
ホームページ >テクノロジー周辺機器 >AI >生物医学 NLP ドメインの特定の事前トレーニング済みモデル: PubMedBERT
生物医学 NLP ドメインの特定の事前トレーニング済みモデル: PubMedBERT

- 王林転載
- 2023-11-27 17:13:461318ブラウズ
今年の大規模言語モデルの急速な開発により、BERT のようなモデルは「小規模」モデルと呼ばれるようになりました。 Kaggle の LLM 科学試験コンテストでは、deberta を使用しているプレイヤーが 4 位に入賞するという素晴らしい成績を収めました。したがって、特定のドメインまたはニーズでは、必ずしも大規模な言語モデルが最適なソリューションとして必要なわけではなく、小規模なモデルにも適した場所があります。したがって、今日紹介するのは、2022 年の ACM で Microsoft Research によって発表された論文、PubMedBERT です。このモデルは、ドメイン固有のコーパス
## を使用して、BERT を最初から事前学習します。 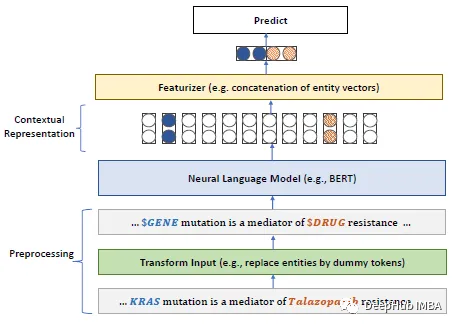
#論文の主な要点は次のとおりです:
生物医学ドメインなど、ラベルのないテキストが大量に含まれる特定のドメインの場合は、事前トレーニングが必要です。スクラッチからの言語モデルは、一般的なドメイン言語モデルの継続的な事前トレーニングよりも効果的です。この目的を達成するために、私たちはドメイン固有の事前トレーニングのために生物医学的言語理解と推論ベンチマーク (BLURB) を提案します
PubMedBERT
1 、ドメイン固有の事前トレーニング
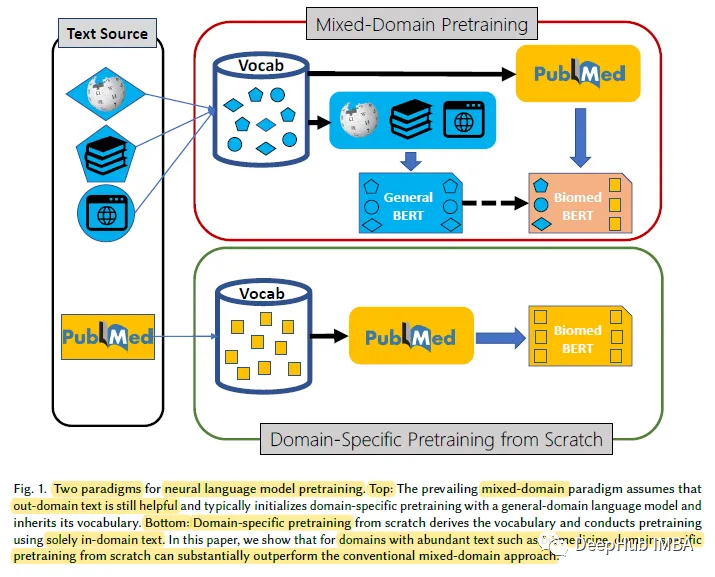
# 研究によると、ゼロからのドメイン固有の事前トレーニングは、一般的な言語モデルの継続的な事前トレーニングよりも大幅に優れており、ハイブリッドのサポートが実証されています。ドメインの事前トレーニングに関する一般的な仮定が常に適用されるわけではありません。
2. モデル
マスクされた言語モデル (MLM) の場合、BERT モデルを使用し、単語全体のマスキング (WWM) の要件を満たします。は必要です 単語全体をマスクします
#3. BLURB データセット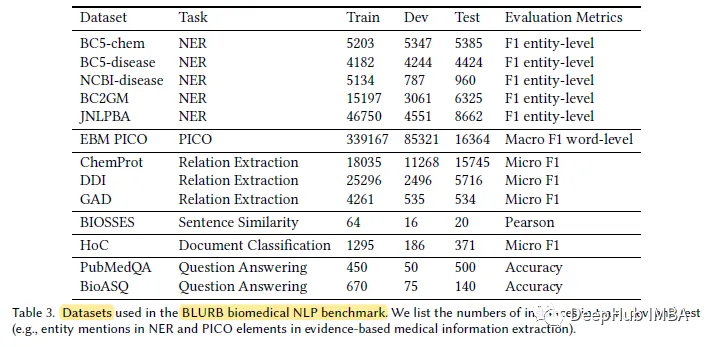
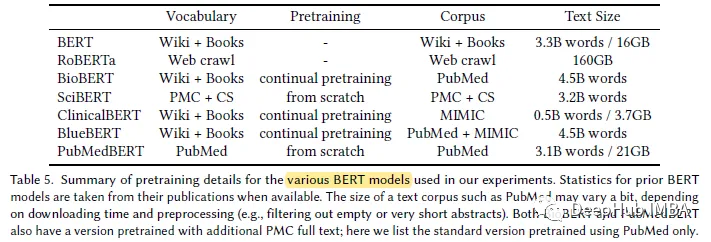 #表示される結果
#表示される結果
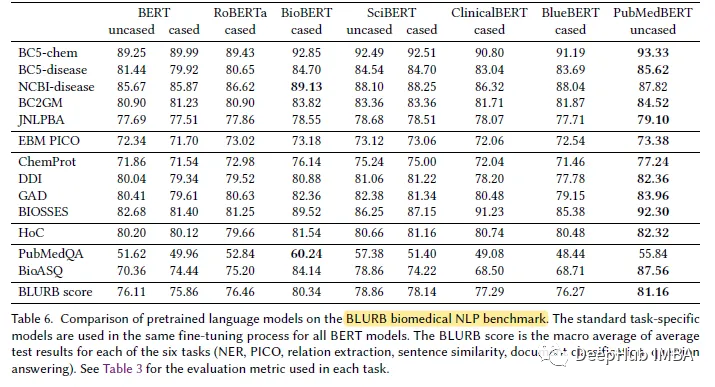 最も生物医学的で自然な言語で処理 (NLP) タスクでは、PubMedBERT は他のすべての BERT モデルよりも一貫して優れたパフォーマンスを示し、多くの場合明らかな利点を備えています
最も生物医学的で自然な言語で処理 (NLP) タスクでは、PubMedBERT は他のすべての BERT モデルよりも一貫して優れたパフォーマンスを示し、多くの場合明らかな利点を備えています
以上が生物医学 NLP ドメインの特定の事前トレーニング済みモデル: PubMedBERTの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。