
Maison >Périphériques technologiques >IA >Mieux que Transformer, BERT et GPT sans attention et les MLP sont en réalité plus forts.
Mieux que Transformer, BERT et GPT sans attention et les MLP sont en réalité plus forts.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-30 14:33:04906parcourir
Des modèles de langage tels que BERT, GPT et Flan-T5 aux modèles d'image tels que SAM et Stable Diffusion, Transformer balaye le monde à un rythme rapide, mais les gens ne peuvent s'empêcher de se demander : Transformer est-il le seul choix ?
Une équipe de recherche de l'Université de Stanford et de l'Université d'État de New York à Buffalo apporte non seulement une réponse négative à cette question, mais propose également une nouvelle technologie alternative : Monarch Mixer. Récemment, l'équipe a publié des articles pertinents ainsi que des modèles de points de contrôle et des codes de formation sur arXiv. D'ailleurs, cet article a été sélectionné pour NeurIPS 2023 et qualifié pour la présentation orale.

Lien papier : https://arxiv.org/abs/2310.12109
L'adresse du code sur GitHub est : https://github.com/HazyResearch/m2
Cette méthode supprime L'attention et le MLP coûteux de Transformer sont remplacés par des matrices Monarch expressives, ce qui lui permet d'obtenir de meilleures performances à moindre coût dans les expériences de langage et d'images.
Ce n'est pas la première fois que l'Université de Stanford propose une technologie alternative à Transformer. En juin de cette année, une autre équipe de l'école a également proposé une technologie appelée Backpack. Veuillez vous référer à l'article de Heart of Machine "Stanford Training Transformer Alternative Model: 170 Million Parameters, Debiased, Controllable and Highly Interpretable". Bien entendu, pour que ces technologies connaissent un réel succès, elles doivent être testées davantage par la communauté des chercheurs et transformées en produits pratiques et utiles entre les mains des développeurs d'applications
Jetons un coup d'œil à l'introduction de Monarch Mixer et à quelques résultats des expériences présentées dans cet article.
Paper Introduction
Dans les domaines du traitement du langage naturel et de la vision par ordinateur, les modèles d'apprentissage automatique ont été capables de gérer des séquences plus longues et des représentations de plus grande dimension, prenant ainsi en charge un contexte plus long et une qualité supérieure. Cependant, la complexité temporelle et spatiale des architectures existantes présente un modèle de croissance quadratique de la longueur des séquences et/ou des dimensions du modèle, ce qui limite la longueur du contexte et augmente les coûts de mise à l'échelle. Par exemple, l'attention et le MLP dans Transformer évoluent de manière quadratique avec la longueur de la séquence et la dimensionnalité du modèle.
En réponse à ce problème, cette équipe de recherche de l'Université de Stanford et de l'Université d'État de New York à Buffalo affirme avoir trouvé une architecture performante dont la complexité croît de manière subquadratique avec la longueur de la séquence et la dimension du modèle (sous-quadratique).
Leurs recherches s'inspirent de MLP-mixer et ConvMixer. Ces deux études observent que : De nombreux modèles d'apprentissage automatique mélangent les informations le long des dimensions de séquence et de modèle sous forme d'axes, et fonctionnent souvent sur les deux axes à l'aide d'un seul opérateur
à la recherche d'opérateurs de mixage expressifs, sous-quadratiques et matériels. Il est difficile de trouver des opérateurs de mixage efficaces. mettre en œuvre. Par exemple, MLP dans MLP-mixer et les convolutions dans ConvMixer sont tous deux expressifs, mais ils évoluent tous deux de manière quadratique avec la dimension d'entrée. Certaines études récentes ont proposé des méthodes hybrides de séquences sous-quadratiques. Ces méthodes utilisent des convolutions plus longues ou des modèles d'espace d'état, et elles utilisent toutes la FFT. Cependant, l'utilisation du FLOP de ces modèles est très faible et la dimensionnalité du modèle est très faible. encore une deuxième extension. Dans le même temps, des progrès prometteurs ont été réalisés sur les couches MLP denses et clairsemées sans compromettre la qualité, mais certains modèles peuvent en réalité être plus lents que les modèles denses en raison d'une moindre utilisation du matériel.
Sur la base de ces inspirations, l'équipe de recherche a proposé Monarch Mixer (M2), qui utilise une matrice structurée sous-quadratique expressive : la matrice Monarch
La matrice Monarch est une matrice de structure de transformée de Fourier rapide (FFT) généralisée , la recherche montre qu'il contient une variété de transformations linéaires, telles que la transformée de Hadamard, la matrice de Toplitz, la matrice AFDF et la convolution, etc. Ces matrices peuvent être paramétrées par le produit de matrices diagonales de blocs. Ces paramètres sont appelés facteurs Monarch et sont liés à l'entrelacement de permutation. Leur calcul est sous-quadratique : si le nombre de facteurs est fixé à p, alors lorsque la longueur d'entrée est N, le nombre de facteurs est défini sur p. la complexité de calcul est
, de sorte que la complexité de calcul peut être comprise entre O (N log N) lorsque p = log N et lorsque p = 2. 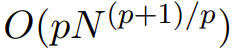 M2 utilise une matrice Monarch pour mélanger les informations le long des axes de séquence et de dimension du modèle. Non seulement cette approche est facile à mettre en œuvre, mais elle est également efficace sur le plan matériel : les facteurs Monarch en diagonale bloquée peuvent être calculés efficacement à l'aide d'un matériel moderne prenant en charge le GEMM (algorithme de multiplication matricielle généralisée).
M2 utilise une matrice Monarch pour mélanger les informations le long des axes de séquence et de dimension du modèle. Non seulement cette approche est facile à mettre en œuvre, mais elle est également efficace sur le plan matériel : les facteurs Monarch en diagonale bloquée peuvent être calculés efficacement à l'aide d'un matériel moderne prenant en charge le GEMM (algorithme de multiplication matricielle généralisée).
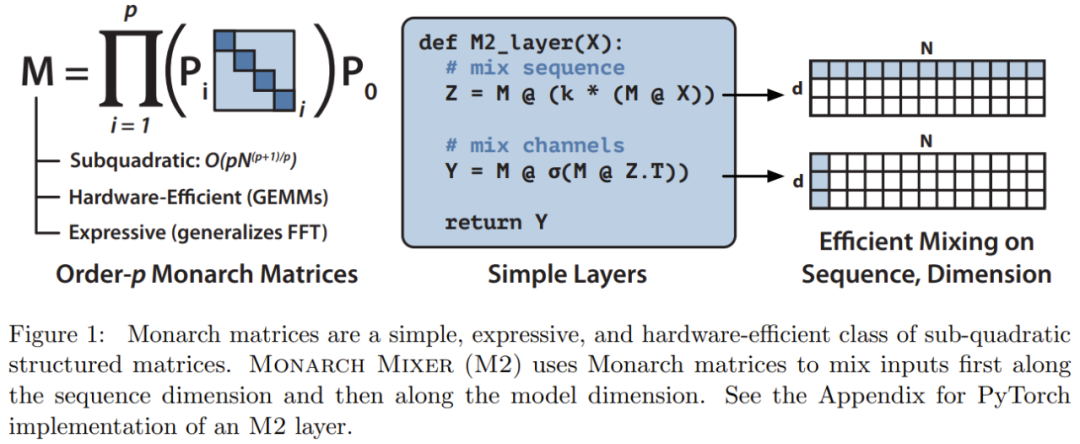
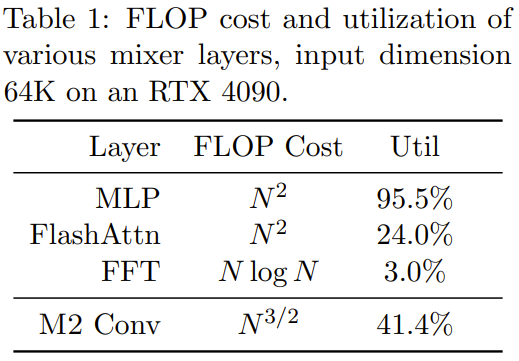
L'équipe de recherche a implémenté une couche M2 en moins de 40 lignes en écrivant du code à l'aide de PyTorch, et s'est appuyée uniquement sur la multiplication matricielle, la transposition, le remodelage et le produit par élément (voir pseudo au milieu du code de la figure 1). Pour une taille d'entrée de 64 Ko, ces codes atteignent une utilisation FLOP de 25,6 % sur un GPU A100. Sur des architectures plus récentes telles que RTX 4090, pour la même taille d'entrée, une simple implémentation de CUDA peut atteindre une utilisation FLOP de 41,4 %
Pour plus de descriptions mathématiques et d'analyses théoriques de Monarch Mixer, veuillez vous référer à l'article original. .
Expérience
L'équipe de recherche a comparé les deux modèles, Monarch Mixer et Transformer, en étudiant principalement la situation dans laquelle Transformer domine trois tâches principales. Les trois tâches sont : la tâche de modélisation du langage de masque non causal de style BERT, la tâche de classification d'images de style ViT et la tâche de modélisation du langage causal de style GPT
Sur chaque tâche, les résultats expérimentaux montrent que la méthode nouvellement proposée peut réaliser un niveau comparable à Transformer sans utiliser l'attention et le MLP. Ils ont également évalué l'accélération de la nouvelle méthode par rapport au puissant modèle de base Transformer dans le cadre BERT. doit être réécrit Pour écrire les tâches, l'équipe a construit une architecture basée sur M2 : M2-BERT. M2-BERT peut remplacer directement les modèles de langage de style BERT, et BERT est une application majeure de l'architecture Transformer. Pour la formation de M2-BERT, une modélisation de langage masqué sur C4 est utilisée et le tokenizer est bert-base-uncased.
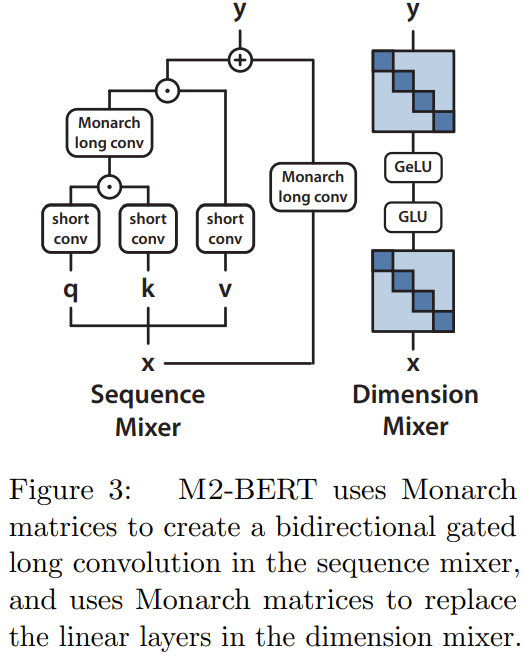
M2-BERT est basé sur le squelette du Transformer, mais la couche M2 remplace la couche d'attention et le MLP, comme le montre la figure 3.
Dans le mélangeur de séquence, l'attention est convoluée avec des portes bidirectionnelles résiduelles convolution à la place (voir côté gauche de la figure 3). Pour restaurer la convolution, l’équipe a défini la matrice Monarch sur une matrice DFT et DFT inverse. Ils ont également ajouté des convolutions en profondeur après l’étape de projection.
Dans le mélangeur dimensionnel, les deux matrices denses du MLP sont remplacées par les matrices diagonales de blocs apprises (l'ordre de la matrice Monarch est 1, b=4)
Le tableau 3 montre les performances du modèle équivalent à BERT-base, et le tableau 4 montre les performances du modèle équivalent à BERT-large.
Comme le montre le tableau, sur le benchmark GLUE, les performances de la base M2-BERT sont comparables à celles de la base BERT, tout en ayant 27 % de paramètres en moins lorsque le nombre de paramètres entre les deux ; est égal, M2 -BERT-base surpasse la base BERT de 1,3 points. De même, M2-BERT-large, qui a 24 % de paramètres en moins, fonctionne aussi bien que BERT-large, tandis qu'avec le même nombre de paramètres, M2-BERT-large a un avantage de 0,7 point.
Le tableau 5 montre le débit aller des modèles comparables au modèle de base BERT. Ce qui est rapporté est le nombre de jetons traités par milliseconde sur le GPU A100-40GB, qui peut refléter le temps d'inférence
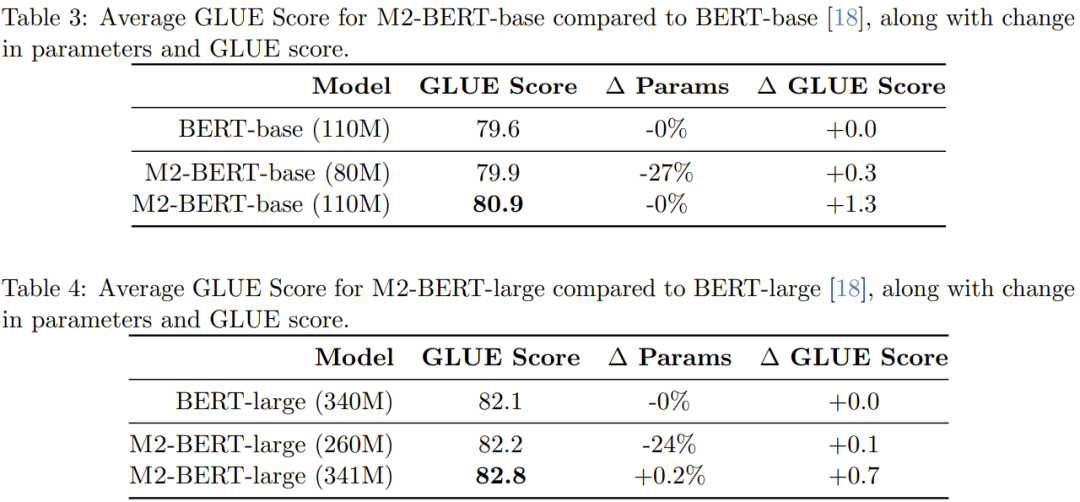
On peut voir que le débit de la base M2-BERT dépasse même le modèle BERT hautement optimisé par rapport à l'implémentation standard de HuggingFace sur une longueur de séquence de 4k, le débit de la base M2-BERT peut atteindre 9,1 fois !
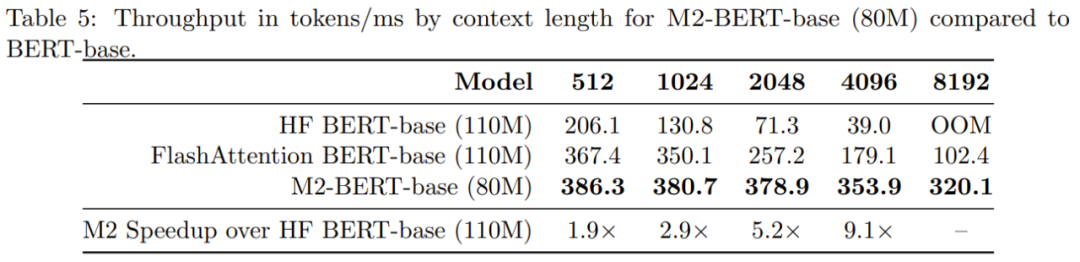
Le tableau 6 donne les temps d'inférence CPU pour M2-BERT-base (80M) et BERT-base - ces résultats sont obtenus en exécutant ces deux modèles directement à l'aide de l'implémentation PyTorch
Lorsque la séquence est courte, l'impact de la localité des données domine toujours la réduction du FLOP, et les opérations telles que la génération de filtres (non disponibles dans BERT) sont plus coûteuses. Lorsque la longueur de la séquence dépasse 1K, l'avantage d'accélération de la base M2-BERT augmente progressivement. Lorsque la longueur de la séquence atteint 8K, l'avantage de vitesse peut atteindre 6,5 fois.
Classification d'images
Pour vérifier si les avantages de la nouvelle méthode dans le domaine de l'image sont les mêmes que dans le domaine du langage, l'équipe a également évalué les performances du M2 sur des tâches de classification d'images, qui reposent sur sur la construction non causale. Le tableau 7 montre les performances de Monarch Mixer, ViT-b, HyenaViT-b et ViT-b-Monarch (remplacement du module MLP dans ViT-b standard par une matrice Monarch) sur les performances ImageNet-1k.
L'avantage de Monarch Mixer est très évident : il ne nécessite que la moitié du nombre de paramètres pour surpasser le modèle ViT-b original. Étonnamment, Monarch Mixer avec moins de paramètres est même capable de surpasser ResNet-152, qui est spécifiquement conçu pour la tâche ImageNet 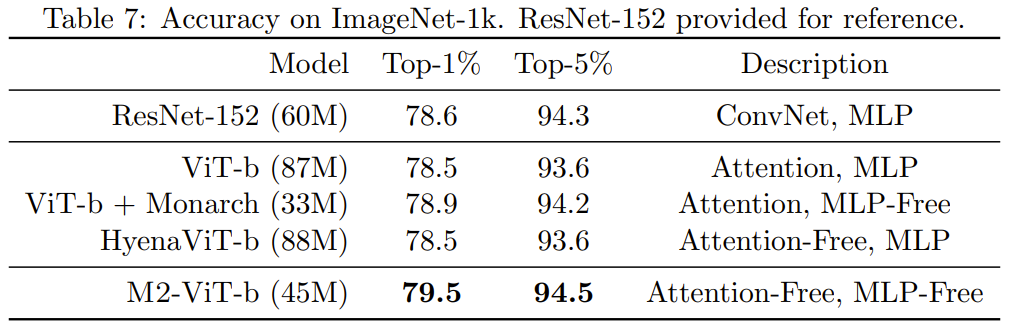
Modélisation du langage causal
Le module de modélisation du langage causal de style GPT est une application importante de Transformer . L'équipe a développé une architecture basée sur M2 pour la modélisation causale du langage, appelée M2-GPT
Pour le mélangeur de séquences, M2-GPT combine les filtres convolutionnels de Hyena, les modèles de langage sans attention de pointe actuels et les paramètres de H3 sont partagés entre les longs. Ils ont remplacé la FFT dans ces architectures par un paramétrage causal et ont entièrement supprimé la couche MLP. L’architecture résultante est complètement dépourvue d’attention et totalement dépourvue de MLP.
Ils ont pré-entraîné M2-GPT sur PILE, un ensemble de données standard pour la modélisation causale du langage. Les résultats sont présentés dans le tableau 8.
On peut voir que bien que le modèle basé sur la nouvelle architecture n'ait aucune attention et MLP du tout, il surpasse toujours Transformer et Hyena dans l'indice de perplexité pré-entraîné. Ces résultats suggèrent que des modèles très différents de Transformer peuvent également atteindre d'excellentes performances en matière de modélisation de langage causal. 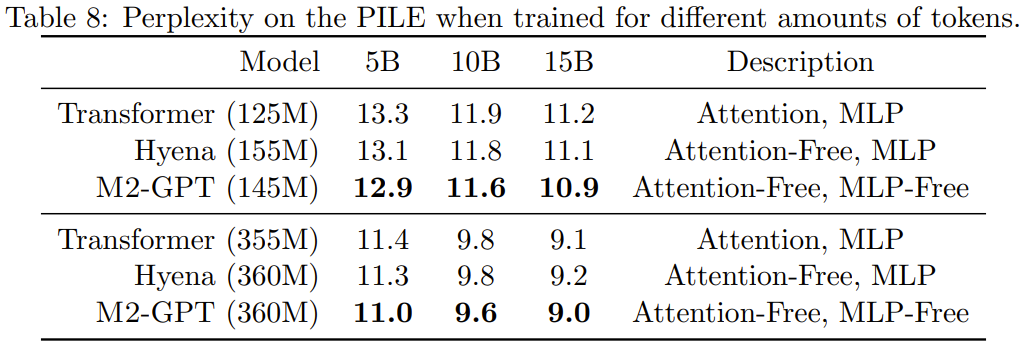
Veuillez vous référer à l'article original pour un contenu plus détaillé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- À quoi fait référence le modèle Python IPO ?
- Entraînez-vous une seule fois pour générer de nouvelles scènes 3D ! L'histoire de l'évolution du « Light Field Neural Rendering » de Google
- Un examen systématique de la pré-formation en apprentissage par renforcement profond, ainsi que des recherches en ligne et hors ligne, suffit.
- CMU s'associe à Adobe : le modèle GAN a inauguré l'ère de la pré-formation, ne nécessitant que 1 % des échantillons de formation
- Premier article : Un nouveau paradigme pour la formation de modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D