
人工知能、機械学習、深層学習の間にはどのような関係があるのでしょうか?

- 青灯夜游オリジナル
- 2021-02-03 15:31:1838873ブラウズ
機械学習は、コンピューターがデータ内の問題を見つけて人工知能アプリケーションを提供できるようにする技術を含む人工知能のサブセットです。ディープラーニングは、コンピューターがより複雑な問題を解決できるようにする機械学習のサブセットです。

このチュートリアルの動作環境: Windows 7 システム、Dell G3 コンピューター。
1.人工知能
人工知能(Artificial Intelligence)、英語の略称はAIです。人間の知性をシミュレートし、拡張し、拡張するための理論、方法、技術、および応用システムを研究および開発する新しい技術科学です。
人工知能は、知能の性質を理解し、人間の知能と同様の方法で応答できる新しいインテリジェントな機械を生み出すことを試みるコンピューター サイエンスの一分野です。この分野の研究には、音声認識、画像認識、ロボット、自然言語処理、インテリジェント検索およびエキスパート システムなど。
人工知能は、人間の意識と思考の情報プロセスをシミュレートできます。人工知能は人間の知能ではありませんが、人間と同じように考えることができ、人間の知能を超える可能性もあります。
2. データマイニング
データマイニングとは、その名の通り、大量のデータから隠された情報を「マイニング」することですが、教科書によると、ここでのデータは「大きくて不完全」です。 .」 「ノイズが多く、あいまいで、ランダムな実用化データ」、情報とは「暗黙的で規則的で、人々には事前に知られていないが、潜在的に役立つ可能性があり、最終的には理解できる情報と知識」を指します。ビジネス環境において、企業はデータベースに保存されたデータが「語り」、意思決定をサポートできることを望んでいます。したがって、データ マイニングはよりアプリケーション指向になります。
データ マイニングは通常、コンピューター サイエンスに関連しており、統計、オンライン分析処理、インテリジェンス検索、機械学習、エキスパート システム (過去の経験則に基づく)、パターン認識などの多くの方法を通じて上記の目標を達成します。
3. 機械学習
機械学習とは、特定のアルゴリズムを使用してコンピューターが既知のデータを使用して適切なモデルを導き出し、このモデルを使用して新しい状況に対する洞察を提供することを指します。判定。
機械学習の考え方は複雑ではなく、人間の生活における学習プロセスのシミュレーションにすぎません。このプロセス全体において、最も重要なものはデータです。
データを通じてトレーニングされた学習アルゴリズムに関する関連研究はすべて機械学習に属します。これには、線形回帰 (線形回帰)、K 平均法 (K 平均法、プロトタイプ) など、長年にわたって開発されてきた多くのテクノロジーが含まれます。ベースの目的関数集計)クラス手法)、Decision Trees(ディシジョン ツリー、確率分析を使用したグラフィカルな手法)、Random Forest(ランダム フォレスト、確率分析を使用したグラフィカルな手法)、PCA(Principal Component Analysis、主成分分析)、SVM(サポートベクターマシン、サポートベクターマシン)とANN(人工ニューラルネットワーク、人工ニューラルネットワーク)。
4. ディープ ラーニング
ディープ ラーニング (Deep Learning) の概念は、人工ニューラル ネットワークの研究から生まれました。複数の隠れ層を持つ多層パーセプトロンは、深層学習構造です。ディープラーニングは、低レベルの特徴を組み合わせてより抽象的な高レベル表現の属性カテゴリまたは特徴を形成することにより、データの分散特徴表現を発見します。
ディープ ラーニングは、機械学習研究の新しい分野です。その動機は、分析と学習のために人間の脳のニューラル ネットワークを構築し、シミュレートすることです。データを解釈する人間の脳のメカニズムを模倣します。画像、音声、テキスト。
5. 人工知能、機械学習、ディープラーニングの関係
厳密に言えば、人工知能と機械学習は直接の関係はありませんが、現在では機械学習の手法が広く使われています。人工知能の問題。現在、機械学習は人工知能の実装手法であり、最も重要な実装手法でもあります。
初期の機械学習は実際にはコンピューター サイエンスではなく統計に属しており、1990 年代以前の古典的な人工知能は機械学習とは何の関係もありませんでした。したがって、今日の AI と ML には重複する部分が多くありますが、厳密な関連性はありません。
しかし、コンピューター部門だけを見てみると、ML は AI に属します。 AI は今日、非常に幅広いテーマになっています。
ディープ ラーニングは機械学習の人気の方向性であり、それ自体がニューラル ネットワーク アルゴリズムから派生したものであり、画像や音声などのリッチ メディアの分類と認識において非常に優れた結果を達成しています。
したがって、人工知能と機械学習を 2 つの分野とみなすと、3 つの関係は次の図のようになります。学習を
人工知能の下位分野として とみなすと、これら 3 つの関係は下図のようになります。 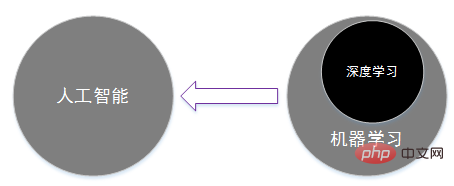
データ マイニングでは、主に機械学習コミュニティが提供するテクノロジーを使用して大量のデータを分析し、データベース コミュニティが提供するテクノロジーを使用して大量のデータを管理します。 
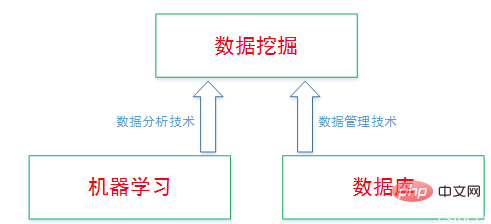
機械学習はデータ マイニングの重要な方法ですが、機械学習は別の分野であり、データ マイニングに従属するものではなく、この 2 つは相互に補完します。
補足:
出典: http://m.elecfans.com/article/691751.html
機械学習プロセスでは次のものを使用します。ステップ 定義:
1. 関連するデータ セットを特定し、分析のために準備します。
2. 使用するアルゴリズムのタイプを選択します。
3. 使用するアルゴリズムに基づいて分析モデルを構築します。
4. テスト データセットに基づいてモデルのトレーニングを実行し、必要に応じてモデルを変更します。
5. モデルを実行してテスト スコアを生成します。
機械学習と深層学習の違い
1. データ量:
マシン学習は、さまざまなデータ量、特にデータ量が少ないシナリオに適応できます。一方で、データ量が急激に増加すると、ディープラーニングの効果がより顕著になります。以下の図は、さまざまなデータ量における機械学習と深層学習のパフォーマンス レベルを示しています。
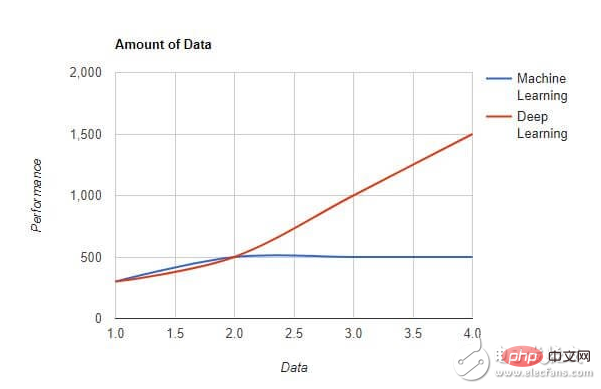
2. ハードウェアの依存関係:
従来の機械学習アルゴリズムとは対照的に、深層学習アルゴリズムはハイエンド機器に大きく依存しています。 。深層学習アルゴリズムは多数の行列乗算演算を実行する必要があるため、それらをサポートするのに十分なハードウェア リソースが必要です。
3. 特徴エンジニアリング:
特徴エンジニアリングは、データの複雑さのレベルを軽減し、データを生成することを目的として、ドメイン固有の知識を指定された特徴に組み込むプロセスです。アルゴリズム学習モードに使用できます。
例: 従来の機械学習モデルは、特徴エンジニアリングに必要なピクセルやその他の属性を見つけることに重点を置いています。深層学習アルゴリズムは、データの他の高レベルの特徴に焦点を当てるため、新しい問題ごとに特徴抽出プログラムの実際の作業負荷が軽減されます。
4. 問題解決アプローチ
従来の機械学習アルゴリズムは、標準的な手順に従って問題を解決します。問題を複数の部分に分割し、個別に解決し、結果を組み合わせて目的の答えを取得します。ディープラーニングは、問題を分割せずに集中的に問題を解決します。
5. 実行時間
実行時間とは、アルゴリズムのトレーニングに必要な時間を指します。ディープラーニングにはより多くのパラメーターが含まれるため、トレーニングに多くの時間がかかり、トレーニングへの時間投資もより重要になります。比較的言えば、機械学習アルゴリズムの実行時間は比較的短いです。
6. 解釈可能性
解釈可能性は、機械学習アルゴリズムと深層学習アルゴリズムの主な違いの 1 つであり、深層学習アルゴリズムは多くの場合、解釈可能ではありません。このため、業界はディープラーニングを使用する前に常によく考えます。
機械学習と深層学習の実用的なアプリケーション:
- 指紋、顔認識、またはナンバー プレートのスキャンによる勤怠パンチの実現 コンピューター ビジョンナンバープレート番号の技術。
- テキスト検索や画像検索など、検索エンジンの情報検索機能。
- 特定のターゲットを特定した自動化された電子メール マーケティング。
- がん腫瘍医学診断またはその他の慢性疾患の異常状態の特定。
- 写真のタグ付けなどの自然言語処理アプリケーション。 Facebook はユーザー エクスペリエンスを向上させるためにこのような機能を提供しています。 ######オンライン広告。
今後の開発トレンド:
業界でデータ サイエンスと機械学習テクノロジーの使用が増えるにつれて、最も重要なこと組織にとって、既存のビジネス プロセスに機械学習ソリューションを導入することは重要です。- ディープラーニングの重要性は、徐々に機械学習を上回っています。事実は、ディープラーニングが現在最も先進的で最も効果的な技術ソリューションの 1 つであることを証明しています。
- 機械学習とディープラーニングは、研究や学術分野でその大きな力を証明します。
- さらに関連記事を読みたい場合は、
以上が人工知能、機械学習、深層学習の間にはどのような関係があるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。