
ホームページ >テクノロジー周辺機器 >AI >LLMLingua: LlamaIndex を統合し、ヒントを圧縮し、効率的な大規模言語モデル推論サービスを提供します
LLMLingua: LlamaIndex を統合し、ヒントを圧縮し、効率的な大規模言語モデル推論サービスを提供します

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-11-27 17:13:551060ブラウズ
大規模言語モデル (LLM) の出現により、複数の分野でイノベーションが刺激されました。しかし、思考連鎖 (CoT) プロンプトや文脈学習 (ICL) などの戦略によってプロンプトの複雑さが増し、計算上の課題が生じています。このような長いプロンプトは推論に多大なリソースを必要とするため、効率的な解決策が必要です。この記事では、効率的な推論を実行するための LLMLingua と独自の LlamaIndex の統合について紹介します。
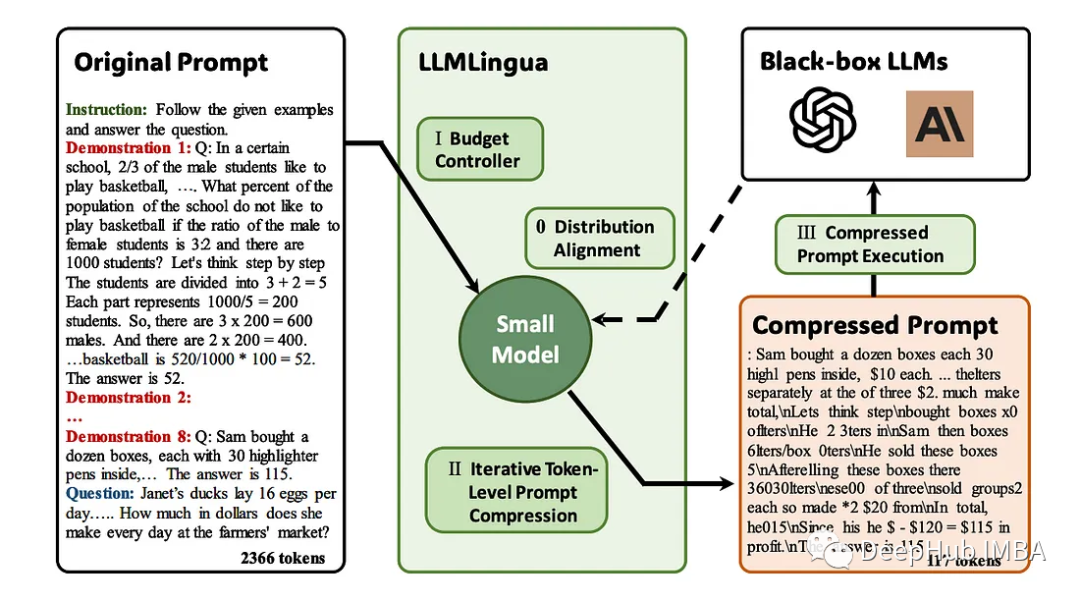
LLMLingua は、EMNLP 2023 で Microsoft 研究者によって発表された論文です。 LongLLMLinguaは、高速圧縮を通じて、長いコンテキストのシナリオで重要な情報を認識する llm の能力を強化する方法です。
LLMLingua と llamindex の連携
LLMLingua は、LLM アプリケーションの冗長プロンプトに対する先駆的なソリューションとして登場しました。このアプローチは、意味上の整合性を確保し、推論速度を向上させながら、長いプロンプトを圧縮することに重点を置いています。さまざまな圧縮戦略を組み合わせて、ヒントの長さと計算効率のバランスをとる微妙な方法を提供します。
LLMLingua と LlamaIndex を統合する利点は次のとおりです:
LLMLingua と LlamaIndex の統合は、llm の迅速な最適化における重要なステップとなります。ステップ。 LlamaIndex は、さまざまな LLM アプリケーション向けに調整された事前に最適化されたヒントを含む特殊なリポジトリです。この統合を通じて、LLMLingua はドメイン固有の微調整されたヒントの豊富なセットにアクセスできるため、ヒント圧縮機能が強化されます。
LLMLingua は、LlamaIndex の最適化ヒント ライブラリとの相乗効果により、LLM アプリケーションの効率を向上させます。 LLMLingua は、LLAMA の特殊なキューを活用して、圧縮戦略を微調整して、キューの長さを短縮しながらドメイン固有のコンテキストを確実に保持できます。このコラボレーションにより、主要なドメインのニュアンスを維持しながら推論が劇的に高速化されます。
LLMLingua と LlamaIndex の統合により、大規模な LLM アプリケーションへの影響が拡大します。 LLAMA のエキスパート ヒントを活用することで、LLMLingua は圧縮テクノロジを最適化し、長いヒントを処理する際の計算負荷を軽減しました。この統合により、推論が高速化されるだけでなく、重要なドメイン固有の情報が確実に保持されます。
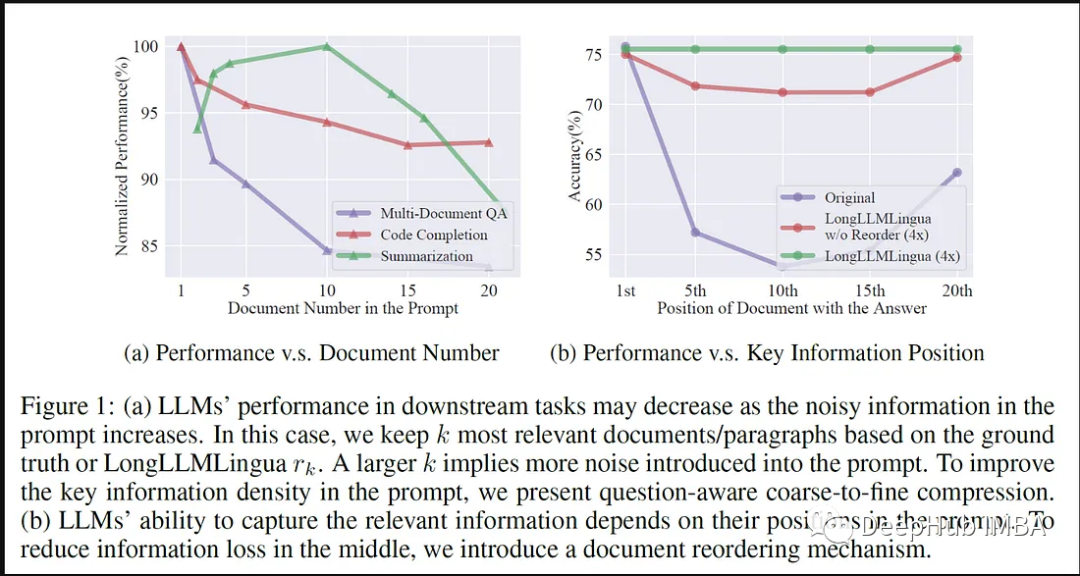
LLMLingua と LlamaIndex のワークフロー
LlamaIndex を使用して LLMLlingua を実装するには、一連の構造化された手順が必要です効率的なヒント圧縮と推論速度の向上のための特殊なヒント ライブラリの使用を含むプロセス
#1. フレームワークの統合
最初に確立する必要がありますLLMLingua と LlamaIndex の間の接続。これには、アクセス権、API 構成、およびタイムリーな取得のための接続の確立が含まれます。
2. 最適化前のヒントの取得
LlamaIndex は、さまざまな LLM アプリケーションに合わせたコンテンツを含む特殊なリポジトリとして利用できます。 。 LLMLingua は、このリポジトリにアクセスし、ドメイン固有のヒントを取得し、これらのヒントを圧縮に利用できます
#3. ヒント圧縮テクノロジ
LLMLingua は、取得したヒントを簡略化するためのヒント圧縮方法。これらの技術は、意味上の一貫性を確保しながら長いプロンプトを圧縮することに重点を置いており、それによってコンテキストや関連性に影響を与えることなく推論速度を向上させます。
4. 圧縮戦略を微調整する
LLMLingua は、LlamaIndex から取得した特殊なヒントに基づいて圧縮戦略を微調整します。この改良プロセスにより、プロンプトの長さを効率的に削減しながら、ドメイン固有のニュアンスが確実に保持されます。
5. 実行と推論
LLMLingua のカスタマイズされた戦略を使用し、圧縮のために LlamaIndex の事前最適化プロンプトと組み合わせた後、取得されたプロンプトは次のようになります。 LLM 推論タスクに使用されます。この段階では、LLM フレームワーク内で圧縮ヒントを実行して、コンテキストを意識した効率的な推論を可能にします
6. 反復的な改善と強化
コード実装では引き続き改良が繰り返されます。このプロセスには、圧縮アルゴリズムの改善、LlamaIndex からのヒントの取得の最適化、圧縮されたヒントと LLM 推論の一貫性とパフォーマンス向上を確保するための統合の微調整が含まれます。
7. テストと検証
LLMLingua と LLMLingua の統合の効率と有効性を高めるために、必要に応じてテストと検証を実行できます。 LlamaIndex を評価できます。パフォーマンス メトリックは、圧縮ヒントがセマンティックな整合性を維持し、精度を損なうことなく推論速度を向上させることを保証するために評価されます。
コード実装
LLMLingua と LlamaIndex のコード実装を詳しく掘り下げていきます
インストール パッケージ:
# Install dependency. !pip install llmlingua llama-index openai tiktoken -q # Using the OAI import openai openai.api_key = "<insert_openai_key>"</insert_openai_key>
データの取得:
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
モデルのロード:
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,load_index_from_storage,StorageContext, ) # load documents documents = SimpleDirectoryReader(input_files=["paul_graham_essay.txt"] ).load_data()
Vector storage :
index = VectorStoreIndex.from_documents(documents) retriever = index.as_retriever(similarity_top_k=10) question = "Where did the author go for art school?" # Ground-truth Answer answer = "RISD" contexts = retriever.retrieve(question) contexts = retriever.retrieve(question) context_list = [n.get_content() for n in contexts] len(context_list) #Output #10
元のプロンプトとリターン
