
Home >Technology peripherals >It Industry >Retrieval-augmented Generation: Revolution or Overpromise?
Retrieval-augmented Generation: Revolution or Overpromise?

- Joseph Gordon-LevittOriginal
- 2025-02-08 11:56:11303browse
This article explores the promises and realities of Retrieval-Augmented Generation (RAG) in AI. We'll examine RAG's functionality, potential advantages, and real-world challenges encountered during implementation, along with the solutions developed and remaining questions. This provides a comprehensive understanding of RAG's capabilities and its evolving role in AI.
Traditional generative AI often suffers from relying on outdated information and "hallucinating" facts. RAG addresses this by providing the AI with real-time data access, improving accuracy and relevance. However, it's not a universal solution and requires adaptation based on the specific application.

How RAG Works:
RAG enhances generative models by incorporating external, current information during response generation. The process involves:
- Query Initiation: The user asks a question.
- Encoding for Retrieval: The query is converted into text embeddings (digital representations).
- Relevant Data Retrieval: Semantic search uses the embeddings to find relevant data from a dataset, focusing on intent, not just keywords.
- Answer Generation: The RAG system combines the AI's knowledge with the retrieved data to create a contextually relevant response.
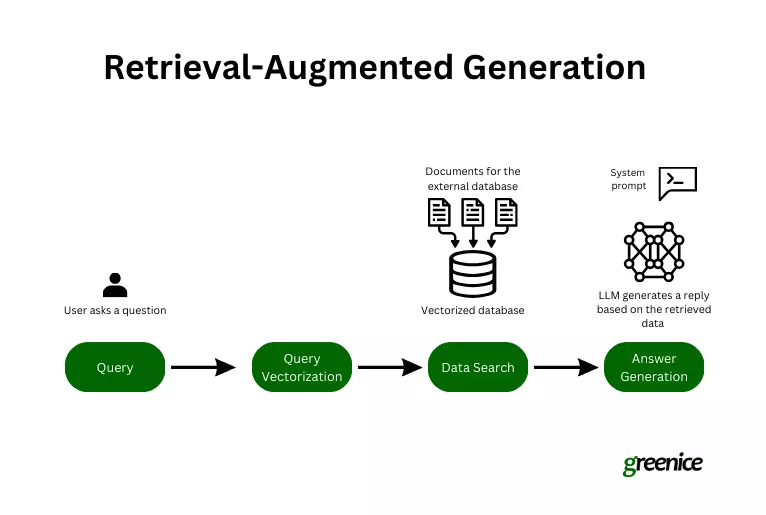
Image source
RAG Development:
Building a RAG system involves:
- Data Collection: Gathering relevant external data (textbooks, manuals, etc.).
- Data Chunking and Formatting: Breaking down large datasets into smaller, manageable pieces.
- Data Embedding: Converting data chunks into numerical vectors for efficient analysis.
- Data Search Development: Implementing semantic search to understand query intent.
- Prompt Preparation: Crafting prompts to guide the LLM's use of retrieved data.
This process, however, often requires adjustments to overcome project-specific challenges.
RAG's Promises:
RAG aims to simplify information retrieval by providing more accurate and relevant responses, improving user experience. It also allows businesses to leverage their data for better decision-making. Key benefits include:
- Accuracy Boost: Reducing false information, outdated responses, and reliance on unreliable sources.
- Conversational Search: Enabling natural, human-like interactions to find information.
Real-World Challenges:
While promising, RAG isn't a perfect solution. Our experiences highlight several challenges:
- Accuracy Isn't Guaranteed: The AI might misinterpret or misapply retrieved information.
- Nuances of Conversational Search: Handling incomplete or context-switching queries is difficult.
- Database Navigation: Efficiently searching through large databases is crucial.
- Hallucinations: The AI might invent information when data is unavailable.
- Finding the "Right" Approach: A single RAG approach may not work across different projects and datasets.
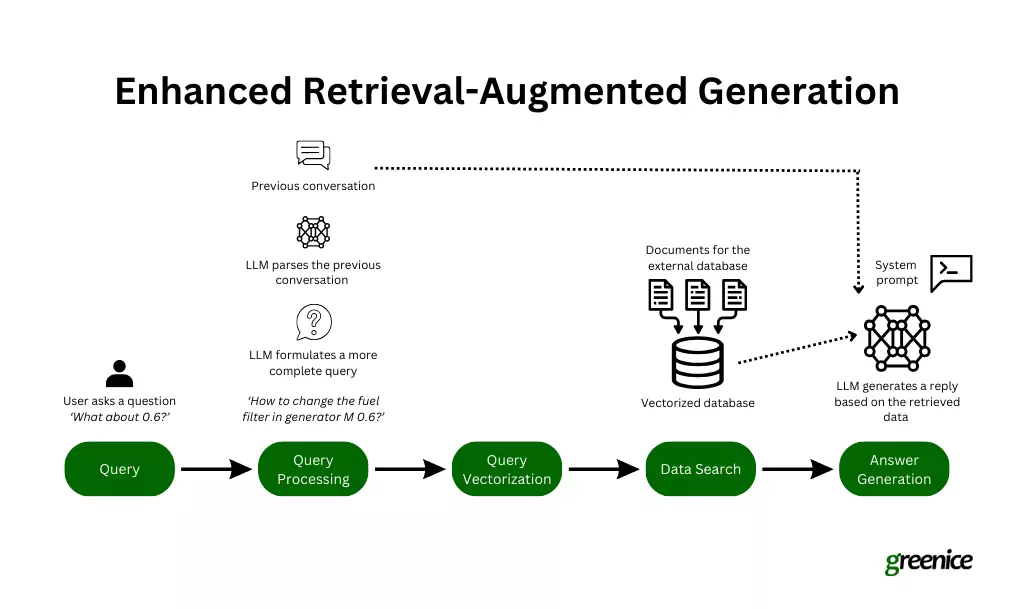
Key Takeaways and the Future of RAG:
Key takeaways include the need for adaptability, continuous improvement, and effective data management. The future of RAG likely involves:
- Enhanced Contextual Understanding: Improved NLP to better handle conversational nuances.
- Broader Implementation: Wider adoption across various industries.
- Innovative Solutions to Existing Challenges: Addressing issues like hallucinations.
In conclusion, RAG offers significant potential but requires ongoing development and adaptation to fully realize its benefits.
The above is the detailed content of Retrieval-augmented Generation: Revolution or Overpromise?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Meng Wanzhou talks about taking office as rotating chairman: Huawei is a collective leadership, not an individual succession
- Hydrogen production and separator development trends under the global hydrogen energy arms race
- Counterpoint Research: 2022 is a milestone year for the global eSIM ecosystem, with more than 260 operators supporting eSIM
- Google sued by publishers in UK for £3.4 billion
- Making mobile phones like making cars: Meizu has changed! Finally taking off?