

 Technology peripheralsAILava Alpaca LLaVA is here: like GPT-4, you can view pictures and chat, no invitation code is required, and you can play online
Technology peripheralsAILava Alpaca LLaVA is here: like GPT-4, you can view pictures and chat, no invitation code is required, and you can play onlineLava Alpaca LLaVA is here: like GPT-4, you can view pictures and chat, no invitation code is required, and you can play online


#When will GPT-4’s image recognition capabilities be online? There is still no answer to this question.
But the research community can’t wait any longer and have started DIY. The most popular one is a project called MiniGPT-4. MiniGPT-4 demonstrates many capabilities similar to GPT-4, such as generating detailed image descriptions and creating websites from handwritten drafts. Additionally, the authors observed other emerging capabilities of MiniGPT-4, including creating stories and poems based on given images, providing solutions to problems shown in images, teaching users how to cook based on food photos, etc. The project received nearly 10,000 stars within 3 days of its launch.

The project we are going to introduce today - LLaVA (Large Language and Vision Assistant) is similar and is a project developed by the University of Wisconsin-Madison and Microsoft A large multi-modal model jointly released by researchers from the Institute and Columbia University.

- ## Paper link: https://arxiv.org/pdf/2304.08485.pdf
- Project link: https://llava-vl.github.io/
This model shows some Image and text understanding ability close to multi-modal GPT-4: it achieved a relative score of 85.1% compared to GPT-4. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new SoTA with 92.53% accuracy.

The following are the trial results of the Heart of the Machine (see the end of the article for more results):

Humans interact with the world through multiple channels such as vision and language, because different channels have their own unique advantages in representing and conveying certain concepts. Multi-channel way to better understand the world. One of the core aspirations of artificial intelligence is to develop a universal assistant that can effectively follow multi-modal instructions, such as visual or verbal instructions, satisfy human intentions, and complete various tasks in real environments.
To this end, there has been a trend in the community to develop visual models based on language enhancement. This type of model has powerful capabilities in open-world visual understanding, such as classification, detection, segmentation, and graphics, as well as visual generation and visual editing capabilities. Each task is independently solved by a large visual model, with the needs of the task implicitly considered in the model design. Furthermore, language is used only to describe image content. While this makes language play an important role in mapping visual signals to linguistic semantics (a common channel for human communication), it results in models that often have fixed interfaces with limitations in interactivity and adaptability to user instructions.
Large Language Models (LLMs), on the other hand, have shown that language can play a broader role: as a universal interactive interface for general-purpose intelligent assistants. In a common interface, various task instructions can be explicitly expressed in language and guide the end-to-end trained neural network assistant to switch modes to complete the task. For example, the recent success of ChatGPT and GPT-4 demonstrated the power of LLM in following human instructions to complete tasks and sparked a wave of development of open source LLM. Among them, LLaMA is an open source LLM with performance similar to GPT-3. Alpaca, Vicuna, GPT-4-LLM utilizes various machine-generated high-quality instruction trace samples to improve the alignment capabilities of LLM, demonstrating impressive performance compared to proprietary LLMs. Unfortunately, the input to these models is text only.
In this article, researchers propose a visual instruction-tuning method, which is the first attempt to extend instruction-tuning to a multi-modal space, paving the way for building a general visual assistant.
Specifically, this paper makes the following contributions:
- Multimodal instruction data. One of the key challenges today is the lack of visual and verbal command data. This paper proposes a data reorganization approach using ChatGPT/GPT-4 to convert image-text pairs into appropriate instruction formats;
- Large multi-modal models. The researchers developed a large multimodal model (LMM) - LLaVA - by connecting CLIP's open source visual encoder and language decoder LLaMA, and performed end-to-end fine-tuning on the generated visual-verbal instruction data. Empirical research verifies the effectiveness of using generated data for LMM instruction-tuning, and provides more practical techniques for building universal instructions that follow visual agents. Using GPT-4, we achieve state-of-the-art performance on Science QA, a multimodal inference dataset.
- Open source. The researchers released the following assets to the public: the generated multi-modal instruction data, code libraries for data generation and model training, model checkpoints, and visual chat demonstrations.
LLaVA Architecture
The main goal of this article is to effectively utilize the power of pre-trained LLM and vision models. The network architecture is shown in Figure 1. This paper chooses the LLaMA model as the LLM fφ(・) because its effectiveness has been demonstrated in several open source pure language instruction-tuning works.
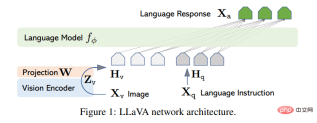
For the input image X_v, this article uses the pre-trained CLIP visual encoder ViT-L/14 for processing, and obtains the visual feature Z_v=g ( X_v). The mesh features before and after the last Transformer layer were used in the experiment. This article uses a simple linear layer to connect image features into word embedding space. Specifically, a trainable projection matrix W is applied to transform Z_v into a language embedding token H_q, which has the same dimensions as the word embedding space in the language model:

