
ホームページ >テクノロジー周辺機器 >AI >全部広める? 3DifFusionDet: 拡散モデルが LV fusion 3D ターゲット検出に加わりました!
全部広める? 3DifFusionDet: 拡散モデルが LV fusion 3D ターゲット検出に加わりました!

- 王林転載
- 2023-12-14 16:51:58783ブラウズ
著者の個人的な理解
近年、拡散モデルは生成タスクで非常に成功しており、当然のことながらターゲット検出タスクにも拡張されています。ノイズ ボックス (ノイジー ボックス) からオブジェクト ボックス (オブジェクト ボックス) へのノイズ除去拡散プロセス。トレーニング フェーズでは、ターゲット ボックスがグラウンド トゥルース ボックスからランダム分布に拡散され、モデルはグラウンド トゥルース ボックスにノイズを追加するこのプロセスを逆転する方法を学習します。推論段階では、モデルはランダムに生成されたターゲット ボックスのセットを段階的に出力結果に絞り込みます。学習可能なクエリの固定セットに依存する従来のオブジェクト検出方法と比較して、3DifFusionDet はオブジェクト検出に学習可能なクエリを必要としません。
3DifFusionDet の主なアイデア
3DifFusionDet フレームワークは、ノイズの多い 3D ボックスからターゲット ボックスへのノイズ除去拡散プロセスとして 3D ターゲット検出を表します。このフレームワークでは、グラウンド トゥルース ボックスがランダム分布拡散でトレーニングされ、モデルは逆ノイズ プロセスを学習します。推論中、モデルはランダムに生成されたボックスのセットを徐々に改良します。フィーチャ アライメント戦略の下では、プログレッシブ リファインメント手法は LIDAR とカメラの融合に重要な貢献をすることができます。反復改良プロセスは、さまざまなレベルの精度と速度を必要とするさまざまな検出環境にフレームワークを適用することで、優れた適応性も示します。 KITTI は、実際の交通ターゲット認識のベンチマークです。KITTI に対して多数の実験が行われ、初期の検出器と比較して、KITTI が優れたパフォーマンスを達成できることが示されています。
3DifFusionDet の主な貢献は次のとおりです:
- 3D ターゲット検出を生成ノイズ除去プロセスとして表し、拡散モデルを 3D ターゲット検出に適用する最初の研究である 3DifFusionDet を提案します。
- 生成ノイズ除去プロセスの枠組みの下での最適なカメラ-LiDAR融合アライメント戦略が研究され、2つのモダリティによって提供される補完的な情報を利用するために2つのブランチ融合アライメント戦略が提案されました。
- KITTI ベンチマークに関して広範な実験が行われました。既存の適切に設計された手法と比較して、3DifFusionDet は競合する結果を達成し、3D オブジェクト検出タスクにおける拡散モデルの有望性を実証しています。
3D ターゲット検出に LiDAR とカメラの融合を使用する
3D ターゲット検出では、カメラと LiDAR は 2 つの補完的なセンサー タイプです。 LiDAR センサーは 3D ローカリゼーションに焦点を当て、3D 構造に関する豊富な情報を提供します。一方、カメラは豊富なセマンティック特徴を導き出すことができる色情報を提供します。カメラと LiDAR からのデータを融合することで 3D オブジェクトを正確に検出するために多くの努力が払われてきました。 LiDAR ベースの検出方法のパフォーマンスはカメラのパフォーマンスよりも大幅に優れているため、最先端の方法は主に LiDAR ベースの 3D 物体検出器に基づいており、LiDAR 検出プロセスのさまざまな段階に画像情報を組み込むよう努めています。ベースのメソッド。 LIDAR ベースとカメラベースの検出システムは複雑であるため、2 つのモードを組み合わせると、必然的に計算コストと推論時間の遅延が増加します。したがって、マルチモーダルな情報を効果的に融合するという問題が残っています。
拡散モデル
拡散モデルは、ノイズを導入することで観測データを徐々に分解し、プロセスを逆に行うことで元のデータを復元する生成モデルです。拡散モデルとノイズ除去スコア マッチングは、最近コンピューター ビジョン アプリケーションへの関心を引き起こしているノイズ除去拡散確率モデル (Ho、Jain、および Abbeel 2020a) を通じて接続されています。グラフ生成、言語理解、ロバスト学習、時間データモデリングなど、多くの分野で応用されています。
拡散モデルは、画像の生成と合成において大きな成功を収めています。一部の先駆的な作品では、画像セグメンテーション タスクに拡散モデルを採用しています。これらの分野と比較すると、物体検出の可能性はまだ十分に活用されていません。拡散モデルを使用した物体検出へのこれまでのアプローチは、2D 境界ボックスに限定されていました。 2D 検出と比較して、3D 検出はより豊富なターゲット空間情報を提供し、周囲の車両との正確な距離を特定する必要がある自動運転などのアプリケーションにとって重要な、正確な奥行き知覚と体積の理解を実現できます。自動運転などの用途に。
3DifFusionDet のネットワーク設計
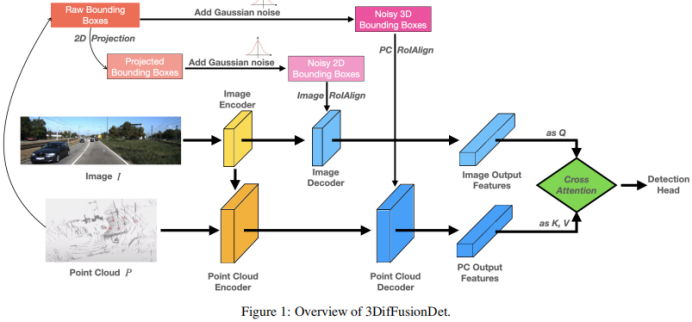
図 1 は、3DifFusionDet の全体的なアーキテクチャを示しています。 RGB 画像や点群などのマルチモーダル入力を受け入れます。 DiffusionDet のように、モデル全体を特徴抽出部分と特徴デコード部分に分割すると、反復ステップごとに元の 3D 特徴に 直接適用することが困難になります。特徴抽出部分は元の入力 X から深い特徴表現を抽出するために 1 回だけ実行されますが、特徴デコード コンポーネントはこの深い特徴に基づいて条件付けされ、ノイズの多いボックスから徐々にボックス予測を描画するようにトレーニングされます。 2 つのモダリティによって提供される補完的な情報を最大限に活用するために、各モダリティのエンコーダとデコーダは分離されています。さらに、画像デコーダと点群デコーダは、拡散モデルを使用して 2D および 3D の特徴を洗練するように個別にトレーニングされ、それぞれノイズ ボックスを生成します。この 2 つの機能ブランチの接続については、単純に接続すると情報の共有が発生し、パフォーマンスが低下します。この目的を達成するために、これらの機能を深く調整するために、マルチヘッド クロス アテンション メカニズムが導入されています。これらの位置合わせされた特徴は検出ヘッドに入力され、ノイズを発生させることなく最終的な真の値を予測します。
点群エンコーダの場合、抽出にはボクセルベースの方法が使用され、処理にはスパースベースの方法が使用されます。ボクセルベースの方法は、LiDAR ポイントをボクセルに変換します。他の一連の点特徴抽出方法 (ポイントベースの方法など) と比較して、これらの方法は点群を等間隔の 3D グリッドに離散化し、元の 3D 形状情報を可能な限り保持しながらメモリ要件を削減します。スパースベースの処理方法は、ネットワークの計算効率の向上にさらに役立ちます。これらの利点により、拡散モデルの比較的高い計算要件のバランスがとれます。
2D フィーチャと比較して、3D フィーチャには余分な寸法が含まれるため、学習がより困難になります。これを念頭に置いて、元のモダリティからの特徴の抽出に加えて、抽出された画像特徴をポイント エンコーダーへの別の入力として追加する融合パスが追加され、情報交換が容易になり、より多様なソースからの学習が活用されます。 PointFusion 戦略が採用されており、LiDAR センサーからのポイントが画像平面に投影されます。画像の特徴と対応する点の連結は、VoxelNet アーキテクチャによって共同処理されます。
機能デコーダ。抽出された画像特徴および抽出された点特徴は、対応する画像および点デコーダへの入力として使用されます。各デコーダは、独自に作成されたノイズ ボックス または からの入力も結合し、対応する抽出された特徴に加えて、2D 特徴と 3D 特徴をそれぞれ改良することを学習します。
Sparse RCNN からインスピレーションを得た画像デコーダーは、2D 提案ボックスのコレクションから入力を受け取り、画像エンコーダーによって作成された特徴マップから RoI 特徴を切り取ります。ポイント デコーダは、3D プロポーザル ボックスのコレクションから入力を受け取り、イメージ エンコーダによって作成された特徴マップから RoI 特徴を切り取ります。ポイント デコーダの場合、入力は、ポイント エンコーダ
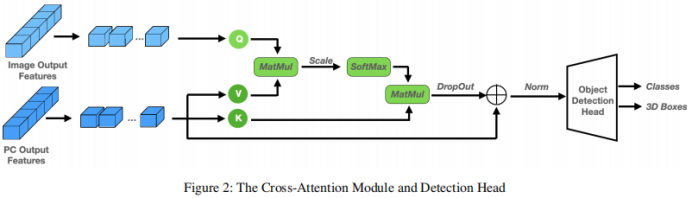
