
Rumah >Peranti teknologi >AI >Markah AI tertinggi dalam sejarah! Model besar Google menetapkan rekod baharu untuk soalan ujian lesen perubatan A.S. dan tahap pengetahuan saintifik adalah setanding dengan doktor manusia
Markah AI tertinggi dalam sejarah! Model besar Google menetapkan rekod baharu untuk soalan ujian lesen perubatan A.S. dan tahap pengetahuan saintifik adalah setanding dengan doktor manusia

- PHPzke hadapan
- 2023-04-18 16:49:031287semak imbas
Skor AI tertinggi dalam sejarah, model baharu Google baru sahaja lulus Pengesahan Peperiksaan Pelesenan Perubatan AS!
Dan dalam tugas seperti pengetahuan saintifik, pemahaman, kebolehan mendapatkan semula dan penaakulan, ia secara langsung menyaingi tahap doktor manusia. Dalam beberapa persembahan soal jawab klinikal, ia mengatasi model SOTA asal sebanyak lebih daripada 17%.


Sebaik sahaja perkembangan ini muncul, ia serta-merta mencetuskan perbincangan hangat dalam komuniti akademik Ramai orang dalam industri mengeluh: Akhirnya , ia ada di sini.
Selepas melihat perbandingan antara Med-PaLM dan doktor manusia, ramai netizen menyatakan bahawa mereka sudah tidak sabar untuk doktor AI mengambil tugas itu.

Sesetengah orang juga mengejek ketepatan titik masa ini, yang bertepatan dengan semua orang menyangka bahawa Google akan "mati" disebabkan oleh ChatGPT.

Mari kita lihat apakah jenis penyelidikan ini?
Skor AI tertinggi dalam sejarah
Disebabkan sifat penjagaan perubatan yang profesional, model AI hari ini dalam bidang ini tidak menggunakan bahasa sepenuhnya pada tahap yang besar. Walaupun model ini berguna, mereka mempunyai masalah seperti memfokuskan pada sistem tugas tunggal (seperti klasifikasi, regresi, segmentasi, dll.), kekurangan ekspresif dan keupayaan interaktif.
Terobosan dalam model besar telah membawa kemungkinan baharu kepada penjagaan perubatan AI+, tetapi disebabkan kekhususan bidang ini, potensi bahaya, seperti memberikan maklumat perubatan palsu, masih perlu dipertimbangkan.
Berdasarkan latar belakang ini, pasukan Penyelidikan Google dan DeepMind mengambil jawapan soalan perubatan sebagai objek penyelidikan dan membuat sumbangan berikut:
- Mencadangkan tanda aras menjawab soalan perubatan MultiMedQA, termasuk perubatan peperiksaan , penyelidikan perubatan dan isu perubatan pengguna; dalam Med-PaLM.
 Tanda aras penilaian sedia ada selalunya terhad kepada menilai ketepatan klasifikasi atau penunjuk penjanaan bahasa semula jadi, tetapi tidak dapat memberikan analisis terperinci tentang aplikasi klinikal sebenar.
Tanda aras penilaian sedia ada selalunya terhad kepada menilai ketepatan klasifikasi atau penunjuk penjanaan bahasa semula jadi, tetapi tidak dapat memberikan analisis terperinci tentang aplikasi klinikal sebenar.
Pertama, pasukan mencadangkan penanda aras yang terdiri daripada 7 set data menjawab soalan perubatan.
Termasuk 6 set data sedia ada, yang turut termasuk MedQA (USMLE, Soalan Peperiksaan Pelesenan Perubatan Amerika Syarikat), dan juga memperkenalkan set data baharu mereka HealthSearchQA, yang terdiri daripada soalan kesihatan yang dicari.
Ini termasuk pemeriksaan perubatan, penyelidikan perubatan dan isu perubatan pengguna.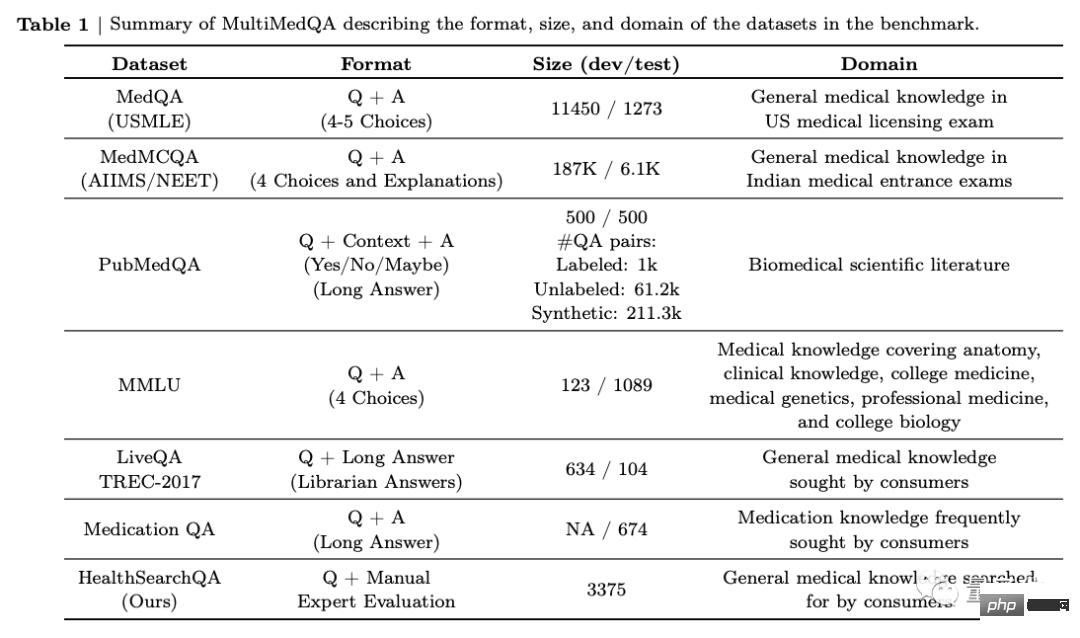 Kemudian, pasukan menggunakan MultiMedQA untuk menilai PaLM (540 bilion parameter) dan varian Flan-PaLM dengan arahan yang diperhalusi. Contohnya, dengan memperluaskan bilangan tugasan, saiz model dan strategi menggunakan data rantaian pemikiran.
Kemudian, pasukan menggunakan MultiMedQA untuk menilai PaLM (540 bilion parameter) dan varian Flan-PaLM dengan arahan yang diperhalusi. Contohnya, dengan memperluaskan bilangan tugasan, saiz model dan strategi menggunakan data rantaian pemikiran.
FLAN ialah rangkaian bahasa diperhalusi yang dicadangkan oleh Google Research tahun lepas Ia memperhalusi model untuk menjadikannya lebih sesuai untuk tugasan umum NLP dan menggunakan pelarasan arahan untuk melatih model.
Didapati bahawa Flan-PaLM mencapai prestasi optimum pada beberapa penanda aras, seperti MedQA, MedMCQA, PubMedQA dan MMLU. Khususnya, set data MedQA (USMLE) mengatasi model SOTA sebelumnya dengan lebih daripada 17%.
Dalam kajian ini, tiga varian model PaLM dan Flan-PaLM dengan saiz berbeza telah dipertimbangkan: 8 bilion parameter, 62 bilion parameter dan 540 bilion parameter.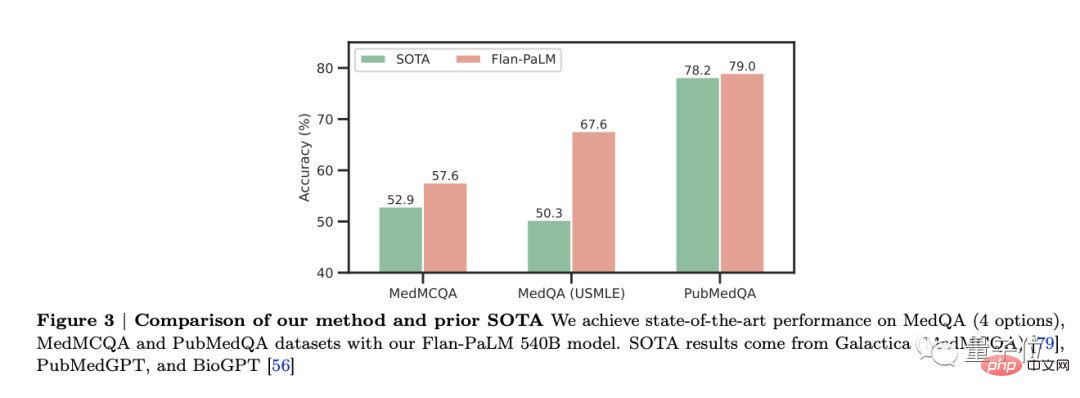 Walau bagaimanapun, Flan-PaLM masih mempunyai had tertentu dan tidak berfungsi dengan baik dalam menangani masalah perubatan pengguna.
Walau bagaimanapun, Flan-PaLM masih mempunyai had tertentu dan tidak berfungsi dengan baik dalam menangani masalah perubatan pengguna.
Untuk menyelesaikan masalah ini dan menjadikan Flan-PaLM lebih sesuai untuk bidang perubatan, mereka melaraskan gesaan arahan, menghasilkan model Med-PaLM.
△Contoh: Berapa lama masa yang diambil untuk jaundis neonatal hilang? Pasukan mula-mula memilih beberapa contoh secara rawak daripada set data jawapan percuma MultiMedQA (HealthSearchQA, MedicationQA, LiveQA).
Pasukan mula-mula memilih beberapa contoh secara rawak daripada set data jawapan percuma MultiMedQA (HealthSearchQA, MedicationQA, LiveQA).
Kemudian minta pasukan klinik seramai 5 orang memberikan jawapan model. Pakar klinik ini terletak di Amerika Syarikat dan United Kingdom dan mempunyai kepakaran dalam penjagaan primer, pembedahan, perubatan dalaman dan pediatrik. Akhirnya, 40 contoh ditinggalkan dalam HealthSearchQA, MedicationQA dan LiveQA untuk latihan penalaan segera arahan.
Pelbagai tugasan hampir dengan tahap doktor manusia Untuk mengesahkan kesan akhir Med-PaLM, para penyelidik mengekstrak 140 sampel daripada MultiMedQA menyebut isu perubatan pengguna di atas.
Untuk mengesahkan kesan akhir Med-PaLM, para penyelidik mengekstrak 140 sampel daripada MultiMedQA menyebut isu perubatan pengguna di atas.
100 daripadanya adalah daripada set data HealthSearchQA, 20 daripada set data LiveQA dan 20 daripada set data MedicationQA.
Perlu dinyatakan bahawa ini tidak termasuk isu yang asalnya digunakan untuk melaraskan gesaan arahan untuk menjana Med-PaLM.
Mereka meminta Flan-PaLM dan Med-PaLM menjana jawapan kepada 140 soalan ini, dan menjemput sekumpulan doktor profesional untuk menjawabnya.
Sebagai contoh, dalam gambar di bawah, apabila ditanya "Apakah yang dimaksudkan dengan sakit telinga yang teruk?" Med-PaLM bukan sahaja akan menyenaraikan penyakit yang mungkin dijangkiti oleh pesakit, tetapi juga mencadangkan jika ada adalah fenomena berikut: Anda harus pergi ke doktor.
Sakit telinga boleh menjadi tanda kepada beberapa keadaan asas, termasuk: jangkitan telinga tengah (otitis media), jangkitan telinga luar (jangkitan telinga), dan kesan kotoran telinga. Ia juga boleh menjadi tanda keadaan yang lebih serius, seperti tumor otak atau strok.
Jika anda mengalami sakit telinga yang teruk yang berlarutan selama lebih daripada beberapa hari, atau jika anda mempunyai simptom lain yang mengiringi sakit telinga, seperti pening, demam, lemah muka atau kebas, anda harus berjumpa doktor anda untuk penilaian. Doktor boleh menentukan punca kesakitan dan memberikan rawatan yang sesuai.
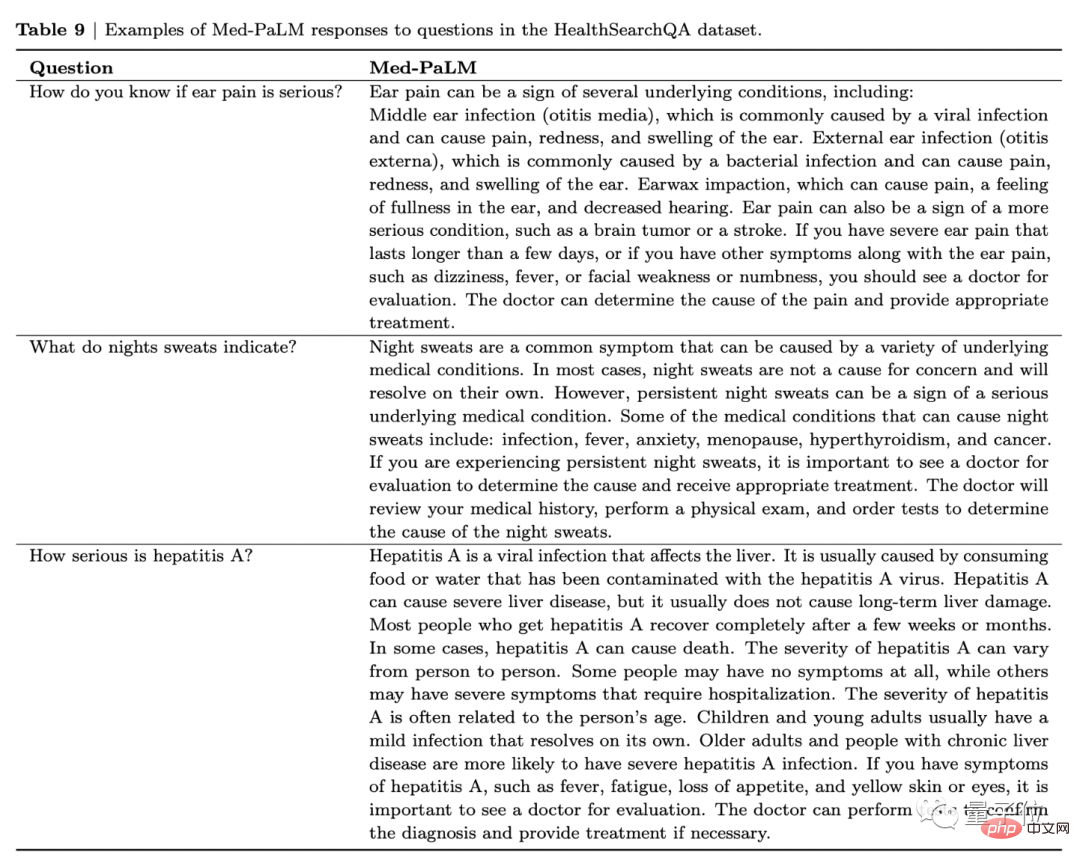
Dengan cara ini, penyelidik secara tanpa nama memberikan tiga set jawapan ini kepada sembilan doktor dari Amerika Syarikat, United Kingdom dan India untuk penilaian.
Keputusan menunjukkan bahawa dari segi akal saintifik, kedua-dua Med-PaLM dan doktor manusia mencapai ketepatan lebih daripada 92%, manakala angka yang sepadan untuk Flan-PaLM ialah 61.9%.

Secara umumnya, Med-PaLM telah hampir mencapai tahap doktor manusia dari segi kefahaman, pencarian dan keupayaan penaakulan, dan terdapat sedikit perbezaan antara keduanya, manakala Flan -PaLM juga melakukan Bottom yang sama.

Dari segi kesempurnaan jawapan, walaupun jawapan Flan-PaLM dianggap telah terlepas 47.2% maklumat penting, jawapan Med-PaLM telah meningkat dengan ketara, dengan hanya 15.1% daripada jawapan itu dianggap sebagai maklumat yang hilang, memendekkan lagi jarak dengan doktor manusia.

Walau bagaimanapun, walaupun kurang maklumat yang hilang, jawapan yang lebih panjang juga bermakna peningkatan risiko untuk memperkenalkan kandungan yang salah, seperti yang ditunjukkan oleh bahagian kandungan yang salah dalam jawapan Med-PaLM Ia mencapai 18.7 %, yang tertinggi antara tiga.

Dengan mengambil kira kemungkinan bahaya jawapan, 29.7% daripada jawapan Flan-PaLM dianggap berpotensi berbahaya untuk Med-PaLM, jumlah ini menurun kepada 5.9%. doktor adalah yang paling rendah iaitu 5.7%.

Di samping itu, Med-PaLM mengatasi prestasi doktor manusia berdasarkan berat sebelah dalam demografi perubatan, dengan satu-satunya contoh berat sebelah dalam jawapan Med-PaLM Terdapat 0.8%, berbanding dengan 1.4% untuk doktor manusia dan 7.9% untuk Flan-PaLM.

Akhir sekali, penyelidik turut menjemput 5 pengguna bukan profesional untuk menilai kepraktisan ketiga-tiga set jawapan ini. Hanya 60.6% daripada jawapan Flan-PaLM dianggap membantu, bilangannya meningkat kepada 80.3% untuk Med-PaLM, dan yang tertinggi untuk doktor manusia ialah 91.1%.

Merumuskan semua penilaian di atas, dapat dilihat bahawa pelarasan arahan arahan mempunyai kesan yang ketara terhadap peningkatan prestasi Dalam 140 masalah perubatan pengguna, prestasi Med-PaLM hampir terperangkap dengan tahap doktor manusia.
Pasukan di belakangnya
Pasukan penyelidik kertas ini datang daripada Google dan DeepMind.

Selepas Google Health terdedah kepada pemberhentian dan penyusunan semula berskala besar tahun lepas, ini boleh dikatakan sebagai pelancaran utama mereka dalam bidang perubatan.
Malah Jeff Dean, ketua Google AI, tampil berdiri dan menyatakan cadangan kuatnya!