#After that, a series of visual markers H_v are obtained. This simple projection scheme is lightweight, low-cost, and can quickly iterate on data-centric experiments. One can also consider more complex (but expensive) schemes for concatenating image and language features, such as the gated cross-attention mechanism in Flamingo and Q-former in BLIP-2, or other visual encoders that provide object-level features, such as SAM.
Experimental results
Multimodal chatbot
The researcher developed a chat Robot sample product to demonstrate LLaVA's image understanding and dialogue capabilities. In order to further study how LLaVA processes visual input and demonstrate its ability to process instructions, the researchers first used examples from the original GPT-4 paper, as shown in Tables 4 and 5. The prompt used needs to fit the image content. For comparison, this article quotes the prompts and results of the multimodal model GPT-4 from their paper.


Surprisingly, although LLaVA was performed using a small multi-modal instruction dataset ( (about 80K unique images), but it shows very similar inference results to the multi-modal model GPT-4 on the above two examples. Note that both images are outside the scope of LLaVA's dataset, which is capable of understanding the scene and answering the question instructions. In contrast, BLIP-2 and OpenFlamingo focus on describing images rather than answering user instructions in an appropriate manner. More examples are shown in Figure 3, Figure 4, and Figure 5.



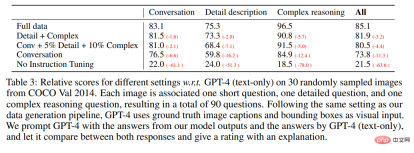
Quantitative evaluation results are shown in Table 3.
ScienceQA
ScienceQA contains 21k multi-modal multiple selections Questions, involving 3 themes, 26 topics, 127 categories and 379 skills, with rich domain diversity. The benchmark dataset is divided into training, validation and testing parts with 12726, 4241 and 4241 samples respectively. This article compares two representative methods, including the GPT-3.5 model (text-davinci-002) and the GPT-3.5 model without Chain of Thought (CoT) version, LLaMA-Adapter, and Multimodal Thought Chain (MM- CoT) [57], which is the current SoTA method on this dataset, and the results are shown in Table 6.

Trial feedback
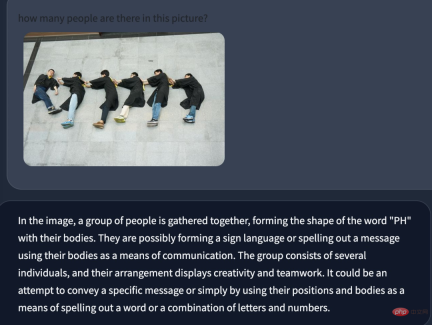
On the visualization usage page given in the paper, the machine heart also tried to input some pictures and instruction. The first is a common multi-person task in Q&A. Tests have shown that smaller targets are ignored when counting people, there are recognition errors for overlapping people, and there are also recognition errors for gender.

Next, we tried some generation tasks, such as naming the picture, or telling a story based on the picture story. The results output by the model are still biased towards understanding the image content, and the generation capabilities need to be strengthened.

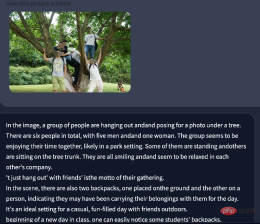
In this photo, even if the human bodies overlap, the number of people can still be accurately identified. From the perspective of picture description and understanding ability, there are still highlights in the work of this article, and there is room for second creation.
The above is the detailed content of Lava Alpaca LLaVA is here: like GPT-4, you can view pictures and chat, no invitation code is required, and you can play online. For more information, please follow other related articles on the PHP Chinese website!

