
ホームページ >テクノロジー周辺機器 >AI >エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2024-04-11 20:52:211286ブラウズ
大規模モデルの継続的な最適化に基づいて、LLM エージェント - これらの強力なアルゴリズム エンティティは、複雑な複数ステップの推論タスクを解決できる可能性を示しています。自然言語処理から深層学習に至るまで、LLM エージェントは徐々に研究や業界の焦点になりつつあります。LLM エージェントは、人間の言語を理解して生成するだけでなく、戦略を策定し、多様な環境でタスクを実行し、API 呼び出しやコーディングを使用して構築することもできます。ソリューション。
この文脈では、AgentQuest フレームワークの導入はマイルストーンです。LLM エージェントの評価と進捗のためのモジュール式ベンチマーク プラットフォームを提供するだけでなく、簡単に拡張可能な API によって、研究者は、これらのエージェントのパフォーマンスをより詳細なレベルで追跡し、改善するための強力なツールを利用できます。 AgentQuest の中核は、革新的な評価指標である進捗率と繰り返し率にあり、タスクを解決する際のエージェントの行動パターンを明らかにし、それによってアーキテクチャの最適化と調整を導きます。
「AgentQuest: 進捗状況を測定し、LLM エージェントを改善するためのモジュラー ベンチマーク フレームワーク」は、NEC ヨーロッパ研究所、トリノ工科大学、サン シリル大学の多様な研究チームによって作成されました。メトディウス。この論文は、計算言語学協会北米支部の 2024 年の会議 (NAACL-HLT 2024) で発表される予定で、人間の言語技術分野におけるチームの研究結果が、その価値だけでなく同業者によって認められたことを示しています。 AgentQuest フレームワークの認定は、LLM エージェントの将来の開発可能性を裏付けるものでもあります。
AgentQuest フレームワークは、大規模言語モデル (LLM) エージェントの機能を測定および改善するためのツールです。その主な貢献は、モジュール式でスケーラブルなベンチマーク テスト プラットフォームを提供することです。このプラットフォームは、特定のタスクに対するエージェントのパフォーマンスを評価するだけでなく、問題解決の過程におけるエージェントの行動パターンを表示することで、問題解決の過程におけるエージェントの行動パターンを明らかにすることもできます。 AgentQuest の利点は、その柔軟性とオープン性であり、研究者がニーズに応じてベンチマークをカスタマイズできるため、LLM エージェント テクノロジの開発が促進されます。
AgentQuest フレームワークの概要
AgentQuest フレームワークは、大規模言語モデル (LLM) エージェントのパフォーマンスを測定および改善するために設計された革新的な調査ツールです。 。これにより、研究者は、モジュール式の一連のベンチマークと評価指標を提供することで、複雑なタスクの実行におけるエージェントの進捗状況を系統的に追跡し、改善の余地がある領域を特定することができます。
AgentQuest は、複数のベンチマークとエージェント アーキテクチャをサポートするモジュラー フレームワークで、エージェント アーキテクチャのパフォーマンスを評価するための 2 つの新しい指標 (進捗率とリピート率) が導入されています。このフレームワークは、任意のエージェント アーキテクチャをさまざまなベンチマーク セットに接続し、そこから進捗率と繰り返し率を計算するための標準インターフェイスを定義します。
AgentQuest には、ALFWorld、Lateral Thinking Puzzles、Mastermind、Digital Solitude の 4 つのベンチマーク テストが含まれています。さらに、AgentQuest には新しいテストも導入されています。テスト対象のエージェントに変更を加えずに、ベンチマークを簡単に追加できます。
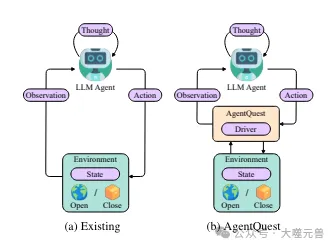 図
図
図 1: 現在のフレームワーク AgentQuest におけるエージェントのベースライン対話の概要。 AgentQuest は、ベンチマークと対話して進捗メトリクスを計算するための共通インターフェイスを定義し、新しいベンチマークの追加を簡素化し、研究者がエージェント アーキテクチャを評価およびテストできるようにします。
基本的な構成と機能
