
ホームページ >テクノロジー周辺機器 >AI >複数のSOTA! OV-Uni3DETR: カテゴリ、シーン、モダリティにわたる 3D 検出の汎用性の向上 (清華大学および HKU)
複数のSOTA! OV-Uni3DETR: カテゴリ、シーン、モダリティにわたる 3D 検出の汎用性の向上 (清華大学および HKU)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-11 19:46:18675ブラウズ
この文書では、3D ターゲット検出の分野、特に Open-Vocabulary の 3D ターゲット検出について説明します。従来の 3D オブジェクト検出タスクでは、システムは実際のシーン内のオブジェクトの 3D 境界ボックスとセマンティック カテゴリ ラベルの位置を予測する必要があり、通常は点群または RGB イメージに依存します。 2D 物体検出テクノロジはその普及性と速度により優れたパフォーマンスを発揮しますが、関連する調査によると、3D ユニバーサル検出の開発はそれに比べて遅れをとっています。現在、ほとんどの 3D オブジェクト検出方法は依然として完全教師あり学習に依存しており、特定の入力モード下で完全に注釈が付けられたデータによって制限されており、屋内シーンか屋外シーンかにかかわらず、トレーニング中に出現するカテゴリのみを認識できます。
この論文では、3D ユニバーサル オブジェクト検出が直面する課題には主に次のようなものがあると指摘しています。既存の 3D 検出器はクローズドな語彙集約でのみ機能するため、すでに見たことのあるカテゴリしか検出できません。 Open-Vocabulary の 3D オブジェクト検出は、トレーニング中に取得されなかった新しいクラス オブジェクト インスタンスを識別して特定するために緊急に必要です。既存の 3D 検出データセットは 2D データセットと比較してサイズとカテゴリが制限されているため、新しいオブジェクトの位置を特定する際の一般化能力が制限されています。さらに、3D ドメインには事前トレーニングされた画像テキスト モデルが存在しないため、Open-Vocabulary 3D 検出の課題はさらに悪化しています。同時に、マルチモーダル 3D 検出のための統一されたアーキテクチャが不足しており、既存の 3D 検出器は主に特定の入力モダリティ (点群、RGB 画像、またはその両方) 向けに設計されているため、データの効果的な利用が妨げられています。モダリティやシーン (屋内または屋外) が異なるため、新しいターゲットへの一般化能力が制限されます。
上記の問題を解決するために、この論文では OV-Uni3DETR と呼ばれる統合マルチモーダル 3D 検出器を提案します。検出器は、トレーニング中に、点群、正確な 3D ボックス アノテーションを含む点群と点群に位置合わせされた 3D 検出画像、2D ボックス アノテーションのみを含む 2D 検出画像などのマルチモーダルおよびマルチソース データを利用できます。このマルチモーダル学習方法により、OV-Uni3DETR は推論中にあらゆるモダリティのデータを処理し、テスト中にモーダル切り替えを実現し、基本カテゴリと新しいカテゴリの検出に優れたパフォーマンスを発揮できます。さらに、統合された構造により、OV-Uni3DETR は Open-Vocabulary 機能を使用して屋内および屋外のシーンで検出できるようになり、カテゴリ、シーン、モダリティ全体で 3D 検出器の汎用性が大幅に向上しました。
