



RAG has become a popular technology in 2025, it avoids the fine-tuning of the model which is expensive as well as time-consuming. There’s an increased demand for RAG frameworks in the current scenario, Lets Understand what are these. Retrieval-augmented generation (RAG) frameworks are essential tools in the field of artificial intelligence. They enhance the capabilities of Large Language Models (LLMs) by allowing them to retrieve relevant information from external sources. This leads to more accurate and context-aware responses. Here, we will explore five notable RAG frameworks: LangChain, LlamaIndex, LangGraph, Haystack, and RAGFlow. Each framework offers unique features that can improve your AI projects.
Table of contents
- LangChain
- LlamaIndex
- LangGraph
- Haystack
- RAGFlow
- Conclusion
1. LangChain
LangChain is a flexible framework that simplifies the development of applications using LLMs. It provides tools for building RAG applications, making integration straightforward.
-
Key Features:
- Modular design for easy customization.
- Supports various LLMs and data sources.
- Built-in tools for document retrieval and processing.
- Suitable for chatbots and virtual assistants.
Here’s the hands-on:
Install the following libraries
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
Set up OpenAI API key and os environment
from getpass import getpass
openai = getpass("OpenAI API Key:")
import os
os.environ["OPENAI_API_KEY"] = openai
Import the following dependencies
import bs4 from langchain import hub from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chroma from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAI, OpenAIEmbeddings
Loading the document for RAG using WebBase Loader (replace with your own Data)
# Load Documents
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
Chunking the document using RecursiveCharacterTextSplitter
# Split text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) splits = text_splitter.split_documents(docs)
Storing the vector documents in ChromaDB
# Embed vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever()
Pulling the RAG prompt from the LangChain hub and defining LLM
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
Processing the retrieved docs
# Post-processing def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)
Creating the RAG chain
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
Invoking the chain with the question
# Question
rag_chain.invoke("What is Task Decomposition?")
Output
‘Task Decomposition is a technique used to break down complex tasks into<br> smaller and simpler steps. This approach helps agents to plan ahead and<br> tackle difficult tasks more effectively. Task decomposition can be done<br> through various methods, including using prompting techniques, task-specific<br> instructions, or human inputs.’
Also Read: Find everything about LangChain Here.
2. LlamaIndex
LlamaIndex, previously known as the GPT Index, focuses on organizing and retrieving data efficiently for LLM applications. It helps developers access and use large datasets quickly.
-
Key Features:
- Organizes data for fast lookups.
- Customizable components for RAG workflows.
- Supports multiple data formats, including PDFs and SQL.
- Integrates with vector stores like Pinecone and FAISS.
Here’s the hands-on:
Install the following dependencies
!pip install llama-index llama-index-readers-file !pip install llama-index-embeddings-openai !pip install llama-index-llms-openai
Import the following dependencies and initialize the LLM and embeddings
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding llm = OpenAI(model='gpt-4o') embed_model = OpenAIEmbedding() from llama_index.core import Settings Settings.llm = llm Settings.embed_model = embed_model
Download the data (You can replace it with your data)
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/10k/uber_2021.pdf' -O './uber_2021.pdf'
Read the data using SimpleDirectoryReader
from llama_index.core import SimpleDirectoryReader documents = SimpleDirectoryReader(input_files=["/content/uber_2021.pdf"]).load_data()
Chunking the document using TokenTextSplitter
from llama_index.core.node_parser import TokenTextSplitter splitter = TokenTextSplitter( chunk_size=512, chunk_overlap=0, ) nodes = splitter.get_nodes_from_documents(documents)
Storing the vector embeddings in VectorStoreIndex
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex(nodes)
query_engine = index.as_query_engine(similarity_top_k=2)
Invoking the LLM using RAG
response = query_engine.query("What is the revenue of Uber in 2021?")
print(response)
Output
‘The revenue of Uber in 2021 was $171.7 million.
3. LangGraph
LangGraph connects LLMs with graph-based data structures. This framework is useful for applications that require complex data relationships.
-
Key Features:
- Efficiently retrieves data from graph structures.
- Combines LLMs with graph data for better context.
- Allows customization of the retrieval process.
Code
Install the following dependencies
%pip install --quiet --upgrade langchain-text-splitters langchain-community langgraph langchain-openai
Initialise the model, embeddings and Vector database
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
Import the following dependencies
import bs4 from langchain import hub from langchain_community.document_loaders import WebBaseLoader from langchain_core.documents import Document from langchain_text_splitters import RecursiveCharacterTextSplitter from langgraph.graph import START, StateGraph from typing_extensions import List, TypedDict
