
Maison >Périphériques technologiques >IA >CMU s'associe à Adobe : le modèle GAN a inauguré l'ère de la pré-formation, ne nécessitant que 1 % des échantillons de formation
CMU s'associe à Adobe : le modèle GAN a inauguré l'ère de la pré-formation, ne nécessitant que 1 % des échantillons de formation

- WBOYavant
- 2023-05-11 09:28:051483parcourir
Après être entrés dans l'ère de la pré-formation, les performances des modèles de reconnaissance visuelle se sont développées rapidement, mais les modèles de génération d'images, tels que les réseaux contradictoires génératifs (GAN), semblent avoir pris du retard.
Habituellement, la formation GAN est effectuée à partir de zéro, de manière non supervisée, ce qui prend du temps et demande beaucoup de travail. Les « connaissances » acquises grâce au big data lors d'une pré-formation à grande échelle ne sont pas utilisées. ?
Et la génération d'images elle-même doit être capable de capturer et de simuler les données statistiques complexes dans des phénomènes visuels du monde réel, sinon les images générées ne seront pas conformes aux lois du monde physique et seront directement identifiées comme « fausses ». en un coup d'œil.

Le modèle pré-entraîné fournit des connaissances et le modèle GAN fournit des capacités de génération La combinaison des deux est une belle chose !
La question est de savoir quels modèles pré-entraînés et comment les combiner peuvent améliorer la capacité de génération du modèle GAN ?
Récemment, des chercheurs de la CMU et d'Adobe ont publié un article dans CVPR 2022, combinant la formation de modèles pré-entraînés et de modèles GAN par « sélection ».

Lien papier : https://arxiv.org/abs/2112.09130
Lien du projet : https://github.com/nupurkmr9/vision-aided-gan
Lien vidéo : https://www. youtube.com/watch?v=oHdyJNdQ9E4
Le processus de formation du modèle GAN se compose d'un discriminateur et d'un générateur. Le discriminateur est utilisé pour apprendre les données statistiques pertinentes qui distinguent les échantillons réels et les échantillons générés, tandis que l'objectif du générateur. est de laisser L'image générée est la plus identique possible à la distribution réelle.
Idéalement, le discriminateur devrait être capable de mesurer l'écart de répartition entre l'image générée et l'image réelle.
Mais lorsque la quantité de données est très limitée, l'utilisation directe d'un modèle pré-entraîné à grande échelle comme discriminateur peut facilement conduire à un « écrasement cruel » du générateur puis à un « surajustement ».
Grâce à des expériences sur l'ensemble de données FFHQ 1k, même si la dernière méthode d'amélioration des données différenciables est utilisée, le discriminateur sera toujours surajusté. Les performances de l'ensemble d'entraînement sont très bonnes, mais les performances de l'ensemble de validation sont très mauvaises.
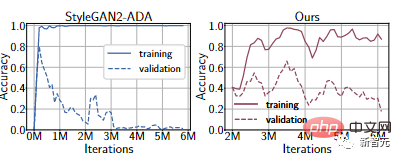
De plus, le discriminateur peut se concentrer sur des déguisements impossibles à distinguer pour les humains mais évidents pour les machines.
Afin d'équilibrer les capacités du discriminateur et du générateur, les chercheurs ont proposé d'assembler les représentations d'un ensemble de différents modèles pré-entraînés en tant que discriminateur.
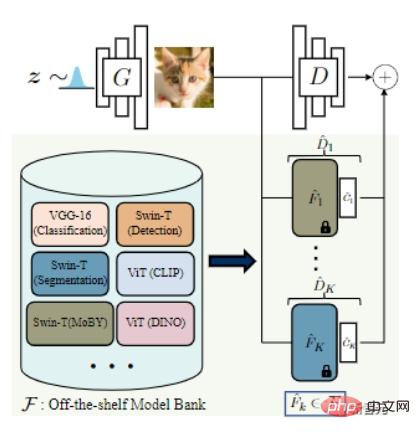
Cette méthode présente deux avantages :
1. La formation d'un classificateur superficiel sur des fonctionnalités pré-entraînées est une méthode courante pour adapter les réseaux profonds à des ensembles de données à petite échelle, tout en réduisant le surajustement.
C'est-à-dire que tant que les paramètres du modèle pré-entraîné sont fixes et qu'un réseau de classification léger est ajouté à la couche supérieure, un processus de formation stable peut être fourni.
Par exemple, à partir de la courbe Ours dans l'expérience ci-dessus, vous pouvez voir que la précision de l'ensemble de validation est bien améliorée par rapport à StyleGAN2-ADA.
2. Certaines études récentes ont également prouvé que les réseaux profonds peuvent capturer des concepts visuels significatifs, depuis les repères visuels de bas niveau (bords et textures) jusqu'aux concepts de haut niveau (objets et parties d'objets).
Un discriminateur construit sur ces caractéristiques pourrait être plus conforme à la perception humaine.
Et la combinaison de plusieurs modèles pré-entraînés peut permettre au générateur de correspondre à la distribution réelle dans différents espaces de fonctionnalités complémentaires.
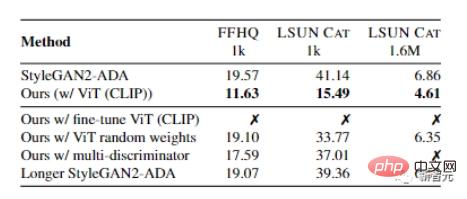
Afin de sélectionner le meilleur réseau pré-entraîné, les chercheurs ont d'abord collecté plusieurs modèles sota pour former une « banque de modèles », dont VGG-16 pour la classification, Swin-T pour la détection et la segmentation, etc.
Ensuite, sur la base de la segmentation linéaire des images réelles et fausses dans l'espace des fonctionnalités, une stratégie de recherche automatique de modèle est proposée, et des techniques de lissage des étiquettes et d'amélioration différentiable sont utilisées pour stabiliser davantage l'entraînement du modèle et réduire le surajustement.
Plus précisément, l'union d'échantillons de formation réels et d'images générées est divisée en un ensemble de formation et un ensemble de validation.
Pour chaque modèle pré-entraîné, entraînez un discriminateur linéaire logique pour classer si l'échantillon provient d'un échantillon réel ou généré, et utilisez la « perte d'entropie croisée binaire négative » sur la division de vérification pour mesurer l'écart de distribution et renvoyer le plus petit. modèle d'erreur.
Une erreur de validation plus faible est associée à une précision de détection linéaire plus élevée, indiquant que ces fonctionnalités sont utiles pour distinguer les échantillons réels des échantillons générés, et que l'utilisation de ces fonctionnalités peut fournir un retour d'information plus utile au générateur.
Chercheurs Nous avons vérifié empiriquement la formation GAN à l'aide de 1000 échantillons de formation provenant des ensembles de données FFHQ et LSUN CAT.
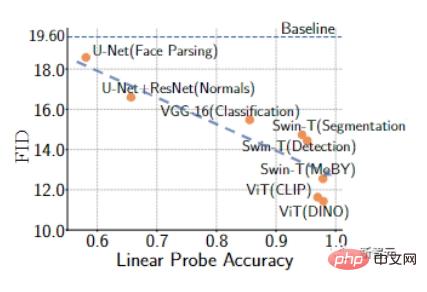
 Les résultats montrent que les GAN formés avec des modèles pré-entraînés ont une précision de détection linéaire plus élevée et, de manière générale, peuvent obtenir un meilleur indicateur FID .
Les résultats montrent que les GAN formés avec des modèles pré-entraînés ont une précision de détection linéaire plus élevée et, de manière générale, peuvent obtenir un meilleur indicateur FID .
Afin d'incorporer les commentaires de plusieurs modèles prêts à l'emploi, l'article explore également deux stratégies de sélection et d'intégration de modèles
1) Stratégie de sélection de modèle K-fixe, sélectionnée au début de la formation des K meilleurs modèles disponibles dans le commerce et entraînement jusqu'à convergence ;
2) Stratégie de sélection de modèle K-progressive, sélectionner et ajouter de manière itérative le modèle le plus performant et inutilisé après un nombre fixe d'itérations.
Les résultats expérimentaux montrent que par rapport à la stratégie K-fixe, l'approche progressive a une complexité de calcul inférieure et est également utile pour sélectionner des modèles pré-entraînés pour capturer les différences dans la distribution des données. Par exemple, les deux premiers modèles sélectionnés par la stratégie progressive sont généralement une paire de modèles auto-supervisés et supervisés.
Les expérimentations présentées dans l'article sont principalement progressives.
L'algorithme d'entraînement final entraîne d'abord un GAN avec une perte adverse standard.

 Étant donné un générateur de base, vous pouvez utiliser le sondage linéaire pour rechercher le meilleur modèle pré-entraîné et introduire une perte pendant l'objectif d'entraînement fonction.
Étant donné un générateur de base, vous pouvez utiliser le sondage linéaire pour rechercher le meilleur modèle pré-entraîné et introduire une perte pendant l'objectif d'entraînement fonction.
Dans la stratégie K-progressive, après un entraînement pour un nombre fixe d'itérations proportionnel au nombre d'échantillons d'entraînement réels disponibles, un nouveau discriminateur visuellement auxiliaire est ajouté à l'étape précédente avec le meilleur instantané de l’ensemble d’entraînement FID.
Pendant le processus de formation, l'augmentation des données est effectuée par retournement horizontal, et des techniques d'augmentation différentiable et de lissage d'étiquettes unilatérales sont utilisées comme termes de régularisation.
On peut également observer que l'utilisation uniquement de modèles disponibles dans le commerce comme discriminateurs conduit à une divergence, tandis que la combinaison de discriminateurs originaux et de modèles pré-entraînés peut améliorer cette situation.
L'expérience finale montre les résultats lorsque les échantillons d'entraînement des ensembles de données FFHQ, LSUN CAT et LSUN CHURCH varient de 1 000 à 10 000.
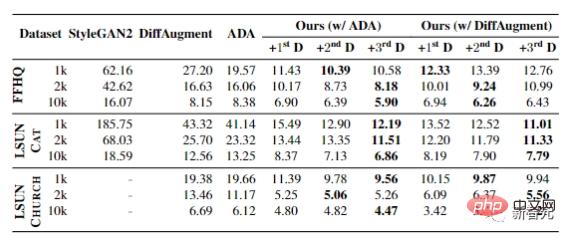
 Dans tous les contextes, le FID peut réaliser des améliorations significatives, prouvant l'efficacité de cette méthode dans des scénarios de données limitées.
Dans tous les contextes, le FID peut réaliser des améliorations significatives, prouvant l'efficacité de cette méthode dans des scénarios de données limitées.
Afin d'analyser qualitativement la différence entre cette méthode et StyleGAN2-ADA, en fonction de la qualité des échantillons générés par les deux méthodes, la nouvelle méthode proposée dans l'article peut améliorer la qualité des pires échantillons , notamment pour FFHQ et LSUN CAT

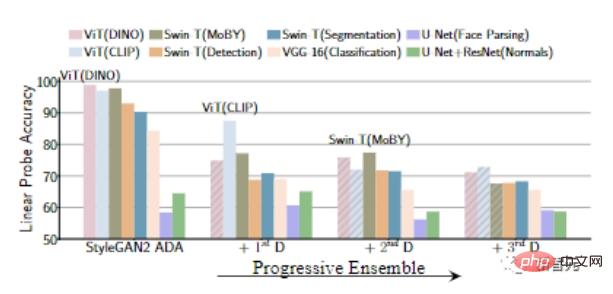
 Quand on augmente progressivement le discriminateur suivant, on peut voir la précision de la détection linéaire sur les caractéristiques du modèle pré-entraîné Le sexe diminue progressivement, ce qui signifie que le générateur devient plus fort.
Quand on augmente progressivement le discriminateur suivant, on peut voir la précision de la détection linéaire sur les caractéristiques du modèle pré-entraîné Le sexe diminue progressivement, ce qui signifie que le générateur devient plus fort.
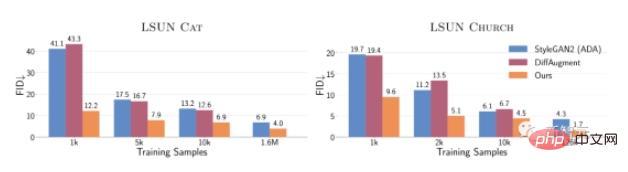
 En général, avec seulement 10 000 échantillons d'entraînement, le FID de cette méthode sur LSUN CAT est le même que celui sur LSUN CAT. les performances de StyleGAN2 formé sur 1,6 million d’images sont similaires.
En général, avec seulement 10 000 échantillons d'entraînement, le FID de cette méthode sur LSUN CAT est le même que celui sur LSUN CAT. les performances de StyleGAN2 formé sur 1,6 million d’images sont similaires.
 Sur l'ensemble des données complètes, cette méthode améliore de 1,5 à 2 sur les catégories LSUN chat, église et cheval fois le FID. .
Sur l'ensemble des données complètes, cette méthode améliore de 1,5 à 2 sur les catégories LSUN chat, église et cheval fois le FID. .

L'auteur Richard Zhang a obtenu son doctorat de l'Université de Californie à Berkeley, ainsi que ses diplômes de premier cycle et de maîtrise de l'Université Cornell. Les principaux intérêts de recherche comprennent la vision par ordinateur, l'apprentissage automatique, l'apprentissage profond, le graphisme et le traitement d'images, travaillant souvent avec des chercheurs universitaires dans le cadre de stages ou d'universités.

 L'auteur Jun-Yan Zhu est professeur adjoint à l'école de robotique de l'école d'informatique de l'université Carnegie Mellon. Il travaille également au département d'informatique et au département d'apprentissage automatique. les domaines comprennent la vision par ordinateur, l'infographie, l'apprentissage automatique et la photographie informatique.
L'auteur Jun-Yan Zhu est professeur adjoint à l'école de robotique de l'école d'informatique de l'université Carnegie Mellon. Il travaille également au département d'informatique et au département d'apprentissage automatique. les domaines comprennent la vision par ordinateur, l'infographie, l'apprentissage automatique et la photographie informatique.
Avant de rejoindre la CMU, il était chercheur scientifique chez Adobe Research. Il est diplômé de l'Université Tsinghua avec un baccalauréat et un doctorat de l'Université de Californie à Berkeley, puis a travaillé comme chercheur postdoctoral au MIT CSAIL. ..
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI