
Maison >Périphériques technologiques >IA >Il existe des preuves. Le MIT montre que les grands modèles de langage ≠ les perroquets aléatoires peuvent effectivement apprendre la sémantique.
Il existe des preuves. Le MIT montre que les grands modèles de langage ≠ les perroquets aléatoires peuvent effectivement apprendre la sémantique.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-23 08:01:051119parcourir
Bien que les grands modèles linguistiques pré-entraînés (LLM) aient démontré des performances considérablement améliorées dans une gamme de tâches en aval, comprennent-ils vraiment la sémantique du texte qu'ils utilisent et génèrent ?
La communauté de l'IA a longtemps été profondément divisée sur cette question. On suppose que les modèles linguistiques formés uniquement sur la forme du langage (comme la distribution conditionnelle de jetons dans un corpus de formation) n'acquerront aucune sémantique. Au lieu de cela, ils génèrent simplement du texte basé sur des corrélations statistiques superficielles glanées à partir des données de formation, leurs fortes capacités d'émergence étant attribuées à la taille du modèle et des données de formation. Ces personnes appellent LLM le « perroquet aléatoire ».
Mais il y a aussi des personnes qui ne sont pas d'accord avec ce point de vue. Une étude récente a montré qu'environ 51 % des personnes interrogées dans la communauté PNL conviennent que « certains modèles génératifs formés uniquement sur le texte, avec suffisamment de données et de ressources informatiques, peuvent comprendre la nature d'une manière significative (au-delà des corrélations statistiques au niveau de la surface, impliquant une compréhension). » de la sémantique et des concepts derrière le langage) ».
Afin d'explorer cette question sans réponse, des chercheurs du MIT CSAIL ont mené une étude détaillée.

Adresse papier : https:/ /paperswithcode.com/paper/evidence-of-meaning-in-lingual-models
Le modèle de langage utilisé dans cette étude a été uniquement formé pour le texte prédiction Un modèle de jeton et formule deux hypothèses :
- H1 : LM formé uniquement en prédisant le prochain jeton sur le texte est fondamentalement limité. H2LM ne parvient pas à attribuer un sens à le texte qu'il digère et génère grâce à la répétition de corrélations statistiques au niveau de la surface dans son corpus de formation ;
- Afin d'explorer l'exactitude des deux hypothèses H1 et H2, cette étude applique la modélisation du langage à la tâche de synthèse du programme, c'est-à-dire compte tenu des entrées et produire des programmes de synthèse dans le cas d'exemples de spécifications formelles. Cette étude adopte cette approche principalement parce que la signification (et l'exactitude) d'un programme est entièrement déterminée par la sémantique du langage de programmation.
Plus précisément, cette étude entraîne un modèle de langage (LM) sur un corpus de programmes et leurs spécifications, puis utilise un classificateur linéaire pour détecter la représentation cachée de la sémantique représentation du programme par l’état LM. L'étude a révélé que la capacité du détecteur à extraire la sémantique est stochastique lors de l'initialisation, puis subit un changement de phase au cours de la formation, qui est fortement corrélé à la capacité du LM à générer des programmes corrects sans avoir vu les spécifications. De plus, l'étude présente les résultats d'une expérience interventionnelle montrant que la sémantique est représentée dans les états du modèle (plutôt que apprise via des sondes).
Les principales contributions de cette recherche comprennent :
1 Les résultats expérimentaux montrent que lors de l'exécution du. la prédiction des prochaines représentations significatives a émergé dans le LM de la tâche symbolique. Plus précisément, l'étude utilise un LM entraîné pour générer des programmes à partir de plusieurs exemples d'entrées-sorties, puis entraîne un détecteur linéaire pour extraire des informations sur l'état du programme à partir de l'état du modèle. Les chercheurs ont découvert que la représentation interne contient le codage linéaire suivant : (1) sémantique abstraite (interprétation abstraite) - suivi des entrées spécifiées pendant l'exécution du programme ; (2) prédictions de l'état futur du programme correspondant aux jetons du programme qui n'ont pas encore été générés. Au cours de la formation, ces représentations linéaires de la sémantique se développent parallèlement à la capacité du LM à générer des programmes corrects lors de l'étape de formation.
2. Cette étude a conçu et évalué une nouvelle méthode interventionnelle pour explorer les contributions du LM et des détecteurs lors de l'extraction du sens des représentations. Plus précisément, cette étude tente d'analyser laquelle des deux questions suivantes est vraie : (1) les représentations LM contiennent des transcriptions pures (syntaxiques) tandis que le détecteur apprend à interpréter les transcriptions pour en déduire une signification ; (2) les représentations LM contiennent simplement un état sémantique, les détecteurs ; extraire le sens des états sémantiques. Les résultats expérimentaux montrent que la représentation LM est en fait alignée sur la sémantique originale (plutôt que de simplement coder du contenu lexical et syntaxique), ce qui suggère que l'hypothèse H2 est fausse.
3. Cette étude montre que le résultat du LM est différent de la distribution de la formation, ce qui se manifeste spécifiquement par le fait que LM a tendance à générer des programmes plus courts que ceux de l'ensemble de formation (tout en étant corrects). Bien que la capacité de LM à synthétiser des programmes corrects se soit améliorée, la perplexité de LM sur les programmes de l'ensemble d'entraînement reste élevée, ce qui indique que l'hypothèse H1 est fausse.
Dans l'ensemble, cette étude propose un cadre pour étudier empiriquement le LM basé sur la sémantique des langages de programmation. Cette approche nous permet de définir, mesurer et expérimenter des concepts issus de la sémantique formelle précise du langage de programmation sous-jacent, contribuant ainsi à la compréhension des capacités émergentes des LM actuels.
Contexte de recherche
Cette recherche utilise la sémantique de traçage comme modèle de signification de programme. En tant que sujet fondamental de la théorie des langages de programmation, la sémantique formelle étudie comment attribuer formellement une sémantique aux chaînes dans un langage. Le modèle sémantique utilisé dans cette étude consiste à retracer l'exécution d'un programme : étant donné un ensemble d'entrées (c'est-à-dire des affectations de variables), la signification d'un programme (syntaxique) est identifiée par des valeurs sémantiques calculées à partir des expressions, et la trace est exécuté en fonction des entrées Une séquence de valeurs intermédiaires générées par le programme.
Il existe plusieurs raisons importantes d'utiliser les traces de trace pour les modèles de signification de programme : premièrement, la capacité de tracer avec précision un morceau de code est directement liée à la capacité d'interpréter le le code ; deuxièmement, l'enseignement de l'informatique souligne également que le traçage est une méthode importante pour comprendre le développement de programmes et localiser les erreurs de raisonnement ; troisièmement, le développement de programmes professionnels repose sur des débogueurs basés sur les traces (dbugger).
L'ensemble de formation utilisé dans cette étude contient 1 million de programmes Karel échantillonnés au hasard. Dans les années 1970, Rich Pattis, diplômé de l'Université de Stanford, a conçu un environnement de programmation permettant aux étudiants d'apprendre aux robots à résoudre des problèmes simples. Ce robot s'appelait le robot Karel.
Cette étude utilise un échantillonnage aléatoire pour construire un programme de référence pour la formation des échantillons, puis échantillonne 5 entrées aléatoires et exécute le programme pour obtenir les 5 sorties correspondantes. Le LM est formé pour effectuer la prédiction du prochain jeton sur un corpus d'échantillons. Au moment des tests, cette étude ne fournit que des préfixes d'entrée et de sortie à LM et utilise un décodage glouton pour compléter le programme. La figure 1 ci-dessous représente l'achèvement d'un programme de référence réel et le LM formé.
L'étude a entraîné un modèle Transformer prêt à l'emploi pour effectuer la prochaine prédiction de jeton sur l'ensemble de données. Après 64 000 étapes de formation et environ 1,5 époques, le LM finalement formé a atteint une précision de génération de 96,4 % sur l'ensemble de test. Toutes les 2 000 étapes de formation, l’étude a capturé un ensemble de données de trace. Pour chaque ensemble de données de trajectoire de formation, cette étude entraîne un détecteur linéaire pour prédire l'état du programme en fonction de l'état du modèle.
L'émergence du sens
Les chercheurs ont étudié l'hypothèse suivante : Dans le processus d'entraînement d'un modèle de langage pour effectuer la prochaine prédiction de jeton, la sémantique La représentation de l’État apparaît comme un sous-produit de l’État modèle. Considérant que le modèle de langage finalement formé a atteint une précision de génération de 96,4 %, si cette hypothèse est rejetée, elle serait cohérente avec H2, c'est-à-dire que le modèle de langage a appris à utiliser « uniquement » les statistiques de surface pour générer de manière cohérente des programmes corrects.
Pour tester cette hypothèse, les chercheurs ont entraîné un détecteur linéaire pour extraire l'état sémantique de l'état du modèle sous forme de 5 tâches indépendantes à 4 voies (chaque entrée fait face à une direction) , comme décrit à la section 2.2.
L'émergence du sens est positivement corrélée à l'exactitude de la génération
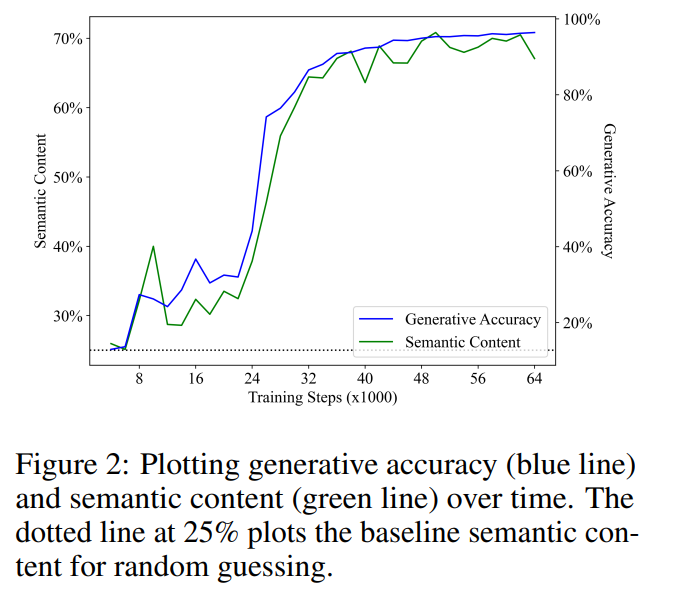
#🎜 🎜#La figure 2 présente les principaux résultats. Notre première observation est que le contenu sémantique part de la performance de base de devinettes aléatoires (25 %) et augmente de manière significative au cours de la formation. Ce résultat montre que l’état caché du modèle de langage contient effectivement un codage (linéaire) de l’état sémantique et, surtout, cette signification émerge dans un modèle de langage qui est uniquement utilisé pour effectuer des prédictions de jetons sur le texte.
Une régression linéaire a été effectuée entre la précision de la génération et le contenu sémantique, et les deux ont montré une corrélation linéaire étonnamment forte et statistiquement significative dans l'étape de formation (R2 = 0,968, p
La représentation est une prédiction de la sémantique future du programme
La section précédente a discuté de la question de savoir si un modèle de langage peut représenter le sens du texte qu'il génère. Les résultats de cet article donnent une réponse positive à la question selon laquelle les modèles de langage sont capables d'expliquer (abstraitement) les programmes générés. Cependant, l’interprète n’est pas la même chose que le synthétiseur, et la capacité de comprendre à elle seule ne suffit pas pour générer. En ce qui concerne l’émergence du langage humain, il existe un large consensus selon lequel le langage provient d’un message non verbal dans l’esprit, qui est ensuite transformé en un énoncé reflétant le concept original. Les chercheurs émettent l’hypothèse que le processus de génération du modèle de langage formé suit un mécanisme similaire, c’est-à-dire que la représentation du modèle de langage code la sémantique du texte qui n’a pas encore été généré.
Pour tester cette hypothèse, ils ont entraîné un détecteur linéaire en utilisant la même méthode que ci-dessus pour prédire les futurs états sémantiques dérivés de l'état du modèle. Notez que puisqu’ils utilisent une stratégie de décodage gourmande, le futur état sémantique est également déterministe et donc la tâche est bien définie.
La figure 3 montre les performances du détecteur linéaire dans la prédiction de l'état sémantique des prochaines étapes 1 et 2 (la ligne de segment verte représente "Sémantique (+1)", la ligne pointillée verte représente "Sémantique (+2) ") . Semblables aux résultats précédents, les performances du détecteur ont commencé à partir d'une base de suppositions aléatoires, puis se sont améliorées de manière significative avec la formation. Ils ont également constaté que le contenu sémantique des états futurs montrait une forte corrélation avec la précision de la génération (ligne bleue) au cours de l'étape de formation. sexe. Les valeurs R2 obtenues par analyse de régression linéaire du contenu sémantique et de la précision de génération sont respectivement de 0,919 et 0,900, correspondant au statut sémantique de 1 étape et 2 étapes dans le futur, et les valeurs p des deux sont inférieures à 0,001.
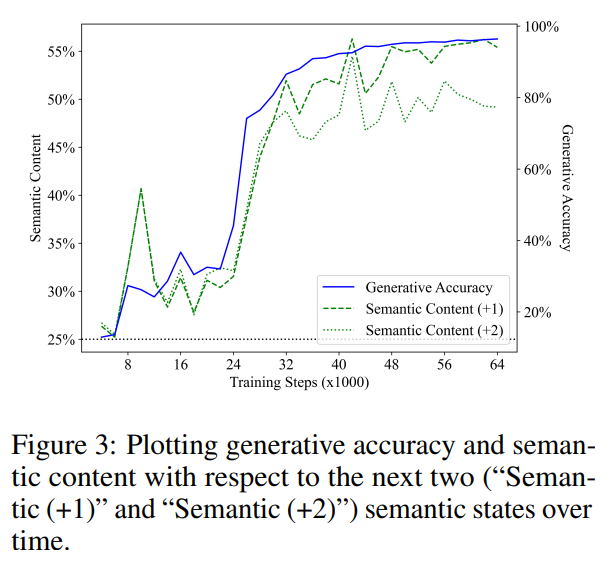
Ils ont également considéré l'hypothèse selon laquelle la représentation du modèle code uniquement l'état sémantique actuel, et le détecteur prédit simplement l'état sémantique futur à partir de l'état sémantique actuel. Pour tester cette hypothèse, ils ont calculé un classificateur optimal qui mappe la direction orientée vers la vérité terrain dans le programme actuel à l'une des 4 directions orientées vers les programmes futurs.
Il convient de noter que 3 des 5 opérations maintiennent la direction orientée et que le jeton suivant est échantillonné uniformément. Par conséquent, ils s’attendaient à ce que, pour la situation à un pas dans le futur, le classificateur optimal pour prédire l’état sémantique futur atteigne une précision de 60 % en prédisant que la direction orientée reste inchangée. En fait, en ajustant directement l’ensemble de tests, ils ont constaté que les limites supérieures de prédiction des états sémantiques futurs à partir de l’état sémantique actuel sont respectivement de 62,2 % et 40,7 % (correspondant aux cas 1 étape et 2 étapes dans le futur). En comparaison, les détecteurs étaient précis à 68,4 % et 61,0 % dans la prévision des états futurs, étant donné que le détecteur avait correctement prédit l'état actuel.
Cela montre que la capacité du détecteur à extraire les états sémantiques futurs des états du modèle ne peut pas être déduite uniquement à partir des représentations des états sémantiques actuels. Par conséquent, leurs résultats montrent que les modèles de langage apprennent à représenter la signification des jetons qui n'ont pas encore été générés, ce qui rejette l'idée selon laquelle les modèles de langage ne peuvent pas apprendre la signification (H2), et montrent également que le processus de génération n'est pas basé sur des statistiques purement superficielles. (H1).
Le résultat généré est différent de la distribution de formation
Ensuite, les chercheurs fournissent des preuves pour réfuter H1 en comparant la distribution de programme générée par le modèle de langage formé avec la distribution de programme dans l'ensemble de formation. Si H1 est vérifié, ils s’attendent à ce que les deux distributions soient à peu près égales, car le modèle linguistique reproduit simplement les corrélations statistiques du texte dans l’ensemble d’apprentissage.
La figure 6a montre la durée moyenne des programmes générés par LM au fil du temps (ligne bleue continue), comparée à la durée moyenne du programme de référence dans l'ensemble d'entraînement (ligne rouge pointillée). Ils ont trouvé une différence statistiquement significative, indiquant que la distribution des résultats du LM est effectivement différente de la distribution des programmes dans son ensemble de formation. Cela contredit le point mentionné dans H1 selon lequel LM ne peut reproduire que des corrélations statistiques dans ses données d'entraînement.
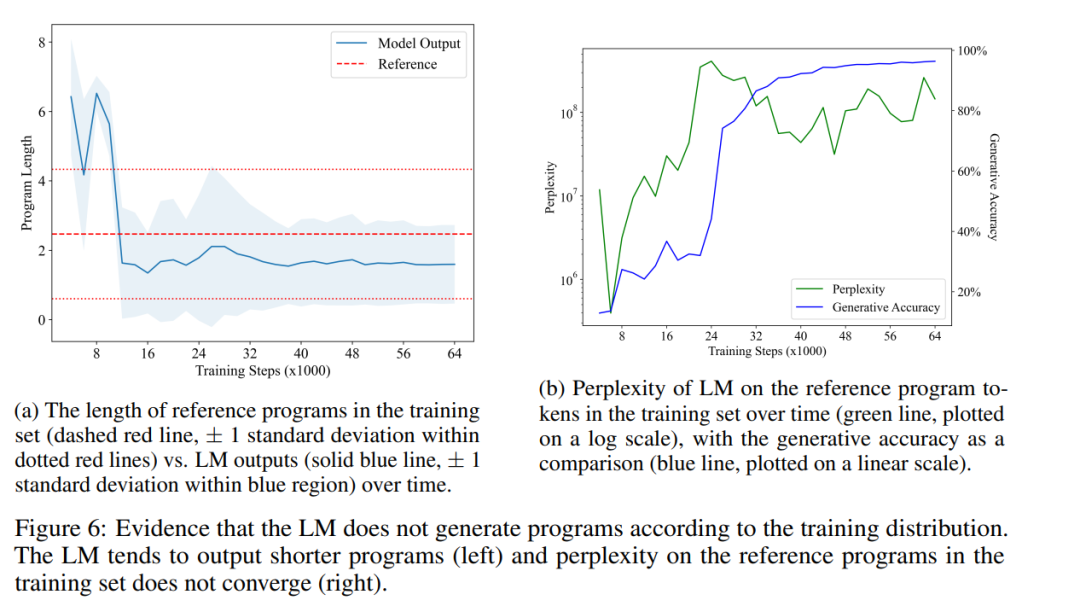
Enfin, ils ont également mesuré comment la perplexité des LM sur le programme dans l'ensemble d'entraînement évoluait au fil du temps. La figure 6b montre leurs résultats. Comme on peut le voir, LM n’apprend jamais à bien s’adapter à la répartition des programmes dans l’ensemble de formation, ce qui réfute encore davantage H1. Cela peut être dû au fait que les programmes échantillonnés aléatoirement dans l'ensemble d'entraînement contiennent de nombreuses instructions sans opération, alors que LM préfère générer des programmes plus concis. Il est intéressant de noter qu’une forte augmentation de la perplexité – à mesure que le LM dépasse le stade de l’imitation – semble conduire à des améliorations de la précision de la génération (et du contenu sémantique). Puisque le problème de l'équivalence des programmes est étroitement lié à la sémantique des programmes, la capacité de LM à générer des programmes courts et corrects montre qu'il a effectivement appris certains aspects de la sémantique.
Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI