
Maison >Périphériques technologiques >IA >Modèles pré-entraînés spécifiques pour le domaine de la PNL biomédicale : PubMedBERT
Modèles pré-entraînés spécifiques pour le domaine de la PNL biomédicale : PubMedBERT

- 王林avant
- 2023-11-27 17:13:461260parcourir
Le développement rapide des grands modèles de langage cette année a conduit à ce que des modèles comme BERT soient désormais appelés « petits » modèles. Lors du concours d'examen scientifique LLM de Kaggle, les joueurs utilisant deberta ont obtenu la quatrième place, ce qui est un excellent résultat. Par conséquent, dans un domaine ou un besoin spécifique, un grand modèle de langage n’est pas nécessairement requis comme meilleure solution, et les petits modèles ont également leur place. Par conséquent, ce que nous allons présenter aujourd'hui est PubMedBERT, un article publié par Microsoft Research à l'ACM en 2022. Ce modèle pré-entraîne BERT à partir de zéro en utilisant des corpus spécifiques à un domaine
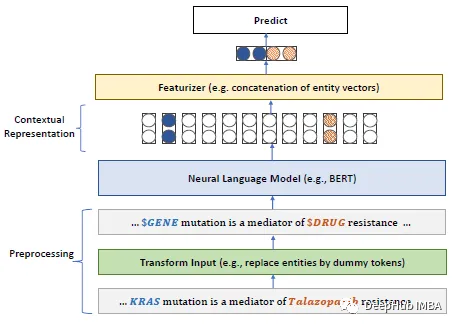
Ce qui suit est les points principaux de l'article :
Pour les domaines spécifiques contenant de grandes quantités de texte non étiqueté, tels que le domaine biomédical, la pré-entraînement des modèles linguistiques à partir de zéro est plus efficace que la pré-entraînement continu des modèles linguistiques du domaine général. À cette fin, nous proposons le Biomedical Language Understanding and Reasoning Benchmark (BLURB) pour la pré-formation spécifique à un domaine
PubMedBERT
1, la pré-formation spécifique à un domaine
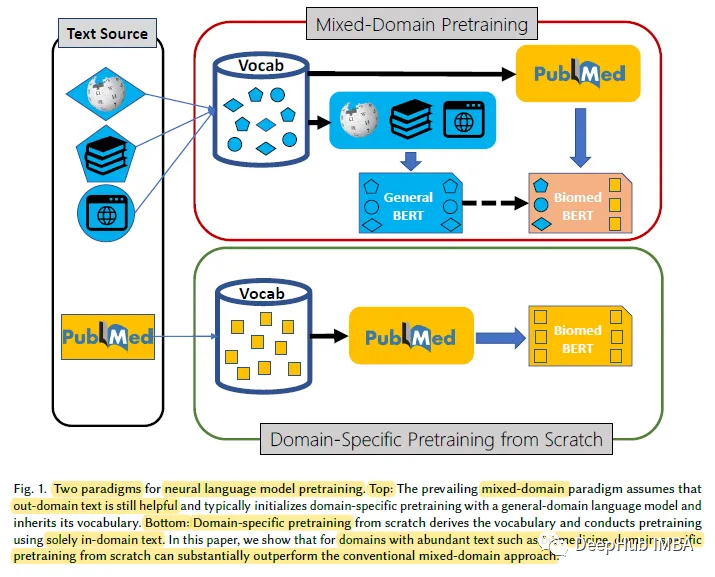
La recherche montre que partir de zéro La pré-formation spécifique surpasse considérablement la pré-formation continue des modèles de langage à usage général, démontrant que les hypothèses dominantes qui sous-tendent la pré-formation dans des domaines mixtes ne s'appliquent pas toujours.
2. Modèle
En utilisant le modèle BERT, pour le modèle de langage de masque (MLM), l'exigence de masquage de mot entier (WWM) est que le mot entier doit être masqué
3. set
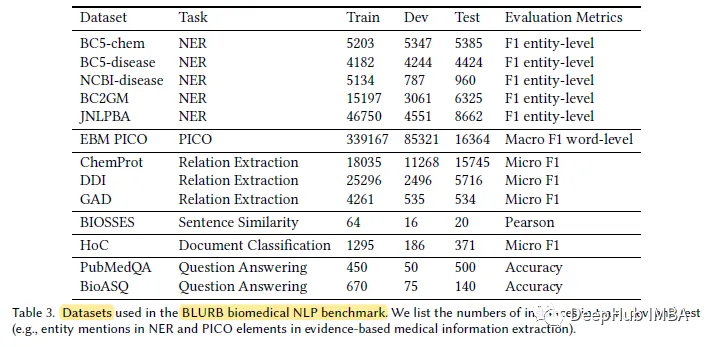
Selon l'auteur, BLUE [45] est la première tentative de création d'une référence en PNL dans le domaine biomédical. Mais la couverture de BLUE est limitée. Pour les applications biomédicales basées sur pubmed, l’auteur propose le Biomedical Language Understanding and Reasoning Benchmark (BLURB).
PubMedBERT utilise un corpus spécifique au domaine plus grand (21 Go).
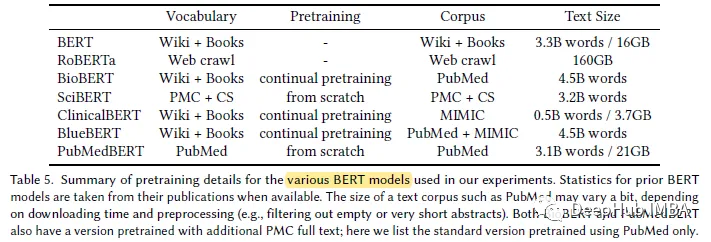
Affichage des résultats
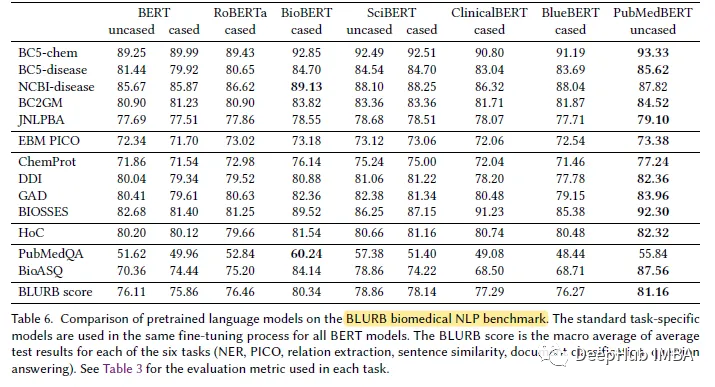
PubMedBERT surpasse systématiquement tous les autres modèles BERT dans la plupart des tâches biomédicales de traitement du langage naturel (PNL), souvent avec un net avantage
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Pour une compréhension complète des grands modèles de langage, voici une liste de lecture
- Les paramètres sont légèrement améliorés, et l'indice de performance explose ! Google : les grands modèles de langage cachent des « compétences mystérieuses »
- Voulez-vous installer ChatGPT sur votre ordinateur ? Le grand modèle de langage open source national ChatGLM vous aide à le réaliser !
- 360 et Zhipu AI ont annoncé une coopération stratégique pour développer conjointement un grand modèle de langage de 100 milliards de niveaux « 360GLM »
- Cet article vous amènera à comprendre le grand modèle de langage universel développé indépendamment par Tencent - le grand modèle Hunyuan.