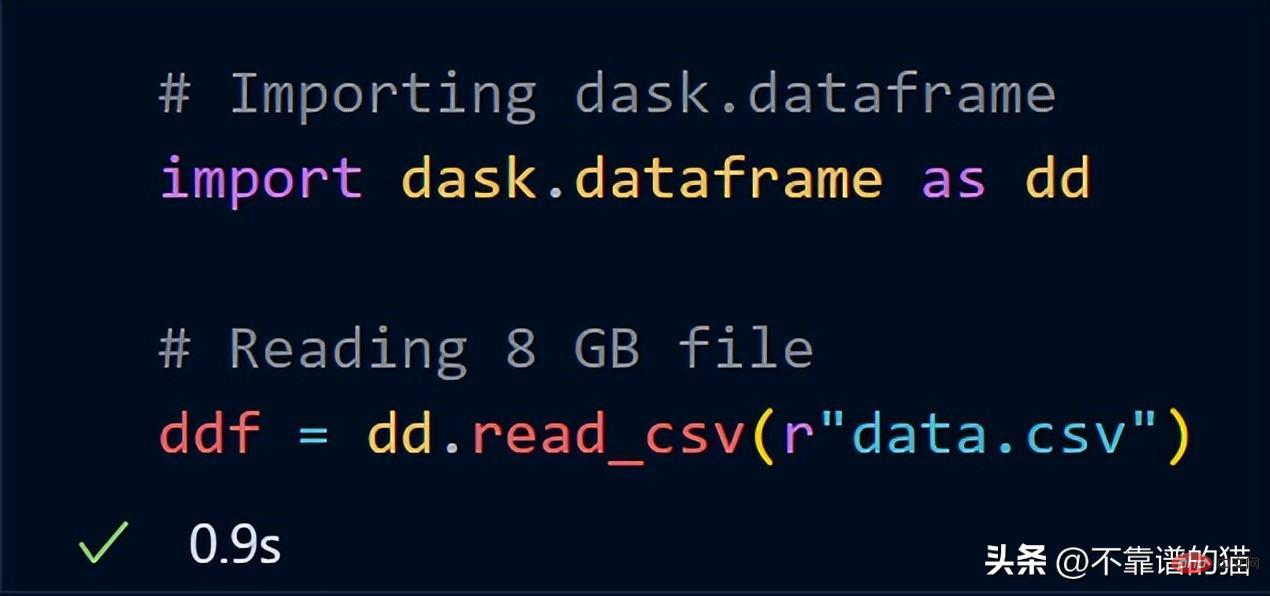
dask mengambil masa hanya seketika untuk memuatkan keseluruhan fail 8 GB ke dalam ddf pembolehubah.
Mari kita lihat output pembolehubah ddf.
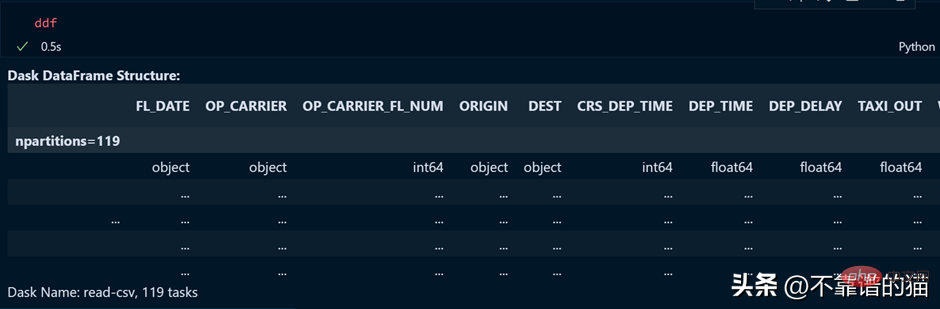
Seperti yang anda lihat, masa pelaksanaan ialah 0.5 saat dan ia ditunjukkan di sini dibahagikan kepada 119 partition.
Anda juga boleh menyemak bilangan partition kerangka data anda menggunakan:
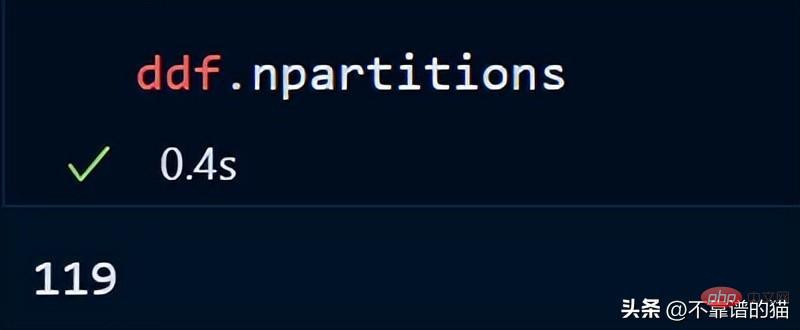
Secara lalai, dask memuatkan fail CSV 8 GB saya ke dalam 119 Partition (setiap partition saiz ialah 64MB), ini dilakukan berdasarkan memori fizikal yang tersedia dan bilangan teras komputer.
Saya juga boleh menentukan bilangan partition saya sendiri menggunakan parameter saiz blok semasa memuatkan fail CSV.
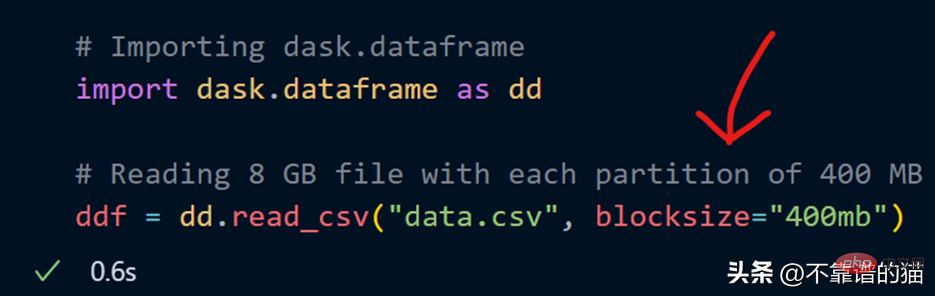
Kini parameter saiz blok dengan nilai rentetan 400MB ditentukan, yang menjadikan setiap saiz partition 400 MB, mari lihat berapa banyak partition yang terdapat
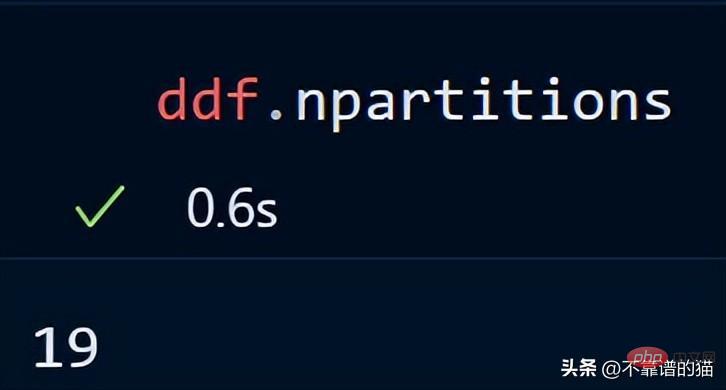
Perkara Utama: Apabila menggunakan Dask DataFrames, peraturan yang baik ialah mengekalkan partition di bawah 100MB.
Partition tertentu bagi kerangka data boleh dipanggil menggunakan:
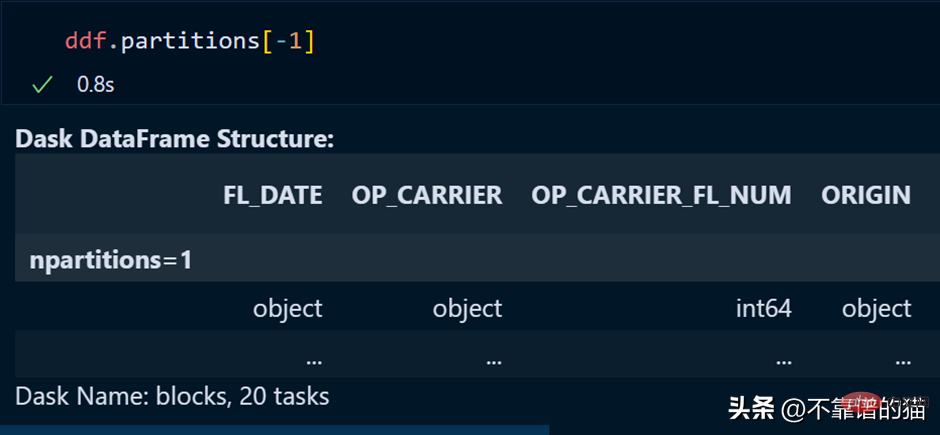
Partition terakhir juga boleh dipanggil dengan menggunakan indeks negatif, sama seperti kita memanggil senarai sebagai elemen terakhir.
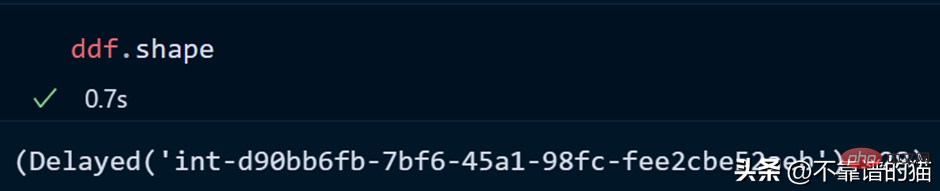
Mari kita lihat bentuk set data:
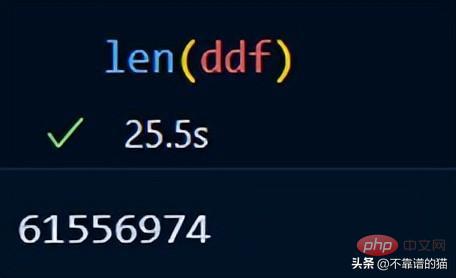
Anda boleh menyemak bilangan baris set data menggunakan len():
Dask sudah termasuk set data sampel. Saya akan menggunakan data siri masa untuk menunjukkan kepada anda cara dask melaksanakan operasi matematik pada set data.
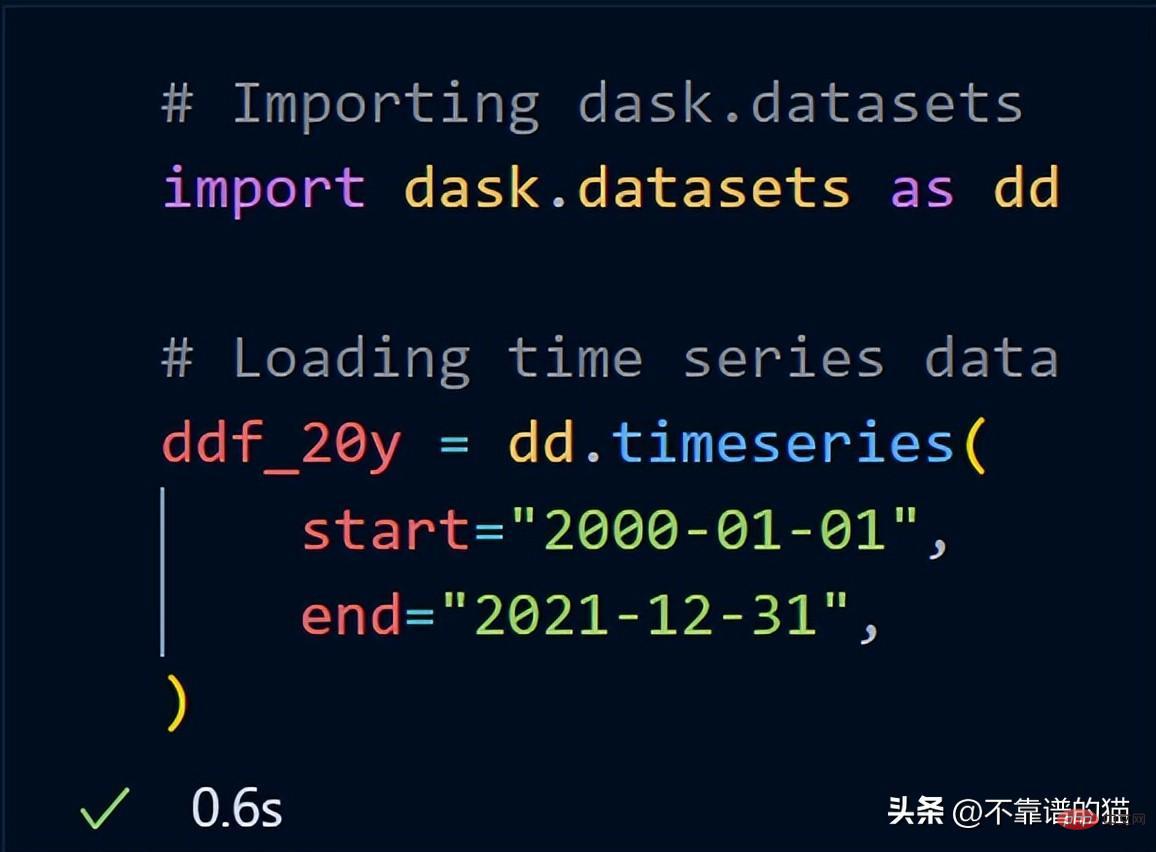
Selepas mengimport dask.datasets, ddf_20y memuatkan data siri masa dari 1 Januari 2000 hingga 31 Disember 2021.
Mari kita lihat bilangan partition untuk data siri masa kita.
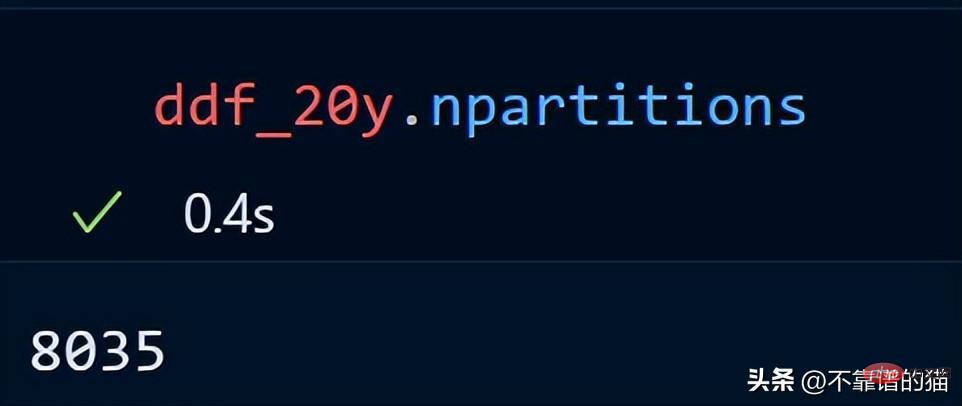
Data siri masa 20 tahun diedarkan dalam 8035 sekatan.
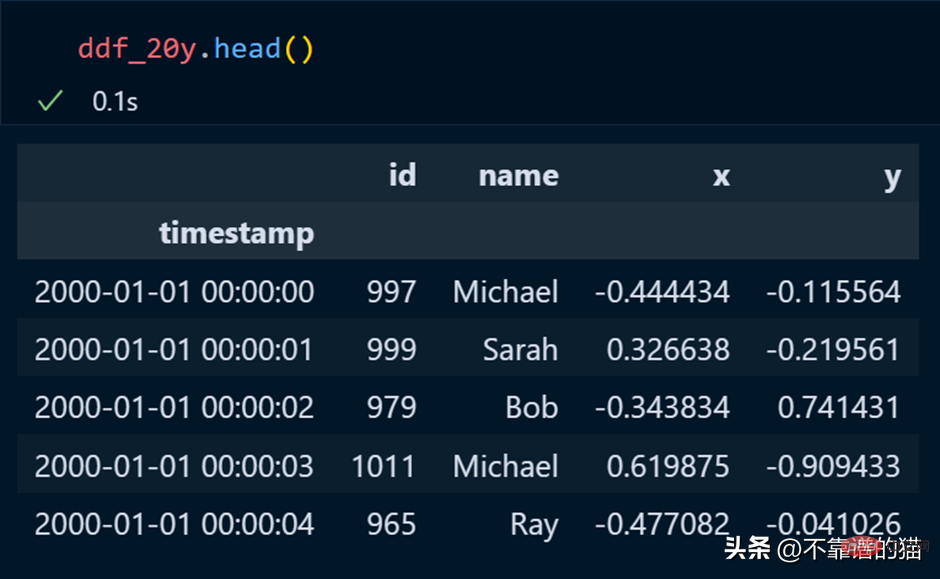
Dalam panda, kami menggunakan kepala untuk mencetak beberapa baris pertama set data, dan perkara yang sama berlaku untuk dask.
Mari kita hitung purata lajur id.
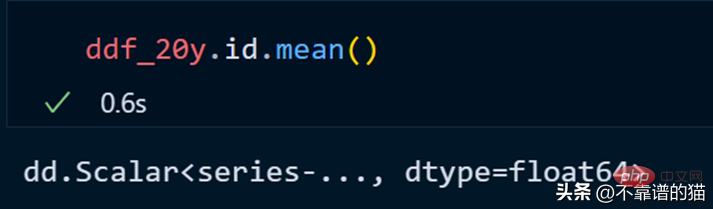
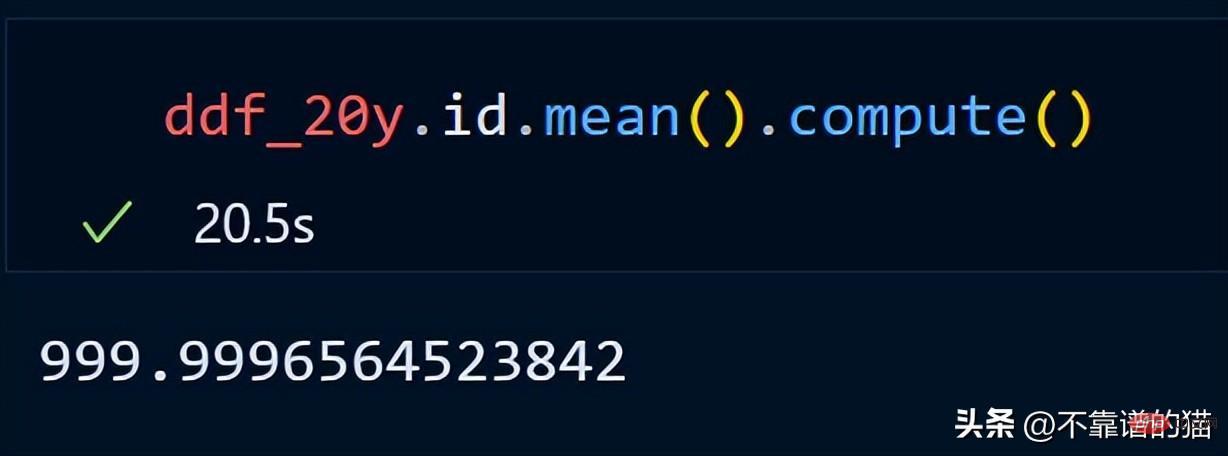
dask tidak mencetak jumlah bilangan baris rangka data kerana ia menggunakan pengiraan malas (output tidak dipaparkan sehingga diperlukan). Untuk memaparkan output, kita boleh menggunakan kaedah pengiraan.
Katakan saya ingin menormalkan setiap lajur set data (tukar nilai kepada antara 0 dan 1), kod Python adalah seperti berikut:
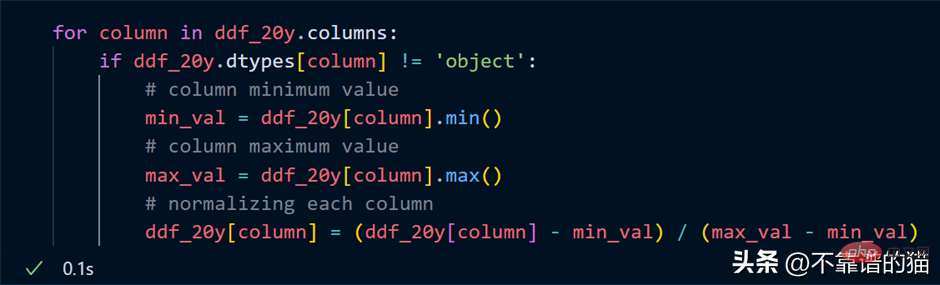
Gelung melalui lajur, cari nilai minimum dan maksimum untuk setiap lajur dan normalkan lajur menggunakan formula matematik mudah.
Perkara utama: Dalam contoh normalisasi kami, jangan fikir pengiraan berangka sebenar berlaku, ia hanyalah penilaian yang malas (output tidak pernah ditunjukkan kepada anda sehingga ia diperlukan).
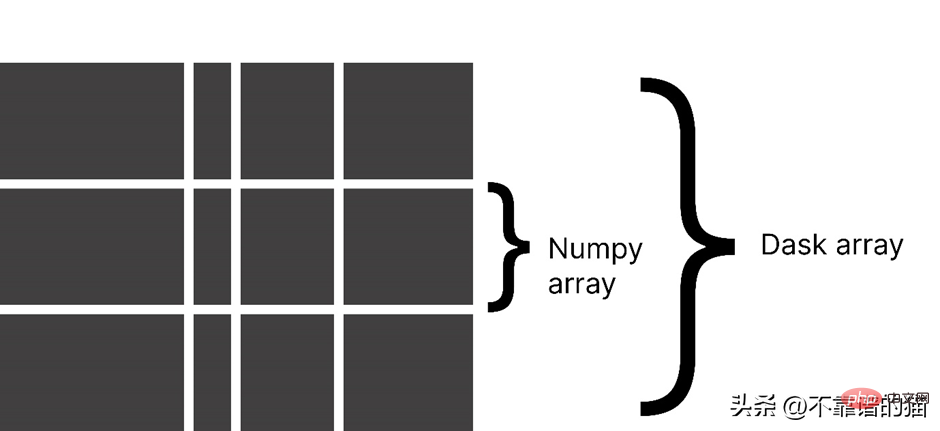
Mengapa menggunakan tatasusunan Dask?
Dask membahagikan tatasusunan kepada ketulan kecil, di mana setiap ketulan ialah tatasusunan NumPy.
dask.arrays digunakan untuk mengendalikan tatasusunan besar Kod Python berikut menggunakan dask untuk mencipta tatasusunan 10000 x 10000 dan menyimpannya dalam pembolehubah x.
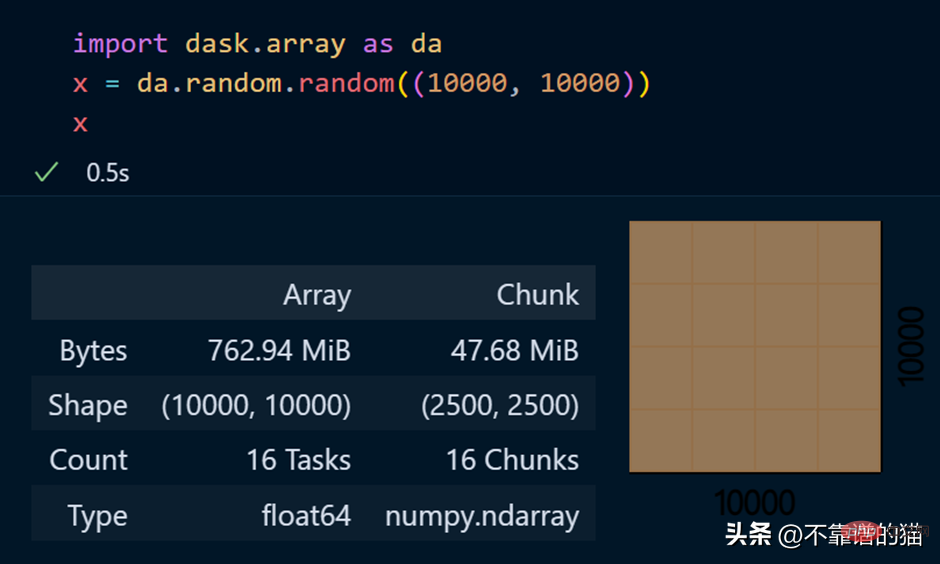
Memanggil pembolehubah x menghasilkan pelbagai maklumat tentang tatasusunan.
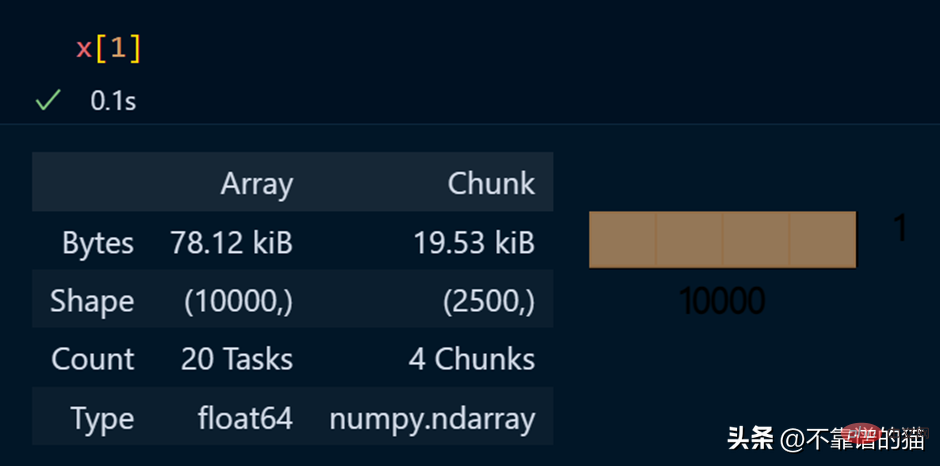
Lihat elemen tertentu tatasusunan
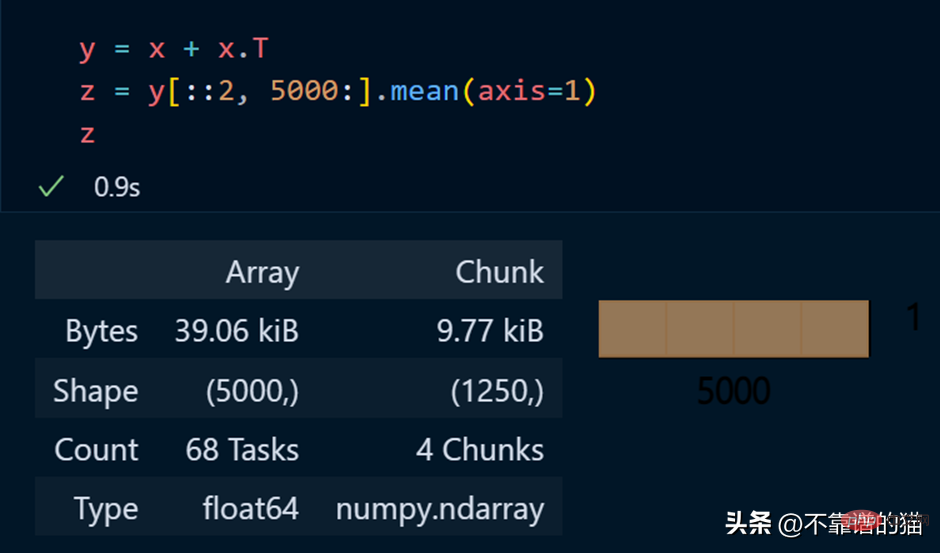
Contoh python untuk melaksanakan operasi matematik pada tatasusunan dask:
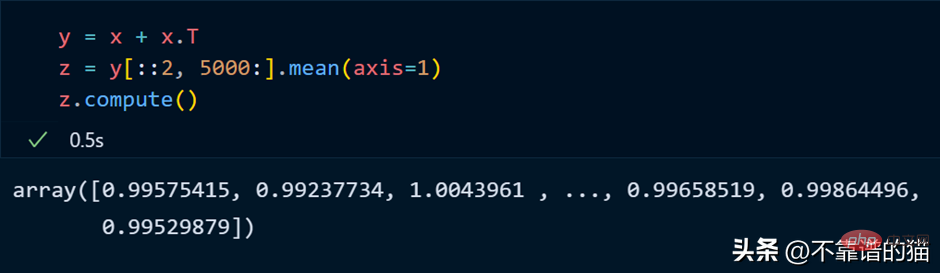
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据
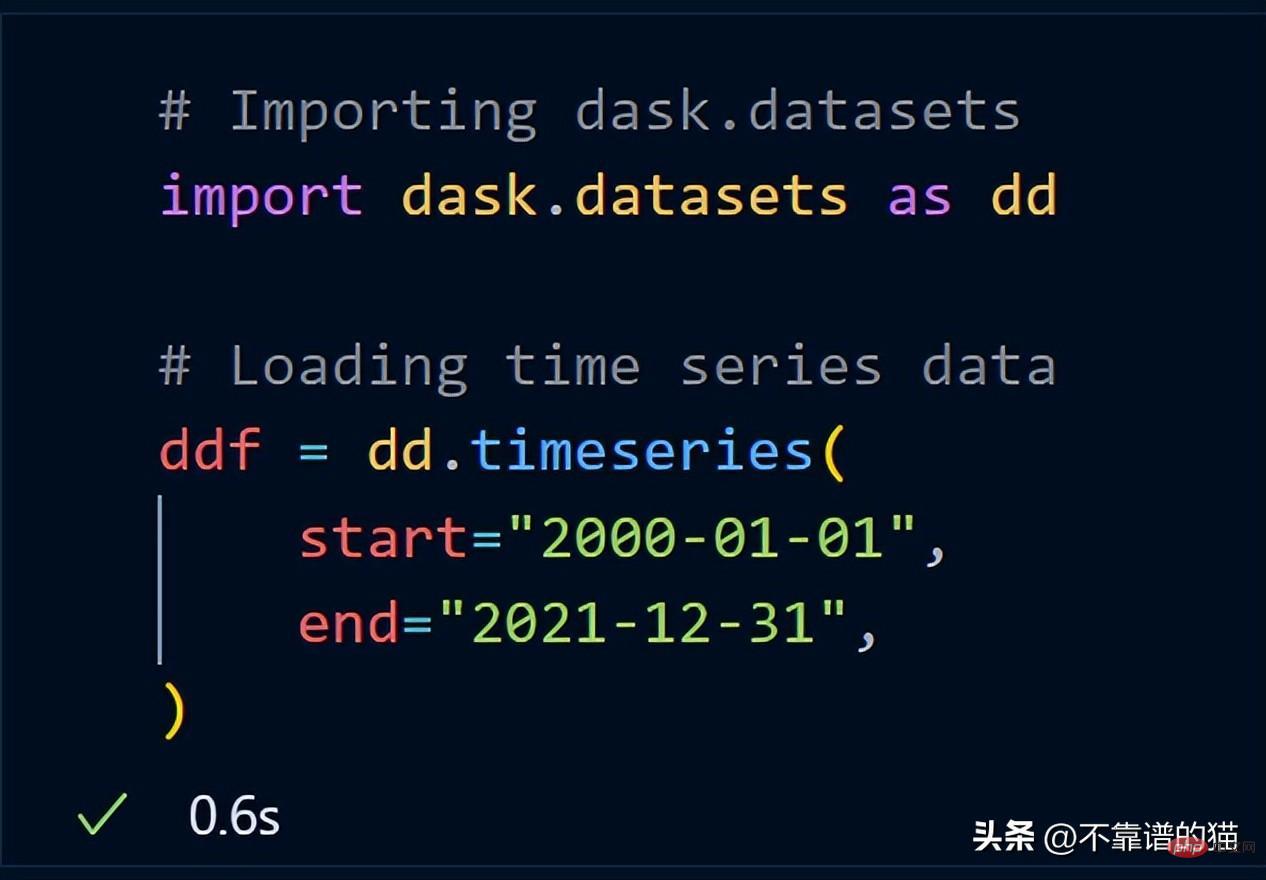
让我们取数据集的一个子集并计算该子集的总行数。
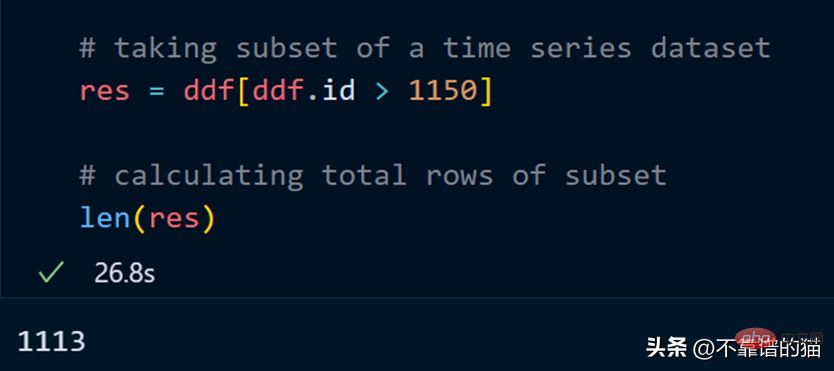
计算总行数需要 27 秒。
我们现在使用 persist 方法:
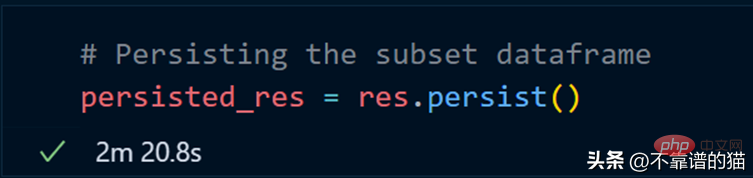
持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
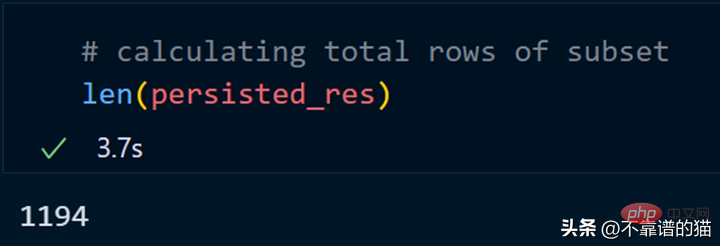
同样,我们可以对持久化数据集执行其他操作以减少计算时间。
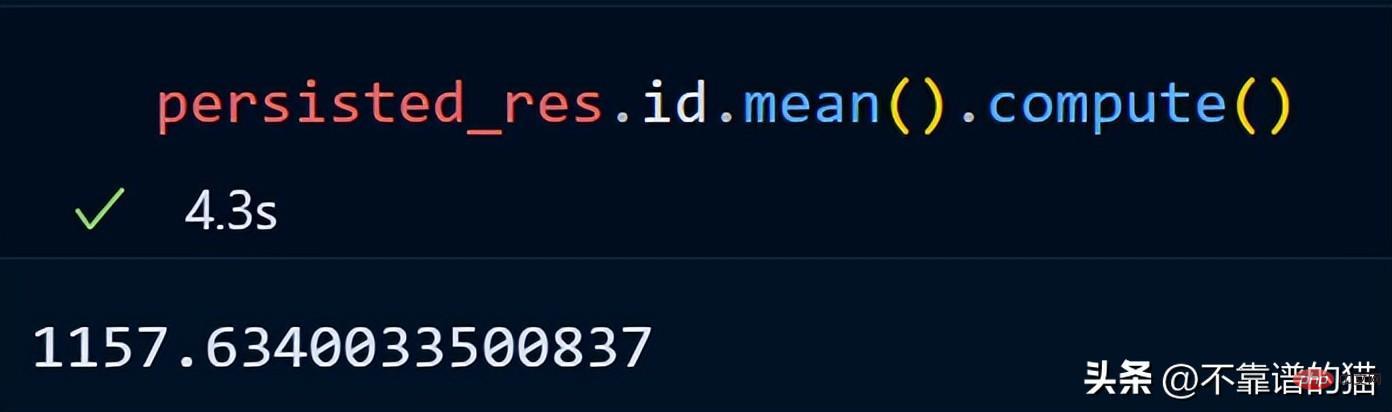
persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。
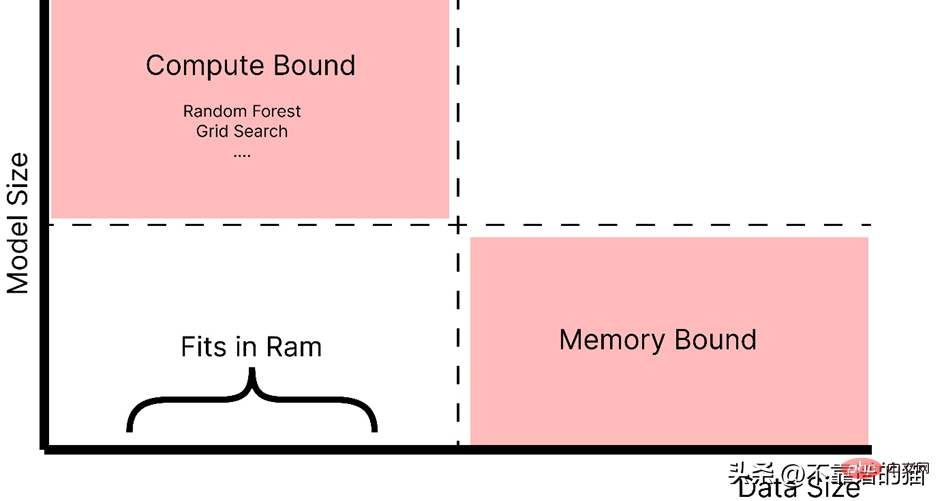
正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
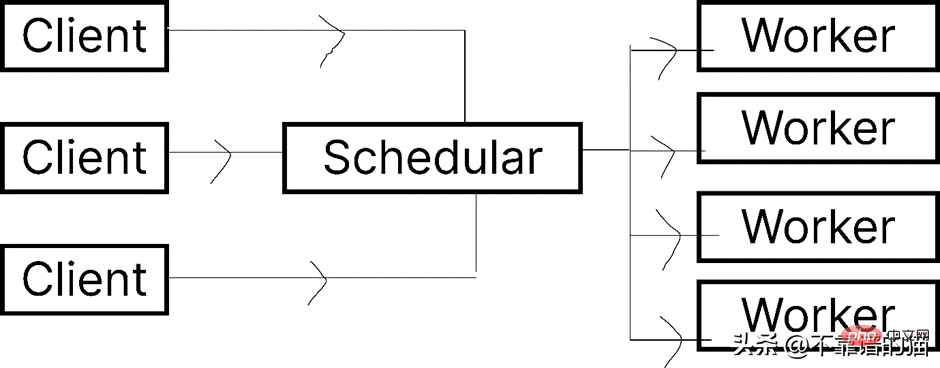
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
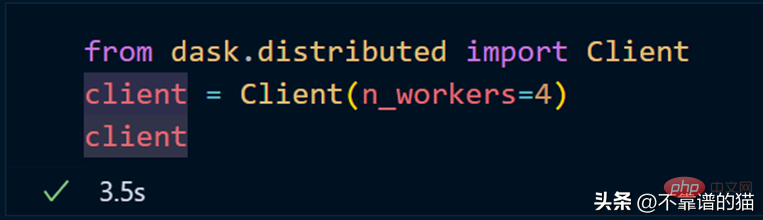
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群
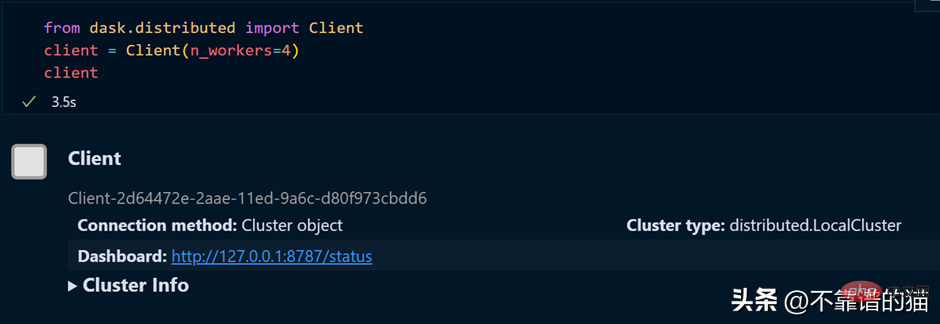
如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
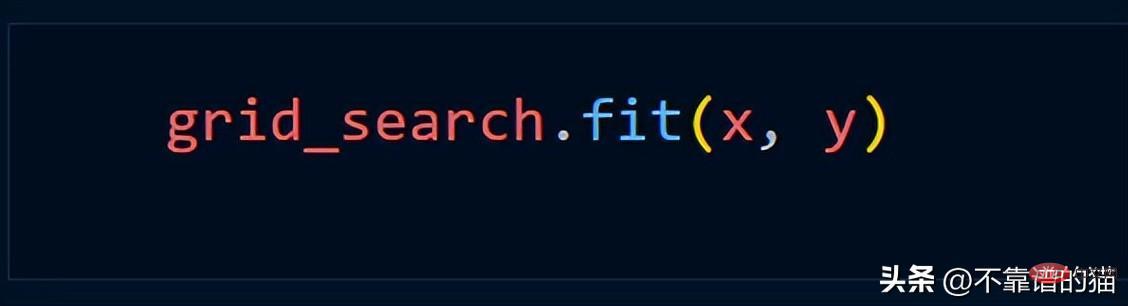
Dengan mengandaikan kami menggunakan kaedah Grid_Search, kami biasanya menggunakan kod Python berikut
Gunakan dask.distributed untuk mencipta gugusan:
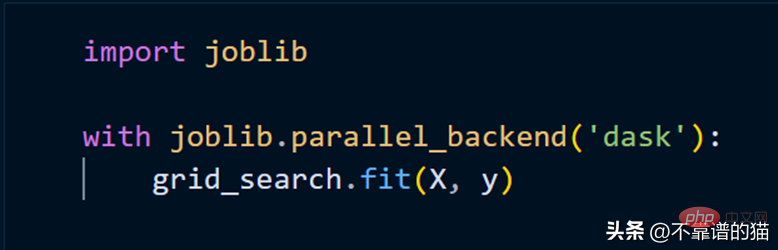
Untuk menyesuaikan model scikit-lear menggunakan kluster, kita hanya perlu menggunakan joblib.
Atas ialah kandungan terperinci Cara mudah untuk memproses set data pembelajaran mesin yang besar dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI