
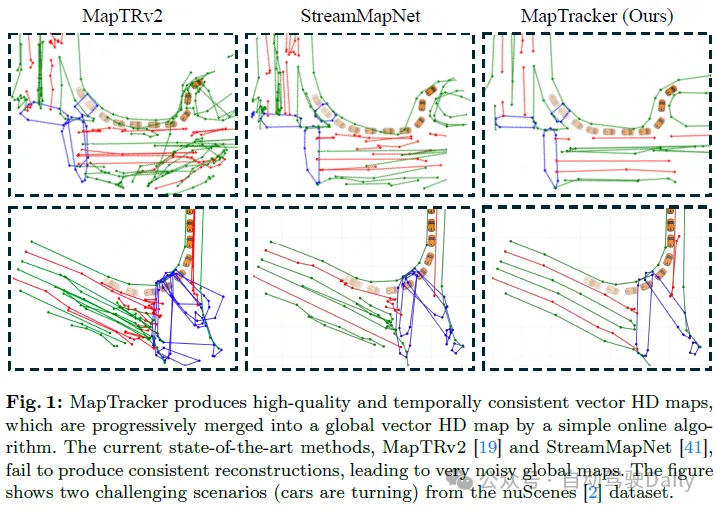
Home >Technology peripherals >AI >Can online maps still be like this? MapTracker: Use tracking to realize the new SOTA of online maps!
Can online maps still be like this? MapTracker: Use tracking to realize the new SOTA of online maps!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2024-04-25 17:01:171448browse
Written before&The author’s personal understanding
This algorithm allows online high-precision map construction. Our method, MapTracker, accumulates sensor streams into memory buffers of two displays: 1) Raster latents in Bird’s Eye View (BEV) space and 2) Vector latents on road elements (i.e., crosswalks, lane lines, and road boundaries). The method draws on the query propagation paradigm in target tracking, which explicitly associates the tracked road elements of the previous frame with the current frame, while fusing a subset of memory latents with distance strides to
Open source link: https://map-tracker.github.io/
In summary, the main contributions of this article are as follows:
- A new vector HD mapping algorithm that formulates HD mapping as a tracking task and exploits the history of memory latents in both representations to achieve temporal consistency;
- An improved vector HD mapping benchmark , with time-consistent GT and consistency-aware mAP metric;
- SOTA performance! Significant improvements over the current best methods on traditional and new metrics.
Review of related work
This paper considers and solves the problem of consistent vector HD mapping in two ways. We first review the latest trends in visual object tracking using Transformer and memory designs in vision-based autonomous driving. Finally, we discuss competing vector HD mapping methods.
Using transformers for visual target tracking. Visual object tracking has a long history, among which end-to-end transformer methods have become a recent trend due to their simplicity. TrackFormer, TransTrack, and MOTR leverage attention mechanisms and tracking queries to explicitly correlate instances across frames. MeMOT and MeMOTR further extend the tracking transformer with a memory mechanism for better long-term consistency. This paper formulates vector HD mapping as a tracking task by combining tracking queries with a more robust memory mechanism.
Memory design in autonomous driving. Single-frame autonomous driving systems have difficulty handling occlusions, sensor failures, or complex environments. Temporal modeling with Memory provides a promising addition. Many memory designs exist for grating BEV functions that form the basis of most autonomous driving tasks. BEVDet4D and BEVFormerv2 superimpose the features of multiple past frames into Memory, but the calculation expands linearly with the history length, making it difficult to capture long-term information. VideoBEV propagates BEV raster queries across frames to accumulate information in a loop. In the vector domain, Sparse4Dv2 uses similar RNN-style memory for target queries, while Sparse4Dv3 further uses temporal denoising for robust temporal learning. These ideas have been partially incorporated into vector HD mapping methods. This paper proposes a new memory design for the grating BEV latency and vector latency of road elements.
Vector HD mapping. Traditionally, high-precision maps are reconstructed offline using SLAM-based methods and then manually managed, which requires high maintenance costs. With the improvement of accuracy and efficiency, online vector high-precision map algorithms have attracted more attention than offline map algorithms, which will simplify the production process and handle map changes. HDMapNet converts raster image segmentation into vector image instances through post-processing and established the first vector HD mapping benchmark. Both VectorMapNet and MapTR utilize DETR-based transformers for end-to-end prediction. The former autoregressively predicts the vertices of each detected curve, while the latter uses hierarchical query and matching loss to predict all vertices simultaneously. MapTRv2 further complements MapTR with auxiliary tasks and network modifications. Curve representation, network design, and training paradigms are the focus of other work. StreamMapNet takes a step towards consistent mapping by drawing on the flow idea in BEV perception. The idea is to accumulate past information into memory latents and pass them as conditions (i.e. condition detection framework). SQD MapNet imitates DN-DETR and proposes temporal curve denoising to promote temporal learning.
MapTracker
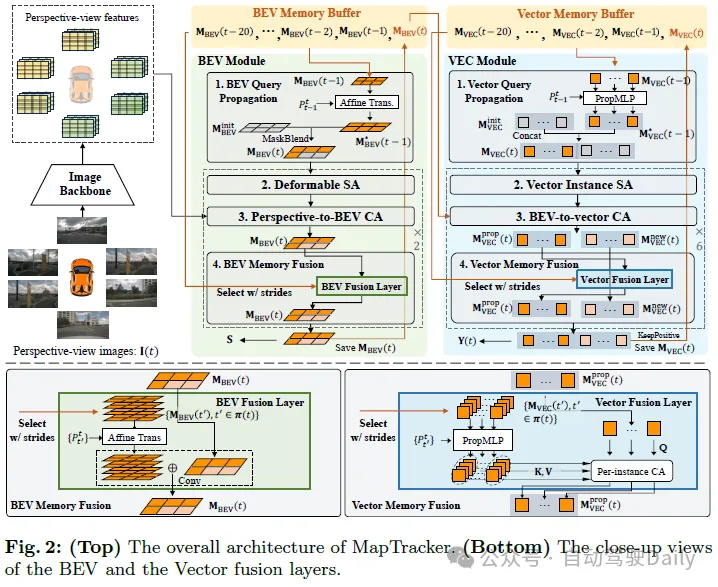
The robust memory mechanism is the core of MapTracker, which accumulates sensor streams into latent memories represented in two ways: 1) Bird's-eye view (BEV) memory of the area around the vehicle in a top-down BEV coordinate system as the latent image; and 2) Vector (VEC) memory of road elements (i.e., pedestrian intersections, lane lines, and road boundaries) as a set of potential quantities.
Two simple ideas and the memory mechanism achieve consistent mapping. The first idea is to use a historical memory buffer instead of a single memory for the current frame. A single memory should hold information for the entire history, but it is easy to lose memory, especially in cluttered environments with a large number of vehicles blocking road structures. Specifically, for efficiency and coverage, we select a subset of past latent memories for fusion at each frame based on vehicle motion. The second idea is to formulate online HD maps as tracking tasks. The VEC memory mechanism maintains the sequence of memory latents for each road element and makes this formulation simple by borrowing the query propagation paradigm from the tracking literature. The remainder of this section explains our neural architecture (see Figures 2 and 3), including BEV and VEC memory buffers and their corresponding network modules, and then introduces the training details.
Memory Buffers
BEV memory is a 2D latent in the BEV coordinate system, centered on the vehicle and oriented at the tth frame. The spatial dimension (i.e. 50×100) covers a rectangular area, 15m left/right and 30m front/back. Each memory latency accumulates the entire past information, and the buffer maintains such memory latents in the last 20 frames, making the memory mechanism redundant but robust.
VECmemory is a set of vector latency times. Each vector latency time accumulates information about active road elements until frame t. The number of active elements changes from frame to frame. The buffer holds the latent vectors of the past 20 frames and their correspondence between frames (i.e., the latent sequence of vectors corresponding to the same road element).
BEV Module

The input is 1) CNN features of the airborne surround image processed by the image backbone and its camera parameters; 2) BEV memory buffer and 3) vehicle motion. The following explains the four components of the BEV module architecture and their outputs.
- BEV Query Propagation: BEV memory is the 2D latent image in the vehicle coordinate system. Affine transformation and bilinear interpolation initialize the current BEV memory to the previous BEV memory. For pixels located outside the latent image after transformation, the learnable embedding vector of each pixel is initialized, and its operation is represented as "MaskBlend" in Figure 3.
- Deformable Self-Attention: The deformable self-attention layer enriches BEV memory.
- Perspective-to-BEV Cross-Attention: Similar to StreamMapNet, BEVFormer’s spatially deformable cross-attention layer injects perspective information into MBEV(t).
- BEV Memory Fusion: The memory latents in the buffer are fused to enrich MBEV(t). Using all memories is computationally expensive and redundant.
The output is 1) the final memory MBEV(t) saved to the buffer and passed to the VEC module; and 2) the rasterized road element geometry S(t) inferred by the segmentation head and used for loss calculations ). The segmentation head is a linear projection module that projects each pixel in the memory latent to a 2×2 segmentation mask, resulting in a 100×200 mask.
VEC Module
The input is BEV memory MBEV(t) and vector memory buffer and vehicle motion;
- Vector Query Propagation: vector memory is a set of potential vectors of active road elements.
- Vector Instance Self Attention: Standard self-attention layer;
- BEV-to-Vector Cross Attention: Multi-Point Attention;
- Vector Memory Fusion: For the current memory For each latent vector in MVEC(t), the latent vectors in the buffer associated with the same road element are fused to enrich its representation. The same stride frame selection selects four potential vectors, where for some road elements with short tracking history, the selected frames π(t) will be different and less. For example, an element tracked for two frames has only two latents in the buffer.
The output is 1) the final memory of "positive" road elements that passed the classification test of a single fully connected layer from MVEC(t); and 2) the final memory of the "positive" road elements passed by the classification test from MVEC(t); 3-layer MLP regression of positive road elements on vector road geometry.
Training
BEV loss:
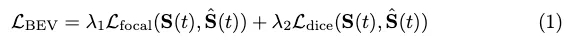
VEC loss. Inspired by MOTR, an end-to-end transformer for multi-object tracking, we extend the matching-based loss to explicitly consider GT tracking. The optimal instance-level label assignment for a new element is defined as:
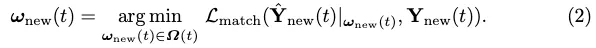
Then the label assignment ω(t) between all outputs and GT is defined inductively:
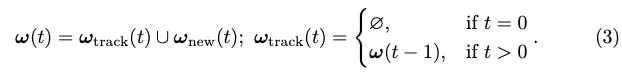
The tracking style loss of vector output is:
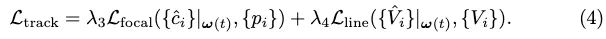
Conversion loss. We borrow the transformation loss Ltrans from StreamMapNet to train PropMLP, which forces query transformations in the latent space to preserve vector geometry and class types. The final training loss is:
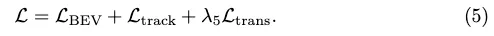
Consistent Vector HD Mapping Benchmarks
Consistent ground truth
MapTR created a vector HD mapping benchmark from the nuScenes and Agroverse2 datasets, which was adopted by many subsequent studies. However, crosswalks are naively merged together and inconsistent across frames. The dividing line is also inconsistent with the failure of its graph tracking process (for Argoverse2).
StreamMapNet inherits the code of VectorMapNet and creates a benchmark with better realism that has been used in the workshop challenge. However, some problems remain. For Argoverse2, dividers are sometimes split into shorter segments. For nuScenes, large crosswalks sometimes segment out small loops, whose inconsistencies appear randomly in each frame, resulting in temporarily inconsistent representations. We provide visualizations of existing benchmark problems in the appendix.
We improved the processing code of the existing baseline to (1) enhance the GT geometry of each frame and then (2) calculate their correspondence between frames to form a GT "trajectory".
(1) Enhance each frame geometry. We inherited and improved the MapTR codebase popular in the community while making two changes: replacing walking area processing with processing in StreamMapNet and improving quality with more geometric constraints; and enhancing the graph tracking algorithm to handle Noise from the original annotations to enhance temporal consistency in divider processing (Argoverse2 only).
(2) Forming tracks. Given the geometric structure of road elements in each frame, we solve the optimal bipartite matching problem between each pair of adjacent frames to establish the correspondence between road elements. Pairs of correspondences are linked to form trajectories of road elements. The matching score between a pair of road elements is defined as follows. Road element geometry is a polygonal curve or loop. We convert the element geometry from the old frame to the new frame based on vehicle motion and then rasterize two curves/loops with a certain thickness into instance masks. Their intersection on the union is the matching score.
Consistency-aware mAP metric
The mAP metric does not penalize temporarily inconsistent reconstructions. We match reconstructed road elements and ground truth in each frame independently with chamfer distances, as in the standard mAP procedure, and then eliminate temporarily inconsistent matches through the following checks. First, for the baseline method that does not predict tracking information, we use the same algorithm used to obtain GT temporal correspondence to form trajectories of reconstructed road elements (we also extend the algorithm to re-identify missing elements by trading off speed; see for details appendix). Next, let the "ancestors" be the road elements that belong to the same trajectory in the previous frame. From the beginning of the sequence, we remove every frame match (reconstructed element and ground truth element) as temporarily inconsistent if any of their ancestors do not match. The remaining temporally consistent matches are then used to calculate standard mAP.
Experiments
We built our system based on the StreamMapNet codebase while using 8 NVIDIA RTX A5000 GPUs for 72 epochs on nuScenes and 35 on Argoverse2 epoch to train our model. The batch sizes for the three training stages are 16, 48 and 16 respectively. Training takes about three days, and inference speed is about 10 FPS. After explaining the dataset, metrics, and baseline methods, this section provides experimental results.
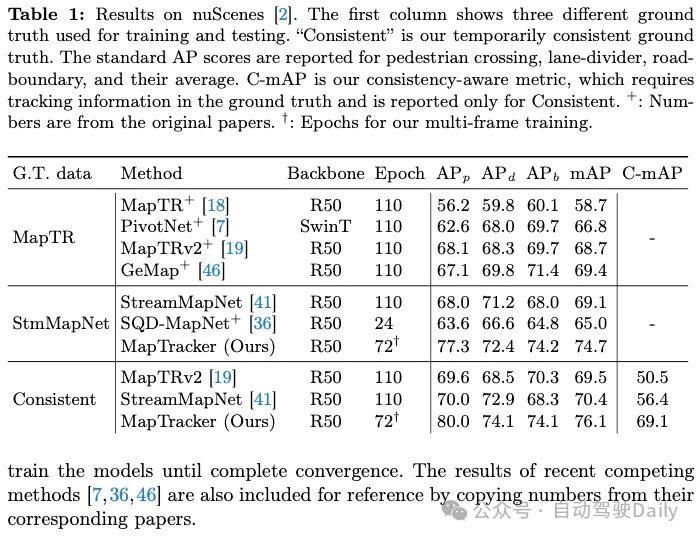
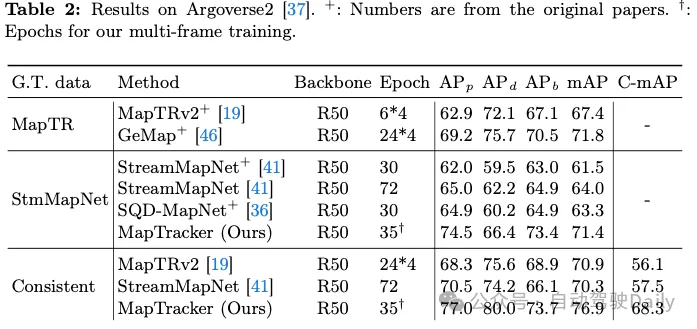
One of our contributions is to achieve temporal consistency on two existing counterparts, namely MapTR and StreamMapNet Ground Truth (GT). Tables 1 and 2 show the results of training and testing the system on one of the three GTs (shown in the first column). Since our codebase is based on StreamMapNet, we evaluate our system on StreamMapNet GT and our ad hoc consistent GT.
nuScenes results. Table 1 shows that both MapTRv2 and StreamMapNet achieve better mAP using our GT, which is what we would expect when fixing the inconsistency in their original GT. StreamMapNet's improvement is slightly higher because it has temporal modeling (while MapTR does not) and exploits temporal consistency in the data. MapTracker significantly outperforms competing methods, especially as our consistent GT improves by more than 8% and 22% in raw and consistency-aware mAP scores, respectively. Note that MapTracker is the only system that produces explicit tracking information (i.e., reconstructing the correspondence of elements between frames), which is required for consistency region mAP. A simple matching algorithm creates trajectories for the baseline method.
Argoverse2 results. Table 2 shows that both MapTRv2 and StreamMapNet achieve better mAP scores with our consistent GT, which in addition to being temporally consistent, also has higher quality GT (for crosswalks and dividers), benefiting all methods. MapTracker outperforms all other baselines in all settings by a significant margin (i.e., 11% or 8%, respectively). The Consistency Awareness Score (C-mAP) further demonstrates our superior consistency, improving over 18% over StreamMapNet.
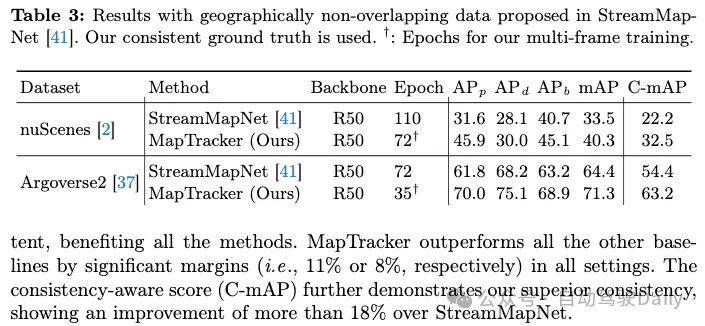
Results with geographically non-overlapping data
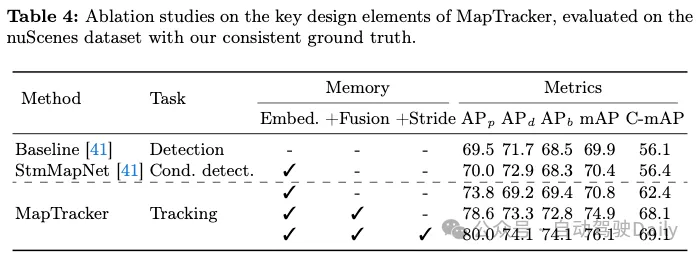
Ablation studies
Qualitative evaluations

Conclusion
This paper introduces MapTracker, which formulates online HD mapping as a tracking task and leverages the history of raster and vector latents to maintain temporal consistency. We use a query propagation mechanism to associate tracked road elements across frames, and fuse a selected subset of memory entries with distance strides to enhance consistency. We also improve existing baselines by generating consistent GTs using tracking labels and enhancing the raw mAP metric with timing consistency checks. MapTracker significantly outperforms existing methods on nuScenes and Agroverse2 datasets when evaluated using traditional metrics, and it demonstrates superior temporal consistency when evaluated using our consistency-aware metrics.Limitations: We identified two limitations of MapTracker. First, the current tracking formulation does not handle the merging and splitting of road elements (e.g., a U-shaped boundary is split into two straight lines in future frames, and vice versa). Nor do basic facts represent them appropriately. Secondly, our system is still at 10 FPS and real-time performance is a bit lacking, especially during critical crash events. Optimizing efficiency and handling more complex real-world road structures are our future work.
The above is the detailed content of Can online maps still be like this? MapTracker: Use tracking to realize the new SOTA of online maps!. For more information, please follow other related articles on the PHP Chinese website!