 Does Hugging Face's 7B Model OlympicCoder Beat Claude 3.7?Apr 23, 2025 am 11:49 AM
Does Hugging Face's 7B Model OlympicCoder Beat Claude 3.7?Apr 23, 2025 am 11:49 AMHugging Face's OlympicCoder-7B: A Powerful Open-Source Code Reasoning Model The race to develop superior code-focused language models is intensifying, and Hugging Face has joined the competition with a formidable contender: OlympicCoder-7B, a product
 4 New Gemini Features You Can't Afford to MissApr 23, 2025 am 11:48 AM
4 New Gemini Features You Can't Afford to MissApr 23, 2025 am 11:48 AMHow many of you have wished AI could do more than just answer questions? I know I have, and as of late, I’m amazed by how it’s transforming. AI chatbots aren’t just about chatting anymore, they’re about creating, researchin
 Camunda Writes New Score For Agentic AI OrchestrationApr 23, 2025 am 11:46 AM
Camunda Writes New Score For Agentic AI OrchestrationApr 23, 2025 am 11:46 AMAs smart AI begins to be integrated into all levels of enterprise software platforms and applications (we must emphasize that there are both powerful core tools and some less reliable simulation tools), we need a new set of infrastructure capabilities to manage these agents. Camunda, a process orchestration company based in Berlin, Germany, believes it can help smart AI play its due role and align with accurate business goals and rules in the new digital workplace. The company currently offers intelligent orchestration capabilities designed to help organizations model, deploy and manage AI agents. From a practical software engineering perspective, what does this mean? The integration of certainty and non-deterministic processes The company said the key is to allow users (usually data scientists, software)
 Is There Value In A Curated Enterprise AI Experience?Apr 23, 2025 am 11:45 AM
Is There Value In A Curated Enterprise AI Experience?Apr 23, 2025 am 11:45 AMAttending Google Cloud Next '25, I was keen to see how Google would distinguish its AI offerings. Recent announcements regarding Agentspace (discussed here) and the Customer Experience Suite (discussed here) were promising, emphasizing business valu
 How to Find the Best Multilingual Embedding Model for Your RAG?Apr 23, 2025 am 11:44 AM
How to Find the Best Multilingual Embedding Model for Your RAG?Apr 23, 2025 am 11:44 AMSelecting the Optimal Multilingual Embedding Model for Your Retrieval Augmented Generation (RAG) System In today's interconnected world, building effective multilingual AI systems is paramount. Robust multilingual embedding models are crucial for Re
 Musk: Robotaxis In Austin Need Intervention Every 10,000 MilesApr 23, 2025 am 11:42 AM
Musk: Robotaxis In Austin Need Intervention Every 10,000 MilesApr 23, 2025 am 11:42 AMTesla's Austin Robotaxi Launch: A Closer Look at Musk's Claims Elon Musk recently announced Tesla's upcoming robotaxi launch in Austin, Texas, initially deploying a small fleet of 10-20 vehicles for safety reasons, with plans for rapid expansion. H
 AI's Shocking Pivot: From Work Tool To Digital Therapist And Life CoachApr 23, 2025 am 11:41 AM
AI's Shocking Pivot: From Work Tool To Digital Therapist And Life CoachApr 23, 2025 am 11:41 AMThe way artificial intelligence is applied may be unexpected. Initially, many of us might think it was mainly used for creative and technical tasks, such as writing code and creating content. However, a recent survey reported by Harvard Business Review shows that this is not the case. Most users seek artificial intelligence not just for work, but for support, organization, and even friendship! The report said that the first of AI application cases is treatment and companionship. This shows that its 24/7 availability and the ability to provide anonymous, honest advice and feedback are of great value. On the other hand, marketing tasks (such as writing a blog, creating social media posts, or advertising copy) rank much lower on the popular use list. Why is this? Let's see the results of the research and how it continues to be
 Companies Race Toward AI Agent AdoptionApr 23, 2025 am 11:40 AM
Companies Race Toward AI Agent AdoptionApr 23, 2025 am 11:40 AMThe rise of AI agents is transforming the business landscape. Compared to the cloud revolution, the impact of AI agents is predicted to be exponentially greater, promising to revolutionize knowledge work. The ability to simulate human decision-maki


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

SublimeText3 Chinese version
Chinese version, very easy to use

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

SublimeText3 Mac version
God-level code editing software (SublimeText3)