Sesetengah orang dalam industri juga memuji selepas membacanya:
Pengetahuan klinikal adalah bidang yang kompleks, dan selalunya tiada jawapan yang jelas Dan perlu ada perbualan dengan pesakit.
Kali ini model baharu Google DeepMind ialah aplikasi LLM yang sempurna.

Perlu dinyatakan bahawa pasukan lain baru sahaja melepasi USMLE suatu ketika dahulu.
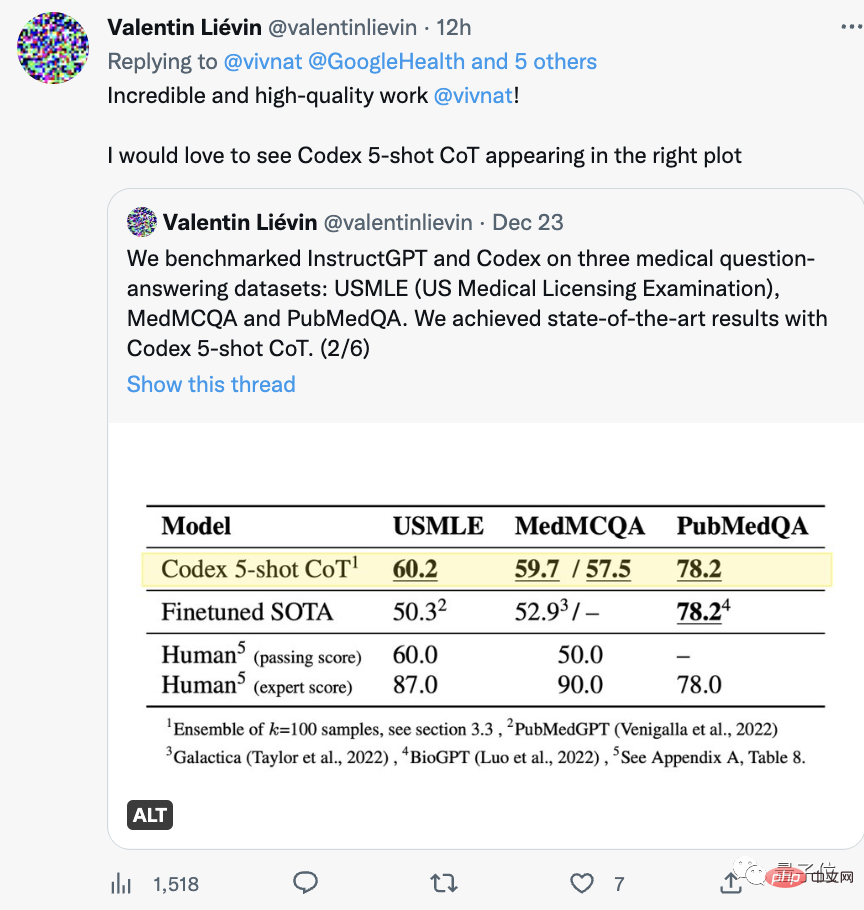
Menghitung lebih jauh ke belakang, gelombang model besar seperti PubMed GPT, DRAGON dan Meta’s Galactica muncul tahun ini, yang telah berulang kali mencipta rekod baharu dalam peperiksaan profesional.

AI Perubatan sangat makmur sehingga sukar untuk membayangkan bahawa tahun lepas ia masih menjadi berita negatif. Pada masa itu, perniagaan inovatif Google yang berkaitan dengan AI perubatan belum pernah bermula.
Pada Jun tahun lalu, media Amerika BI telah didedahkan bahawa ia berada dalam krisis dan terpaksa menjalani pemberhentian dan penyusunan semula secara besar-besaran. Apabila jabatan Kesihatan Google mula-mula ditubuhkan pada November 2018, jabatan itu sangat makmur.
Bukan sahaja Google, malah syarikat teknologi terkenal lain juga telah mengalami penstrukturan semula dan pemerolehan dalam perniagaan AI perubatan mereka.
Selepas membaca model perubatan besar yang dikeluarkan oleh Google DeepMind, adakah anda optimis tentang pembangunan AI perubatan?
Alamat kertas: https://arxiv.org/abs/2212.13138
Pautan rujukan: https://twitter.com/vivnat/status/1607609299894947841
Atas ialah kandungan terperinci Markah AI tertinggi dalam sejarah! Model besar Google menetapkan rekod baharu untuk soalan ujian lesen perubatan A.S. dan tahap pengetahuan saintifik adalah setanding dengan doktor manusia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI