
ホームページ >テクノロジー周辺機器 >AI >Transformer の状況に応じた学習機能の源は何ですか?
Transformer の状況に応じた学習機能の源は何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-09-18 08:01:141515ブラウズ
なぜトランスはこれほど優れた性能を発揮するのでしょうか?多くの大規模な言語モデルにもたらすインコンテキスト学習機能はどこから来るのでしょうか?人工知能の分野では、トランスフォーマーはディープラーニングの主流のモデルとなっていますが、その優れたパフォーマンスの理論的根拠は十分に研究されていません。
最近、Google AI、チューリッヒ工科大学、Google DeepMind の研究者は、Google AI の一部の最適化アルゴリズムの秘密を明らかにするために、新しい研究を実施しました。この研究では、トランスをリバースエンジニアリングし、いくつかの最適化方法を発見しました。この論文は「Transformer における Mesa 最適化アルゴリズムの解明」と呼ばれています。
論文リンク: https://arxiv.org/abs/2309.05858
著者らは、普遍的な自己回帰損失を最小限に抑えると、補助的な勾配ベースの最適化アルゴリズムが Transformer のフォワード パスで動作することを実証しました。この現象は最近「メサ最適化」と呼ばれています。さらに、研究者らは、結果として得られたメサ最適化アルゴリズムが、モデルのサイズに関係なく、状況に応じたスモールショット学習機能を発揮することを発見しました。したがって、新しい結果は、大規模な言語モデルで以前に出現したスモールショット学習の原則を補完します。
研究者らは、Transformers の成功は、フォワード パスでの Mesa 最適化アルゴリズムの実装におけるアーキテクチャ上のバイアス、(i) 内部学習目標の定義、および (ii) に基づいていると考えています。最適化
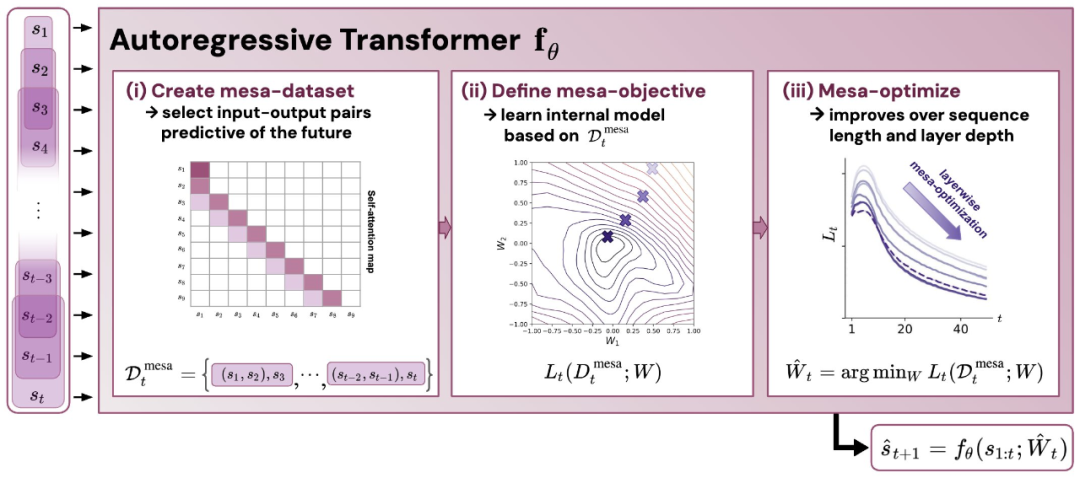
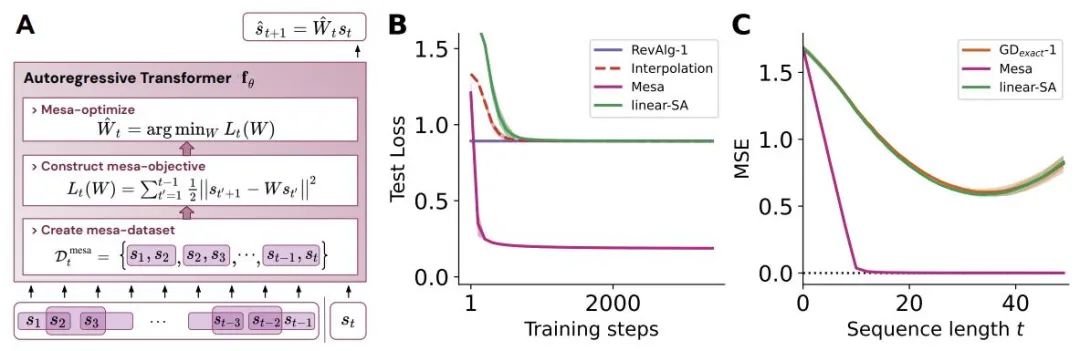
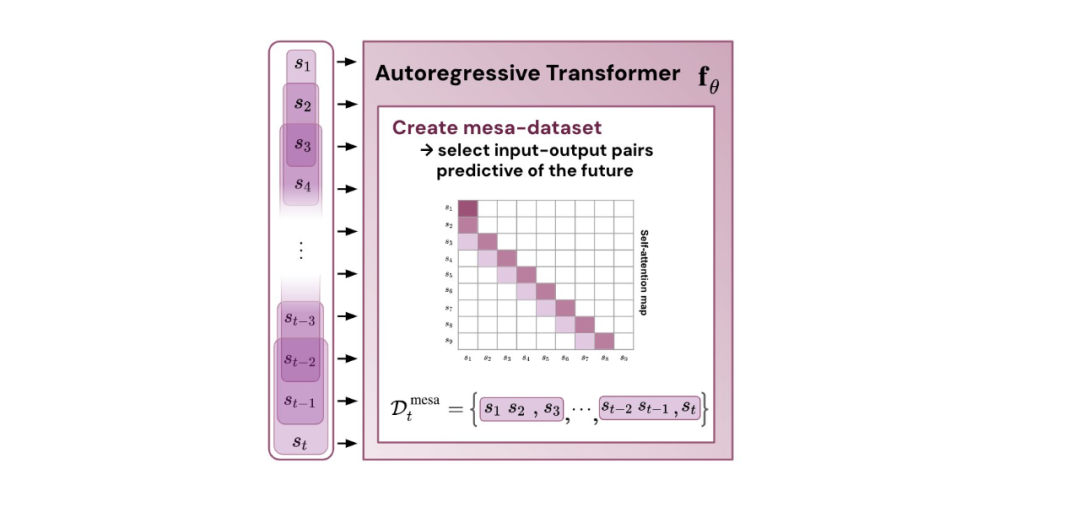
図 1: 新しい仮説の図: 自己回帰変換器 fθ の重み θ を最適化すると、次の順伝播で実装されるメサが生成されます。モデルの最適化。入力シーケンスとして s_1、... 。 、s_t はタイム ステップ t まで処理されます。Transformer は、(i) 入力とターゲットの関連付けペアで構成される内部トレーニング セットを作成します。(ii) 結果データセットを通じて内部目的関数を定義します。これは、内部モデルのパフォーマンスを測定するために使用されます。重み W を使用して、(iii) この目標を最適化し、学習したモデルを使用して将来の予測を生成します。 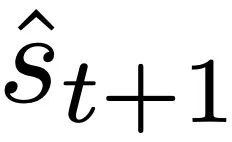
この研究の貢献には次のものが含まれます:
- von Oswald らの理論を要約し、上記のことを実証します。 Transformers は、内部で構築された目標を最適化し、勾配ベースの方法を使用した回帰からシーケンスの次の要素を予測します。
- シンプルなシーケンス モデリング タスクでトレーニングされたトランスフォーマーを実験的にリバース エンジニアリングし、フォワード パスが 2 段階のアルゴリズムを実装しているという強力な証拠を発見しました。 (i) 初期の自己注意層が内部トレーニングを構築するラベルをグループ化してコピーすることでデータセットを作成し、内部トレーニング データセットを暗黙的に構築します。内部目的関数を定義し、(ii) これらの目的をより深いレベルで最適化して予測を生成します。
- LLM と同様に、単純な自己回帰トレーニング モデルもコンテキスト学習者になることが実験で示されており、LLM のコンテキスト学習を改善するにはオンザフライ調整が不可欠であり、特定のパフォーマンスも向上させることができます。環境、パフォーマンス。
- アテンション層が内部目的関数を暗黙的に最適化しようとするという発見に触発されて、著者は、最小の問題を効果的に解決できる新しいタイプのアテンション層であるメサ層を紹介します。最適化を達成するために単一の勾配ステップを実行するのではなく、二乗最適化問題を実行します。実験では、単一のメサ層が、単純な逐次タスクにおいてディープリニアおよびソフトマックスセルフアテンショントランスフォーマーよりも優れたパフォーマンスを発揮し、より高い解釈可能性を提供することを実証しています。

- 言語モデリングの予備実験の後、これを mesa に置き換えることが判明しました。レイヤー 標準のセルフアテンション レイヤーで有望な結果が得られ、レイヤーの強力なコンテキスト学習機能が実証されました。
まず、単純な線形ダイナミクスでトレーニングされた Transformer を分析します。この場合、シーケンス間の記憶を防ぐために、各シーケンスは異なる W* によって生成されます。この単純なセットアップで、研究者らは、Transformer がメサ データセットを作成し、前処理された GD を使用してメサの目標を最適化する方法を示します
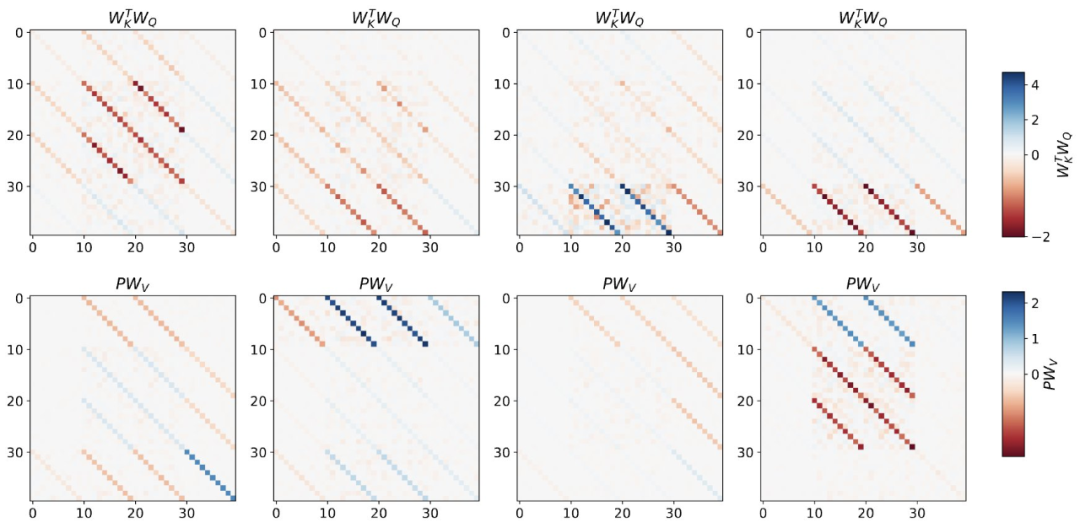
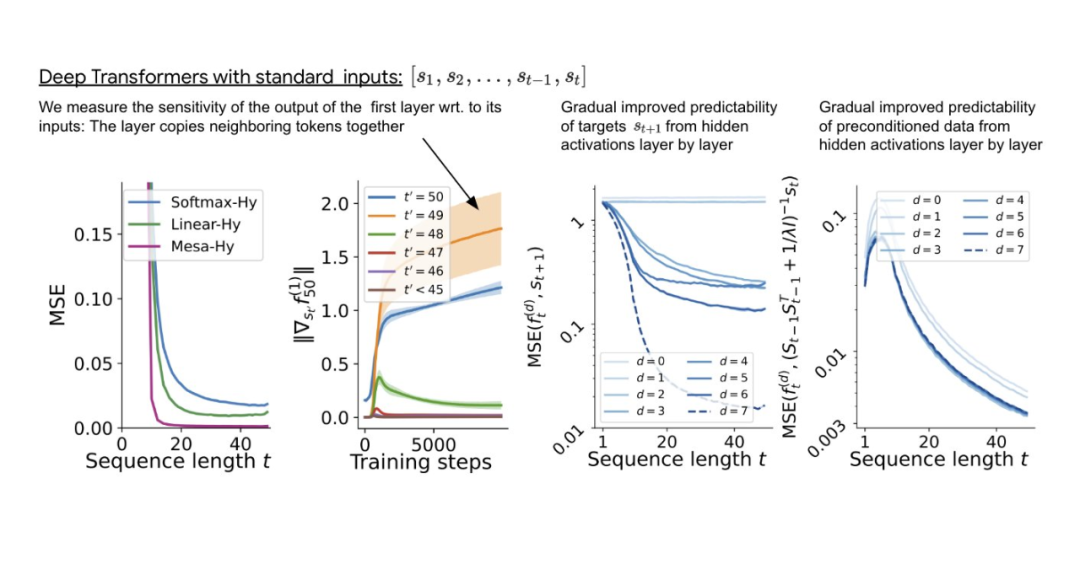
#書き直された内容は次のとおりです。ディープ トランスフォーマーをトレーニングすることで、隣接するシーケンス要素のトークン構造を集約できます。興味深いことに、この単純な前処理方法では、非常にまばらな重み行列 (ゼロ以外の重みが 1% 未満) が生成され、その結果、リバース エンジニアリング アルゴリズム 単層線形セルフアテンションの場合、重みは 1 つの勾配降下ステップに対応します。奥深いトランスフォーマーの場合、解釈が難しくなります。この研究は線形検出に依存しており、隠れたアクティベーションが自己回帰ターゲットまたは前処理された入力を予測できるかどうかを調べています。 興味深いことに、両方の検出方法の予測可能性はネットワークの深さに応じて増加し、徐々に増加します。この発見は、前処理された GD がモデル内に隠されていることを示唆しています。 図 2: トレーニングされた線形自己注意層のリバース エンジニアリング。 研究では、学習された学習率イータだけでなく、学習された初期値のセットも含め、すべての自由度が構築に使用される場合、トレーニング層が完全に適合できることがわかりました。重み W_0 。重要なのは、図 2 に示すように、学習されたワンステップ アルゴリズムは依然として単一メサ層よりもはるかに優れたパフォーマンスを発揮することです。 単純な重み設定を使用すると、基本的な最適化を通じて、この層がこの研究タスクを最適に解決できることが簡単にわかることがわかります。この結果は、ハードコーディングされた誘導バイアスがメサの最適化に有益であることを証明しています。 多層の場合の理論的洞察を利用して、まず深い線形とソフトマックスを分析し、トランスのみに注目します。著者らは、W_0 = 0 の選択に対応する 4 チャネル構造 単層モデルの場合と同様に、著者らはトレーニングされたモデルの重みに明確な構造があることを確認しています。最初のリバース エンジニアリング分析として、この研究ではこの構造を利用し、レイヤー ヘッダーごとに (3200 ではなく) 16 個のパラメーターを含むアルゴリズム (RevAlg-d、d はレイヤー数を表します) を構築します。著者らは、この圧縮されているが複雑な式でトレーニング済みモデルを記述できることを発見しました。特に、実際の Transformer と RevAlg-d の重みの間の補間をほぼロスレスな方法で行うことができます。 RevAlg-d 式はトレーニングされた多層 Transformer を解釈しますが、解釈するのは困難です。それをメサ最適化アルゴリズムとして使用します。したがって、著者らは線形回帰プロービング分析 (Alain & Bengio、2017; Akyürek et al.、2023) を利用して、仮説的なメサ最適化アルゴリズムの特性を見つけました。 図 3 に示すディープ リニア セルフアテンション トランスフォーマーでは、両方のプローブが線形デコード可能であり、シーケンスの長さとネットワークの深さが増加するにつれてデコード パフォーマンスが向上することがわかります。も増えた。そこで、メサ最適化問題の条件数を改善しながら、元のメサ目標Lt(W)に基づいて層ごとに降順する基本的な最適化アルゴリズムを発見しました。これにより、メサ対物レンズの Lt (W) が急速に低下します。さらに、深さが増すにつれてパフォーマンスが大幅に向上することも観察できます。 データの前処理が改善されると、自己回帰目的関数 Lt ( W) が向上するため、次のように考えることができます。この最適化によって急速な降下が達成されることがわかります。 図 3: 構築されたトークン入力 Transformer トレーニングの複数層のリバース エンジニアリング。 これは、トランスフォーマーが構築されたトークンでトレーニングされた場合、メサ最適化を使用して予測することを示しています。興味深いことに、シーケンス要素が直接与えられると、トランスフォーマーは要素をグループ化することで独自にトークンを構築します。これを研究チームは「メサ データセットの作成」と呼んでいます。 この研究の結果は、標準的な自己回帰目標、勾配ベースの推論アルゴリズムの下でシーケンス予測タスクに Transformer モデルを使用してトレーニングした場合に得られるということです。したがって、最新のマルチタスクおよびメタ学習の結果は、従来の自己教師あり LLM トレーニング設定にも適用できます さらに、この研究では、学習された自己回帰推論アルゴリズムが次のような可能性があることもわかりました。教師ありコンテキスト学習タスクを解決し、結果を統一フレームワーク内で解釈するために再トレーニングが必要な場合には、別の Re-adapt で使用できます。 その後、これらとコンテキスト学習との関係は何でしょうか?研究によると、自己回帰シーケンス タスクでトランスフォーマー モデルをトレーニングした後、適切なメサ最適化が達成されるため、微調整を行わずに数ショットのコンテキスト学習を実行できます
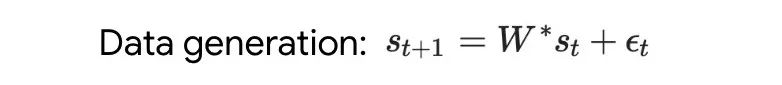
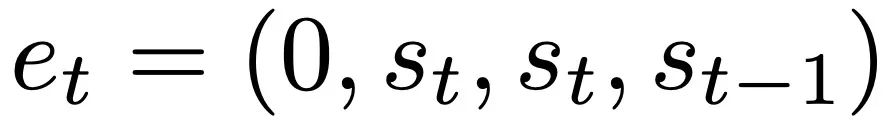 に従って入力をフォーマットします。
に従って入力をフォーマットします。 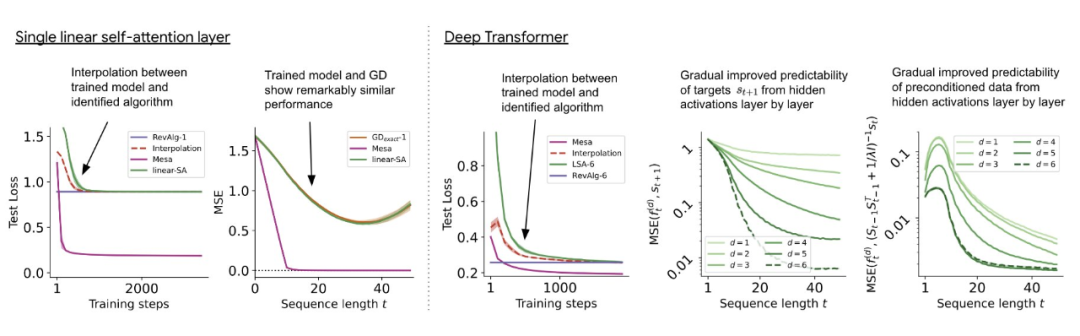
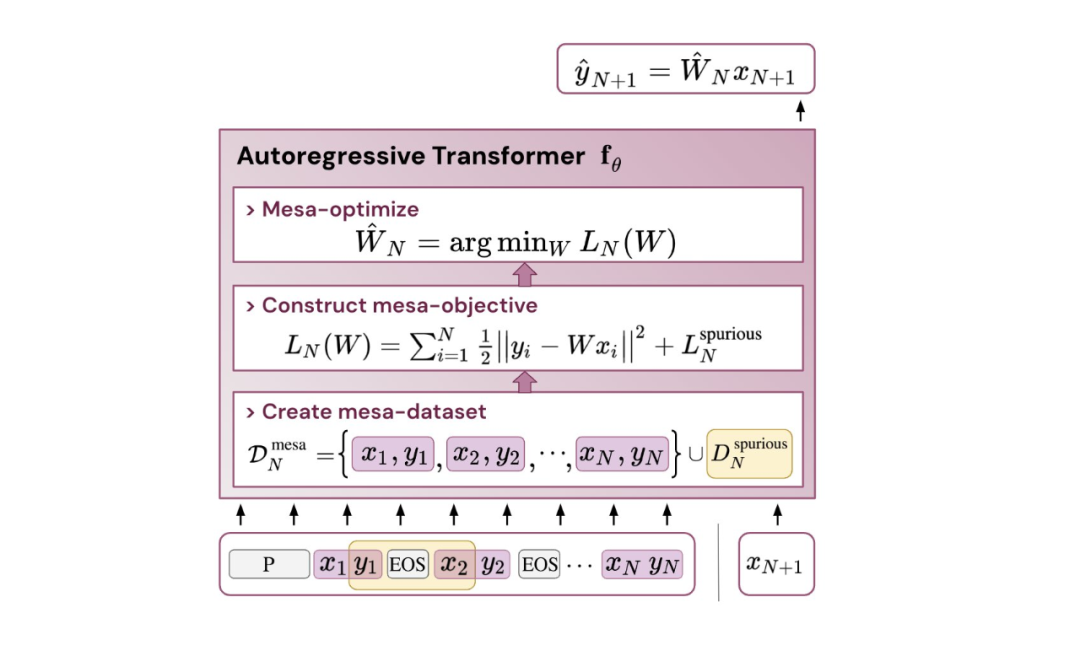
結論
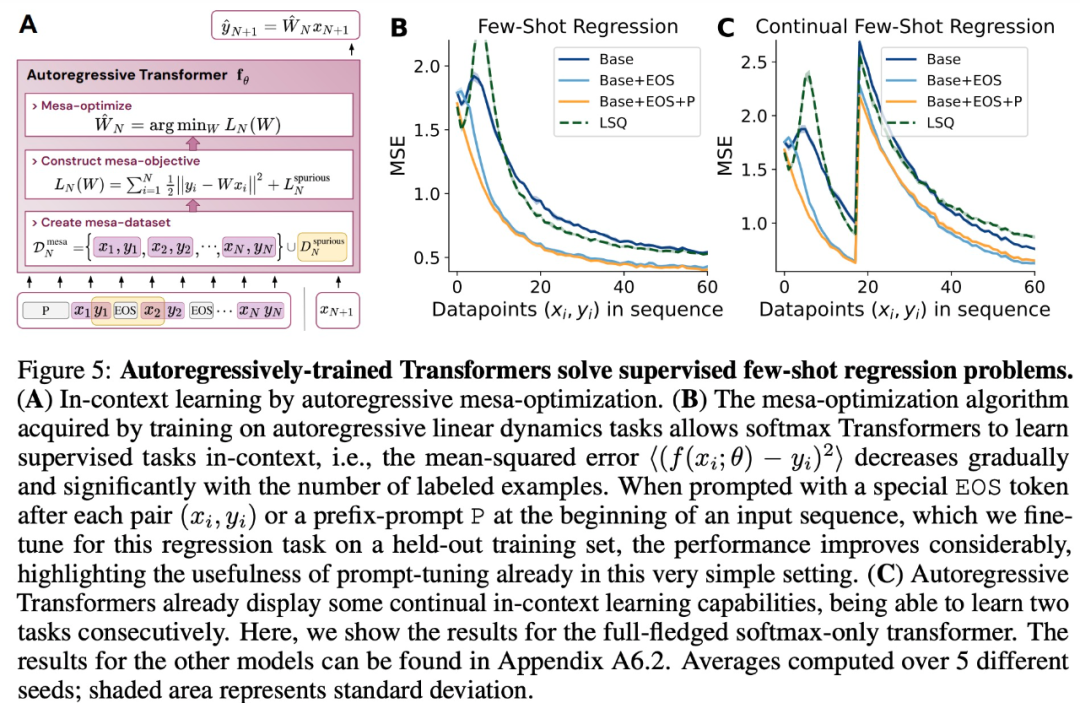
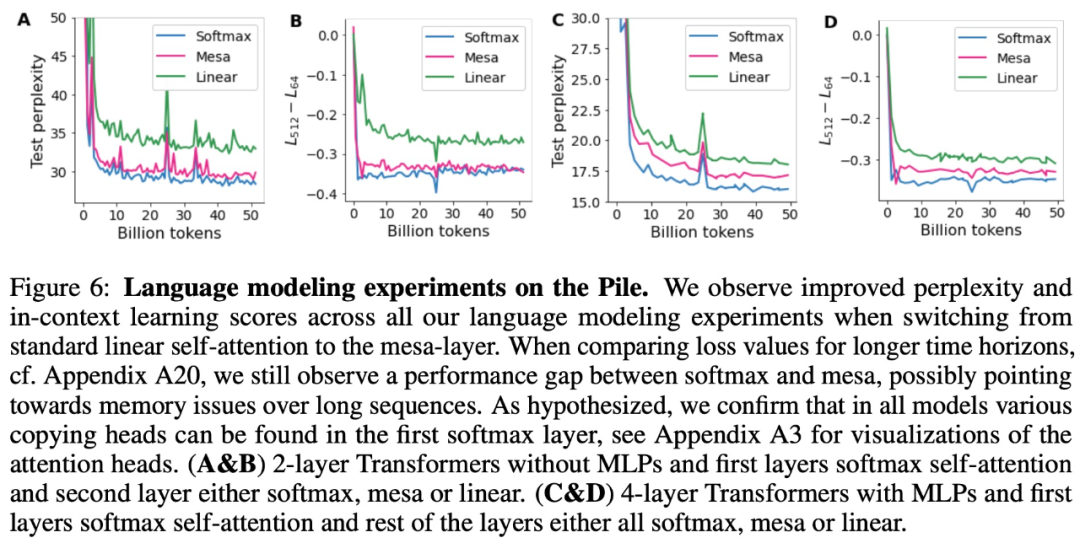 興味のある読者は、論文の原文を読んで学ぶことができます。詳細 さらにコンテンツを調査します。
興味のある読者は、論文の原文を読んで学ぶことができます。詳細 さらにコンテンツを調査します。
以上がTransformer の状況に応じた学習機能の源は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。