Download the dataset using WebBaseLoader(replace it with your own dataset)
# Load and chunk contents of the blog
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
Chunking of the document using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) all_splits = text_splitter.split_documents(docs) # Index chunks _ = vector_store.add_documents(documents=all_splits)
Extracting the prompt from the LangChain hub
# Define prompt for question-answering
prompt = hub.pull("rlm/rag-prompt")
Defining the State, Nodes and edges in Langgraph
Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
# Define application steps
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
Compiling the Graph
# Compile application and test graph_builder = StateGraph(State).add_sequence([retrieve, generate]) graph_builder.add_edge(START, "retrieve") graph = graph_builder.compile()
Invoking the LLM for RAG
response = graph.invoke({"question": "What is Task Decomposition?"})
print(response["answer"])
Output
Task Decomposition is the process of breaking down a complicated task into<br> smaller, manageable steps. This can be achieved using techniques like Chain<br> of Thought (CoT) or Tree of Thoughts, which guide models to reason step by<br> step or evaluate multiple possibilities. The goal is to simplify complex<br> tasks and enhance understanding of the reasoning process.
4. Haystack
Haystack is an end-to-end framework for developing applications powered by LLMs and transformer models. It excels in document search and question answering.
-
Key Features:
- Combines document search with LLM capabilities.
- Uses various retrieval methods for optimal results.
- Offers pre-built pipelines for quick development.
- Compatible with Elasticsearch and OpenSearch.
Here’s the hands-on:
Install the following Dependencies
!pip install haystack-ai !pip install "datasets>=2.6.1" !pip install "sentence-transformers>=3.0.0" Import the VectorStore and initialise it from haystack.document_stores.in_memory import InMemoryDocumentStore document_store = InMemoryDocumentStore()
Loading the inbuilt dataset from the dataset library
from datasets import load_dataset
from haystack import Document
dataset = load_dataset("bilgeyucel/seven-wonders", split="train")
docs = [Document(content=doc["content"], meta=doc["meta"]) for doc in dataset]
Downloading the Embedding model (you can replace it with OpenAI embeddings also)
from haystack.components.embedders import SentenceTransformersDocumentEmbedder doc_embedder = SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2") doc_embedder.warm_up() docs_with_embeddings = doc_embedder.run(docs) document_store.write_documents(docs_with_embeddings["documents"])
Storing the embeddings in VectorStore
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever retriever = InMemoryEmbeddingRetriever(document_store)
Defining the prompt for RAG
from haystack.components.builders import ChatPromptBuilder
from haystack.dataclasses import ChatMessage
template = [
ChatMessage.from_user(
"""
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
)
]
prompt_builder = ChatPromptBuilder(template=template)
Initializing the LLM
from haystack.components.generators.chat import OpenAIChatGenerator chat_generator = OpenAIChatGenerator(model="gpt-4o-mini")
Defining the Pipeline nodes
from haystack import Pipeline
basic_rag_pipeline = Pipeline()
# Add components to your pipeline
basic_rag_pipeline.add_component("text_embedder", text_embedder)
basic_rag_pipeline.add_component("retriever", retriever)
basic_rag_pipeline.add_component("prompt_builder", prompt_builder)
basic_rag_pipeline.add_component("llm", chat_generator)
Connecting the nodes to each other
# Now, connect the components to each other
basic_rag_pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
basic_rag_pipeline.connect("retriever", "prompt_builder")
basic_rag_pipeline.connect("prompt_builder.prompt", "llm.messages")
Invoking the LLM using RAG
question = "What does Rhodes Statue look like?"
response = basic_rag_pipeline.run({"text_embedder": {"text": question}, "prompt_builder": {"question": question}})
print(response["llm"]["replies"][0].text)
Output
Batches: 100%<br><br> 1/1 [00:00<br>‘The Colossus of Rhodes, a statue of the Greek sun-god Helios, is believed to<br> have stood approximately 33 meters (108 feet) tall and was constructed with<br> iron tie bars and brass plates forming its skin, filled with stone blocks.<br> Although the specific details of its appearance are not definitively known,<br> contemporary accounts suggest that it had curly hair with bronze or silver<br> spikes radiating like flames on the head. The statue likely depicted Helios<br> in a powerful, commanding pose, possibly with one hand shielding his eyes,<br> similar to other representations of the sun god from the time. Overall, it<br> was designed to project strength and radiance, celebrating Rhodes' victory<br> over its enemies.’
5. RAGFlow
RAGFlow focuses on integrating retrieval and generation processes. It streamlines the development of RAG applications.
-
Key Features:
- Simplifies the connection between retrieval and generation.
- Allows for tailored workflows to meet project needs.
- Integrates easily with various databases and document formats.
Here’s the hands-on:
Sign up at the RAGFlow and then Click on Try RAGFlow

Then Click on Create Knowledge Base

Then Go to Model Providers and select the LLM model that you want to use, We are using Groq here and paste its API key.
Then Go to System Model settings and select the chat model from there.

Now go to datasets and upload the pdf you want, then click on the Play button near the Parsing status column and wait for the pdf to get parsed.

Now go to the chat section create an assistant there, Give it a name and also select the knowledge base that you created.

Then create a new chat and ask the question it will perform RAG over your knowledge base and answer accordingly.

Conclusion
RAG has become an important technology for custom enterprise datasets in recent times, hence the need for RAG frameworks has increased drastically. Frameworks like LangChain, LlamaIndex, LangGraph, Haystack, and RAGFlow represent significant advancements in AI applications. By using these frameworks, developers can create systems that provide accurate and relevant information. As AI continues to evolve, these tools will play an important role in shaping intelligent applications.
The above is the detailed content of Top 5 RAG Frameworks for AI Applications. For more information, please follow other related articles on the PHP Chinese website!

 Gemini 2.5 Pro vs GPT 4.5: Can Google Beat OpenAI's Best?Apr 24, 2025 am 09:39 AM
Gemini 2.5 Pro vs GPT 4.5: Can Google Beat OpenAI's Best?Apr 24, 2025 am 09:39 AMThe AI race is heating up with newer, competing models launched every other day. Amid this rapid innovation, Google Gemini 2.5 Pro challenges OpenAI GPT-4.5, both offering cutting-edge advancements in AI capabilities. In this Gem
 Karun Thanks's bluepring for data science successApr 24, 2025 am 09:38 AM
Karun Thanks's bluepring for data science successApr 24, 2025 am 09:38 AMKarun Thankachan: A Data Science Journey from Software Engineer to Walmart Senior Data Scientist Karun Thankachan, a senior data scientist specializing in recommender systems and information retrieval, shares his career path, insights on scaling syst
 We Tried Gemini 2.5 Pro Experimental and It's Mind-Blowing!Apr 24, 2025 am 09:36 AM
We Tried Gemini 2.5 Pro Experimental and It's Mind-Blowing!Apr 24, 2025 am 09:36 AMGoogle DeepMind's Gemini 2.5 Pro (experimental): A Powerful New AI Model Google DeepMind has released Gemini 2.5 Pro (experimental), a groundbreaking AI model that has quickly ascended to the top of the LMArena Leaderboard. Building on its predecess
 Top 5 Code Editors to Vibe Code in 2025Apr 24, 2025 am 09:31 AM
Top 5 Code Editors to Vibe Code in 2025Apr 24, 2025 am 09:31 AMRevolutionizing Software Development: A Deep Dive into AI Code Editors Tired of endless coding, constant tab-switching, and frustrating troubleshooting? The future of coding is here, and it's powered by AI. AI code editors understand your project f
 5 Jobs AI Can't Replace According to Bill GatesApr 24, 2025 am 09:26 AM
5 Jobs AI Can't Replace According to Bill GatesApr 24, 2025 am 09:26 AMBill Gates recently visited Jimmy Fallon's Tonight Show, talking about his new book "Source Code", his childhood and Microsoft's 50-year journey. But the most striking thing in the conversation is about the future, especially the rise of artificial intelligence and its impact on our work. Gates shared his thoughts in a hopeful yet honest way. He believes that AI will revolutionize the world at an unexpected rate and talks about work that AI cannot replace in the near future. Let's take a look at these tasks together. Table of contents A new era of abundant intelligence Solve global shortages in healthcare and education Will artificial intelligence replace jobs? Gates said: For some jobs, it will Work that artificial intelligence (currently) cannot replace: human touch remains important Conclusion
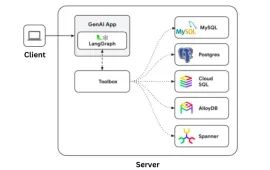 Google Gen AI Toolbox: A Python Library for SQL DatabasesApr 24, 2025 am 09:23 AM
Google Gen AI Toolbox: A Python Library for SQL DatabasesApr 24, 2025 am 09:23 AMGoogle's Gen AI Toolbox for Databases: Revolutionizing Database Interaction with Natural Language Google has unveiled the Gen AI Toolbox for Databases, a revolutionary open-source Python library designed to simplify database interactions using natura
 OpenAI's GPT 4o Image Generation is SUPER COOLApr 24, 2025 am 09:21 AM
OpenAI's GPT 4o Image Generation is SUPER COOLApr 24, 2025 am 09:21 AMOpenAI's ChatGPT Now Boasts Native Image Generation: A Game Changer ChatGPT's latest update has sent ripples through the tech world with the introduction of native image generation, powered by GPT-4o. Sam Altman himself hailed it as "one of the
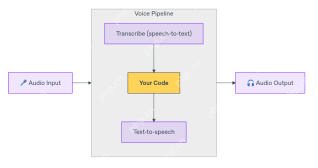 How to Build Multilingual Voice Agent Using OpenAI Agent SDK? - Analytics VidhyaApr 24, 2025 am 09:16 AM
How to Build Multilingual Voice Agent Using OpenAI Agent SDK? - Analytics VidhyaApr 24, 2025 am 09:16 AMOpenAI's Agent SDK now offers a Voice Agent feature, revolutionizing the creation of intelligent, real-time, speech-driven applications. This allows developers to build interactive experiences like language tutors, virtual assistants, and support bo


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Mac version
God-level code editing software (SublimeText3)

