
 Technology peripheralsAIThe first open source model to surpass GPT4o level! Llama 3.1 leaked: 405 billion parameters, download links and model cards are available
Technology peripheralsAIThe first open source model to surpass GPT4o level! Llama 3.1 leaked: 405 billion parameters, download links and model cards are availableThe first open source model to surpass GPT4o level! Llama 3.1 leaked: 405 billion parameters, download links and model cards are available

Get your GPU ready!

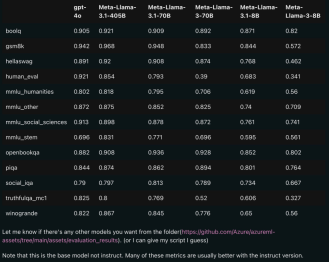
Some netizens said that this is the first time that an open source model has surpassed closed source models such as GPT4o and Claude Sonnet 3.5 and reached SOTA
Someone summarized the following highlights: 
Fine-tuning data includes public Available instruction fine-tuning dataset (unlike Llama 3) and 15 million synthetic samples;
Model supports multiple languages, including English, French, German, Hindi, Italian, Portuguese, Spanish and Thai.
Although the leaked Github link is currently 404, some netizens have given download links ( However, for the sake of safety, it is recommended to wait for the official channel announcement tonight): 
The following is the Llama 3.1 model Important content in the card:


Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish and Thai.
Llama 3.1 series model is 128k


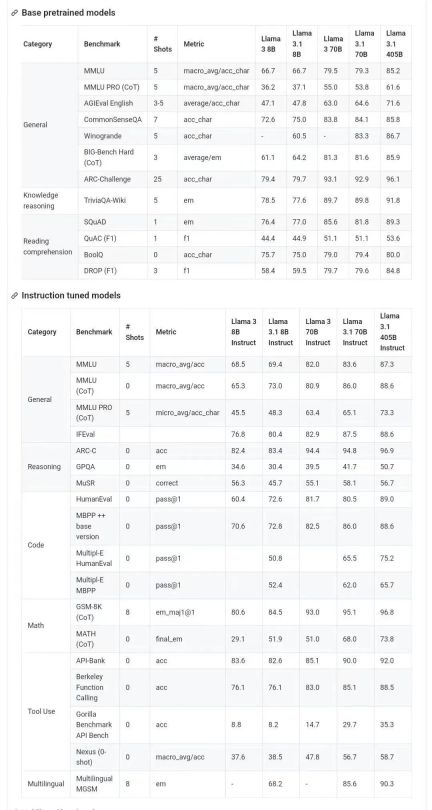
The above is the detailed content of The first open source model to surpass GPT4o level! Llama 3.1 leaked: 405 billion parameters, download links and model cards are available. For more information, please follow other related articles on the PHP Chinese website!

 The Prompt: Cursor's Customer Support Bot Made Up A PolicyApr 23, 2025 am 11:11 AM
The Prompt: Cursor's Customer Support Bot Made Up A PolicyApr 23, 2025 am 11:11 AMAI coding software is all the rage. One particularly popular tool is Cursor, built by nascent AI startup Anysphere, which has become one of the fastest growing startups of all time. But even Cursor isn’t immune to hallucinations— AI’s tendency to mak
 How NVIDIA Isaac GR00T N1 Is Redefining Humanoid Robotics?Apr 23, 2025 am 11:07 AM
How NVIDIA Isaac GR00T N1 Is Redefining Humanoid Robotics?Apr 23, 2025 am 11:07 AMNVIDIA Isaac GR00T N1: Leading the Innovation of Humanoid Robot Technology NVIDIA's Isaac GR00T N1 has achieved a leap forward in the field of humanoid robots, perfectly combining cutting-edge AI technology with open source accessibility. As the world's first open basic model for universal humanoid robot inference, the technology enables robots to understand language instructions, process visual data, and perform complex operational tasks in various environments. Table of contents Detailed explanation of the technical architecture Complete Installation Guide Comprehensive workflow implementation Breakthrough synthetic data generation Deployment and performance metrics Enterprise-level development tools Beginner Resources Summarize Detailed explanation of the technical architecture Dual system cognitive framework System 1 (Quick Thinking):
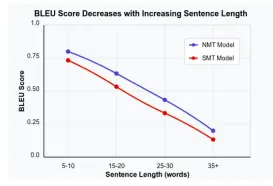 Evaluating Language Models with BLEU MetricApr 23, 2025 am 11:05 AM
Evaluating Language Models with BLEU MetricApr 23, 2025 am 11:05 AMEvaluating Language Models: A Deep Dive into the BLEU Metric and Beyond In the field of artificial intelligence, assessing the performance of language models presents a unique challenge. Unlike tasks like image recognition or numerical prediction, ev
 Exploring Microsoft's AutoGen Framework for Agentic WorkflowApr 23, 2025 am 10:59 AM
Exploring Microsoft's AutoGen Framework for Agentic WorkflowApr 23, 2025 am 10:59 AMGenerative AI's rapid advancement necessitates a shift from human-driven prompting to autonomous task execution. This is where agentic workflows and AI agents come in—agents act as the "limbs" to the model's "brain," enabling ind
 Build an Audio RAG with AssemblyAI, Qdrant & DeepSeek-R1Apr 23, 2025 am 10:48 AM
Build an Audio RAG with AssemblyAI, Qdrant & DeepSeek-R1Apr 23, 2025 am 10:48 AMThis guide demonstrates building an AI-powered chatbot that transforms audio recordings (meetings, podcasts, interviews) into interactive conversations. It leverages AssemblyAI for transcription, Qdrant for efficient data storage, and DeepSeek-R1 vi
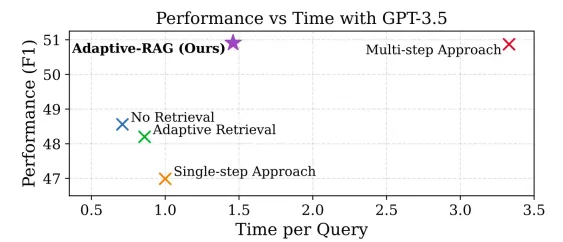 Guide to Adaptive RAG Systems with LangGraphApr 23, 2025 am 10:45 AM
Guide to Adaptive RAG Systems with LangGraphApr 23, 2025 am 10:45 AMAdaptive RAG: A Smarter Approach to Question Answering Large language models (LLMs) excel at answering questions based on their training data, but this fixed knowledge base limits their ability to provide current or highly specific information. Retri
 Top 5 RAG Frameworks for AI ApplicationsApr 23, 2025 am 10:39 AM
Top 5 RAG Frameworks for AI ApplicationsApr 23, 2025 am 10:39 AMRAG has become a popular technology in 2025, it avoids the fine-tuning of the model which is expensive as well as time-consuming. There’s an increased demand for RAG frameworks in the current scenario, Lets Understand what are th
 Role of Fully Convolutional Networks in Semantic SegmentationApr 23, 2025 am 10:37 AM
Role of Fully Convolutional Networks in Semantic SegmentationApr 23, 2025 am 10:37 AMFully Convolutional Networks (FCNs): A Deep Dive into Semantic Segmentation Semantic segmentation, the pixel-wise classification of images, is a cornerstone of computer vision. In 2015, a groundbreaking paper by Jonathan Long, Evan Shelhamer, and Tr


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 English version
Recommended: Win version, supports code prompts!

