
Home >Technology peripherals >AI >AI interview robot back-end architecture practice
AI interview robot back-end architecture practice

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-04-08 17:21:041809browse
01 Introduction
The AI interview robot uses the human-machine voice dialogue capabilities of the Lingxi Intelligent Speech Semantic Platform to simulate multiple rounds of voice communication between recruiters and job seekers to achieve the effect of online interviews. This article describes in detail the back-end architecture composition, dialogue engine design, resource demand estimation strategy, and service performance optimization methods of the AI interview robot. The AI interview robot has been online for more than a year and has received millions of interview requests, greatly improving the recruitment efficiency of recruiters and the interview experience of job seekers.
02 Project Background
58 City Life Service Platform includes four established businesses: real estate, automobiles, recruitment, and local services (yellow pages). The platform connects a large number of C-end users and B-end merchants. B-side merchants can publish various types of information (we call them "posts") such as houses, cars, jobs, and life services on the platform. The platform distributes these posts to C-side users for them to browse, thereby helping them obtain what they want. The required information helps B-side merchants distribute and disseminate information to acquire target customers. In order to improve the efficiency of B-side merchants in acquiring target customers and enhance the C-side user experience, the platform continues to carry out product innovation in aspects such as personalized recommendations and intelligent connections. .
Take recruitment as an example. Affected by the epidemic in 2020, the traditional offline recruitment and interview methods have been greatly impacted. The number of online interview requests from job seekers on the platform through WeChat, video, etc. has increased sharply. Since one recruiter can only establish an online video interview channel with one job seeker at the same time, the success rate of the link between the job seeker and the recruiter is low. In order to improve the user experience for job seekers and improve interview efficiency for recruiters, 58.com TEG AI Lab collaborated with multiple departments such as the recruitment business line to create an intelligent recruitment interview tool: the Magic Interview Room. The product mainly consists of three parts: client, audio and video communication, and AI interview robot (see: People | Li Zhong: AI interview robot creates intelligent recruitment).
This article will mainly focus on the AI interview robot. The AI interview robot simulates multiple rounds of voice communication between recruiters and job seekers by using the human-machine voice dialogue capabilities of the Lingxi Intelligent Speech Semantic Platform to achieve the goal of online interviews. Effect. On the one hand, it can solve the problem that one recruiter can only respond to one job seeker's online interview request, improving the job efficiency of the recruiter; on the other hand, it can allow job seekers to conduct video interviews regardless of time and location, and at the same time, it can change personal resumes from traditional ones. The text description introduction is converted into a more intuitive and vivid video self-presentation. This article describes in detail the back-end architecture of the AI interview robot, the design of the human-machine voice dialogue engine, how to estimate resource requirements to cope with traffic expansion, and how to optimize service performance to ensure the stability and availability of the overall AI interview robot service.
03 AI interview robot backend architecture
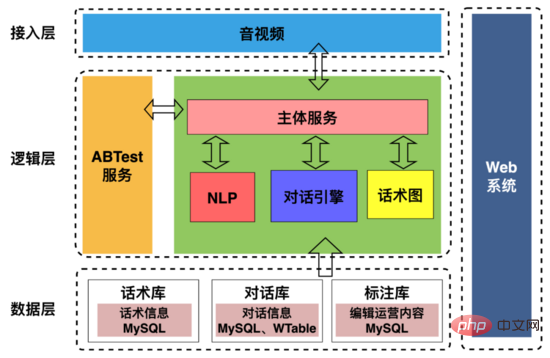
The AI interview robot architecture is shown in the figure above, including:
1. Access layer : Mainly used to handle interactions with upstream and downstream, including agreeing on communication protocols with audio and video terminals; extracting user portraits during interviews and extracting robot user interaction timeline information and sending them to the recruitment department.
2. Logic layer: Mainly used to handle the dialogue interaction between the robot and the user, including synthesizing the robot's question text into voice data and sending it to the user, asking the user questions, so that the robot can "speak" ; After the user replies, the user's reply voice data is segmented through VAD (Voice Activity Detection), and streaming speech recognition is converted into text, so that the robot can "hear" it; the dialogue engine determines the reply content based on the user's reply text and conversational diagram and then synthesizes it. The voice is sent to the user, thereby realizing "communication" between the robot and the user.
3. Data layer: stores basic data such as speech diagrams, dialogue records, and annotation information.
4. Web system: Visually configure discourse structure, dialogue strategies, and annotate interview dialogue data.
04 The overall process of interaction between the AI interview robot and the user
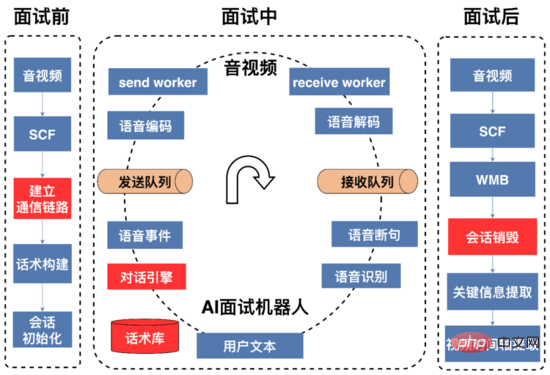
A complete AI interview process is as shown in the figure above, which can be divided into pre-interview and during-interview , three stages after the interview.
Before the interview: The main task is to establish communication links and initialize resources. The voice signals between the AI interview robot and the audio and video terminals are transmitted through UDP. The IP and ports required for audio and video communication with the AI interview robot need to be dynamically maintained. The audio and video end initiates an interview request through the SCF (SCF is an RPC framework independently developed by 58) interface. On the one hand, the request dynamically obtains IP and port resources from the AI interview robot in real time for subsequent audio and video collection of the interview process. The voice signal is sent to the AI robot. On the other hand, the AI robot is told the IP and port that need to be sent in response to the user's voice signal. Since SCF supports load balancing, the interview request initiated by the audio and video end will be randomly hit to the AI interview robot service. On a certain machine in the cluster, the AI interview robot on this machine obtains the IP and port of the audio and video terminal through SCF transparent transmission parameters. Next, the AI interview robot service first tries to select from the available port queue (created during service initialization). This queue uses the data structure of the queue to store available port pairs) and polls the first available port pair (a pair consisting of a sending port and a receiving port). If the acquisition is successful, the service will pass the IP and port of this machine through the SCF interview. The request interface is returned to the audio and video end, and the two parties can then conduct UDP communication. After the interview is completed, the service will push the port pair to the available port queue. If obtaining the port pair fails, the service will return a communication failure code to the audio and video terminal through the SCF interface. The audio and video terminal can retry or give up the interview request.
Establish communication process:
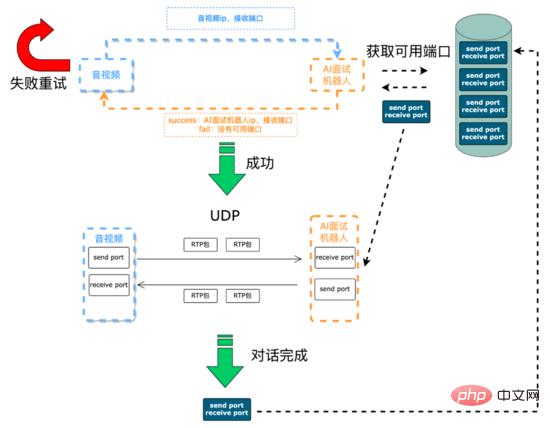
In the voice signal transmission process, we use the RTP protocol as the audio media protocol in the system. RTP protocol, Real-time Transport Protocol, provides end-to-end real-time transmission services for various multimedia data such as voice, image, fax, etc. that need to be transmitted in real time over IP. RTP messages consist of two parts: header and payload.
RTP header:
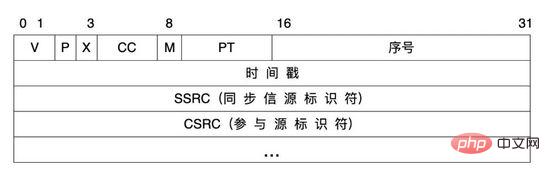
Attribute explanation:
Attribute |
Explanation |
|
| ##V | The version number of the RTP protocol version, which occupies 2 digits. The current protocol version number is 2 | |
| P | Padding flag, occupying 1 bit, if P=1, then the tail of the message is filled with one or more additional 8-bit arrays, which are not part of the payload | |
| X | Extension flag, occupies 1 bit, if |
|
| M | ||
| PT | ||
| The sequence number | ||
| Time stamp | ||
| SSRC | ||
| CSRC | Each CSRC identifier occupies 32 bits and can have 0 to 15. Each CSRC identifies all privileged sources contained in the RTP message payload. |
During the interview: During this process, the AI interview robot first sends an opening statement. The text of the opening statement is synthesized into voice data through tts (Text To Speech). The voice data is encoded, compressed, and sent to the agreed IP and video terminal. port, users make relevant replies based on the questions they hear; the AI interview robot decodes the received user voice stream and converts it into text through vad segmentation and streaming speech recognition. The dialogue engine determines the reply based on the user's reply text and the speech structure state diagram. Content, the AI interview robot continues to interact with the user until the conversation ends or the user hangs up the interview.
After the interview: Once the AI interview robot receives the audio and video request for the end of the interview, the AI interview robot will recycle the resources applied for in the interview preparation stage such as ports, threads, etc.; build a portrait of the user (involving the user’s fastest Information such as arrival time, whether you have worked in the job, age, etc.) are provided to the recruiter to facilitate the merchants to screen and record and store the interview conversation.
Recording plan:
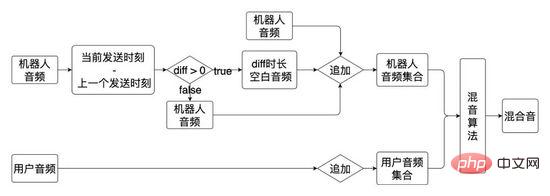
05 Core function of dialogue engine
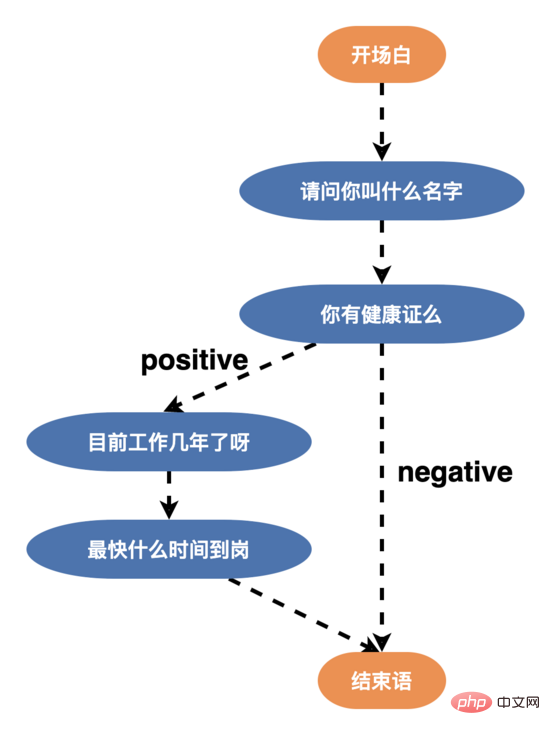
In the entire interview process, the interaction between the AI interview robot and the user is driven by the dialogue engine Driven by the Hua Shu process, Hua Shu is a directed acyclic graph. The initial Hua Shu graph is a two-branch Hua Shu (edges of all nodes
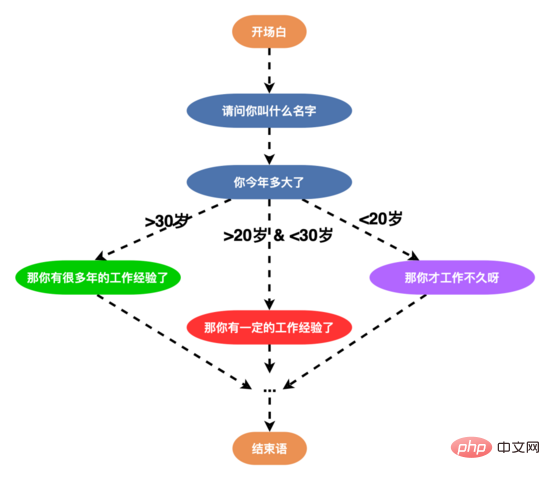
Therefore, in order to improve users’ willingness to talk and enhance the robot’s intelligent dialogue capabilities, we reconstructed the speech structure and designed a multi-branch speech (edge of a node >= 3), as shown below, users can respond to users with different words according to their age, education, and personality. After the new word structure was launched, the interview completion rate exceeded 50%.
At the same time, in order to design the dialogue strategy in a more fine-grained manner, we have designed a node-level strategy chain on the strategy chain, which can customize a personalized dialogue strategy for a single node to meet the needs of Personalized conversation needs.
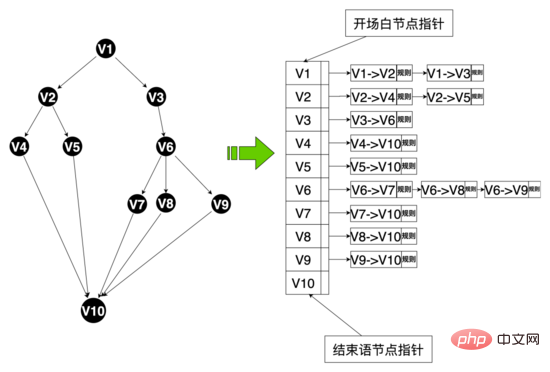
Data level: In order to realize multi-branch speech skills, we redesigned the data structure related to speech skills and abstracted some data entities including: speech skills table, speech skills nodes , talking skills and so on. Hua Shu nodes are bound to Hua Shu through Hua Shu numbers, and at the same time maintain Hua Shu text and other attributes. Hua Shu edges maintain the topological relationship between nodes, including start nodes and end nodes. Hua Shu edges are bound to this through edge numbers. The edge hit regularity, corpus and other rules, and you can use the edge ID to customize your own rules for this edge. The policy chain binds different policies through the policy chain number, and the words and nodes bind different policy chains through the policy chain number.
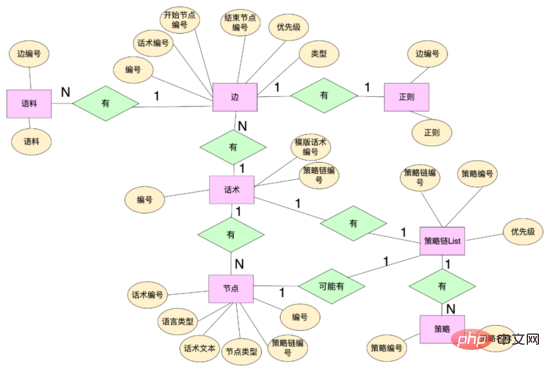
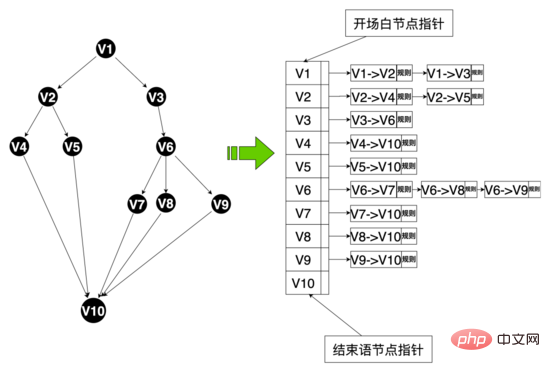
Code level: Abstract the concepts of edges, nodes, speech classes, and speech state classes. Edges and nodes are mappings of the data layer, and regular, The corpus and other hit logic, the speech class maintains key information such as the opening node, the speech graph, etc. The speech graph is the mapping of the entire speech topology, and maintains the mapping between the node and the node edge set starting from the node, the speech state The class maintains the current status of the Hua Shu, including the Hua Shu class and the current node. The system can obtain all the edges starting from the node from the Hua Shu graph based on the current node of the Hua Shu (similar to the adjacency list). According to the user's current The reply matches the rules on different edges. If there is a hit, the speech graph will flow to the end node of the hit edge. At the same time, the robot's reply content will be obtained from this node, and the speech structure will flow.
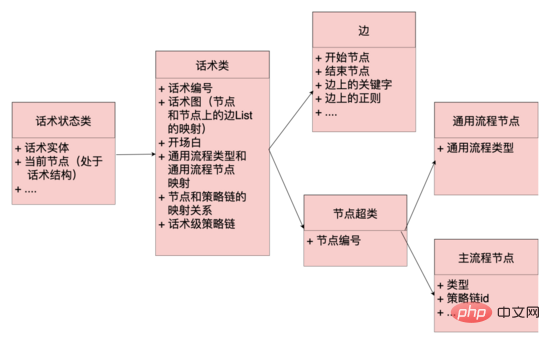
Data structure of speech diagram:
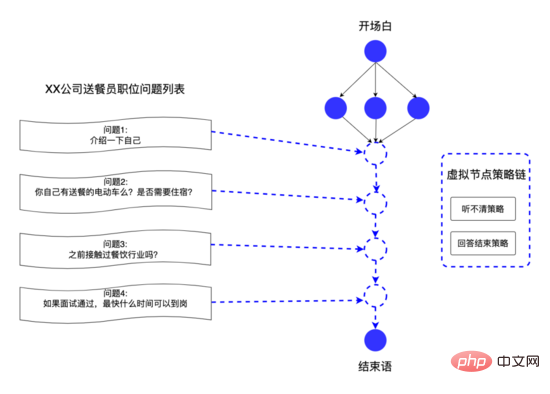
Through the above data structure, the system platform can quickly respond to the business side’s customization needs for speech. For example, the recruiter can customize the questions for each recruitment position. We abstract these questions into virtual nodes in the speech, and use virtual edges to Virtual nodes are connected to provide personalized interview questions for different positions, achieving the effect of thousands of people.
06 Service Performance Optimization Practice
The magical interview room has achieved good results after it went online. Therefore, the business side hopes to expand quickly, and the AI interview robot needs to support the highest simultaneous There are more than a thousand people online, so we started from four aspects: resource management, resource estimation, performance testing, and monitoring to effectively improve the performance of the AI interview robot service. In actual online use, the optimized service can handle interview requests at the same time. 20 times before optimization.
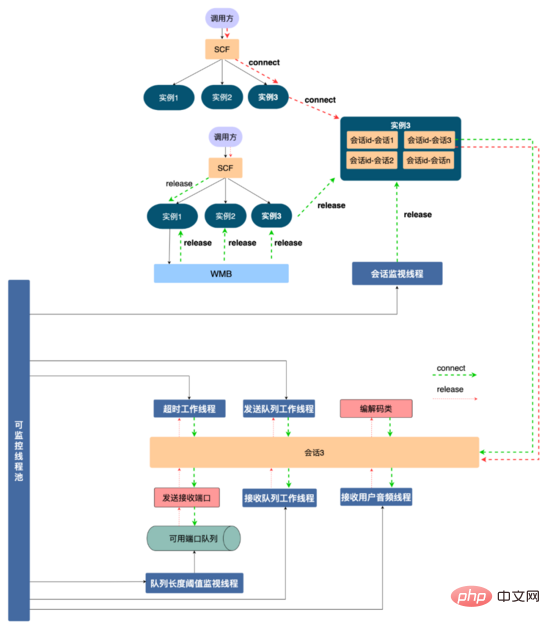
Resource management solution: In order to better manage the resources used in the service and prevent resource exhaustion, we have designed the following The resource management scheme shown. First of all, the AI interview robot and audio and video agree on a communication protocol through SCF. Since SCF is load-balanced, the caller's request will be randomly hit to a certain machine in the cluster. For example, a certain request hits service instance 1. The communication protocol can The interaction of this interview is bound to the instance. Next, the concept of a session is abstracted (the code level is a session class, and each session is a thread). The resources applied for in this interview, such as sending and receiving ports, programming The decoding class and various thread resources are registered to the session, and the code ensures that the resources registered on the session will be released when the session is released. In this way, different video interviews realize resource isolation through thread isolation, thus facilitating resource management.
At the same time, the session instance is bound to the session container through the session id (agreed by the caller through the communication protocol, which is globally unique). When the user hangs up, SCF is called to release resources. Due to the randomness of SCF, the request may hit service instance 3. There is no such interview session on instance 3. In order to release resources, we use WMB (Wuba Tongcheng self-developed message queue) ) Broadcast this resource release message, the message body contains the session id, all service instances will consume this message, service instance 1 contains the session id, find the session bound to the session id, call the resource release function of the session, will use The resource is released (remaining instances will discard the message).
If the release request is not executed for some reason, the session container has a session monitoring thread that can scan the life cycle of all sessions in the session container and set a maximum life cycle for the session (such as 10 minutes). If the session expires, actively trigger session resource recycling and release session resources. At the same time, for the limited resources such as threads and ports applied for in the session, we use centralized management, use the thread pool to centrally manage threads, put all available ports into a queue, and monitor the remaining ports in the queue to ensure the stability of the service. and availability.
Machine resource estimate:
| ## Restricted resources | Bottleneck concerns |
| Temporary resources requested by the session | Whether temporary resources can be recycled in time, such as ports, threads, codecs and other resources. |
Machine network bandwidth |
1000MB/s >> 2500 * 32 KB/s |
Machine hard disk resources |
Merchant custom issues LRU elimination strategy |
Threads |
Indicators such as task size, task execution time, and number of threads created in the thread pool queue |
Performance experiment:
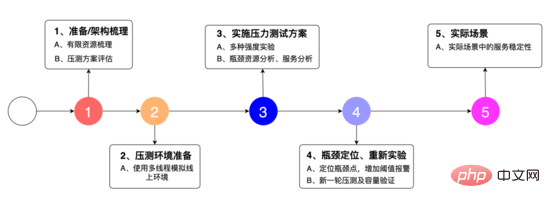
We designed the experimental plan as shown in the figure above: 1. To sort out the system architecture, discover the limited resources, and organize The stress testing plan, 2. uses multi-threading to simulate the online environment, 3. is a strength test of various strengths, analysis of bottleneck resources, and analysis of services. 4. Locate bottleneck points, add threshold alarms, and retest. 5. The stability of the service in actual scenarios.
Stress test: Next, we conducted a stress test and tried various strength request volume tests. When using 2500 requests/min to stress test the interface, we found that the main bottleneck of the service is the heap memory of the service. As you can see from the picture below, the heap memory of the service quickly reaches 100% and the interface becomes unresponsive. After we dumped the heap memory, we found that there were hundreds of DialingInfo objects in the heap memory. Each object occupied 18.75MB. Looking at the code, we can see that this object is used to store the conversation content between the AI interview robot and the user. The two objects allRobotVoiceBuffer and allUserVoiceBuffer each occupy half of it. The memory size, allRobotVoiceBuffer is used to store the robot's voice information (storage format: byte array), and allUserVoiceBuffer is used to store the user's voice information.
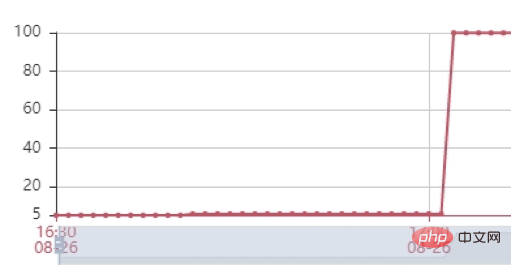
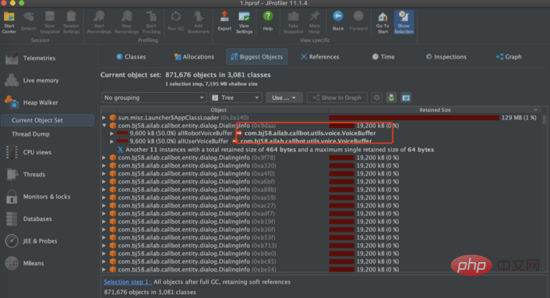
Looking at the code, you can find that the two objects allRobotVoiceBuffer and allUserVoiceBuffer jointly occupy 18.75MB when initializing the service (this value is because To store 5 minutes of audio data), we need to consider whether this initialization size is reasonable. Analyzing the historical call data of the Magic Interview Room, it can be seen that 63% of users did not answer the first question of the robot and directly hung up the interview, so we tried to reduce these two Initialize the memory size of an object, modify allRobotVoiceBuffer to 0.47MB (this value is the size of the robot's first question audio), and allUserVoiceBuffer to 0MB. At the same time, since the two objects allRobotVoiceBuffer and allUserVoiceBuffer can expand at the ms level, if the conversation content exceeds the object size Capacity expansion can be achieved without affecting the service. After the modification, we still use 2500min/request for stress testing, and the service can achieve stable garbage collection.
Fine-grained monitoring:
| ## Indicator Type | Overview |
| Service Key Indicator | Request Volume, success volume, failure volume, no available port, etc. 13 indicators |
| Available ports Queue length is less than the threshold, cache personalization issues exceed the threshold, etc. 5 indicators | |
Process indicators |
52 indicators including failure to construct words, failure to deliver key information, failure to deliver timeline, etc. |
Thread pool monitoring indicators |
The number of threads requested to be created, the number of tasks being executed, and the average task time 6 Indicators |
Position question and answer session indicators |
Abnormalities in obtaining voice answers, average answer warm-up time, etc. 9 Indicators |
ASR Indicators |
18 indicators including average duration of self-developed speech recognition, failure of self-developed recognition, etc. |
Vad indicators |
4 indicators such as number of calls and maximum time consumption |
07 Summary
This article mainly introduces the back-end architecture of the AI interview robot, the entire interaction process between the AI interview robot and the user, and the dialogue engine core functions and service performance optimization practices. In the future, we will continue to support the function iteration and performance optimization of the Magic Interview Room project, and further implement the AI interview robot into different businesses.
References
1. RTP: A Transport Protocol for Real-Time Applications. H. Schulzrinne R. Frederick S. Casner V. Jacobson
About the author
Zhang Chi, 58.com AI Lab back-end senior development engineer, joined 58.com in December 2019. Currently, he is mainly engaged in back-end R&D work related to voice interaction. Graduated from North China University of Technology with a master's degree in 2016. He has worked at Bianlifeng and China Electronics, engaged in back-end development.
The above is the detailed content of AI interview robot back-end architecture practice. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology