Snowflake joins the LLM melee.
Snowflake releases high "enterprise intelligence" model Arctic, focusing on internal enterprise applications. Just now, data management and warehouse provider Snowflake announced that it has joined the LLM melee and released a top-level large language model (LLM) focused on enterprise-level applications - Snowflake Arctic . As an LLM launched by a cloud computing company, Arctic mainly has the following two advantages:
- Efficient intelligence: Arctic excels at enterprise tasks such as SQL generation, programming, and instruction following, even competing with open source models trained with higher computational costs. Arctic sets a new baseline for cost-effective training, enabling Snowflake customers to create high-quality custom models at low cost for their enterprise needs.
- Open source: Arctic adopts the Apache 2.0 license, providing open access to weights and code, and Snowflake will also open source all data solutions and research findings.
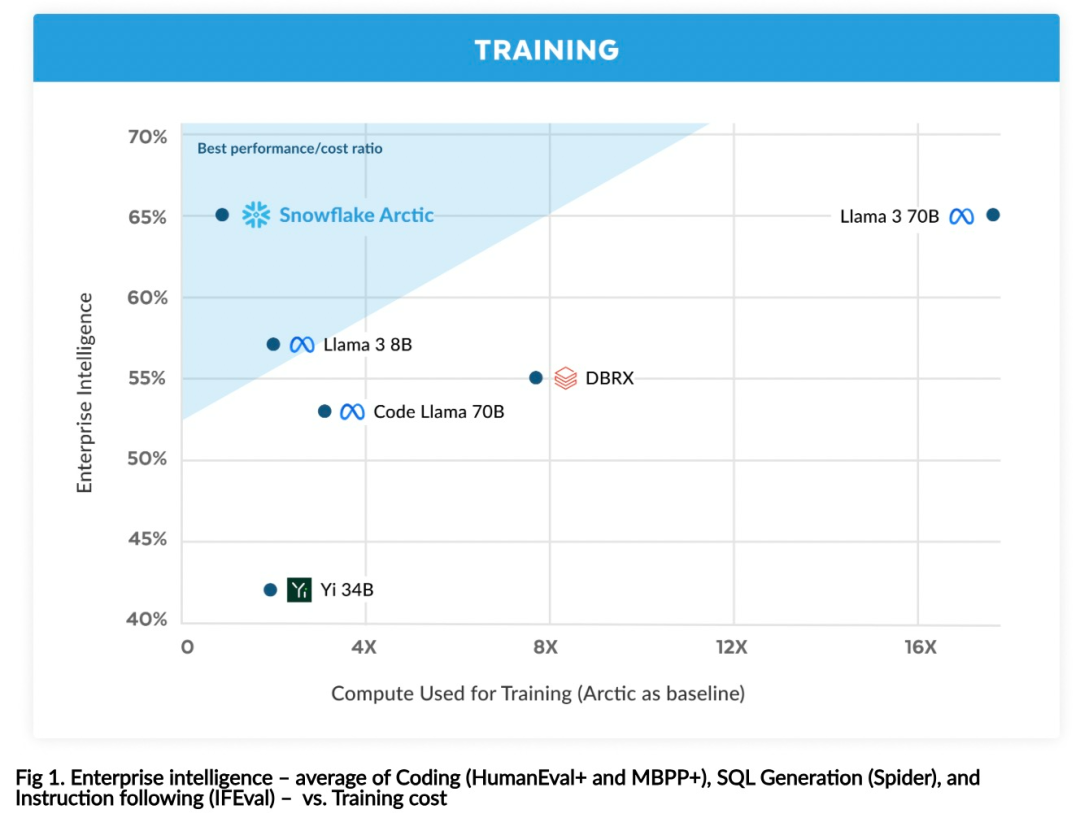
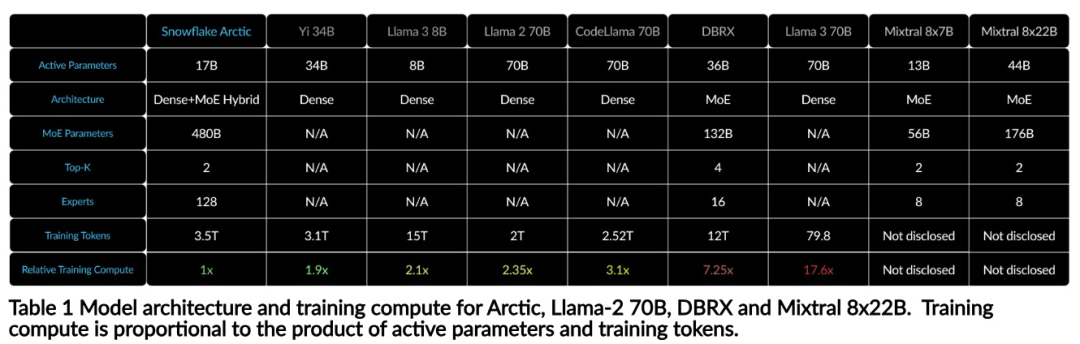
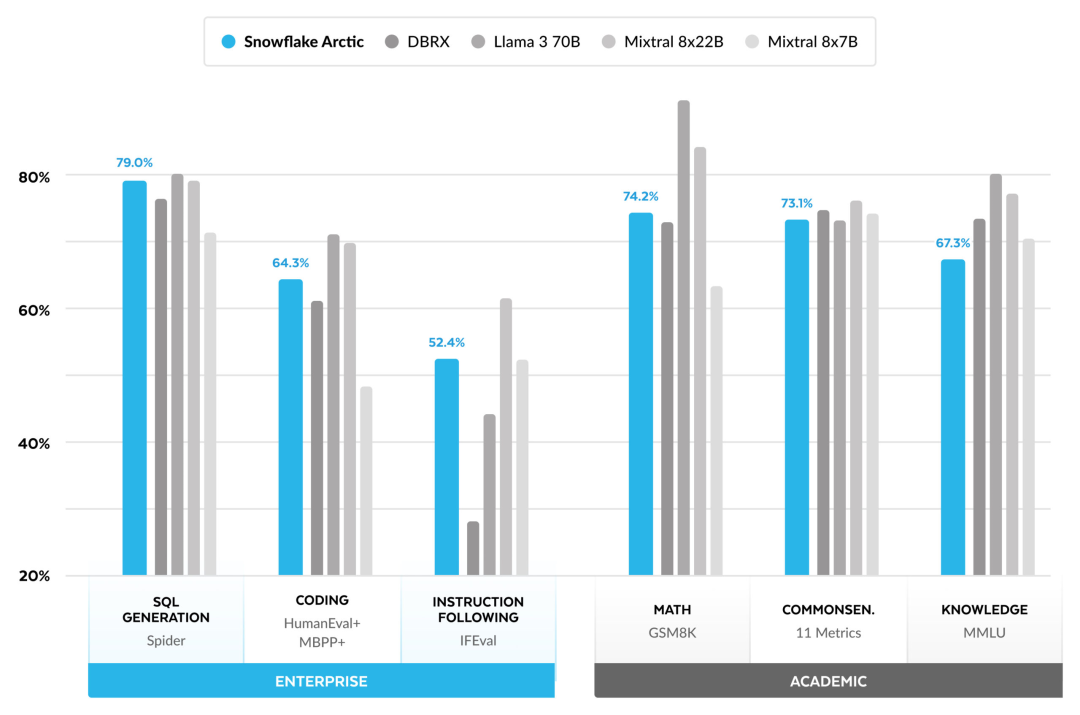
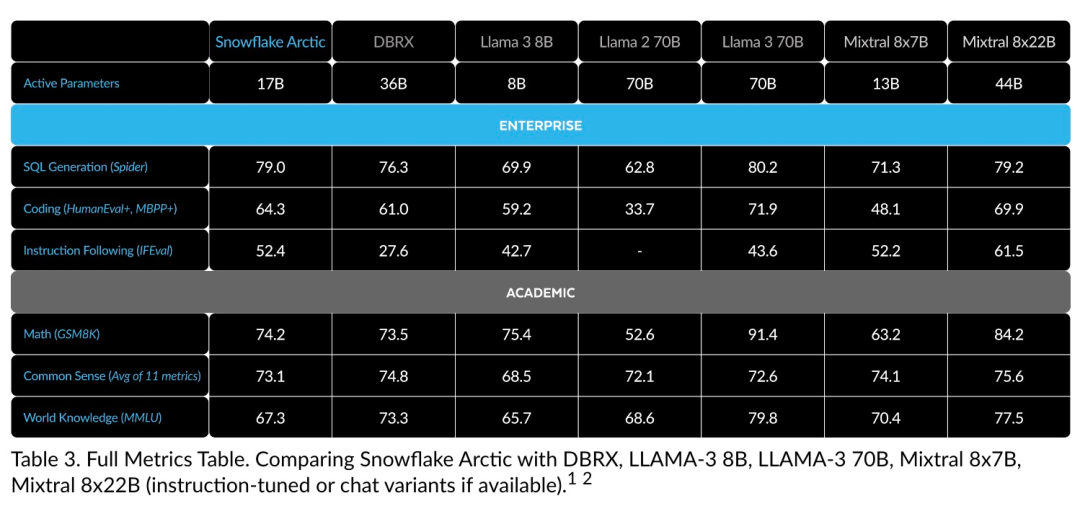
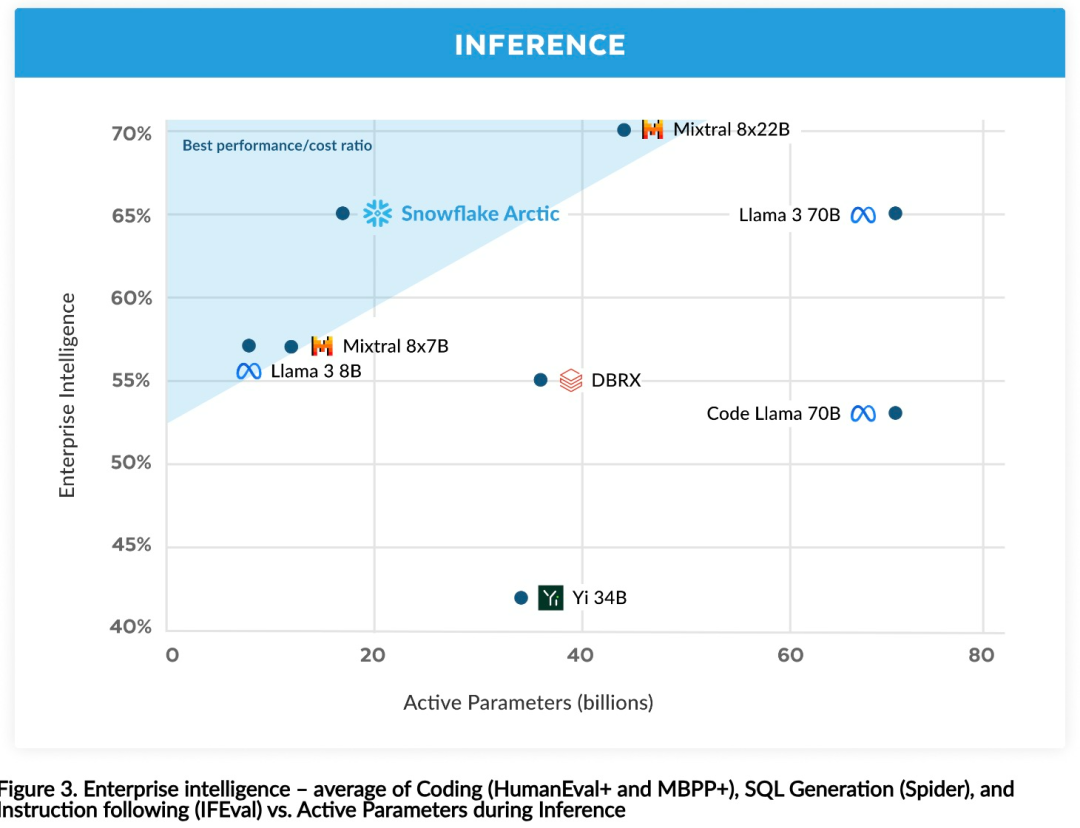
You can now access the Arctic model on Hugging Face. Snowflake said: Users will soon be able to obtain it through a number of model libraries, including Snowflake Cortex, AWS, Microsoft Azure, NVIDIA API, Lamini, Perplexity, Replicate and Together, etc. Hugging Face: https://huggingface.co/Snowflake/snowflake-arctic-instructArctic The context window is set to 4K, and the research team is developing a sliding window implementation based on attention-sink, which will support unlimited sequence generation in the next few weeks and expand to 32K attention windows in the near future. High performance, low costSnowflake’s research team draws from enterprise customers’ AI A consistent pattern is seen in the requirements and use cases: Enterprises want to use LLM to build conversational SQL data copilots, code copilots, and RAG chatbots. This means the LLM needs to excel in SQL, code, following complex instructions and generating concrete responses. Snowflake combines these capabilities into a single metric called "Enterprise Intelligence" by averaging encoding (HumanEval and MBPP), SQL generation (Spider), and instruction following (IFEval) performance levels. Arctic reaches the top level of "enterprise intelligence" in open source LLM, and does so at approximately less than $2 million in training compute costs (less than 3K GPU weeks) Under the circumstances. This means Arctic is more capable than other open source models trained with similar computational costs. #More importantly, Arctic excels at enterprise intelligence even when compared to models trained with far higher computational costs. Arctic’s high training efficiency means Snowflake’s customers and the AI community at large can train custom models more cost-effectively. As shown in Figure 1, Arctic is on par with LLAMA 3 8B and LLAMA 2 70B on enterprise intelligence metrics while using less than half the training compute cost. And, despite using only 1/17 times the computing cost, Arctic is comparable to Llama3 70B in indicators such as encoding (HumanEval and MBPP), SQL (Spider), and instruction following (IFEval), that is, Arctic maintains overall performance competitiveness. Did this at the same time. Additionally, Snowflake evaluated Arctic on academic benchmarks involving world knowledge, common sense reasoning, and mathematical abilities. The full assessment results are below. As shown in the picture: In order to achieve the above training efficiency, Arctic uses a unique Dense-MoE hybrid transformer architecture. It combines a 10B dense transformer model with a 128×3.66B residual MoE MLP, with a total of 480B parameters and 17B active parameters, using top-2 gating for selection.
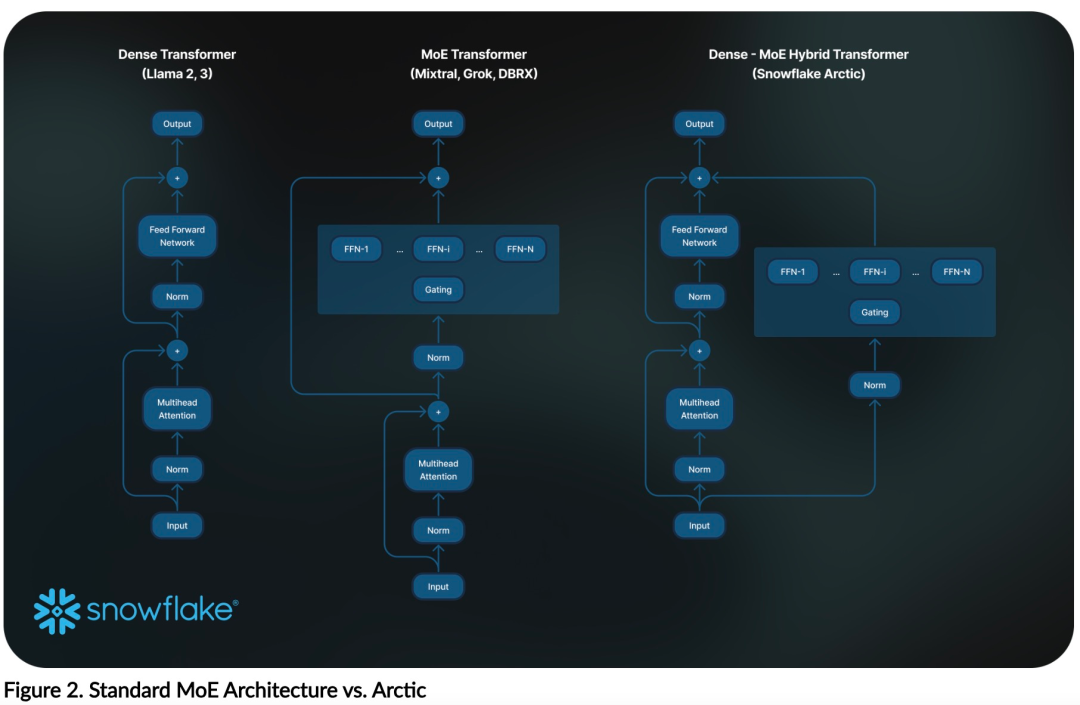
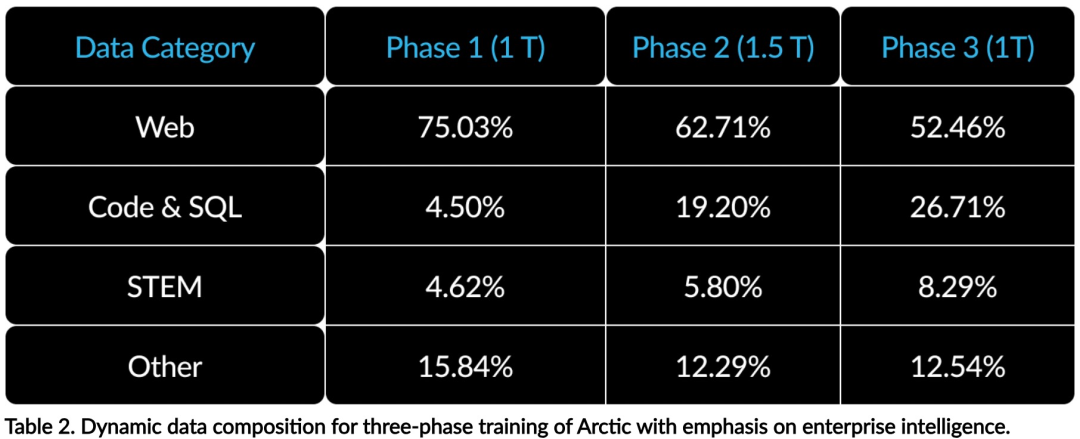
When designing and training Arctic, the research team used the following three key insights and innovations: MoE experts have a large number of experts and adopt compression technologyAt the end of 2021, the DeepSpeed team proved that MoE can be applied to autoregressive LLM, thereby significantly improving model quality without increasing computational cost. When designing Arctic, the research team noticed that based on this idea, the improvement of model quality mainly depends on the number of experts and the total number of parameters in the MoE model, as well as the number of combinations of these experts. Based on this, Arctic is designed to distribute 480B parameters among 128 fine-grained experts and use top-2 gating to select 17B active parameters . Architecture and system co-designTraining on powerful AI training hardware has The basic MoE architecture with a large number of experts is very inefficient because of the high overhead of fully connected communication between experts. Snowflake found that this overhead could be eliminated if communication could overlap with computation. Therefore, Arctic combines the dense transformer with the residual MoE component (Figure 2) to calculate the overlap through communication, allowing the training system to achieve good training efficiency, hiding communication overhead. Course learning focusing on enterprise dataEnterprise-level learning in code generation and SQL Excelling at metrics requires a very different kind of data curriculum learning than general metrics. Through hundreds of small-scale ablation experiments, the team learned that general skills, such as common-sense reasoning, can be learned in the initial stages; while more complex metrics, such as coding, math, and SQL, can be effectively learned later in training. This can be compared to human life education, gradually acquiring abilities from simple to difficult. Therefore, Arctic uses a three-stage curriculum, with each stage having a different data composition, with the first stage focusing on general skills (1T token) and the last two stages focusing on enterprise skills (1.5T and 1T token). Inference efficiency is also an important aspect of model efficiency, affecting Whether the model can be realistically deployed at low cost. Arctic represents a leap in the scale of MoE models, using more experts and total parameters than any other open source regression MoE model. Therefore, Snowflake needs several innovative ideas to ensure Arctic can infer efficiently: #a) In interactive inference with a small batch size, such as a batch size of 1, the MoE model The inference latency of is limited by the time to read all active parameters, and inference is limited by memory bandwidth. At this batch size, the memory read volume of Arctic (17B active parameters) is only 1/4 of Code-Llama 70B and 2/5 of Mixtral 8x22B (44B active parameters), resulting in faster inference rates. b) When the batch size increases significantly, such as thousands of tokens in each forward pass, Arctic changes from memory bandwidth limited to computationally limited, and inference suffers Limits on active parameters for each token. In this regard, Arctic is 1/4 the computational effort of CodeLlama 70B and Llama 3 70B. To achieve compute-bound inference and high throughput that matches the small number of active parameters in Arctic, a larger batch size is required. Achieving this requires sufficient KV cache to support it, as well as enough memory to store the model's nearly 500B parameters. Although challenging, Snowflake performs inference using two nodes and combines FP8 weights, split-fuse and continuous batching, intra-node tensor parallelism, and node This is achieved through system optimization such as inter-pipeline parallelism. The research team has worked closely with NVIDIA to optimize inference for NVIDIA NIM microservices powered by TensorRT-LLM. At the same time, the research team is also working with the vLLM community, and internal development teams will also implement Arctic's efficient inference for enterprise use cases in the coming weeks. Reference link: https://www.snowflake.com/blog/arctic-open-efficient-foundation-language-models-snowflake/ The above is the detailed content of With only 1/17 the training cost of Llama3, Snowflake open source 128x3B MoE model. For more information, please follow other related articles on the PHP Chinese website!