
Rumah >Peranti teknologi >AI >Pengembangan teknologi aplikasi TensorFlow—pengkelasan imej
Pengembangan teknologi aplikasi TensorFlow—pengkelasan imej

- 王林ke hadapan
- 2023-04-18 16:07:031801semak imbas
1. Pengembangan operasi penggunaan persekitaran platform penyelidikan saintifik
Untuk latihan model dalam pembelajaran mesin, saya mengesyorkan anda mempelajari lebih banyak kursus atau sumber TensorFlow, seperti dua kursus mengenai MOOC Universiti Cina 《Kursus Praktikal Pengenalan TensorFlow》 dan 《Kursus Pengenalan TensorFlow - Deployment》. Untuk latihan model yang diedarkan yang terlibat dalam penyelidikan atau kerja saintifik, platform sumber mungkin selalunya sangat memakan masa dan tidak dapat memenuhi keperluan individu tepat pada masanya. Di sini, saya akan membuat pengembangan khusus mengenai penggunaan platform Jiutian Bisheng yang disebut dalam artikel sebelum ini "Pemahaman Awal Pembelajaran Rangka Kerja TensorFlow" untuk memudahkan pelajar dan pengguna Menjalankan latihan model dengan lebih cepat. Platform ini boleh melaksanakan tugas seperti pengurusan data dan latihan model, dan merupakan platform amalan yang mudah dan pantas untuk tugasan penyelidikan saintifik. Langkah khusus dalam latihan model ialah:
(1) Daftar dan log masuk ke platform Jiutian Bisheng Memandangkan tugas latihan seterusnya memerlukan penggunaan kacang kuasa pengkomputeran, bilangan kacang kuasa pengkomputeran untuk pengguna baharu adalah terhad. , tetapi mereka boleh dikongsi oleh Rakan dan tugas lain untuk menyelesaikan pemerolehan kacang kuasa pengkomputeran. Pada masa yang sama, untuk tugas latihan model berskala besar, untuk mendapatkan lebih banyak ruang storan latihan model, anda boleh menghubungi kakitangan platform melalui e-mel untuk menaik taraf konsol, sekali gus memenuhi keperluan storan latihan yang diperlukan pada masa hadapan. Butiran biji kuasa penyimpanan dan pengkomputeran adalah seperti berikut:

(2) Masukkan antara muka pengurusan data untuk menggunakan set data yang digunakan oleh model projek penyelidikan saintifik, dan tambah set data yang diperlukan untuk tugasan penyelidikan saintifik Pakej dan muat naik untuk melengkapkan penggunaan set data yang diperlukan untuk latihan model pada platform.
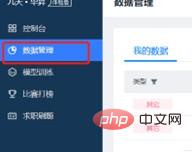
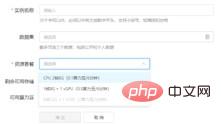
(3) Tambahkan contoh latihan projek baharu dalam tetingkap latihan model, pilih set data yang diimport sebelum ini dan sumber CPU yang diperlukan. Contoh yang dibuat ialah fail model tunggal yang perlu dilatih untuk penyelidikan saintifik. Butiran contoh projek baharu adalah seperti yang ditunjukkan di bawah:

(4) Jalankan contoh projek baharu, iaitu jalankan persekitaran latihan projek , selepas berjalan dengan jayanya, anda boleh memilih editor jupyter untuk mencipta dan mengedit fail kod yang diperlukan.

(5) Penulisan kod dan latihan model seterusnya boleh dilakukan menggunakan editor jupyter.
2. Pengembangan teknologi pengelasan imej
Klasifikasi imej, seperti namanya, adalah untuk menilai kategori imej yang berbeza berdasarkan perbezaan antara imej. Mereka bentuk model diskriminasi berdasarkan perbezaan antara imej adalah pengetahuan yang perlu dikuasai dalam pembelajaran mesin. Untuk pengetahuan asas dan proses pengendalian klasifikasi imej, anda boleh merujuk kepada "Kursus Praktikal Pengenalan TensorFlow" di MOOC Universiti China untuk memahami dengan cepat aplikasi asas dan idea reka bentuk TensorFlow. . https://www.php.cn/link/b977b532403e14d6681a00f78f95506e
Bab ini bertujuan untuk memperkenalkan pelajar kepada kursus klasifikasi ini dengan meluaskan imej teknologi. Pengguna mendapat pemahaman yang lebih mendalam tentang klasifikasi imej.
2.1 Apakah kegunaan operasi lilitan?
Apabila ia melibatkan pemprosesan atau pengelasan imej, terdapat satu operasi yang tidak boleh dielakkan, dan operasi ini ialah konvolusi. Operasi lilitan khusus pada asasnya boleh difahami melalui video pembelajaran, tetapi lebih ramai pembaca mungkin hanya kekal pada tahap cara melaksanakan operasi lilitan, dan mengapa lilitan dilakukan dan apakah kegunaan operasi lilitan masih tidak jelas. Berikut ialah beberapa pengembangan untuk semua orang untuk membantu anda memahami konvolusi dengan lebih baik.
Proses lilitan asas ditunjukkan dalam rajah di bawah dengan mengambil imej sebagai contoh, matriks digunakan untuk mewakili imej Setiap elemen matriks adalah nilai piksel yang sepadan dalam imej . Operasi lilitan adalah untuk mendapatkan nilai eigen kawasan kecil ini dengan mendarab isirong lilitan dengan matriks yang sepadan. Ciri yang diekstrak akan berbeza disebabkan oleh kernel lilitan yang berbeza Inilah sebabnya mengapa seseorang akan melakukan operasi lilitan pada saluran imej yang berbeza untuk mendapatkan ciri saluran imej yang berbeza untuk melaksanakan tugas pengelasan berikutnya dengan lebih baik.
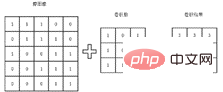
Dalam latihan model harian, kernel konvolusi khusus tidak perlu direka secara manual, tetapi dilatih secara automatik menggunakan rangkaian dengan memberikan label sebenar imej Walau bagaimanapun, proses ini tidak kondusif untuk pemahaman orang ramai tentang kernel konvolusi Proses kernel dan lilitan tidak intuitif. Oleh itu, untuk membantu semua orang lebih memahami maksud operasi lilitan, berikut ialah contoh operasi lilitan. Seperti yang ditunjukkan dalam matriks di bawah, nilai berangka mewakili piksel grafik Untuk kemudahan pengiraan, hanya 0 dan 1 diambil di sini separuh daripada grafik adalah terang dan separuh bahagian bawah grafik adalah hitam, jadi imej Terdapat garis pemisah yang sangat jelas, iaitu, ia mempunyai ciri mendatar yang jelas.

Oleh itu, untuk mengekstrak ciri mendatar matriks di atas dengan baik, kernel lilitan yang direka juga harus mempunyai sifat pengekstrakan ciri mendatar. Kernel lilitan yang menggunakan atribut pengekstrakan ciri menegak agak tidak mencukupi dalam kejelasan pengekstrakan ciri. Seperti yang ditunjukkan di bawah, kernel lilitan yang mengekstrak ciri mendatar digunakan untuk lilitan:
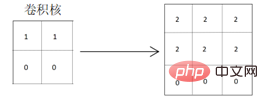
Ia boleh dilihat daripada matriks hasil lilitan yang diperolehi bahawa ciri mendatar grafik asal adalah diekstrak dengan baik, dan garis pemisah grafik akan menjadi lebih jelas, kerana nilai piksel bahagian berwarna grafik diperdalam, yang boleh mengekstrak dan menyerlahkan ciri mendatar grafik. Apabila berbelit menggunakan kernel lilitan yang mengekstrak ciri menegak:
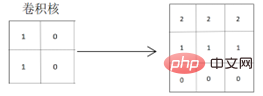
Ia boleh dilihat daripada matriks hasil lilitan yang diperoleh bahawa ciri mendatar grafik asal juga boleh diekstrak, tetapi Dua garis pemisah akan dijana Grafik berubah daripada sangat terang kepada terang dan kemudian kepada hitam, dan situasi yang dicerminkan pada grafik sebenar juga akan menjadi situasi dari terang ke gelap kepada hitam, yang berbeza daripada ciri mendatar sebenar. grafik asal.
Tidak sukar untuk mengetahui daripada contoh di atas bahawa kernel lilitan yang berbeza akan menjejaskan kualiti ciri grafik yang diekstrak akhir Pada masa yang sama, ciri yang ditunjukkan oleh grafik yang berbeza juga berbeza atribut ciri grafik yang berbeza kepada Ia juga amat penting untuk mereka bentuk model rangkaian untuk mempelajari dengan lebih baik dan mereka bentuk inti konvolusi. Dalam projek klasifikasi peta sebenar, adalah perlu untuk memilih dan mengekstrak ciri yang sesuai berdasarkan perbezaan dalam imej, dan selalunya terdapat pertukaran untuk dipertimbangkan.
2.2 Bagaimana untuk mempertimbangkan konvolusi untuk mengklasifikasikan imej dengan lebih baik?
Seperti yang anda boleh lihat daripada peranan operasi lilitan dalam bahagian sebelumnya, adalah amat penting untuk mereka bentuk model rangkaian untuk mempelajari kernel lilitan yang menyesuaikan diri dengan imej dengan lebih baik. Walau bagaimanapun, dalam aplikasi praktikal, pembelajaran dan latihan automatik dilakukan dengan menukar label sebenar bagi kategori imej yang diberikan kepada data vektor yang boleh difahami oleh mesin. Sudah tentu, tidak mustahil untuk diperbaiki melalui tetapan manual. Walaupun label set data adalah tetap, kita boleh memilih model rangkaian yang berbeza berdasarkan jenis imej set data Memandangkan kelebihan dan kekurangan model rangkaian yang berbeza selalunya akan mempunyai hasil latihan yang baik.
Pada masa yang sama, apabila mengekstrak ciri imej, anda juga boleh mempertimbangkan untuk menggunakan kaedah pembelajaran berbilang tugas Dalam data imej sedia ada, gunakan data imej sekali lagi untuk mengekstrak beberapa ciri imej tambahan (seperti ciri saluran imej) dan ciri spatial, dsb.), dan kemudian menambah atau mengisi ciri yang diekstrak sebelum ini untuk menambah baik ciri imej yang diekstrak akhir. Sudah tentu, kadang-kadang operasi ini akan menyebabkan ciri yang diekstrak menjadi berlebihan, dan kesan klasifikasi yang diperoleh selalunya tidak produktif Oleh itu, ia perlu dipertimbangkan berdasarkan keputusan klasifikasi latihan yang sebenar.
2.3 Beberapa cadangan untuk pemilihan model rangkaian
Bidang klasifikasi imej telah lama berkembang, daripada model rangkaian AlexNet klasik asal kepada model rangkaian ResNet yang popular baru-baru ini tahun, dsb., teknologi pengelasan imej telah berkembang dengan agak baik, dan ketepatan klasifikasi untuk beberapa set data imej yang biasa digunakan cenderung 100%. Pada masa ini, dalam bidang ini, kebanyakan orang menggunakan model rangkaian terkini, dan dalam kebanyakan tugas pengelasan imej, menggunakan model rangkaian terkini sememangnya boleh membawa kesan klasifikasi yang jelas Oleh itu, ramai orang dalam bidang ini Orang sering mengabaikan model rangkaian sebelumnya dan pergi terus untuk mempelajari model rangkaian terkini dan popular.
Di sini, saya masih mengesyorkan agar pembaca membiasakan diri dengan beberapa model rangkaian klasik dalam bidang klasifikasi graf, kerana kemas kini teknologi dan lelaran sangat pantas, malah model rangkaian terkini akan digunakan pada masa hadapan mungkin dihapuskan, tetapi prinsip operasi model rangkaian asas adalah lebih kurang sama Dengan menguasai model rangkaian klasik, anda bukan sahaja boleh menguasai prinsip asas, tetapi juga memahami perbezaan antara model rangkaian yang berbeza dan kelebihan memproses tugas yang berbeza. . Contohnya, apabila set data imej anda agak kecil, latihan dengan model rangkaian terkini mungkin sangat kompleks dan memakan masa, tetapi kesan penambahbaikan adalah minimum, jadi pengorbanan kos masa latihan anda sendiri untuk kesan yang boleh diabaikan tidak berbaloi. . Oleh itu, untuk menguasai model rangkaian klasifikasi imej, anda perlu tahu apakah itu dan mengapa ia supaya anda benar-benar boleh disasarkan apabila memilih model klasifikasi imej pada masa hadapan.
Pengenalan pengarang:
Bubur, editor komuniti 51CTO, pernah bekerja di jabatan teknologi data besar sebuah pusat penyelidikan dan pembangunan kecerdasan buatan e-dagang, melakukan algoritma pengesyoran. Pada masa ini terlibat dalam penyelidikan ke arah pemprosesan bahasa semula jadi bidang kepakaran utamanya termasuk algoritma cadangan, NLP, dan bahasa pengekodan yang digunakan termasuk Java, Python, dan Scala. Menerbitkan satu kertas persidangan ICCC.
Atas ialah kandungan terperinci Pengembangan teknologi aplikasi TensorFlow—pengkelasan imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI