
ホームページ >テクノロジー周辺機器 >AI >MIT は、大規模な言語モデル ≠ ランダムなオウムが実際にセマンティクスを学習できることを示しています。
MIT は、大規模な言語モデル ≠ ランダムなオウムが実際にセマンティクスを学習できることを示しています。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-23 08:01:051091ブラウズ
大規模な事前トレーニング済み言語モデル (LLM) は、さまざまな下流タスクにわたってパフォーマンスが劇的に向上していることが実証されていますが、使用および生成するテキストのセマンティクスを本当に理解しているのでしょうか?
AI コミュニティでは、この問題に関して長い間意見が大きく分かれてきました。推測の 1 つは、純粋に言語の形式 (トレーニング コーパス内のトークンの条件付き分布など) に基づいてトレーニングされた言語モデルは、セマンティクスをまったく獲得しないということです。代わりに、モデルとトレーニング データのサイズに起因する強力な創発能力により、トレーニング データから収集した表面的な統計的相関関係に基づいてテキストを生成するだけです。これらの人々は LLM を「ランダム オウム」と呼んでいます。
しかし、この見解に同意しない人もいます。最近の研究では、NLP コミュニティの回答者の約 51% が、「十分なデータと計算リソースがあれば、テキストのみでトレーニングされた一部の生成モデルは、何らかの有意義な方法で自然を理解できる」ことに同意していることが示されました。言語の背後にある意味論と概念の)」。
この未解決の質問を調査するために、MIT CSAIL の研究者は詳細な研究を実施しました。

論文アドレス: https://paperswithcode.com/paper/evidence-of-meaning -in- language-models
この研究で使用される言語モデルは、次のトークンのテキスト予測のモデルになるようにトレーニングされるだけであり、2 つの仮説が定式化されます。
- ##H1: テキスト上の次のトークンを予測することのみによってトレーニングされた LM は、トレーニング コーパス内で表面レベルの統計的相関を繰り返すことによって基本的に制限されます。
- #H2LM は、ダイジェストして生成したテキストに意味を割り当てることができません。
- 2 つの仮説 H1 と H2 の正しさを調査するために、この研究では、言語モデリングをプログラム合成タスクに適用します。つまり、入力の正式な仕様が与えられた場合です。と出力例 合成プログラムをダウンロードします。この研究がこのアプローチを採用しているのは、主に、プログラムの意味 (および正確さ) がプログラミング言語のセマンティクスによって完全に決定されるためです。
具体的には、この研究では、プログラムとその仕様のコーパスに基づいて言語モデル (LM) をトレーニングし、線形分類器を使用して意味表現の LM の隠れた状態を検出します。プログラムの。この研究では、セマンティクスを抽出する検出器の能力は初期化時に確率的であり、その後、仕様を見なくても正しいプログラムを生成する LM の能力と強く相関するトレーニング中に位相変化を受けることが判明しました。さらに、この研究は、セマンティクスが(プローブを介して学習されたのではなく)モデル状態で表現されることを示す介入実験の結果を提示しています。
この研究の主な貢献は次のとおりです:
1. 実験結果は、タスクを実行する LM にいくつかの問題があることを示しています。次のトークンの予測、意味の表現。具体的には、この研究では、トレーニング済みの LM を使用して、いくつかの入出力例を与えられたプログラムを生成し、次に線形検出器をトレーニングして、モデルの状態からプログラムの状態に関する情報を抽出します。研究者らは、内部表現に次の線形エンコーディングが含まれていることを発見しました:(1)抽象セマンティクス(抽象解釈) - プログラム実行中の指定された入力の追跡、(2)まだ生成されていないプログラム トークンに対応する将来のプログラム状態の予測。トレーニング中に、セマンティクスのこれらの線形表現は、トレーニング ステップ中に正しいプログラムを生成する LM の能力と並行して発達します。
2. この研究では、表現から意味を抽出する際の LM と検出器の寄与を調査するための新しい介入方法を設計および評価しました。具体的には、この研究では、次の 2 つの質問のうちどちらが当てはまるかを分析しようとしています: (1) LM 表現には純粋な (構文的な) トランスクリプトが含まれている一方で、検出器は意味を推測するためにトランスクリプトを解釈することを学習します; (2) LM 表現にはセマンティクスが含まれています。意味論的な状態から意味を抽出します。実験結果は、LM 表現が実際に (語彙的および構文的な内容を単にエンコードするのではなく) 元の意味論と一致していることを示し、仮説 H2 が間違っていることを示唆しています。
3. この研究は、LM の出力がトレーニング分布とは異なることを示しており、具体的には、LM がトレーニング セット内のプログラムよりも短いプログラムを生成する傾向がある (それでも正しい) ことが明らかです。正しいプログラムを合成する LM の能力は向上しましたが、トレーニング セット内のプログラムに対する LM の困惑度は依然として高く、仮説 H1 が間違っていることを示しています。
全体として、この研究は、プログラミング言語のセマンティクスに基づいて LM を実証的に研究するためのフレームワークを提案します。このアプローチにより、基礎となるプログラミング言語の正確な形式的意味論から概念を定義、測定、実験することができるため、現在の LM の新たな機能の理解に貢献します。
研究の背景
この研究では、プログラム意味モデルとしてトレース セマンティクスを使用します。プログラミング言語理論の基本的なトピックとして、形式セマンティクスは、言語内の文字列に形式的にセマンティクスを割り当てる方法を研究します。この研究で使用されるセマンティック モデルは、プログラムの実行をトレースすることで構成されます。一連の入力 (つまり、変数の割り当て) が与えられると、(構文的な) プログラムの意味は、式から計算されたセマンティックな値によって識別され、トレースは、プログラムによって生成された一連の中間値の入力に基づいて実行されます。
プログラム意味モデルにトレース軌跡を使用する重要な理由はいくつかあります。まず、コードの一部を正確にトレースできる能力は、コードを解釈する能力に直接関係しています。次に、コンピュータ サイエンス教育でもトレースが重視されています。これは、プログラム開発を理解し、推論上のエラーを見つけるための重要な方法です。第 3 に、専門的なプログラム開発は、トレース ベースのデバッガ (dbugger) に依存しています。
この研究で使用されたトレーニング セットには、ランダムにサンプリングされた 100 万個の Karel プログラムが含まれていました。 1970 年代、スタンフォード大学卒業生のリッチ パティスは、学生がロボットに簡単な問題を解決できるように教えるためのプログラミング環境を設計しました。このロボットはカレル ロボットと呼ばれていました。
この研究では、ランダム サンプリングを使用してトレーニング サンプルの参照プログラムを構築し、次に 5 つのランダムな入力をサンプリングし、プログラムを実行して対応する 5 つの出力を取得します。 LM は、サンプルのコーパスに対して次のトークン予測を実行するようにトレーニングされます。この研究では、テスト時に入力および出力プレフィックスを LM に提供するだけで、貪欲なデコードを使用してプログラムを完成させます。以下の図 1 は、実際の参照プログラムの完成とトレーニングされた LM を示しています。
この研究では、データセットに対して次のトークン予測を実行するために既製の Transformer モデルをトレーニングしました。 64,000 のトレーニング ステップと約 1.5 エポックの後、最終的にトレーニングされた LM はテスト セットで 96.4% の生成精度を達成しました。研究では、2000 トレーニング ステップごとにトレース データセットがキャプチャされました。この研究では、トレーニング軌跡データセットごとに、モデルの状態を考慮してプログラムの状態を予測するために線形検出器をトレーニングします。
意味の出現
研究者らは次の仮説を研究しました: 次のトークン予測を実行するために言語モデルをトレーニングする過程で、意味論的状態の表現が副産物になりますモデル状態で登場します。最終的にトレーニングされた言語モデルが 96.4% の生成精度を達成したことを考慮すると、この仮説が拒否された場合、H2 と一致することになります。つまり、言語モデルは正しいプログラムを一貫して生成するために表面統計「のみ」を使用することを学習しました。
この仮説を検証するために、研究者らは、説明したように、モデル状態からセマンティック状態を 5 つの独立した 4 方向タスク (それぞれ入力指向の一方向) として抽出するように線形検出器をトレーニングしました。セクション2.2で説明します。
#意味の出現は生成精度と正の相関がある
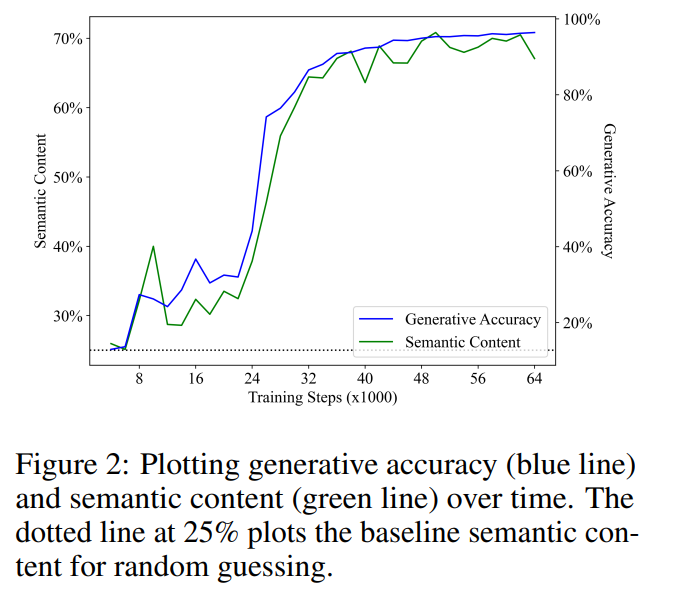
図 2 に主な結果を示します。最初の観察は、セマンティック コンテンツがランダム推測のベースライン パフォーマンス (25%) から始まり、トレーニング中に大幅に増加するということです。この結果は、言語モデルの隠れた状態に実際にセマンティック状態の (線形) エンコーディングが含まれていることを示しています。そして重要なことに、この意味はテキストの次のトークン予測を実行するために純粋に使用される言語モデルで現れるということです。
生成精度と意味内容の間で線形回帰を実行したところ、トレーニング ステップ中に予想外に強力で統計的に有意な線形相関が示されました (R2 = 0.968、p
表現は将来のプログラム セマンティクスの予測です
前のセクションでは、言語モデルが生成するテキストの意味を表現できるかどうかについて説明しました。この論文の結果は、言語モデルが生成されたプログラムを (抽象的に) 説明できるという疑問に対して肯定的な答えを与えます。ただし、インタープリターはシンセサイザーとは異なり、理解する能力だけでは生成するのに十分ではありません。人間の言語の出現に関する限り、言語は心の中の非言語メッセージに由来し、その後、元の概念を反映した発話に変換されるという広範なコンセンサスがあります。研究者らは、トレーニングされた言語モデルの生成プロセスも同様のメカニズムに従っている、つまり、言語モデルの表現がまだ生成されていないテキストのセマンティクスをエンコードしているという仮説を立てています。
この仮説を検証するために、彼らは上記と同じ方法を使用して線形検出器をトレーニングし、モデル状態から導出される将来の意味論的状態を予測しました。貪欲なデコード戦略を使用するため、将来のセマンティック状態も決定的であり、タスクが明確に定義されていることに注意してください。
図 3 は、将来のステップ 1 と 2 のセマンティック状態を予測する際の線形検出器のパフォーマンスを示しています (緑のセグメント線は「セマンティック (1)」を表し、緑の点線は「セマンティック (1)」を表します) 「セマンティック (2)」を表します)。以前の結果と同様に、検出器のパフォーマンスはランダムな推測のベースラインから開始され、その後トレーニングによって大幅に向上しました。また、将来の状態の意味内容がトレーニング ステップ中の生成精度 (青い線) と強い相関関係を示すこともわかりました。セックス。意味内容と生成精度の線形回帰分析によって得られた R2 値はそれぞれ 0.919 と 0.900 であり、将来の 1 ステップと 2 ステップの意味ステータスに対応し、両方の p 値は 0.001 未満です。
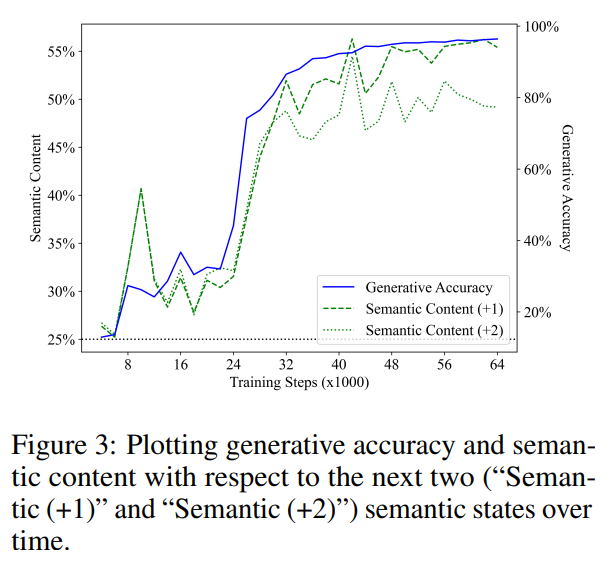
また、モデルの表現は現在のセマンティック状態のみをエンコードし、検出器は単に現在のセマンティック状態から開始するという仮定も考慮しました。将来のセマンティックを予測します。州。この仮説を検証するために、彼らは、現在のプログラムにおけるグラウンド トゥルースの向いている方向を、将来のプログラムにおける 4 つの向いている方向の 1 つにマッピングする最適な分類器を計算しました。
5 つの操作のうち 3 つは向きを維持し、次のトークンが均等にサンプリングされることに注意してください。したがって、1 歩先の状況では、将来の意味状態を予測するための最適な分類器は、向きが変わらないと予測することで 60% の精度を達成できるはずであると彼らは期待していました。実際、テストセットを直接フィッティングすることにより、現在の意味状態から将来の意味状態を予測する上限は、それぞれ 62.2% と 40.7% であることがわかりました (将来のケース 1 と 2 ステップに対応)。比較すると、検出器が現在の状態を正確に予測した場合、検出器は将来の状態を予測する精度が 68.4% および 61.0% でした。
これは、モデル状態から将来の意味論的状態を抽出する検出器の能力が、現在の意味論的状態の表現だけからは推論できないことを示しています。したがって、彼らの結果は、言語モデルがまだ生成されていないトークンの意味を表すことを学習することを示しており、これは言語モデルが意味を学習できないという考え (H2) を否定し、生成プロセスが純粋に表面的な統計に基づいていないことも示しています。 (H1)。
生成された出力はトレーニング配布とは異なります
次に、研究者は、トレーニングされた言語モデルによって生成されたプログラム分布と、次のプログラム分布を比較して反論を行います。 H1 のトレーニング セットの証拠。 H1 が成り立つ場合、言語モデルはトレーニング セット内のテキストの統計的相関を単に複製しているだけであるため、2 つの分布はほぼ等しいはずだと期待されます。
図 6a は、LM で生成されたプログラムの時間の経過に伴う平均長 (青の実線) と、トレーニング セット内の参照プログラムの平均長 (赤の破線) を示しています。 。彼らは統計的に有意な差を発見し、LM の出力分布がトレーニング セット内のプログラム分布と実際に異なることを示しました。これは、LM がトレーニング データの統計的相関のみを再現できるという H1 で述べた点と矛盾します。
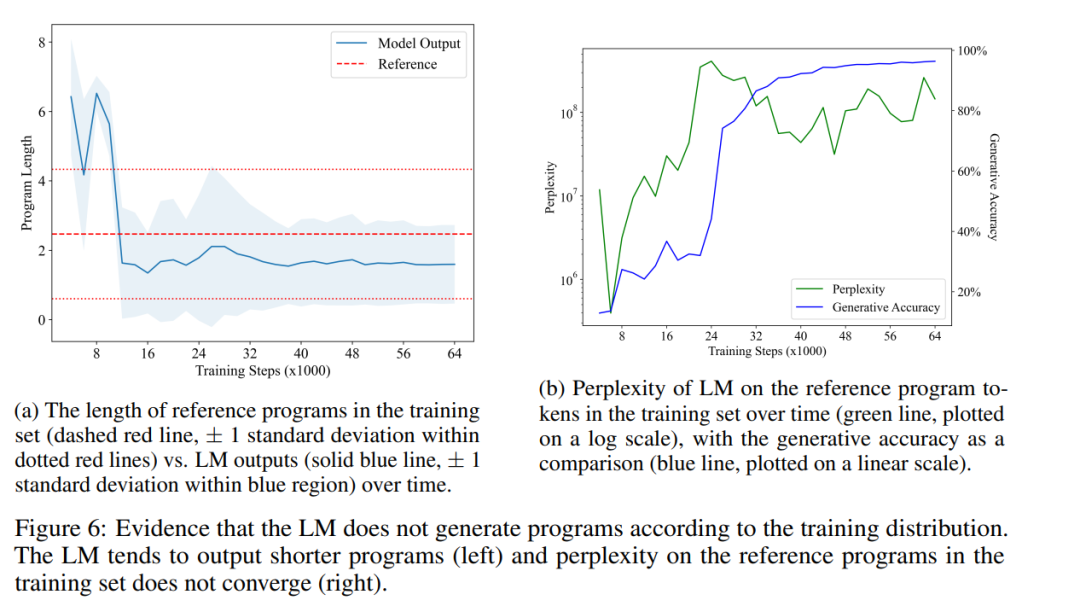
最後に、彼らはトレーニング セット内の LM プログラムの複雑さが時間の経過とともにどのように変化するかも測定しました。図 6b はその結果を示しています。見てわかるように、LM はトレーニング セット内のプログラムの分布を適切に適合させることを学習することはなく、これは H1 をさらに否定します。これは、LM がより簡潔なプログラムを生成することを好む一方で、トレーニング セット内のランダムにサンプリングされたプログラムには多くの no-op 命令が含まれていることが原因である可能性があります。興味深いことに、LM が模倣段階を超えて進むにつれ、混乱が急激に増加すると、生成精度 (および意味論的な内容) の向上につながるようです。プログラムの等価性の問題はプログラムのセマンティクスと密接に関係しているため、短くて正しいプログラムを生成する LM の能力は、LM がセマンティクスのある側面を実際に学習していることを示しています。
詳細については、原著論文を参照してください。
以上がMIT は、大規模な言語モデル ≠ ランダムなオウムが実際にセマンティクスを学習できることを示しています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。