
Maison >Périphériques technologiques >IA >LLMLingua : intégrez LlamaIndex, compressez les astuces et fournissez des services d'inférence de modèles de langage étendus efficaces
LLMLingua : intégrez LlamaIndex, compressez les astuces et fournissez des services d'inférence de modèles de langage étendus efficaces

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-27 17:13:55899parcourir
L'émergence des grands modèles linguistiques (LLM) a stimulé l'innovation dans de multiples domaines. Cependant, la complexité croissante des invites, motivée par des stratégies telles que les invites de chaîne de pensée (CoT) et l'apprentissage contextuel (ICL), pose des défis informatiques. Ces longues invites nécessitent des ressources de raisonnement importantes et nécessitent donc des solutions efficaces. Cet article présentera l'intégration de LLMLingua avec le LlamaIndex propriétaire pour effectuer une inférence efficace
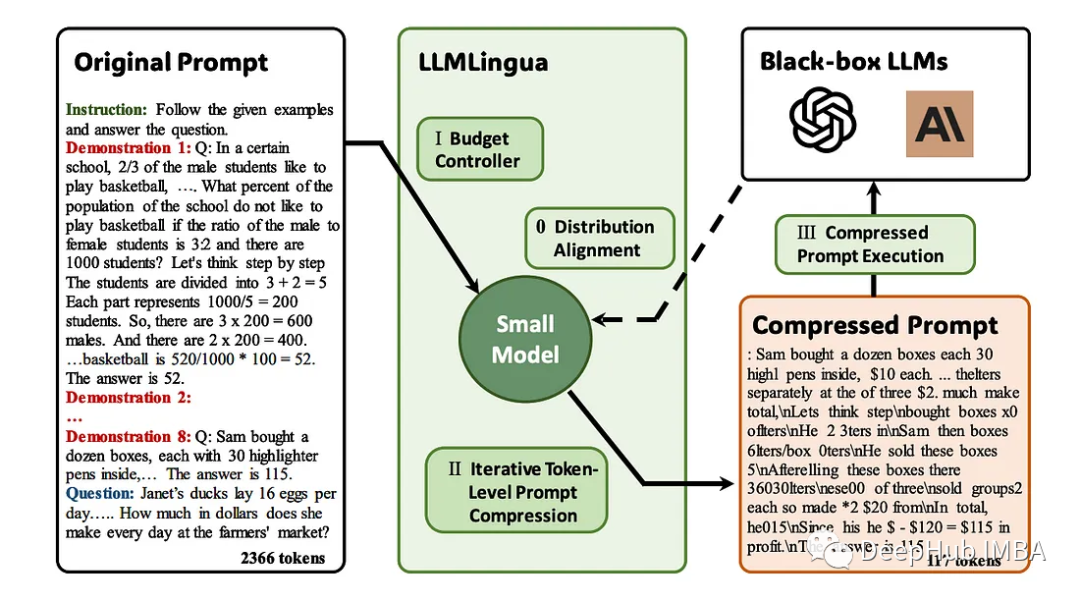
LLMLingua est un article publié par des chercheurs de Microsoft à l'EMNLP 2023. LongLLMLingua est une méthode qui améliore le llm grâce à une compression rapide dans des scénarios de contexte longs. Méthodes pour la capacité de percevoir les informations clés.
LLMLingua travaillant en collaboration avec llamindex
LLMLingua apparaît comme une solution pionnière aux invites verbeuses dans les applications LLM. Cette approche se concentre sur la compression de longues invites tout en garantissant l’intégrité sémantique et en augmentant la vitesse d’inférence. Il combine diverses stratégies de compression pour fournir un moyen subtil d'équilibrer la longueur des indices et l'efficacité des calculs.
Voici les avantages de l'intégration de LLMLingua et LlamaIndex :
L'intégration de LLMLingua et LlamaIndex marque une étape importante pour LLM dans l'optimisation rapide. LlamaIndex est un référentiel spécialisé contenant des indices pré-optimisés adaptés à une variété d'applications LLM, et grâce à cette intégration, LLMLingua peut accéder à un riche ensemble d'indices précis et spécifiques à un domaine, améliorant ainsi ses capacités de compression d'indices.
LLMLingua améliore l'efficacité des applications LLM grâce à une synergie avec la bibliothèque d'astuces d'optimisation de LlamaIndex. En tirant parti des indices spécialisés de LLAMA, LLMLingua peut affiner sa stratégie de compression pour garantir que le contexte spécifique au domaine est préservé tout en réduisant la longueur des indices. Cette collaboration accélère considérablement l'inférence tout en préservant les nuances clés du domaine
LMLMLingua l'intégration avec LlamaIndex étend son impact sur les applications LLM à grande échelle. En tirant parti des conseils d'experts de LAMA, LLMLingua a optimisé sa technologie de compression, réduisant ainsi la charge de calcul liée au traitement des conseils longs. Cette intégration accélère non seulement l'inférence, mais garantit également la conservation des informations critiques spécifiques au domaine. LLMLingua et LlamaIndex . Intégration du framework
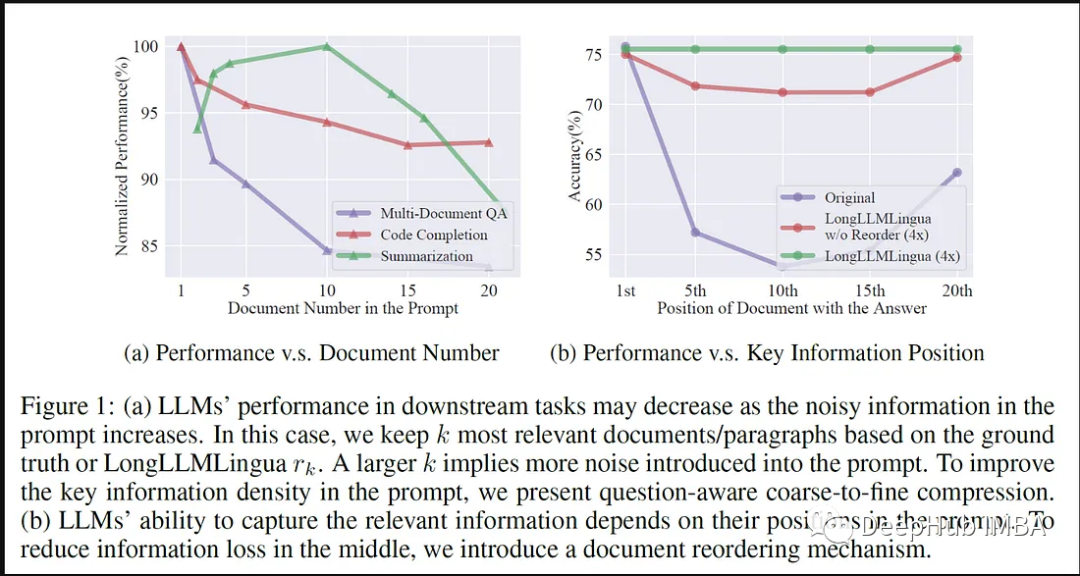 Vous devez d'abord établir une connexion entre LLMLingua et LlamaIndex. Cela inclut les droits d'accès, la configuration de l'API et l'établissement de connexions pour une récupération rapide.
Vous devez d'abord établir une connexion entre LLMLingua et LlamaIndex. Cela inclut les droits d'accès, la configuration de l'API et l'établissement de connexions pour une récupération rapide.
2. Récupération des conseils de pré-optimisation
LlamaIndex sert de référentiel spécialisé contenant des conseils de pré-optimisation adaptés à diverses applications LLM. LLMLingua accède à ce référentiel, récupère des astuces spécifiques au domaine et utilise ces astuces pour la compression
3. Technologie de compression des astuces
LLMLingua utilise sa méthode de compression des astuces pour simplifier les astuces récupérées. Ces techniques se concentrent sur la compression de longues invites tout en garantissant la cohérence sémantique, augmentant ainsi la vitesse d'inférence sans affecter le contexte ou la pertinence.
4. Affiner la stratégie de compression
LLMLlingua affine sa stratégie de compression en fonction des conseils spécialisés qu'elle obtient de LlamaIndex. Ce processus de raffinement garantit que les nuances spécifiques au domaine sont préservées tout en réduisant efficacement la longueur des invites.
5. Exécution et inférence
Après compression à l'aide de la stratégie personnalisée de LLMLingua et combinée avec les astuces de pré-optimisation de LlamaIndex, les astuces résultantes peuvent être utilisées pour les tâches d'inférence LLM. À ce stade, nous effectuons des conseils de compression dans le cadre LLM pour permettre un raisonnement contextuel efficace
6 Améliorations et améliorations itératives
La mise en œuvre du code continue de subir un affinement itératif. Ce processus comprend l'amélioration de l'algorithme de compression, l'optimisation de la récupération des indices de LlamaIndex et le réglage fin de l'intégration pour garantir la cohérence et les performances améliorées des indices compressés et de l'inférence LLM.
7. Tests et vérification
Si nécessaire, des tests et des vérifications peuvent également être effectués, afin que l'efficience et l'efficacité de l'intégration de LLMLingua et LlamaIndex puissent être évaluées. Les mesures de performances sont évaluées pour garantir que les conseils de compression maintiennent l'intégrité sémantique et augmentent la vitesse d'inférence sans compromettre la précision.
Implémentation du code
Nous allons commencer à approfondir l'implémentation du code de LLMLingua et LlamaIndex
Package d'installation :
# Install dependency. !pip install llmlingua llama-index openai tiktoken -q # Using the OAI import openai openai.api_key = "<insert_openai_key>"</insert_openai_key>Obtenir des données :
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
Charger le modèle :
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,load_index_from_storage,StorageContext, ) # load documents documents = SimpleDirectoryReader(input_files=["paul_graham_essay.txt"] ).load_data()Stockage de vecteurs :
index = VectorStoreIndex.from_documents(documents) retriever = index.as_retriever(similarity_top_k=10) question = "Where did the author go for art school?" # Ground-truth Answer answer = "RISD" contexts = retriever.retrieve(question) contexts = retriever.retrieve(question) context_list = [n.get_content() for n in contexts] len(context_list) #Output #10Invite originale et retour
# The response from original prompt from llama_index.llms import OpenAI llm = OpenAI(model="gpt-3.5-turbo-16k") prompt = "\n\n".join(context_list + [question]) response = llm.complete(prompt) print(str(response)) #Output The author went to the Rhode Island School of Design (RISD) for art school.Configurer LLMLingua
from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor node_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder,"dynamic_context_compression_ratio": 0.3,}, )
通过LLMLingua进行压缩
retrieved_nodes = retriever.retrieve(question) synthesizer = CompactAndRefine() from llama_index.indices.query.schema import QueryBundle # postprocess (compress), synthesize new_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=question) ) original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes]) original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts) compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
打印2个结果对比:
print(compressed_contexts) print() print("Original Tokens:", original_tokens) print("Compressed Tokens:", compressed_tokens) print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")
打印的结果如下:
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1] I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. [] the Accademia wasn't, and my money was running out, end year back to thelot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6] Original Tokens: 10719 Compressed Tokens: 308 Comressed Ratio: 34.80x
验证输出:
response = synthesizer.synthesize(question, new_retrieved_nodes) print(str(response)) #Output #The author went to RISD for art school.
总结
LLMLingua与LlamaIndex的集成证明了协作关系在优化大型语言模型(LLM)应用程序方面的变革潜力。这种协作彻底改变了即时压缩方法和推理效率,为上下文感知、简化的LLM应用程序铺平了道路。
这种集成不仅可以提升推理速度,而且可以保证在压缩提示中保持语义的完整性。通过对基于LlamaIndex特定领域提示的压缩策略进行微调,我们平衡了提示长度的减少和基本上下文的保留,从而提高了LLM推理的准确性
从本质上讲,LLMLingua与LlamaIndex的集成超越了传统的提示压缩方法,为未来大型语言模型应用程序的优化、上下文准确和有效地针对不同领域进行定制奠定了基础。这种协作集成预示着大型语言模型应用程序领域中效率和精细化的新时代的到来。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que l'intelligence artificielle Python
- Le but de l'intelligence artificielle est de rendre les machines capables de
- L'appel à communications de l'ICML interdit l'utilisation de grands modèles de langage. LeCun a transmis : Des modèles de petite et moyenne taille peuvent-ils être utilisés ?
- Une étude montre que les grands modèles de langage ont des problèmes de raisonnement logique
- Il existe des preuves. Le MIT montre que les grands modèles de langage ≠ les perroquets aléatoires peuvent effectivement apprendre la sémantique.