
Home >Technology peripherals >AI >Talk about the data-centric AI behind the GPT model
Talk about the data-centric AI behind the GPT model

- 王林forward
- 2023-04-11 23:55:011462browse
Artificial intelligence (AI) is making huge strides in changing the way we live, work, and interact with technology. Recently, an area where significant progress has been made is the development of large language models (LLMs) such as GPT-3, ChatGPT, and GPT-4. These models can accurately perform tasks such as language translation, text summarization, and question answering.

While it is difficult to ignore the ever-increasing model sizes of LLMs, it is equally important to recognize that their success is largely due to the large number of High quality data.
In this article, we will provide an overview of recent advances in LLM from a data-centric AI perspective. We'll examine GPT models through a data-centric AI lens, a growing concept in the data science community. We reveal the data-centric AI concepts behind the GPT model by discussing three data-centric AI goals: training data development, inference data development, and data maintenance.
Large Language Model (LLM) and GPT Model
LLM is a natural language processing model trained to infer words in context. For example, the most basic function of LLM is to predict missing markers given context. To do this, LLMs are trained to predict the probability of each candidate word from massive amounts of data. The figure below is an illustrative example of using LLM in context to predict the probability of missing markers.

GPT model refers to a series of LLMs created by OpenAI, such as GPT-1, GPT-2, GPT-3, InstructGPT, ChatGPT/GPT-4, etc. Like other LLMs, the architecture of the GPT model is mainly based on Transformers, which uses text and location embeddings as inputs and uses attention layers to model the relationships of tokens.
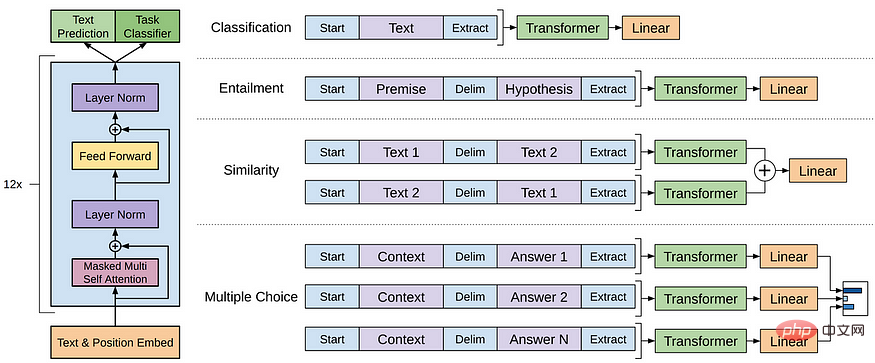
GPT-1 model architecture
Later GPT models use a similar architecture to GPT-1, except that they use more model parameters and more layers. Larger context length, hidden layer size, etc.

What is Data-Centric Artificial Intelligence
Data-centric AI is an emerging new way of thinking about how to build AI systems. Data-centric AI is the discipline of systematically designing the data used to build artificial intelligence systems.
In the past, we have mainly focused on creating better models (model-centric AI) when the data is basically unchanged. However, this approach can cause problems in the real world because it does not take into account different issues that can arise in the data, such as label inaccuracies, duplications, and biases. Therefore, "overfitting" a data set does not necessarily lead to better model behavior.
In contrast, data-centric AI focuses on improving the quality and quantity of data used to build AI systems. This means that the attention is on the data itself and the model is relatively more fixed. Using a data-centric approach to develop AI systems has greater potential in real-world scenarios, as the data used for training ultimately determines the model's maximum capabilities.
It should be noted that there is a fundamental difference between "data-centered" and "data-driven". The latter only emphasizes using data to guide the development of artificial intelligence, and usually still focuses on developing models rather than data. .

Comparison between data-centric artificial intelligence and model-centric artificial intelligence
The data-centric AI framework contains three Target:
- Training data development is to collect and produce rich, high-quality data to support the training of machine learning models.
- Inference data development is for creating new evaluation sets that can provide more fine-grained insights into the model or trigger specific features of the model through data input.
- Data maintenance is to ensure the quality and reliability of data in a dynamic environment. Data maintenance is critical because real-world data is not created once but requires ongoing maintenance.

Data-centric AI framework
Why data-centric AI makes the GPT model successful
A few A few months ago, Yann LeCun tweeted that ChatGPT was nothing new. In fact, all the techniques used in ChatGPT and GPT-4 (transformers, reinforcement learning from human feedback, etc.) are not new at all. However, they did achieve results that were not possible with previous models. So, what is the reason for their success?
Training data development. The quantity and quality of data used to train GPT models has improved significantly through better data collection, data labeling, and data preparation strategies.
-
GPT-1: BooksCorpus dataset is used for training. The dataset contains 4629.00 MB of raw text covering various genres of books such as adventure, fantasy, and romance.
-Data-Centric AI Strategy: None.
- Results: Using GPT-1 on this dataset can improve the performance of downstream tasks through fine-tuning. -
GPT-2: Use WebText in training. This is an internal dataset within OpenAI created by scraping outbound links from Reddit.
- Data-Centric AI Strategy: (1) Collate/filter data using only outbound links from Reddit that earn at least 3 karma. (2) Use tools Dragnet and Newspaper to extract clean content. (3) Use deduplication and some other heuristic-based cleaning.
- Result: 40 GB of text after filtering. GPT-2 achieves robust zero-shot results without fine-tuning. -
GPT-3: The training of GPT-3 is mainly based on Common Crawl.
-Data-centric AI strategy: (1) Train a classifier to filter out low-quality documents based on each document's similarity to WebText (high-quality documents). (2) Use Spark’s MinHashLSH to fuzzy and deduplicate documents. (3) Data augmentation using WebText, book corpus, and Wikipedia.
- Result: 45TB of plaintext was filtered and 570GB of text was obtained (only 1.27% of the data was selected for this quality filtering). GPT-3 significantly outperforms GPT-2 in the zero-sample setting. -
InstructGPT: Let human evaluation adjust GPT-3 answers to better match human expectations. They designed a test for annotators, and only those who passed the test were eligible for annotation. They even designed a survey to ensure annotators were fully engaged in the annotation process.
-Data-centric AI strategy: (1) Tune the model through supervised training using answers to prompts provided by humans. (2) Collect comparative data to train a reward model, and then use this reward model to tune GPT-3 through reinforcement learning with human feedback (RLHF).
- Results: InstructGPT exhibits better realism and less bias, i.e. better alignment. - ChatGPT/GPT-4: OpenAI did not disclose details. But as we all know, ChatGPT/GPT-4 largely follows the design of the previous GPT model, and they still use RLHF to tune the model (possibly with more and higher quality data/labels). It is generally accepted that GPT-4 uses larger datasets as the model weights increase.
Inference data development. Since recent GPT models have become powerful enough, we can achieve various goals by adjusting hints or adjusting inference data while the model is fixed. For example, we can perform text summarization by providing the text to be summarized and instructions such as "summarize it" or "TL;DR" to guide the reasoning process.

Adjust in time
Designing the right reasoning prompts is a challenging task. It relies heavily on heuristics. A good survey summarizes the different promotional methods. Sometimes, even semantically similar cues can have very different outputs. In this case, soft cue-based calibration may be needed to reduce variance.

#Research on LLM inference data development is still in its early stages. In the near future, more inferential data development techniques that have been used for other tasks can be applied in LLM.
data maintenance. ChatGPT/GPT-4, as a commercial product, is not only trained once, but also continuously updated and maintained. Obviously, we have no way of knowing how data maintenance is done outside of OpenAI. Therefore, we discuss some general data-centric AI strategies that have been or will likely be used for GPT models:
- Continuous data collection: When we use ChatGPT/GPT-4 Our tips/feedback may in turn be used by OpenAI to further advance their models. Quality metrics and assurance strategies may have been designed and implemented to collect high-quality data during the process.
- Data Understanding Tools: Various tools can be developed to visualize and understand user data, promoting a better understanding of user needs and guiding the direction of future improvements.
- Efficient data processing: With the rapid growth of the number of ChatGPT/GPT-4 users, an efficient data management system is needed to achieve rapid data collection.

The picture above is an example of ChatGPT/GPT-4 collecting user feedback through "likes" and "dislikes".
What the data science community can learn from this wave of LLM
The success of LLM has revolutionized artificial intelligence. Going forward, LLM can further revolutionize the data science lifecycle. We make two predictions:
- Data-centric artificial intelligence becomes more important. After years of research, model design has become very mature, especially after Transformer. Data becomes a key way to improve AI systems in the future. Also, when the model becomes powerful enough, we don't need to train the model in our daily work. Instead, we only need to design appropriate inference data to explore knowledge from the model. Therefore, research and development of data-centric AI will drive future progress.
- LLM will enable better data-centric artificial intelligence solutions
Many tedious data science tasks can be more effective with the help of LLM carried out. For example, ChaGPT/GPT-4 already makes it possible to write working code to process and clean data. Additionally, LLM can even be used to create training data. For example, using LLM to generate synthetic data can improve model performance in text mining.

The above is the detailed content of Talk about the data-centric AI behind the GPT model. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology