
Maison >Périphériques technologiques >IA >Premier article : Un nouveau paradigme pour la formation de modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D
Premier article : Un nouveau paradigme pour la formation de modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D

- 王林avant
- 2023-09-30 08:49:061596parcourir
Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression.
[RenderOcc, le premier nouveau paradigme pour former des modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D] L'auteur extrait des représentations volumétriques 3D de style NeRF à partir d'images multi-vues et utilise la technologie de rendu de volume pour construire des reconstructions 2D afin de réaliser une transformation sémantique à partir de La supervision 3D directe 2D avec étiquettes de profondeur réduit le recours aux annotations d'occupation 3D coûteuses. Des expériences approfondies montrent que RenderOcc fonctionne de manière comparable à des modèles entièrement supervisés utilisant des étiquettes 3D, soulignant l'importance de cette approche dans les applications du monde réel. Déjà open source.
Titre : RenderOcc : Prédiction d'occupation 3D centrée sur la vision avec supervision 2DRendering
Affiliation de l'auteur : Peking University, Xiaomi Automobile, Hong Kong Chinese MMLAB
Le contenu qui doit être réécrit est : Adresse open source : GitHub - pmj110119/RenderOcc
3D Occupation Prediction, qui quantifie les scènes 3D dans des cellules de grille sémantiquement étiquetées, est très prometteuse dans les domaines de la perception des robots et de la conduite autonome. Les travaux récents utilisent principalement des étiquettes d'occupation complètes dans l'espace voxel 3D pour la supervision. Cependant, des processus d’annotation coûteux et des étiquettes parfois ambiguës limitent considérablement la convivialité et l’évolutivité des modèles d’occupation 3D. Pour résoudre ce problème, les auteurs proposent RenderOcc, un nouveau paradigme pour former des modèles d'occupation 3D en utilisant uniquement des étiquettes 2D. Plus précisément, nous extrayons des représentations volumétriques 3D de style NeRF à partir d'images multi-vues et utilisons des techniques de rendu de volume pour créer des reconstructions 2D, permettant une supervision 3D directe à partir d'étiquettes sémantiques et de profondeur 2D. De plus, les auteurs présentent une méthode de rayons auxiliaires pour résoudre le problème du point de vue clairsemé dans les scènes de conduite autonome, qui utilise des images séquentielles pour créer un rendu 2D complet pour chaque cible. RenderOcc est la première tentative de formation d'un modèle d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D, réduisant ainsi le recours à des annotations d'occupation 3D coûteuses. Des expériences approfondies montrent que RenderOcc fonctionne de manière comparable à des modèles entièrement supervisés utilisant des étiquettes 3D, soulignant l'importance de cette approche dans les applications du monde réel.
Structure du réseau :
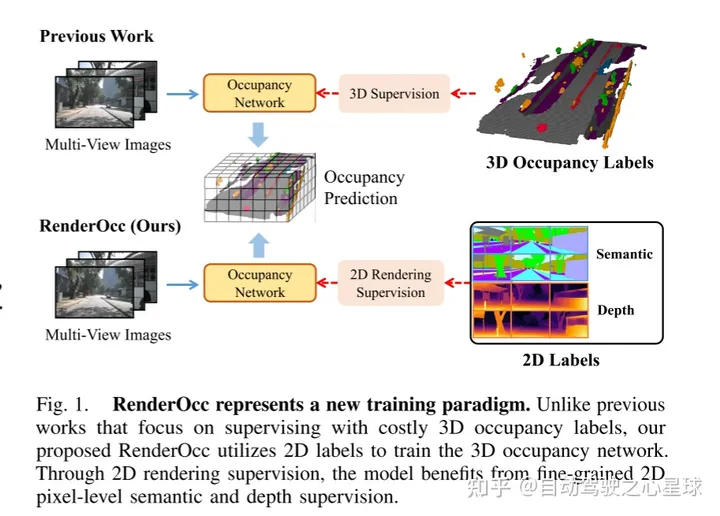
La figure 1 montre une nouvelle méthode de formation de RenderOcc. Contrairement aux méthodes précédentes qui s'appuient sur des étiquettes d'occupation 3D coûteuses pour la supervision, le RenderOcc proposé dans cet article utilise des étiquettes 2D pour former le réseau d'occupation 3D. Avec la supervision du rendu 2D, le modèle est capable de bénéficier d'une sémantique fine au niveau des pixels 2D et d'une supervision en profondeur
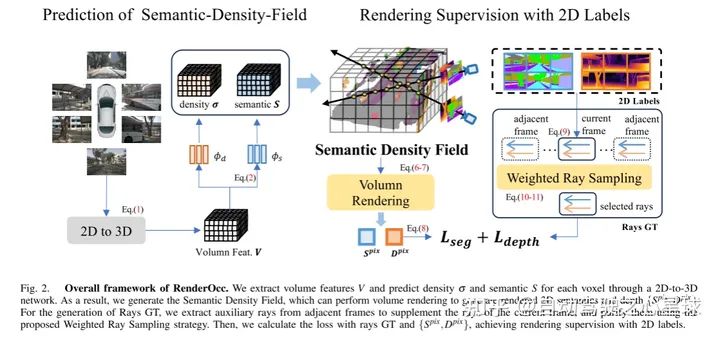
Figure 2. Le cadre global de RenderOcc. Cet article extrait des caractéristiques volumétriques via un réseau 2D à 3D et prédit la densité et la sémantique de chaque voxel. Par conséquent, cet article génère un champ de densité sémantique, qui peut effectuer un rendu de volume pour générer une sémantique et une profondeur 2D rendues. Pour la génération de Rays GT, cet article extrait les rayons auxiliaires des trames adjacentes pour compléter les rayons de la trame actuelle et utilise la stratégie d'échantillonnage de rayons pondéré proposée pour les purifier. Ensuite, cet article utilise light GT et {} pour calculer la perte afin d'obtenir une supervision du rendu des étiquettes 2D
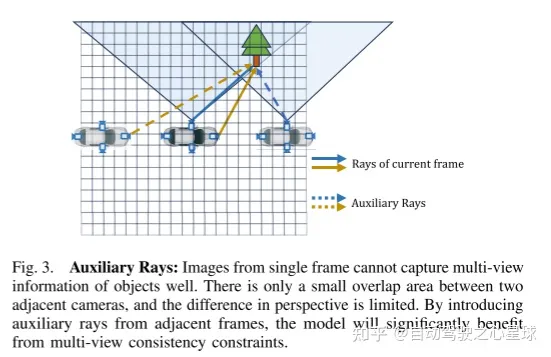
Contenu réécrit : Figure 3. Lumière auxiliaire : une image à image unique ne peut pas bien capturer les informations multi-vues de l'objet. Il n'y a qu'une petite zone de chevauchement entre les caméras adjacentes et la différence d'angle de vision est limitée. En introduisant des rayons auxiliaires provenant de cadres adjacents, le modèle peut bénéficier de manière significative des contraintes de cohérence multi-vues.

Le contenu qui doit être réécrit est : Lien original : https://mp.weixin.qq.com/s/WzI8mGoIOTOdL8irXrbSPQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!