クロス アテンション モジュールによって生成された特徴マップから 3D RoI 特徴を切り出すために使用される 3D プロポーザル ボックスのセットです。 2 つの機能ブランチをデコードした後、それらを結合する方法が必要です。簡単なアプローチは、2 つの機能ブランチを単純に接続することです。この方法は大雑把すぎるように見え、モデルに情報のせん断が発生し、パフォーマンスの低下につながる可能性があります。したがって、図 1 に示すように、これらの機能を深く調整して洗練させるために、マルチヘッド クロスアテンション メカニズムが導入されています。具体的には、ポイント デコーダの出力は k と v のソースとして扱われ、イメージ デコーダの出力は q に投影されます。
#実験結果
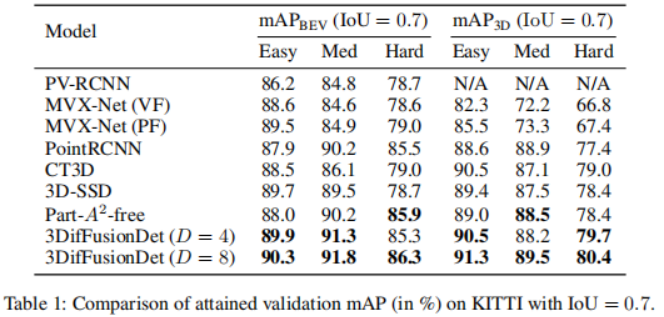
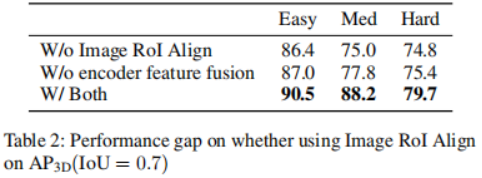
実験は、KITTI 3D 物体検出ベンチマークで実施されました。検出性能を測定するための標準的な KITTI 評価プロトコル (IoU = 0.7) に従って、表 1 に、KITTI 検証セットの最先端のメソッドと比較した 3DifFusionDet メソッドの平均精度 (mAP) スコアを示します。パフォーマンスは、[diffusionDet、difficileist] に従って、タスクごとに最もパフォーマンスの高い 2 つのモデルを太字にして報告されます。表 1 の結果によると、この研究の方法はベースラインと比較して大幅なパフォーマンスの向上を示しています。 D=4 の場合、この方法はより短い推論時間でほとんどのベースライン モデルを超えることができます。さらに D を 8 に増やすと、推論時間は長くなりますが、すべてのモデルの中で最高のパフォーマンスが得られます。この柔軟性により、この方法には幅広い応用可能性があることがわかります。拡散モデルを使用してカメラと LiDAR から 3D オブジェクト検出器を設計する場合、最も簡単なアプローチは、生成されたノイズを含む 3D ボックスを入力として融合 3D フィーチャに直接適用することです。ただし、このアプローチでは情報の共有が発生し、表 2 に示すようにパフォーマンスが低下する可能性があります。これを使用して、点群 RoIAlign をエンコードされた 3D フィーチャの下に配置することに加えて、画像 RoIAlign をエンコードされた 2D フィーチャの下に配置する 2 番目のブランチも作成します。パフォーマンスが大幅に向上したことは、両方のモードによって提供される補完的な情報をより有効に活用できることを示唆しています。
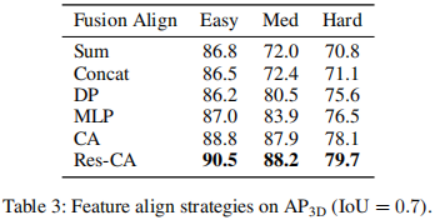
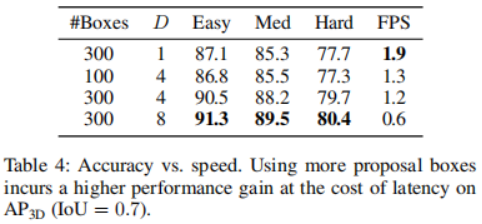
次に、さまざまな融合戦略の影響を分析します。学習した 2D および 3D 表現の特徴を考慮して、それらをより効果的に組み合わせるにはどうすればよいかを分析します。 2D フィーチャと比較して、3D フィーチャには余分な次元があるため、学習プロセスがより困難になります。 LiDAR センサーからの点を画像特徴上に投影し、それらを共同処理される対応する点と連結することにより、画像特徴から点特徴への情報フロー パスを追加します。これが VoxelNet アーキテクチャです。表 3 からわかるように、この融合戦略には検出精度の面で大きな利点があります。融合する必要があるもう 1 つの部分は、デコード後の 2 つの特徴ブランチの接続です。ここでは、マルチヘッド クロス アテンション メカニズムを適用して、これらの特徴を深く調整し、洗練させます。これに加えて、連結演算、総和演算、直接積演算、多層パーセプトロン(MLP)の使用など、より直接的な方法も研究されています。結果を表4に示す。その中でも、クロスアテンション メカニズムは、ほぼ同じ学習速度と推論速度で最高のパフォーマンスを示します。精度と推論速度のトレードオフを検討します。さまざまな提案ボックスと D を選択した場合の影響は、3D 検出精度と 1 秒あたりのフレーム数 (FPS) を比較することで示されます。提案ボックスの数は 100、300 から選択され、D は 1、4、8 から選択されます。実行時間は、バッチ サイズ 1 の単一の NVIDIA RTX A6000 GPU で評価されます。提案ボックスの数を 100 から 300 に増やすと、レイテンシ コストが無視できる程度で精度が大幅に向上することがわかりました (1.3 FPS 対 1.2 FPS)。一方で、検出精度が向上すると推論時間が長くなります。 D を 1 から 8 に変更すると、3D 検出精度はシャープ (Easy: 87.1 mAP から 90.5 mAP) から比較的ゆっくり (Easy: 90.5 AP から 91.3 mAP) まで増加しますが、FPS は減少し続けます。
事例研究と今後の取り組み この記事では、3DifFusionDet のユニークな特性に基づいて、3DifFusionDet の潜在的な用途について説明します。一般に、物体検出タスクには、正確、堅牢、およびリアルタイム推論の 3 つの要件があります。自動運転車の認識の分野では、高速で走行する車は慣性により速度を落としたり方向を変えるために余分な時間と距離を費やす必要があることを考慮すると、認識モデルはリアルタイム要件に特に敏感です。さらに重要なことは、快適な乗り心地を実現するためには、安全を前提にできるだけ加速度の絶対値を小さくしてスムーズに走行することです。その主な利点の 1 つは、他の同様の自動運転車製品と比較して、スムーズな乗り心地です。そのためには、自動運転車は加速、減速、方向転換のいずれにおいても迅速に反応し始める必要があります。車の反応が速ければ速いほど、その後の操作や調整のための余地が大きくなります。これは、検出されたターゲットの最も正確な分類や位置を最初に取得することよりも重要です。車が反応し始めても、車の動作を調整するための時間と距離がまだあり、それを使用して、より正確な判断を下すことができます。外挿された結果は、車の運転挙動を微調整するために使用されます。
書き換えた内容は次のとおりです。 表 4 の結果によると、推論ステップ サイズが小さい場合、3DifFusionDet モデルは推論を高速に実行でき、比較的高い精度が得られます。この最初の認識は、自動運転車が新たな反応を開発できるほど正確です。推論ステップの数が増えるにつれて、より正確な物体検出を生成し、応答をさらに微調整することができます。この検出に対する進歩的なアプローチは、私たちのタスクに理想的に適しています。さらに、このモデルは推論中に提案ボックスの数を調整できるため、小さなステップから得られた事前情報を活用して、リアルタイムの提案ボックスの数を最適化できます。表 4 の結果によれば、異なるアプリオリ提案フレームの下でのパフォーマンスも異なります。したがって、このような適応検出器の開発は有望な仕事です。
自動運転車に加えて、私たちのモデルは基本的に、連続反応空間での短い推論時間を必要とする現実的なシナリオ、特に検出器がベースで移動するシナリオに一致します。検出結果について。拡散モデルの特性を利用して、3DifFusionDet はほぼ正確な実空間の関心領域を迅速に見つけて、マシンに新しい操作と自己最適化を開始させることができます。後続の高精度パーセプトロンにより、マシンの動作がさらに微調整されます。これらの動き検出器にモデルを展開するための未解決の質問の 1 つは、より大きなステップでの以前の推論とより小さなステップでのより最近の推論の間の推論情報を組み合わせる戦略であり、これもまた未解決の質問です。
#要約
この記事では、強力な LiDAR およびカメラ フュージョン機能を備えた 3DifFusionDet と呼ばれる新しい 3D オブジェクト検出器を紹介します。 3D オブジェクト検出を生成ノイズ除去プロセスとして定式化することで、これは 3D オブジェクト検出に拡散モデルを適用した最初の研究です。この研究では、ノイズ除去プロセス フレームワークの生成に関連して、最も効果的なカメラ LIDAR フュージョン アライメント戦略を検討し、両方のモードによって提供される補完的な情報を最大限に活用するためのフュージョン アライメント戦略を提案します。成熟した検出器と比較して、3DifFusionDet は良好なパフォーマンスを示し、物体検出タスクにおける拡散モデルの幅広い応用の見通しを示しています。その強力な学習結果と柔軟な推論モデルにより、幅広い用途が可能になります
以上が全部広める? 3DifFusionDet: 拡散モデルが LV fusion 3D ターゲット検出に加わりました!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。