# The response from original prompt from llama_index.llms import OpenAI llm = OpenAI(model="gpt-3.5-turbo-16k") prompt = "\n\n".join(context_list + [question]) response = llm.complete(prompt) print(str(response)) #Output The author went to the Rhode Island School of Design (RISD) for art school.
LLMLinguaの設定
from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )
通过LLMLingua进行压缩
retrieved_nodes = retriever.retrieve(question) synthesizer = CompactAndRefine() from llama_index.indices.query.schema import QueryBundle # postprocess (compress), synthesize new_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=question) ) original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes]) original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts) compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
打印2个结果对比:
print(compressed_contexts) print() print("Original Tokens:", original_tokens) print("Compressed Tokens:", compressed_tokens) print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")
打印的结果如下:
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1] I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. [] the Accademia wasn't, and my money was running out, end year back to thelot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6] Original Tokens: 10719 Compressed Tokens: 308 Comressed Ratio: 34.80x
验证输出:
response = synthesizer.synthesize(question, new_retrieved_nodes) print(str(response)) #Output #The author went to RISD for art school.
总结
LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。
这种集成不仅可以提升推理速度,而且可以保证在压缩提示中保持语义的完整性。通过对基于LlamaIndex特定领域提示的压缩策略进行微调,我们平衡了提示长度的减少和基本上下文的保留,从而提高了LLM推理的准确性
从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。
以上がLLMLingua: LlamaIndex を統合し、ヒントを圧縮し、効率的な大規模言語モデル推論サービスを提供しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。