さらに、検出器を一般化して新しいカテゴリを認識する方法、および 3D ボックスの注釈なしで多数の 2D 検出画像から学習する方法という問題を目指して、この論文では周期モード伝播と呼ばれる方法を提案しています。アプローチ - このアプローチでは、2D モダリティと 3D モダリティの間で知識が分散され、両方の課題に対処します。このアプローチを通じて、2D 検出器の豊富な意味論的な知識を 3D ドメインに伝播して新しいボックスの発見を支援することができ、3D 検出器の幾何学的知識を使用して 2D 検出画像内のオブジェクトの位置を特定し、分類ラベルを照合することができます。マッチングを通じて。
この論文の主な貢献には、さまざまなモダリティおよび多様なシーンであらゆるカテゴリーのターゲットを検出できる統合オープンボキャブラリー 3D 検出器 OV-Uni3DETR の提案、屋内および屋外向けの統合オープンボキャブラリー 3D 検出器の提案が含まれます。マルチモーダル アーキテクチャ、および 2D モダリティと 3D モダリティ間の知識伝播サイクルの概念が提案されています。これらの革新により、OV-Uni3DETR は複数の 3D 検出タスクで最先端のパフォーマンスを達成し、Open-Vocabulary 設定で以前の方法を大幅に上回ります。これらの結果は、OV-Uni3DETR が将来の 3D 基本モデルの開発に重要な一歩を踏み出したことを示しています。
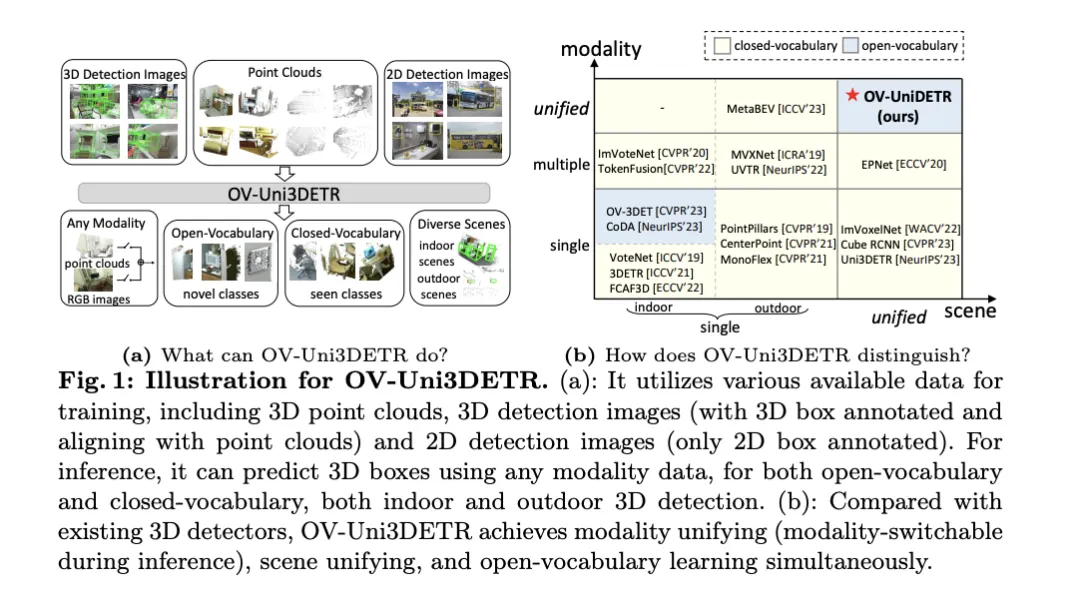
OV-Uni3DETR メソッドの詳細な説明
マルチモーダル学習
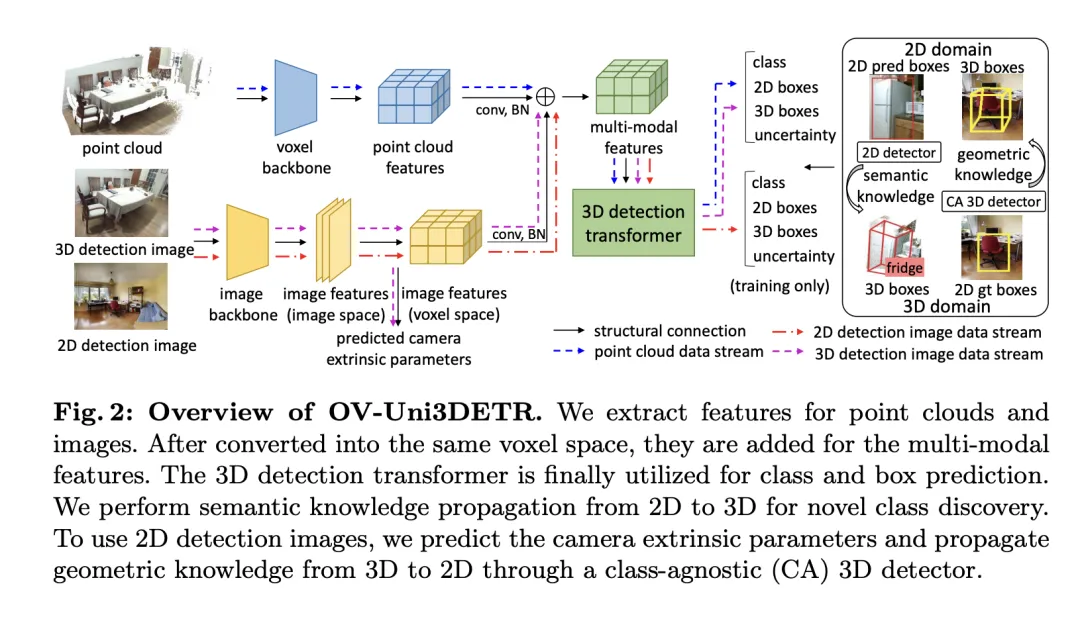
この記事では、クラウド データと画像データを統合することで検出パフォーマンスを向上させる、3D 物体検出タスクに特化したマルチモーダル学習フレームワークを紹介します。このフレームワークは、推論中に欠落している可能性がある特定のセンサー モダリティを処理できます。つまり、テスト中にモードを切り替える機能も備えています。 3D 点群特徴と 2D 画像特徴を含む 2 つの異なるモダリティからの特徴が特定のネットワーク構造を通じて抽出および統合され、要素処理とカメラ パラメーター マッピングの後、これらの特徴は後続のターゲット検出タスクのために融合されます。
主要な技術ポイントには、3D 畳み込みとバッチ正規化を使用して、さまざまなモードの機能を正規化および統合し、機能レベルでの不一致によって特定のモードが無視されるのを防ぐことが含まれます。さらに、モードをランダムに切り替えるトレーニング戦略により、モデルが 1 つのモードのみからのデータを柔軟に処理できるようになり、モデルの堅牢性と適応性が向上します。
最終的に、このアーキテクチャは、クラス予測からの損失、2D および 3D 境界ボックス回帰、重み付き回帰損失の不確実性予測を組み合わせた複合損失関数を利用して、検出プロセス全体を最適化します。このマルチモーダル学習手法は、既存のカテゴリの検出性能を向上させるだけでなく、異なる種類のデータを融合することで新しいカテゴリへの汎化能力も強化します。マルチモーダル アーキテクチャは、最終的に、2D および 3D オブジェクト検出のためのクラス ラベル、4D 2D ボックス、および 7D 3D ボックスを予測します。 3D ボックス回帰の場合は、L1 損失と分離された IoU 損失が使用され、2D ボックス回帰の場合は、L1 損失と GioU 損失が使用されます。 Open-Vocabulary 設定では、新しいカテゴリのサンプルがあり、サンプルのトレーニングの難易度が高くなります。したがって、不確実性予測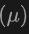 が導入され、L1回帰損失の重み付けに使用されます。物体検出学習の損失は次のとおりです。
が導入され、L1回帰損失の重み付けに使用されます。物体検出学習の損失は次のとおりです。
一部の 3D シーンでは、単一の単眼画像ではなく多視点画像が存在する場合があります。それらのそれぞれについて、画像特徴が抽出され、それぞれの投影行列を使用してボクセル空間に投影されます。ボクセル空間内の複数の画像特徴が合計されて、マルチモーダル特徴が取得されます。このアプローチにより、新しいカテゴリへのモデルの一般化能力が向上し、さまざまなモダリティからの情報を組み合わせることで、多様な入力条件下での適応性が強化されます。
知識伝播: 2D—3D
導入されたマルチモーダル学習に基づいて、この記事では、Open-Vocabulary の 3D 検出のための「知識伝播」と呼ばれる方法を実装します。伝播:  」メソッド。 Open-Vocabulary 学習の中心的な問題は、トレーニング プロセス中に手動でラベル付けされていない新しいカテゴリを特定することです。点群データの取得が難しいため、点群分野では事前トレーニング済みの視覚言語モデルはまだ開発されていません。点群データと RGB 画像の間のモーダルな違いにより、3D 検出におけるこれらのモデルのパフォーマンスが制限されます。
」メソッド。 Open-Vocabulary 学習の中心的な問題は、トレーニング プロセス中に手動でラベル付けされていない新しいカテゴリを特定することです。点群データの取得が難しいため、点群分野では事前トレーニング済みの視覚言語モデルはまだ開発されていません。点群データと RGB 画像の間のモーダルな違いにより、3D 検出におけるこれらのモデルのパフォーマンスが制限されます。

この問題を解決するために、事前トレーニングされた 2D オープンボキャブラリ検出器の意味論的な知識を利用し、新しいカテゴリに対応する 3D 境界ボックスを生成することを提案します。これらの生成された 3D ボックスは、トレーニング中に利用できる限られた 3D グラウンドトゥルース ラベルを補完します。
具体的には、2D バウンディング ボックスまたはインスタンス マスクは、最初に 2DOpen-Vocabulary 検出器を使用して生成されます。 2D ドメインで利用できるデータと注釈がより豊富であることを考慮すると、これらの生成された 2D ボックスはより高い位置精度を実現し、より広範囲のカテゴリをカバーできます。次に、これらの 2D ボックスは 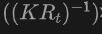 によって 3D 空間に投影され、対応する 3D ボックスが得られます。具体的な操作は、
によって 3D 空間に投影され、対応する 3D ボックスが得られます。具体的な操作は、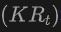
を使用して 3D 点を 2D 空間に投影し、2D ボックス内で点を見つけ、2D ボックス内でこれらの点をクラスタリングして外れ値を除去し、それによって対応する 3D フレームを取得することです。 。事前にトレーニングされた 2D 検出器が存在するため、生成された 3D ボックス セット内で新しいラベルのないオブジェクトを検出できます。このようにして、3DOpen-Vocabulary の検出は、2D ドメインから生成された 3D ボックスに伝播される豊富な意味論的な知識によって非常に容易になります。マルチビュー画像の場合、3D ボックスは個別に生成され、最終的に使用するために統合されます。
推論中に、点群と画像の両方が利用可能な場合は、同様の方法で 3D ボックスを抽出できます。これら生成された 3D ボックスも 3DOpen-Vocabulary の検出結果の一種とみなすことができます。これらの 3D ボックスは、マルチモーダル 3D トランスフォーマーの予測に追加され、欠落している可能性のあるオブジェクトを補完し、3D 非最大抑制 (NMS) を介して重複する境界ボックスをフィルターします。事前トレーニングされた 2D 検出器によって割り当てられた信頼スコアは、体系的に所定の定数で除算され、対応する 3D ボックスの信頼スコアとして再解釈されます。 #########実験###############
この表は、SUN RGB-D および ScanNet データセットでの Open-Vocabulary3D オブジェクト検出に対する OV-Uni3DETR のパフォーマンスを示しています。実験設定は CoDA とまったく同じで、使用されるデータは正式にリリースされた CoDA コードからのものです。パフォーマンス指標には、新しいカテゴリの平均精度 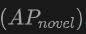 、基本クラスの平均精度
、基本クラスの平均精度 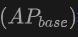 、およびすべてのクラスの平均精度
、およびすべてのクラスの平均精度 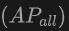 が含まれます。入力タイプには、点群 (P)、画像 (I)、およびそれらの組み合わせ (PI) が含まれます。
が含まれます。入力タイプには、点群 (P)、画像 (I)、およびそれらの組み合わせ (PI) が含まれます。
これらの結果を分析すると、次の点がわかります:
-
マルチモーダル入力の利点: 点群と画像の組み合わせを入力として使用する場合その時点で、OV-Uni3DETR は 2 つのデータセットのすべての評価指標で最高のスコアを達成し、特に新しいカテゴリの平均精度
 で最も顕著な改善を達成しました。これは、点群と画像を組み合わせることで、モデルの未知のクラスを検出する能力と全体的な検出パフォーマンスを大幅に向上できることを示しています。
で最も顕著な改善を達成しました。これは、点群と画像を組み合わせることで、モデルの未知のクラスを検出する能力と全体的な検出パフォーマンスを大幅に向上できることを示しています。 - 他の方法との比較: 他の点群ベースの方法 (Det-PointCLIP、Det-PointCLIPv2、Det-CLIP、3D-CLIP、およびCoDA )、OV-Uni3DETR はすべての評価指標において優れたパフォーマンスを示します。これは、Open-Vocabulary3D オブジェクト検出タスクの処理、特にマルチモーダル学習および知識普及戦略の活用における OV-Uni3DETR の有効性を示しています。
- 画像と点群入力の比較: 画像 (I) のみを入力として使用する OV-Uni3DETR は、点群 (P) を入力として使用するよりもパフォーマンスが低くなりますが、それでも良好な検出を示します能力。これは、単一モーダル データに対する OV-Uni3DETR アーキテクチャの柔軟性と適応性を証明するとともに、検出パフォーマンスを向上させるために複数のモーダル データを融合することの重要性も強調しています。
-
新しいカテゴリでのパフォーマンス: 新しいカテゴリの平均精度に関する OV-Uni3DETR のパフォーマンスは特に注目に値します。これは、オープンボキャブラリの検出にとって特に重要です。 SUN RGB-D データセットでは、 は点群と画像入力を使用した場合に 12.96% を達成し、ScanNet データセットでは 15.21% を達成しましたが、これは他の方法よりも大幅に高く、認識トレーニング プロセスの改善を示しています。これまでにないカテゴリーで。
 で最も顕著な改善を達成しました。これは、点群と画像を組み合わせることで、モデルの未知のクラスを検出する能力と全体的な検出パフォーマンスを大幅に向上できることを示しています。
で最も顕著な改善を達成しました。これは、点群と画像を組み合わせることで、モデルの未知のクラスを検出する能力と全体的な検出パフォーマンスを大幅に向上できることを示しています。  は特に注目に値します。これは、オープンボキャブラリの検出にとって特に重要です。 SUN RGB-D データセットでは、
は特に注目に値します。これは、オープンボキャブラリの検出にとって特に重要です。 SUN RGB-D データセットでは、 は点群と画像入力を使用した場合に 12.96% を達成し、ScanNet データセットでは 15.21% を達成しましたが、これは他の方法よりも大幅に高く、認識トレーニング プロセスの改善を示しています。これまでにないカテゴリーで。
は点群と画像入力を使用した場合に 12.96% を達成し、ScanNet データセットでは 15.21% を達成しましたが、これは他の方法よりも大幅に高く、認識トレーニング プロセスの改善を示しています。これまでにないカテゴリーで。 全体として、OV-Uni3DETR は、統合されたマルチモーダル学習アーキテクチャを通じて、特に点群と画像データを組み合わせる場合に、Open-Vocabulary3D オブジェクト検出タスクで優れたパフォーマンスを示します。同時に、効果的にパフォーマンスを向上させることができます。新しいカテゴリの検出能力、マルチモーダルなインプットと知識普及戦略の有効性と重要性を証明します。
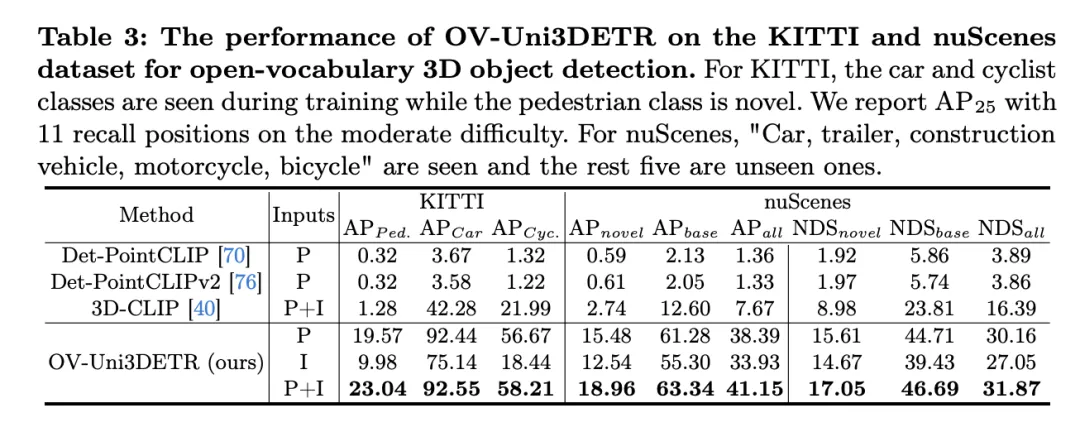
この表は、KITTI および nuScenes データセットでの Open-Vocabulary3D オブジェクト検出に対する OV-Uni3DETR のパフォーマンスを示しており、トレーニング プロセス (ベース) および小説カテゴリー。 KITTI データセットの場合、「自動車」と「自転車」カテゴリはトレーニング中に見られましたが、「歩行者」カテゴリは新規です。パフォーマンスは、中程度の難易度で 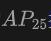
