
ホームページ >テクノロジー周辺機器 >AI >軌跡予測のための視覚的手法のレビュー
軌跡予測のための視覚的手法のレビュー

- PHPz転載
- 2023-05-22 23:54:161521ブラウズ
最近のレビュー論文「ビジョンによる軌道予測: 調査」は、ヒュンダイと Aptiv の会社 Motional からのものですが、これはオックスフォードのレビュー記事「自動運転車におけるビジョンベースの意図と軌道予測: 調査」を参照しています。大学 "。
予測タスクは基本的に 2 つの部分に分かれています: 1) 意図、エージェント用に一連の意図クラスを事前に設計する分類タスクです。通常、教師あり学習問題とみなされます。エージェントの分類意図の可能性をラベル付けするために必要である; 2) 軌道、ウェイポイントと呼ばれる、後続の将来のフレームにおけるエージェントの可能な位置のセットを予測する必要がある; これは、エージェント間およびエージェントと道路の間の相互作用を構成する。
これまでの行動予測モデルは、物理ベース、操作ベース、およびインタラクション知覚モデルの 3 つのカテゴリに分類できます。この文は次のように書き換えることができます: 物理モデルの力学的方程式を使用して、人工的に制御可能な動作がさまざまなタイプのエージェント向けに設計されます。この方法では、状況全体の潜在的な状態をモデル化することはできませんが、通常は特定のエージェントにのみ焦点を当てます。しかし、ディープラーニング以前の時代には、この傾向は SOTA でした。マニューバベースのモデルは、エージェントが予期する動きのタイプに基づいたモデルです。インタラクション対応モデルは通常、シーン内の各エージェントに対してペアごとの推論を実行し、すべての動的エージェントに対してインタラクション対応予測を生成する機械学習ベースのシステムです。シーン内で近くにあるさまざまなエージェント ターゲット間には高度な相関関係があります。複雑なエージェント軌跡注意モジュールをモデル化すると、より良い一般化につながる可能性があります。
将来のアクションやイベントの予測は、暗黙的に表現することも、将来の軌道を明示的に表現することもできます。エージェントの意図は次の影響を受ける可能性があります: a) エージェント自身の信念や願望 (これらは観察されないことが多く、モデル化が困難です); b) さまざまな方法でモデル化できる社会的相互作用 (例: プーリング、グラフ ニューラル ネットワーク、注意)など; c) 高解像度 (HD) マップを通じてエンコードできる道路レイアウトなどの環境制約; d) RGB 画像フレーム、LIDAR 点群、オプティカル フロー、セグメンテーション図などの形式の背景情報。一方、軌道予測は、意図の認識とは異なり、分類問題ではなく回帰 (連続) が関係するため、より困難な問題です。
軌道と意図は、相互作用の認識から始める必要があります。交通量の多い高速道路に積極的に進入しようとすると、追い越し車が急ブレーキをかける可能性があると考えるのが合理的です。モデリング。 軌道予測が可能な BEV 空間でモデル化することをお勧めしますが、画像ビュー (遠近法とも呼ばれます) でもモデル化することができます。この文は、「関心領域 (RoI) をグリッドの形式で専用の距離範囲に割り当てることができるためです。」と書き直すことができます。ただし、遠近法の消失線により、画像遠近法は理論的には RoI を無限に拡大できます。 BEV 空間は動きをより線形にモデル化するため、オクルージョンのモデル化に適しています。姿勢推定(自車両の平行移動と回転)を行うことで、自車両の動きの補償を簡単に行うことができます。さらに、このスペースはエージェントの動きとスケールを維持します。つまり、周囲の車両は、自車両からどれだけ離れていても、同じ数の BEV ピクセルを占有します。ただし、これは画像には当てはまりません。視点。未来を予測するには、過去を理解する必要があります。これは通常、追跡を通じて実行することも、過去の集約された BEV 特徴を使用して実行することもできます。
次の図は、予測モデルのいくつかのコンポーネントとデータ フローのブロック図です。
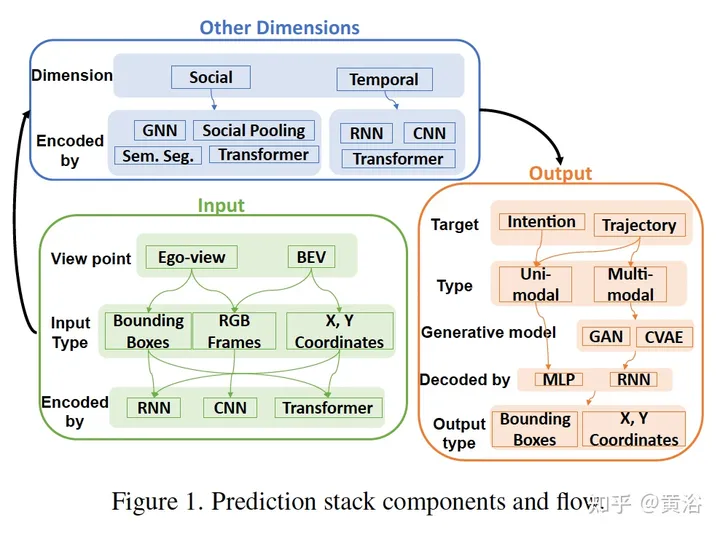
次の表は、予測モデルの概要です。
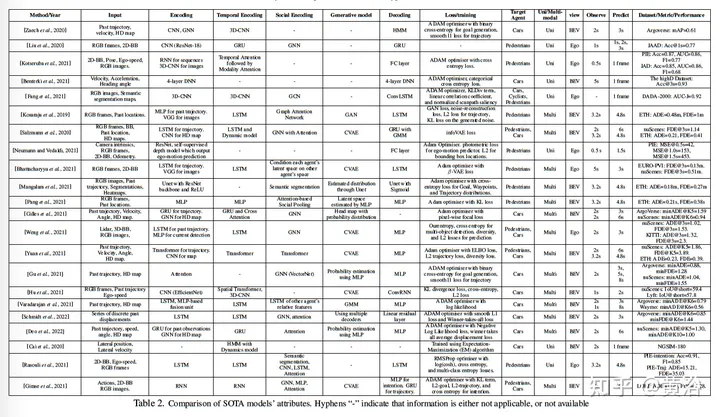
以下では基本的に、入力/出力から始まる予測モデルについて説明します。
1) トラックレット: 認識モジュールは、すべての動的エージェントの現在のステータスを予測します。この状態には、3D 中心、寸法、速度、加速度、その他の属性が含まれます。トラッカーはこのデータを利用して一時的な関連付けを確立し、各トラッカーがすべてのエージェントの状態の履歴を保存できるようにします。ここで、各トラックレットはエージェントの過去の動きを表します。この形式の予測モデルは、入力がまばらな軌跡のみで構成されているため、最も単純です。優れたトラッカーは、現在のフレームでエージェントが遮られている場合でも、エージェントを追跡できます。従来のトラッカーは非機械学習ネットワークに基づいているため、エンドツーエンドのモデルを実装することが非常に困難になります。
2) 生のセンサー データ: これはエンドツーエンドの方法であり、モデルは生のセンサー データ情報を取得し、シーン内の各エージェントの軌道予測を直接予測します。この方法には、複雑なトレーニングを監視するための補助出力とその損失がある場合とない場合があります。このタイプのアプローチの欠点は、入力が大量の情報を必要とし、計算コストがかかることです。これは、知覚、追跡、予測の 3 つの問題が融合しているため、モデルの開発が困難になり、収束の達成がさらに難しくなります。
3) カメラ vs BEV: BEV 手法は、上面図の地図のようなビューからデータを処理し、カメラ予測アルゴリズムは自車の視点から世界を認識します。後者は通常、BEV 手法よりも困難です。前者にはさまざまな理由がありますが、第一に、BEV の知覚では、より広い視野とより豊富な予測情報を得ることができますが、それに比べてカメラの視野は短く、自動車は視野外で計画を立てることができないため、予測範囲が制限されます。ビュー; さらに、カメラはブロックされる可能性が高いため、カメラベースのカメラとは異なります カメラ方式と比較して、BEV 方式は「部分的な可観測性」の課題が少なくなります; 第 2 に、LIDAR データが利用できない限り、単眼視では、アルゴリズムが問題のエージェントの深度を推測することが困難になります。これはエージェントの動作を予測するための重要な手がかりになります。最後に、カメラが移動するため、エージェントと自車両の動きに対処する必要があります。 、静的 BEV とは異なります; 注意事項: 欠点として、BEV 表現方法にはまだ累積誤差の問題があります; ただし、カメラ ビューの処理には固有の課題がありますが、それでも BEV よりも実用的です。また、自動車は、BEV や路上で関係するエージェントの位置を示すカメラにアクセスできることはほとんどありません。結論としては、予測システムは、ライダーやステレオ カメラを含む自車両の視点から世界を見ることができ、そのデータは世界を 3D で認識するのに有利である可能性があるということです。関連するもう 1 つの重要な点は、エージェントの位置を予測する場合、純粋な中心点ではなく境界ボックスの位置を使用する方が良いです。前者の座標は、車両と歩行者の間の相対距離の変化も暗示するためです。カメラの自己の動きとして、言い換えれば、エージェントとして 物体が自車両に近づくにつれて、境界ボックスが大きくなり、追加の (暫定的ではあるが) 深さの推定値が提供されます。
4) 自車の動きの予測: 自車両の動きをモデル化して、より正確な軌道を生成します。他のアプローチでは、ディープ ネットワークまたは動的モデルを使用して、ポーズ、オプティカル フロー、セマンティック マップ、ヒート マップなどのデータセット入力から計算される追加量を利用して、対象のエージェントの動きをモデル化します。
5) 時間領域エンコード: 運転環境は動的であり、アクティブなエージェントが多数存在するため、過去に何が起こったかを比較するより良い予測システムを構築するには、エージェントの時間次元でエンコードする必要があります。未来は現在起こっていることに結びついています。エージェントがどこから来たのかを知ることは、エージェントが次にどこへ行くかを推測するのに役立ちます。ほとんどのカメラベースのモデルはより短い時間スケールを扱いますが、より長い時間スケールでは予測を扱います。モデルにはより複雑な必要があります。構造。
6) ソーシャル エンコーディング: 「マルチエージェント」の課題に対処するために、最もパフォーマンスの高いアルゴリズムのほとんどは、さまざまなタイプのグラフ ニューラル ネットワーク (GNN) を使用してエージェント間のソーシャル インタラクションをエンコードします。時間的次元から始めて社会的次元を検討するか、またはその逆の順序で、社会的次元と社会的次元を別々に検討することができ、両方の次元を同時にエンコードする Transformer ベースのモデルがあります。
7) 期待される目標に基づく予測: シーンのコンテキストと同様に、行動意図の予測は通常、さまざまな期待される目標の影響を受けるため、説明を通じて推測する必要があります。期待される目標を条件とした将来の予測の場合、この目標は次のようにモデル化されます。将来の状態 (目的地座標として定義される) またはエージェントによって予期される動きのタイプ; 神経科学とコンピュータ ビジョンの研究によると、人間は通常、目標指向のエージェントであることが示されています; さらに、意思決定を行う際、人間は一連の連続したレベルに従います。推論し、最終的に短期または長期の計画を策定します。これに基づいて、質問は 2 つのカテゴリに分類できます。1 つ目は認知的なもので、エージェントがどこへ行くのかという質問に答えます。2 つ目は任意の性的なもので、次の質問に答えます。このエージェントが意図した目標をどのように達成するか。
8) マルチモーダル予測: 道路環境は確率的であるため、過去の軌跡が将来の異なる軌跡を展開する可能性があるため、「確率性」の課題を解決する実用的な予測システムは、この問題に大きな影響を与えるでしょう。不確実性はモデル化されます。離散変数の潜在空間モデリングの方法はありますが、マルチモダリティは軌跡にのみ適用され、意図の予測においてその可能性を十分に発揮します。重みの計算に使用できるアテンション メカニズムが使用されます。
以上が軌跡予測のための視覚的手法のレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。