AgentQuest フレームワークの中核は、研究者が必要に応じてベンチマークを追加または変更できるモジュール設計です。この柔軟性は、ベンチマークと評価メトリクスを独立したモジュールに分離することで実現され、それぞれを独立して開発および最適化できます。フレームワークの主なコンポーネントは次のとおりです。
ベンチマーク モジュール: これらは、エージェントが実行する必要がある事前定義されたタスクです。単純な単語ゲームから複雑な論理パズルまで多岐にわたります。
評価指標モジュール: 進捗率や繰り返し率など、エージェントのパフォーマンスを定量化するツールのセットを提供します。これらの指標は、研究者がタスクにおけるエージェントの行動パターンを理解するのに役立ちます。
API インターフェイス: 研究者は、独自のエージェント アーキテクチャを AgentQuest フレームワークに接続したり、外部のデータ ソースやサービスと対話したりできます。
モジュール式ベンチマークとメトリクスの重要性
モジュール式ベンチマークの主な利点は、さまざまなエージェントのパフォーマンスを評価する標準化された方法が提供されることです。これは、研究者が同じ条件下で異なる薬剤からの結果を比較できることを意味し、結果の一貫性と比較可能性を確保します。さらに、モジュール設計により、研究者は特定の研究のニーズに合わせてベンチマークを調整することもできますが、これは従来のベンチマーク フレームワークでは達成が困難なことが多いです。
評価指標は、エージェントのパフォーマンスについての深い洞察を提供するため、同様に重要です。たとえば、進捗率は、エージェントがタスクを解決する際にどれだけ効率的に取り組んでいるかを示すことができ、一方、繰り返し率は、エージェントが特定のステップの繰り返しで行き詰まっているかどうかを明らかにし、意思決定プロセスを改善する必要があることを示す可能性があります。
AgentQuest のスケーラビリティ
AgentQuest の API インターフェイスは、そのスケーラビリティの鍵です。研究者は API を通じて、新しいベンチマークや評価指標を追加したり、外部のデータ ソースやサービスに接続したりする場合でも、AgentQuest を既存の研究ワークフローに簡単に統合できます。この拡張性は、研究の反復プロセスを加速するだけでなく、異なる分野の専門家が AgentQuest フレームワークを使用して共通の研究課題を解決するために協力できるため、学際的なコラボレーションも促進します。
AgentQuest フレームワークは、モジュール式のベンチマークと評価メトリクス、および API による拡張性を通じて、LLM エージェントの研究開発のための強力なプラットフォームを提供します。これは研究の標準化と再現性を促進するだけでなく、将来の革新とインテリジェント エージェントのコラボレーションへの道を切り開きます。
ベンチマークと評価メトリクス
AgentQuest フレームワークでは、ベンチマークは LLM エージェントのパフォーマンスを評価するための重要なコンポーネントです。これらのテストは、さまざまなエージェントの能力を比較するための標準化された環境を提供するだけでなく、特定の問題を解決するときのエージェントの行動パターンを明らかにすることもできます。
AgentQuest は、単一の統合 Python インターフェイス、つまりドライバーと、エージェントと環境の相互作用のコンポーネント (つまり、観察とアクション) を反映する 2 つのクラスを公開します。観察クラスには 2 つの必須プロパティがあります: (i) 出力、環境の状態に関する情報を報告する文字列、(ii) 完了、最終タスクが現在完了したかどうかを示すブール変数。アクション クラスには、アクション値という 1 つの必須属性があります。これはエージェントによって直接出力される文字列です。処理されて環境に提供されると、環境への変化が引き起こされます。インタラクションをカスタマイズするために、開発者はオプションのプロパティを定義できます。
Mastermind Benchmark
Mastermind は、プレーヤーが隠されたカラー コードを推測する必要がある古典的なロジック ゲームです。 AgentQuest フレームワークでは、このゲームはベンチマークの 1 つとして使用され、エージェントは一連の推測を通じて正しいコードを決定する任務を負います。各推測の後、環境はフィードバックを提供し、色は正しいが位置が間違っていたものがいくつあるか、色と位置の両方が正しいものがいくつあったかをエージェントに伝えます。このプロセスは、エージェントが正しいコードを推測するか、事前に設定されたステップ数の制限に達するまで続きます。
 図 2: ここでは、Mastermind がインタラクションを実装する方法の例を示します。
図 2: ここでは、Mastermind がインタラクションを実装する方法の例を示します。
Sudoku ベンチマーク
Sudoku は、プレーヤーが 9x9 のグリッドに数字を埋め、各行に数字を記入する必要があるもう 1 つの人気のある論理パズルです。 、列と各 3x3 サブグリッドは一意です。 AgentQuest フレームワークでは、空間推論と計画におけるエージェントの能力を評価するベンチマークとして Sudoku が使用されます。エージェントは効率的な数字を埋める戦略を立て、限られた手数内でパズルを解く必要があります。
評価指標: 進捗率とリピート率
AgentQuest には、進捗率 (PR) とリピート率 (RR) という 2 つの新しい評価指標が導入されました。 。進捗率は、エージェントのタスク完了の進捗状況を測定する 0 ~ 1 の値です。これは、エージェントが到達したマイルストーンの数をマイルストーンの合計数で割ることによって計算されます。たとえば、マスターマインド ゲームでは、エージェントが合計 4 つの推測のうち 2 つの正しい色と場所を推測した場合、進捗率は 0.5 になります。
繰り返し率は、タスクの実行中にエージェントが同じまたは類似のアクションを繰り返す傾向を測定します。繰り返し率を計算するとき、エージェントの以前のすべてのアクションが考慮され、類似性関数を使用して現在のアクションが以前のアクションと類似しているかどうかが判断されます。反復率は、反復数を合計反復数 (最初のステップを差し引いたもの) で割ることによって計算されます。
メトリクスによる LLM エージェントのパフォーマンスの評価と改善
これらのメトリクスは、研究者に分析のための強力なツールを提供し、LLM エージェントのパフォーマンスを改善します。進捗率を観察することで、研究者はエージェントが問題を解決する際にどれだけ効率的に取り組んでいるかを理解し、ボトルネックの可能性を特定できます。同時に、反復率の分析により、特定の戦略への過度の依存やイノベーションの欠如など、エージェントの意思決定プロセスにおける潜在的な問題が明らかになる可能性があります。
 表 1: AgentQuest で利用可能なベンチマークの概要。
表 1: AgentQuest で利用可能なベンチマークの概要。
一般に、AgentQuest フレームワークのベンチマーク テストと評価指標は、LLM エージェントの開発のための包括的な評価システムを提供します。これらのツールを通じて、研究者はエージェントの現在のパフォーマンスを評価するだけでなく、将来の改善の方向性を導くことができるため、さまざまな複雑なタスクへの LLM エージェントの適用と開発を促進できます。
AgentQuest のアプリケーション ケース
AgentQuest フレームワークの実践的なアプリケーション ケースでは、Mastermind とその他のベンチマーク テストでは、さまざまなシナリオで LLM エージェントのパフォーマンスを観察し、特定の戦略を通じてパフォーマンスを向上させる方法を分析できます。
Mastermind アプリケーションのケース
Mastermind ゲームでは、エージェントの論理的推論能力を評価するために AgentQuest フレームワークが使用されます。エージェントは数字で構成される隠されたコードを推測する必要があり、推測するたびに、システムは正しい数字の番号と位置を示すフィードバックを提供します。このプロセスを通じて、エージェントはフィードバックに基づいて推測戦略を調整し、より効率的に目標を達成する方法を学習します。
実際のアプリケーションでは、エージェントの初期パフォーマンスが理想的ではない可能性があり、同じまたは類似の推測が繰り返されることが多く、その結果、繰り返し率が高くなります。ただし、進捗率と反復率に関するデータを分析することで、研究者はエージェントの意思決定プロセスの欠点を特定し、改善するための措置を講じることができます。たとえば、メモリ コンポーネントを導入すると、エージェントは以前の推測を記憶し、効果のない試行を繰り返すことを回避できるため、効率と精度が向上します。
他のベンチマークの適用例
Mastermind に加えて、AgentQuest には数独、単語ゲーム、論理パズルなどの他のベンチマークも含まれています. .これらのテストでは、エージェントのパフォーマンスは進行率と繰り返し率のメトリクスにも影響されます。たとえば、Sudoku テストでは、エージェントは、各行、各列、および 3x3 の各サブグリッドの数字が繰り返されないように、9x9 のグリッドを埋める必要があります。これには、エージェントが空間推論能力と戦略的計画能力を備えていることが必要です。
これらのテスト中に、エージェントはさまざまな課題に遭遇する可能性があります。一部のエージェントは空間推論には優れているものの、戦略計画には不十分な場合があります。 AgentQuest フレームワークによって提供される詳細なフィードバックを通じて、研究者は対象を絞った方法で問題領域を特定し、アルゴリズムの最適化やトレーニング方法の調整を通じてエージェントの全体的なパフォーマンスを向上させることができます。
メモリ コンポーネントの影響
メモリ コンポーネントの追加は、エージェントのパフォーマンスに大きな影響を与えます。 Mastermind テストでは、メモリ コンポーネントを追加した後、エージェントは無効な推測を繰り返すことを回避でき、それによって繰り返し率が大幅に減少しました。これにより、エージェントが問題を解決する速度が向上するだけでなく、成功率も向上します。さらに、メモリ コンポーネントにより、同様の問題に直面したときにエージェントがより早く学習して適応できるようになり、長期的には学習効率が向上します。
全体として、AgentQuest フレームワークは、モジュール式のベンチマークと評価メトリクスを提供することにより、LLM エージェントのパフォーマンス評価と改善のための強力なツールを提供します。実際のアプリケーションケースの分析を通じて、戦略を調整し、メモリモジュールなどの新しいコンポーネントを導入することで、エージェントのパフォーマンスを大幅に向上できることがわかります。
実験セットアップと結果分析
AgentQuest フレームワークの実験セットアップでは、研究者は、大規模なチャット エージェントで構成される既製のチャット エージェントに基づく参照アーキテクチャを採用しました。 GPT-4 などの言語モデル (LLM) ドライバー。このアーキテクチャが選択されたのは、直感的で拡張が容易で、オープンソースであるため、研究者がさまざまなエージェント戦略を簡単に統合してテストできるためです。
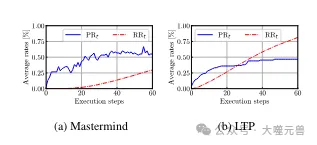 図
図
図 4: Mastermind と LTP の平均進捗率 PRt と反復率 RRt。 Mastermind: RRt は最初は低いですが、ステップ 22 以降は増加しますが、進行状況も 55% で停止します。 LTP: 最初は、RRt が高くなると、エージェントは小さな変更を加えて成功することができますが、後には横ばいになります。
実験セットアップ
実験セットアップには、Mastermind や ALFWorld などの複数のベンチマークが含まれており、それぞれが特定の領域でのエージェントのパフォーマンスを評価するように設計されています。実験では実行ステップの最大数が設定されます (通常は 60 ステップ)。これは、エージェントが問題を解決する際に試行できる試行回数を制限するためです。この制限は、現実世界の限られたリソースの状況をシミュレートし、エージェントに限られた試行の中で最も効果的な解決策を見つけることを強制します。
実験結果の分析
Mastermind ベンチマーク テストでは、実験結果は、メモリ コンポーネントのないエージェントの反復率が比較的高いことを示しています。高い場合、進歩の速度も制限されます。これは、エージェントが問題を解決しようとするときに、無効な推測を繰り返して行き詰まってしまう傾向があることを示しています。しかし、メモリ コンポーネントが導入されると、エージェントのパフォーマンスが大幅に向上し、成功率が 47% から 60% に増加し、繰り返し率が 0% に低下しました。これは、エージェントの効率と精度を向上させるためにメモリ コンポーネントが重要であることを示しています。
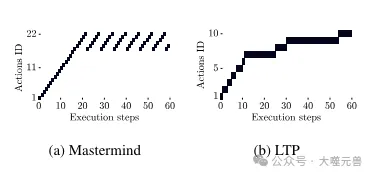 写真
写真
図 5: Mastermind と LTP で繰り返される操作の例。マスターマインド: 最初は一連のユニークな動きをしますが、その後同じ動きを何度も繰り返すことになります。 LTP: 繰り返されるアクションは、同じ問題に対する小さなバリエーションであり、進歩につながります。
ALFWorld ベンチマークでは、エージェントはオブジェクトを見つけるためにテキストの世界を探索する必要があります。実験結果によると、エージェントは解決空間を探索する際にアクションの繰り返しを制限しましたが (RR60 = 6%)、すべてのゲームを解決することはできませんでした (PR60 = 74%)。この違いは、オブジェクトを検出するときにエージェントがより多くの探索ステップを必要とするという事実による可能性があります。ベンチマークの実行時間を 120 ステップに延長すると、成功率と進行率の両方が向上し、エージェントの障害を理解する上で AgentQuest が有用であることがさらに確認されました。
エージェント アーキテクチャの調整
AgentQuest の指標に従って、研究者はエージェント アーキテクチャを調整できます。たとえば、エージェントが特定のベンチマークで高い反復率を示していることが判明した場合、無効な試行を繰り返さないように意思決定アルゴリズムを改善する必要がある可能性があります。同様に、進捗率が低い場合は、より迅速に環境に適応して問題の解決策を見つけるために、エージェントの学習プロセスを最適化する必要がある場合があります。
AgentQuest フレームワークによって提供される実験設定と評価メトリクスは、LLM エージェントのパフォーマンスについての深い洞察を提供します。実験結果を分析することで、研究者はエージェントの長所と短所を特定し、それに応じてエージェントのアーキテクチャを調整して、さまざまなタスクにおけるパフォーマンスを向上させることができます。
ディスカッションと今後の取り組み
AgentQuest フレームワークの提案は、大規模言語モデル (LLM) の研究開発に新たな道を開きますエージェント、その方法。これは、LLM エージェントのパフォーマンスを測定および改善する体系的な方法を提供するだけでなく、研究コミュニティによるエージェントの動作に対する深い理解を促進します。
LLM エージェント研究における AgentQuest の潜在的な影響
AgentQuest を使用すると、研究者は特定のタスクにおける LLM エージェントの進捗状況と効率をより正確に測定できます。この正確な評価機能は、より効率的でインテリジェントなエージェントを設計するために重要です。 LLM エージェントは顧客サービスから自然言語処理に至るまで、さまざまな分野でますます使用されるようになっており、AgentQuest が提供する詳細な分析ツールは、研究者がエージェントの意思決定プロセスを最適化し、実際のアプリケーションでのパフォーマンスを向上させるのに役立ちます。
透明性と公平性の促進における AgentQuest の役割
AgentQuest のもう 1 つの重要な貢献は、LLM エージェント調査の透明性を高めることです。 AgentQuest は、公開された評価指標と再現可能なベンチマークを通じてオープン サイエンスの実践を奨励し、研究結果の検証と比較を容易にします。さらに、AgentQuest のモジュール式の性質により、研究者はベンチマークをカスタマイズできます。つまり、さまざまなニーズや状況に合わせてテストを設計でき、研究における多様性と包括性を促進できます。
AgentQuest の今後の開発と研究コミュニティからの貢献の可能性
テクノロジーの進歩に合わせて、AgentQuest フレームワークは今後も継続されることが期待されています拡張および改善される予定です。新しいベンチマークと評価指標の追加により、AgentQuest はより多くの種類のタスクとシナリオをカバーできるようになり、LLM エージェントの評価により包括的な視点を提供できるようになります。さらに、人工知能テクノロジーの進歩に伴い、AgentQuest には、より効率的なパフォーマンスの最適化を達成するためにエージェント アーキテクチャを自動的に調整する機能など、より高度な機能も統合される可能性があります。
研究コミュニティによる AgentQuest への貢献も、その開発に不可欠です。オープンソースの性質は、研究者が改善や革新を共有できることを意味し、AgentQuest フレームワークの進歩を加速します。同時に、研究コミュニティからのフィードバックと実際の経験は、AgentQuest が実際のアプリケーションのニーズをより適切に満たし、LLM エージェント テクノロジーの開発を促進するのに役立ちます。
参考: https://arxiv.org/abs/2404.06411
以上がエージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuestの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。