メトリクスを使用し、11 のリコール位置を使用して測定されます。 nuScenes データセットの場合、「自動車、トレーラー、建設車両、オートバイ、自転車」は表示されるカテゴリであり、残りの 5 つは未表示のカテゴリです。 AP指標に加えて、検出性能を総合的に評価するNDS(NuScenes Detection Score)も報告されています。
これらの結果を分析すると、次の結論が導き出されます:
- マルチモーダル入力の大きな利点: 点群 (P) または画像 (I) のみを入力として使用する場合と比較して、点群と画像 (P I ) の両方を入力として使用する場合は、 OV-Uni3DETR は、すべての評価指標で最高のスコアを達成しました。この結果は、目に見えないカテゴリの検出機能と全体的な検出パフォーマンスの向上におけるマルチモーダル学習の重要な利点を強調しています。
- オープンボキャブラリ検出の有効性: OV-Uni3DETR は、目に見えないカテゴリ、特に KITTI データセットの「歩行者」カテゴリと「小説」に関する nuScenes データセットを処理するときに優れたパフォーマンスを示します。 " カテゴリー。これは、このモデルが新しいカテゴリに対する強力な一般化能力を備えており、有効なオープンボキャブラリ検出ソリューションであることを示しています。
- 他の方法との比較: 他の点群ベースの方法 (Det-PointCLIP、Det-PointCLIPv2、3D-CLIP など) と比較すると、OV-Uni3DETR はパフォーマンスが大幅に向上しています。見えるカテゴリーと見えないカテゴリーの検出。これは、Open-Vocabulary3D オブジェクト検出タスクの処理における進歩を示しています。
- 画像入力と点群入力の比較: 画像入力を使用した場合のパフォーマンスは点群入力を使用した場合よりも若干劣りますが、画像入力は依然として比較的高い検出精度を提供できます。これは、OV-Uni3DETR アーキテクチャの適応性と柔軟性を示していることを示しています。
- 総合評価指標: NDS評価指標の結果から、OV-Uni3DETRは認識精度だけでなく、総合的な検出品質においても高い結果を達成していることがわかります。特に点群と画像データを組み合わせる場合のスコア。
OV-Uni3DETR は、Open-Vocabulary3D オブジェクト検出、特に目に見えないカテゴリやマルチモーダル データの処理において優れたパフォーマンスを示します。これらの結果は、マルチモーダル入力と知識普及戦略の有効性、および 3D オブジェクト検出タスクの汎化能力の向上における OV-Uni3DETR の可能性を検証します。
ディスカッション

この論文は、Open Vocabulary に大きな進歩をもたらした統合マルチモーダル 3D 検出器である OV-Uni3DETR を提案します。 3D 物体検出の分野で。この方法では、マルチモーダル データ (点群と画像) を利用して検出パフォーマンスを向上させ、2D から 3D への知識普及戦略を通じて、目に見えないカテゴリに対するモデルの認識機能を効果的に拡張します。複数の公開データセットでの実験結果は、特に点群と画像入力を組み合わせた場合に、新しいクラスと基本クラスでの OV-Uni3DETR の優れたパフォーマンスを示しています。これにより、新しいクラスの検出能力が大幅に向上すると同時に、全体的な検出パフォーマンスも新しいレベルに達しています。身長。
利点の点では、OV-Uni3DETR は、3D ターゲット検出パフォーマンスの向上におけるマルチモーダル学習の可能性を初めて実証しました。点群データと画像データを統合することにより、モデルは各モダリティから補完的な特徴を学習できるため、豊富なシーンと多様なターゲット カテゴリでより正確な検出が可能になります。次に、2D から 3D への知識伝達メカニズムを導入することにより、OV-Uni3DETR は豊富な 2D 画像データと事前トレーニングされた 2D 検出モデルを利用して、トレーニング プロセス中には見られなかった新しいカテゴリを識別および特定できるようになり、モデルの一般化、化能力。さらに、この方法はオープンボキャブラリ検出の処理において強力な機能を示し、3D 検出の分野に新しい研究の方向性と潜在的なアプリケーションをもたらします。
欠点に関しては、OV-Uni3DETR は多くの面で利点を実証していますが、潜在的な制限もいくつかあります。まず、マルチモーダル学習はパフォーマンスを向上させることができますが、データの取得と処理の複雑さも増加します。特に実際のアプリケーションでは、異なるモーダル データの同期と登録が課題となる可能性があります。第 2 に、知識普及戦略では 2D データを効果的に利用して 3D 検出を支援できますが、この方法は高品質の 2D 検出モデルと正確な 3D-2D アライメント技術に依存する可能性があり、一部の複雑な環境では保証が難しい場合があります。さらに、一部の非常にまれなカテゴリでは、オープンボキャブラリの検出でも認識精度の課題に直面する可能性があり、解決するにはさらなる研究が必要です。
OV-Uni3DETR は、革新的なマルチモーダル学習および知識普及戦略を通じて、Open-Vocabulary3D オブジェクト検出において大きな進歩を遂げました。潜在的な制限はいくつかありますが、その利点は、3D 検査技術の開発と用途拡大を促進する上で、この方法の大きな可能性を示しています。今後の研究では、これらの制限を克服する方法と、これらの戦略をより広範囲の 3D 認識タスクに適用する方法をさらに検討することができます。
結論
この論文では、主に統合マルチモーダルオープンボキャブラリー 3D 検出器である OV-Uni3DETR を提案しました。マルチモーダル学習と循環モーダル知識普及の助けを借りて、OV-Uni3DETR は新しいクラスを適切に識別して特定し、モーダルの統合とシーンの統合を実現します。実験では、オープンとクローズの両方の語彙環境、屋内と屋外の両方のシーン、およびあらゆるモーダル データ入力において、その強力な機能が実証されています。マルチモーダル環境における統一されたオープン語彙の 3D 検出をターゲットとする私たちの研究は、一般的な 3D コンピュータ ビジョンの有望だが困難な方向に沿ってその後の研究を推進すると信じています。
以上が複数のSOTA! OV-Uni3DETR: カテゴリ、シーン、モダリティにわたる 3D 検出の汎用性の向上 (清華大学および HKU)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。