

 Technology peripheralsAIAdd SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Technology peripheralsAIAdd SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!

Written before&The author’s personal understanding
In the autonomous driving system, the perception task is a crucial component of the entire autonomous driving system. The main goal of the perception task is to enable autonomous vehicles to understand and perceive surrounding environmental elements, such as vehicles driving on the road, pedestrians on the roadside, obstacles encountered during driving, traffic signs on the road, etc., thereby helping downstream modules Make correct and reasonable decisions and actions. A vehicle with self-driving capabilities is usually equipped with different types of information collection sensors, such as surround-view camera sensors, lidar sensors, millimeter-wave radar sensors, etc., to ensure that the self-driving vehicle can accurately perceive and understand surrounding environment elements. , enabling autonomous vehicles to make correct decisions during autonomous driving.
Currently, pure image-based visual perception methods have lower hardware costs and deployment costs than lidar-based perception algorithms, and therefore have received widespread attention from industry and academia. Many excellent visual perception algorithms have emerged to achieve 3D object perception tasks and semantic segmentation tasks in BEV scenes. Although existing 3D target perception algorithms have made significant progress in detection performance, there are still some problems that are gradually revealed in practical applications:
- The original 3D target perception algorithm cannot perform well It solves the long-tail problem that exists in the data set, as well as the objects that exist in the real world but may not be labeled in the current training data set (such as: large rocks on the road, overturned vehicles, etc.)
- Original Some 3D target perception algorithms usually directly output a rough 3D stereoscopic bounding box and cannot accurately describe target objects of arbitrary shapes. The expression of object shape and geometric structure is not fine-grained enough. Although this output result box can satisfy most object scenes, for example, connected buses or construction vehicles with long hooks, the current 3D perception algorithm cannot give an accurate and clear description
Based on the related issues mentioned above, the grid occupancy network (Occupancy Network) sensing algorithm was proposed. Essentially, the Occupancy Network perception algorithm is a semantic segmentation task based on 3D spatial scenes. The Occupancy Network perception algorithm based on pure vision will divide the current 3D space into 3D voxel grids, and send the collected surrounding images to the network model through the surrounding camera sensor equipped on the autonomous vehicle. After the algorithm model Processing and prediction, output the occupancy status of each 3D voxel grid in the current space and the possible target semantic categories, thereby achieving a comprehensive perception of the current 3D space scene.
In recent years, the perception algorithm based on Occupancy Network has received extensive attention from researchers due to its better perception advantages. At present, many excellent works have emerged to improve the detection performance of this type of algorithm. The general direction of these papers is: proposing more robust feature extraction methods, coordinate transformation methods from 2D features to 3D features, more complex network structure designs, and how to more accurately generate Occupancy ground truth annotations to help model learning, etc. However, many existing Occupancy Network perception methods have serious computational overhead in the process of model prediction and inference, making it difficult for these algorithms to meet the requirements of real-time perception for autonomous driving and difficult to deploy in vehicles.
We propose an innovative Occupancy Network prediction method. Compared with current leading perception algorithms, our FastOcc algorithm has real-time inference speed and excellent detection performance. The following figure can visually compare the difference in performance and inference speed between our proposed algorithm and other algorithms.
 Comparison of accuracy and inference speed between FastOcc algorithm and other SOTA algorithms
Comparison of accuracy and inference speed between FastOcc algorithm and other SOTA algorithms
Paper link: https://arxiv.org/pdf/2403.02710.pdf
Overall architecture & details of the network model
In order to improve the inference speed of the Occupancy Network perception algorithm, we extracted the backbone network from the resolution of the input image, the feature extraction method, the method of perspective conversion, and the raster Experiments were conducted on four parts of the prediction head structure. Through the experimental results, it was found that the three-dimensional convolution or deconvolution in the grid prediction head has a large space for time-consuming optimization. Based on this, we designed the network structure of the FastOcc algorithm, as shown in the figure below.
 FastOcc algorithm network structure diagram
FastOcc algorithm network structure diagram
Overall, the proposed FastOcc algorithm includes three sub-modules, which are Image Feature Extraction for multi-scale feature extraction , View Transformation is used for perspective conversion, and Occupancy Prediction Head is used to achieve perceptual output. Next, we will introduce the details of these three parts respectively.
Image Feature Extraction
For the proposed FastOcc algorithm, the network input is still the collected surround image. Here we use the ResNet network structure to complete Feature extraction process for surround images. At the same time, we also use the FPN feature pyramid structure to aggregate the multi-scale image features output by the backbone network. For the convenience of subsequent expression, here we represent the input image as , and the features after feature extraction as .
View Transformation
The main function of the view transformation module is to complete the conversion process of 2D image features to 3D space features, and at the same time, in order to reduce the overhead of the algorithm model , usually the features converted to 3D space will be expressed roughly. For convenience of expression here, we mark the features converted to 3D space as , which represents the dimension of the embedded feature vector and represents the length, width and height of the perceptual space. Among the current perception algorithms, the mainstream perspective conversion process includes two categories:
- One is the Backward coordinate transformation method represented by BEVFormer. This type of method usually generates a voxel query in 3D space first, and then uses Cross-view Attention to interact with the voxel query in 3D space and 2D image features to complete the construction of the final 3D voxel feature.
- The first category is the Forward coordinate transformation method represented by LSS. This type of method will use the depth estimation network in the network to simultaneously estimate the semantic feature information and discrete depth probability of each feature pixel position, construct the semantic frustum feature through the outer product operation, and finally use the VoxelPooling layer to achieve the final 3D voxel feature. of construction.
Considering that the LSS algorithm has better reasoning speed and efficiency, in this article, we adopt the LSS algorithm as our perspective conversion module. At the same time, considering that the discrete depth of each pixel position is estimated, its uncertainty will restrict the final perceptual performance of the model to a certain extent. Therefore, in our specific implementation, we utilize point cloud information for supervision in the depth direction to achieve better perception results.
Raster Prediction Head (Occupancy Prediction Head)
In the network structure diagram shown above, the grid prediction head also contains three sub-parts, namelyBEV feature extraction, Image feature interpolation sampling, Feature integration. Next, we will introduce the details of the three-part method one by one.
BEV feature extraction
Currently, most Occupancy Network algorithms process the 3D voxel features obtained by the perspective conversion module. The processing form is generally a three-dimensional fully convolutional network. Specifically, for any layer of the three-dimensional fully convolutional network, the amount of calculation required to convolve the input three-dimensional voxel features is as follows:
where, and represent the input features and output features respectively. The number of channels represents the size of the feature map space. Compared to processing voxel features directly in 3D space, we use a lightweight 2D BEV feature convolution module. Specifically, for the output voxel features of the perspective conversion module, we first fuse height information and semantic features to obtain 2D BEV features, and then use a 2D fully convolutional network to perform feature extraction to obtain BEV features. The feature extraction of this 2D process The calculation amount of the process can be expressed in the following form
It can be seen from the comparison of the calculation amount of the 3D and 2D processing processes that the original 3D voxel features are replaced by the lightweight 2D BEV feature convolution module Extraction can significantly reduce the computational effort of a model. At the same time, the visual flow charts of the two types of processing processes are shown below:
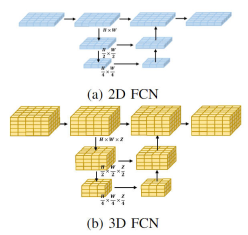
Visualization of 2D FCN and 3D FCN network structures
Image Feature interpolation sampling
In order to reduce the calculation amount of the raster prediction head module, we compress the height of the 3D voxel features output by the perspective conversion module, and use the 2D BEV convolution module for feature extraction . However, in order to increase the missing Z-axis height feature information and adhere to the idea of reducing the amount of model calculations, we proposed an image feature interpolation sampling method.
Specifically, we first set the corresponding three-dimensional voxel space according to the range that needs to be sensed, and assign it to the ego coordinate system, denoted as. Secondly, the camera's extrinsic and intrinsic coordinate transformation matrices are used to project the coordinate points in the ego coordinate system to the image coordinate system, which is used to extract image features at the corresponding positions.
Among them, and represent the intrinsic and extrinsic coordinate transformation matrices of the camera respectively, representing the position of the spatial point in the ego coordinate system projected to the image coordinate system. After obtaining the corresponding image coordinates, we filter out coordinate points that exceed the image range or have negative depth. Then, we use bilinear interpolation operation to obtain the corresponding image semantic features based on the projected coordinate position, and average the features collected from all camera images to obtain the final interpolation sampling result.
Feature integration
In order to integrate the obtained planar BEV features with the 3D voxel features obtained by interpolation sampling, we first use the upsampling operation to combine the spatial dimensions of the BEV features with the 3D The spatial dimensions of the voxel features are aligned, and a repeat operation is performed along the Z-axis direction. The features obtained after the operation are recorded as . Then we concat the features obtained by interpolation sampling of image features and integrate them through a convolutional layer to obtain the final voxel feature.
The above-mentioned image feature interpolation sampling and feature integration process can be represented by the following figure:
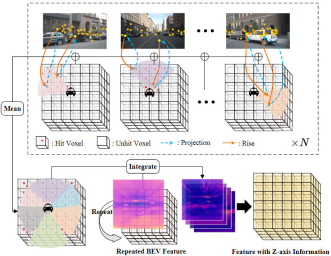
Image feature interpolation sampling and feature integration process
In addition, in order to further ensure that the BEV features output by the BEV feature extraction module contain sufficient feature information to complete the subsequent perception process, we adopted an additional supervision method, that is, using a semantic segmentation Let’s start with the semantic segmentation task first, and use the true value of Occupancy to construct the true value label of semantic segmentation to complete the entire supervision process.
Experimental results & evaluation indicators
Quantitative analysis part
First show the FastOcc algorithm we proposed in Occ3D-nuScenes The comparison between the data set and other SOTA algorithms. The specific indicators of each algorithm are shown in the table below
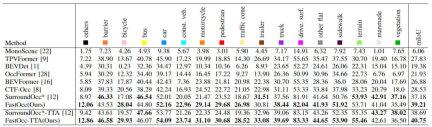
Comparison of each algorithm indicator on the Occ3D-nuScenes data set
It can be seen from the results in the table that the FastOcc algorithm we proposed has more advantages in most categories than other algorithms. At the same time, the overall mIoU index also achieves SOTA Effect.
In addition, we also compared the impact of different perspective conversion methods and the decoding feature module used in the raster prediction head on perceptual performance and reasoning time (the experimental data are all based on the input image The resolution is 640×1600, and the backbone network uses the ResNet-101 network). The relevant experimental results are compared as shown in the table below
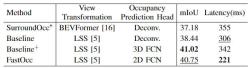
Different perspective conversions and raster prediction heads Comparison of accuracy and inference time consumption
The SurroundOcc algorithm uses a multi-scale Cross-view Attention perspective conversion method and 3D convolution to extract 3D voxel features, and has the highest inference time consumption. After we replaced the original Cross-view Attention perspective conversion method with the LSS conversion method, the mIoU accuracy has been improved and the time consumption has been reduced. On this basis, by replacing the original 3D convolution with a 3D FCN structure, the accuracy can be further increased, but the reasoning time is also significantly increased. Finally, we chose the coordinate conversion method of sampling LSS and the 2D FCN structure to achieve a balance between detection performance and inference time consumption.
In addition, we also verified the effectiveness of our proposed semantic segmentation supervision task based on BEV features and image feature interpolation sampling. The specific ablation experimental results are shown in the following table:
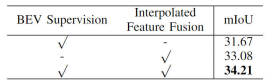
Comparison of ablation experiments of different modules
In addition, we also conducted scale experiments on the model. By controlling the size of the backbone network and the resolution of the input image, we constructed a Set Occupancy Network perception algorithm model (FastOcc, FastOcc-Small, FastOcc-Tiny), the specific configuration is shown in the table below:
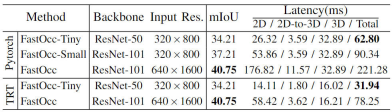
Model capabilities under different backbone network and resolution configurations Comparison
Qualitative analysis part
The following figure shows the comparison of the visual results of our proposed FastOcc algorithm model and the SurroundOcc algorithm model. It can be clearly seen that the proposed The FastOcc algorithm model fills in the surrounding environment elements in a more reasonable way and achieves more accurate perception of driving vehicles and trees.

Comparison of visualization results between FastOcc algorithm and SurroundOcc algorithm
Conclusion
In this article, we proposed the FastOcc algorithm model to solve the problem that the existing Occupancy Network algorithm model takes a long time to detect and is difficult to deploy on the vehicle. By replacing the original 3D convolution module that processes 3D voxels with 2D convolution, the reasoning time is greatly shortened, and compared with other algorithms, SOTA perception results are achieved.
The above is the detailed content of Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!. For more information, please follow other related articles on the PHP Chinese website!

 7 Powerful AI Prompts Every Project Manager Needs To Master NowMay 08, 2025 am 11:39 AM
7 Powerful AI Prompts Every Project Manager Needs To Master NowMay 08, 2025 am 11:39 AMGenerative AI, exemplified by chatbots like ChatGPT, offers project managers powerful tools to streamline workflows and ensure projects stay on schedule and within budget. However, effective use hinges on crafting the right prompts. Precise, detail
 Defining The Ill-Defined Meaning Of Elusive AGI Via The Helpful Assistance Of AI ItselfMay 08, 2025 am 11:37 AM
Defining The Ill-Defined Meaning Of Elusive AGI Via The Helpful Assistance Of AI ItselfMay 08, 2025 am 11:37 AMThe challenge of defining Artificial General Intelligence (AGI) is significant. Claims of AGI progress often lack a clear benchmark, with definitions tailored to fit pre-determined research directions. This article explores a novel approach to defin
 IBM Think 2025 Showcases Watsonx.data's Role In Generative AIMay 08, 2025 am 11:32 AM
IBM Think 2025 Showcases Watsonx.data's Role In Generative AIMay 08, 2025 am 11:32 AMIBM Watsonx.data: Streamlining the Enterprise AI Data Stack IBM positions watsonx.data as a pivotal platform for enterprises aiming to accelerate the delivery of precise and scalable generative AI solutions. This is achieved by simplifying the compl
 The Rise of the Humanoid Robotic Machines Is Nearing.May 08, 2025 am 11:29 AM
The Rise of the Humanoid Robotic Machines Is Nearing.May 08, 2025 am 11:29 AMThe rapid advancements in robotics, fueled by breakthroughs in AI and materials science, are poised to usher in a new era of humanoid robots. For years, industrial automation has been the primary focus, but the capabilities of robots are rapidly exp
 Netflix Revamps Interface — Debuting AI Search Tools And TikTok-Like DesignMay 08, 2025 am 11:25 AM
Netflix Revamps Interface — Debuting AI Search Tools And TikTok-Like DesignMay 08, 2025 am 11:25 AMThe biggest update of Netflix interface in a decade: smarter, more personalized, embracing diverse content Netflix announced its largest revamp of its user interface in a decade, not only a new look, but also adds more information about each show, and introduces smarter AI search tools that can understand vague concepts such as "ambient" and more flexible structures to better demonstrate the company's interest in emerging video games, live events, sports events and other new types of content. To keep up with the trend, the new vertical video component on mobile will make it easier for fans to scroll through trailers and clips, watch the full show or share content with others. This reminds you of the infinite scrolling and very successful short video website Ti
 Long Before AGI: Three AI Milestones That Will Challenge YouMay 08, 2025 am 11:24 AM
Long Before AGI: Three AI Milestones That Will Challenge YouMay 08, 2025 am 11:24 AMThe growing discussion of general intelligence (AGI) in artificial intelligence has prompted many to think about what happens when artificial intelligence surpasses human intelligence. Whether this moment is close or far away depends on who you ask, but I don’t think it’s the most important milestone we should focus on. Which earlier AI milestones will affect everyone? What milestones have been achieved? Here are three things I think have happened. Artificial intelligence surpasses human weaknesses In the 2022 movie "Social Dilemma", Tristan Harris of the Center for Humane Technology pointed out that artificial intelligence has surpassed human weaknesses. What does this mean? This means that artificial intelligence has been able to use humans
 Venkat Achanta On TransUnion's Platform Transformation And AI AmbitionMay 08, 2025 am 11:23 AM
Venkat Achanta On TransUnion's Platform Transformation And AI AmbitionMay 08, 2025 am 11:23 AMTransUnion's CTO, Ranganath Achanta, spearheaded a significant technological transformation since joining the company following its Neustar acquisition in late 2021. His leadership of over 7,000 associates across various departments has focused on u
 When Trust In AI Leaps Up, Productivity FollowsMay 08, 2025 am 11:11 AM
When Trust In AI Leaps Up, Productivity FollowsMay 08, 2025 am 11:11 AMBuilding trust is paramount for successful AI adoption in business. This is especially true given the human element within business processes. Employees, like anyone else, harbor concerns about AI and its implementation. Deloitte researchers are sc


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Linux new version
SublimeText3 Linux latest version

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

