
Heim >Technologie-Peripheriegeräte >KI >Brechen Sie den Fluch vor 36 Jahren! Meta führt eine Reverse-Training-Methode ein, um den „Umkehrfluch' großer Modelle zu beseitigen
Brechen Sie den Fluch vor 36 Jahren! Meta führt eine Reverse-Training-Methode ein, um den „Umkehrfluch' großer Modelle zu beseitigen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-09 15:40:09826Durchsuche
Der „Umkehrfluch“ des großen Sprachmodells wurde gelöst!
Dieser Fluch wurde erstmals im September letzten Jahres entdeckt, was sofort für Aufschrei bei LeCun, Karpathy, Marcus und anderen großen Kerlen sorgte.

Denn das beispiellose und arrogante große Modell hat tatsächlich eine „Achillesferse“: Ein auf „A ist B“ trainiertes Sprachmodell kann nicht richtig mit „Ist B A“ antworten.
Zum Beispiel das folgende Beispiel: LLM weiß eindeutig, dass „Tom Cruises Mutter Mary Lee Pfeiffer ist“, kann aber nicht antworten: „Mary Lee Pfeiffers Kind ist Tom Cruise“.

——Dies war zu dieser Zeit das fortschrittlichste GPT-4. Daher konnten selbst Kinder über normales logisches Denken verfügen, LLM jedoch nicht.
Basierend auf umfangreichen Daten hat er ein Wissen gespeichert, das fast allen Menschen überlegen ist, und verhält sich dennoch so langweilig. Er hat das Feuer der Weisheit erlangt, ist aber für immer in diesem Fluch gefangen.

Papieradresse: https://arxiv.org/pdf/2309.12288v1.pdf
Sobald dieser Vorfall bekannt wurde, war das gesamte Netzwerk in Aufruhr.
Einerseits sagten Internetnutzer, dass das große Modell wirklich dumm sei, wirklich. Da ich nur „A ist B“ wusste, aber nicht wusste, „B ist A“, behielt ich schließlich meine Würde als Mensch.
Andererseits haben auch Forscher begonnen, dies zu untersuchen und arbeiten hart daran, diese große Herausforderung zu lösen.
Kürzlich haben Forscher von Meta FAIR eine Reverse-Training-Methode eingeführt, um den „Umkehrfluch“ von LLM auf einen Schlag zu lösen.
Papieradresse: https://arxiv.org/pdf/2403.13799.pdf
Die Forscher beobachteten zunächst, dass LLMs autoregressiv von links nach rechts trainiert werden – das ist möglich, das ist die Ursache die Umkehrung des Fluches.
Wenn Sie also LLM (Reverse Training) in der Rechts-nach-Links-Richtung trainieren, ist es für das Modell möglich, die Fakten in umgekehrter Richtung zu sehen.
Umgekehrter Text kann als Zweitsprache behandelt werden, indem mehrere verschiedene Quellen durch Multitasking oder sprachübergreifendes Vortraining genutzt werden.
Die Forscher betrachteten 4 Inversionstypen: Token-Inversion, Wortinversion, entitätserhaltende Inversion und zufällige Segmentinversion.
Token- und Wortumkehr, indem die Sequenz in Token bzw. Wörter aufgeteilt und deren Reihenfolge umgekehrt wird, um eine neue Sequenz zu bilden.
Entity Preserving Reverse findet Entitätsnamen in einer Sequenz und behält die Wortreihenfolge von links nach rechts darin bei, während die Wortumkehr durchgeführt wird.
Zufällige Segmentinversion teilt die tokenisierte Sequenz in Blöcke zufälliger Länge auf und behält dann die Reihenfolge von links nach rechts innerhalb jedes Blocks bei.
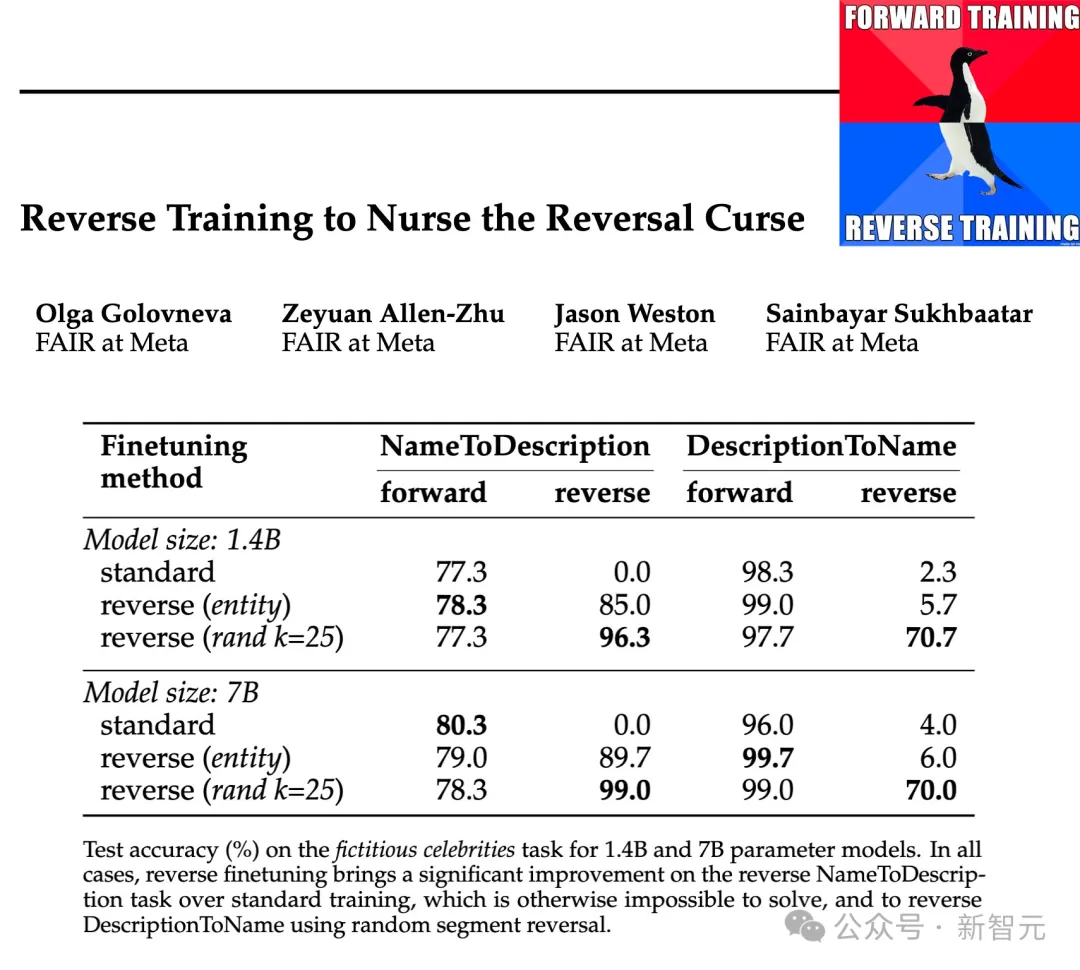
Die Forscher testeten die Wirksamkeit dieser Inversionstypen auf Parameterskalen von 1,4B und 7B, und die Ergebnisse zeigten, dass entitätserhaltendes und randomisiertes stückweises Inversionstraining den Inversionsfluch abschwächen, in manchen Fällen sogar vollständig beseitigen kann.
Darüber hinaus fanden die Forscher auch heraus, dass die Umkehrung vor dem Training die Leistung des Modells im Vergleich zum Standardtraining von links nach rechts verbesserte – sodass das Umkehrtraining als allgemeine Trainingsmethode verwendet werden kann.
Reverse-Trainingsmethode
Reverse-Training umfasst das Erhalten eines Trainingsdatensatzes mit N Stichproben und die Erstellung eines umgekehrten Stichprobensatzes REVERSE (x).
Die Funktion REVERSE ist wie folgt für die Umkehrung einer bestimmten Zeichenfolge verantwortlich:
Wortumkehr: Jedes Beispiel wird zuerst in Wörter aufgeteilt, und dann wird die Zeichenfolge auf Wortebene umgekehrt, wobei Leerzeichen miteinander verbunden werden.
Entitätserhaltende Inversion: Führen Sie einen Entitätsdetektor für ein bestimmtes Trainingsbeispiel aus und teilen Sie dabei auch Nicht-Entitäten in Wörter auf. Dann werden die Wörter, die keine Entitäten sind, umgekehrt, während die Wörter, die Entitäten darstellen, ihre ursprüngliche Wortreihenfolge beibehalten.
Zufällige Segmentumkehr: Anstatt einen Entitätsdetektor zu verwenden, versuchen wir, eine einheitliche Stichprobe zu verwenden, um die Sequenz zufällig in Segmente mit Größen zwischen 1 und k Token aufzuteilen, und kehren diese Segmente dann um, behalten aber die Wortreihenfolge innerhalb von a bei Anschließend werden die Segmente mit dem speziellen Token [REV] verbunden.
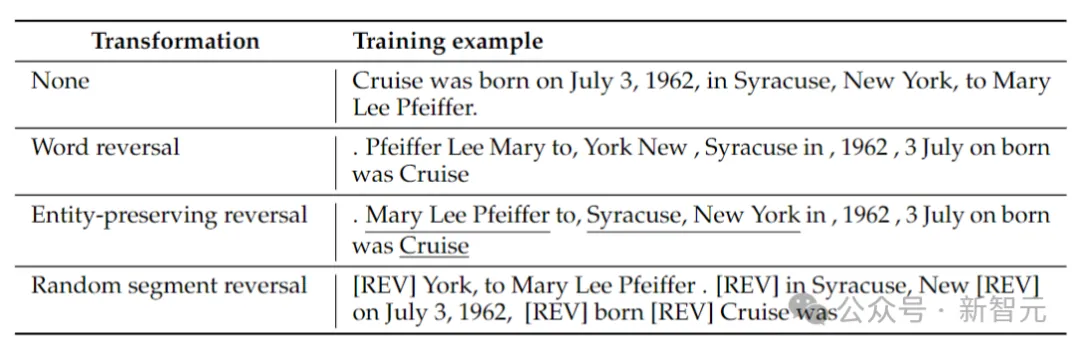
Die obige Tabelle enthält Beispiele für verschiedene Arten der Inversion einer bestimmten Zeichenfolge.
Zu diesem Zeitpunkt wird das Sprachmodell noch von links nach rechts trainiert. Bei der Wortumkehr entspricht dies der Vorhersage von Sätzen von rechts nach links.
Inverses Training umfasst das Training an Standard- und Reverse-Beispielen, sodass die Anzahl der Trainingstokens verdoppelt wird, während sowohl Vorwärts- als auch Reverse-Trainingsbeispiele gemischt werden.
Die Umkehrtransformation kann als zweite Sprache angesehen werden, die das Modell lernen muss. Während der Umkehrung bleibt die Beziehung zwischen den Fakten unverändert und das Modell kann anhand der Grammatik beurteilen, ob es sich um eine Vorwärts- oder Rückwärtssprache handelt Vorhersagemodell.
Eine andere Perspektive des inversen Trainings kann durch die Informationstheorie erklärt werden: Das Ziel der Sprachmodellierung besteht darin, die Wahrscheinlichkeitsverteilung natürlicher Sprache zu lernen
Erstellen Sie zunächst einen einfachen symbolbasierten Datensatz, um den Inversionsfluch in einer kontrollierten Umgebung zu untersuchen.
Paaren Sie die Entitäten a und b zufällig eins zu eins. Die Trainingsdaten enthalten alle (a→b)-Zuordnungspaare, aber nur die Hälfte der (b→a)-Zuordnungen, und die andere Hälfte dient als Testdaten. Das Modell muss die Regel a→b ⇔ b→a aus den Trainingsdaten ableiten und diese dann auf die Paare in den Testdaten verallgemeinern.
Die obige Tabelle zeigt die Testgenauigkeit (%) der Vorzeichenumkehraufgabe. Trotz der Einfachheit der Aufgabe scheitert das Standard-Sprachmodelltraining vollständig, was darauf hindeutet, dass Skalierung allein das Problem wahrscheinlich nicht lösen kann.
Im Gegensatz dazu kann das umgekehrte Training das Problem von zwei Wortentitäten fast lösen, aber seine Leistung lässt schnell nach, wenn die Entitäten länger werden.
Wortumkehr funktioniert gut für kürzere Entitäten, aber für Entitäten mit mehr Wörtern ist eine entitätserhaltende Umkehrung erforderlich. Die zufällige Segmentumkehr funktioniert gut, wenn die maximale Segmentlänge k mindestens so lang wie die Entität ist. 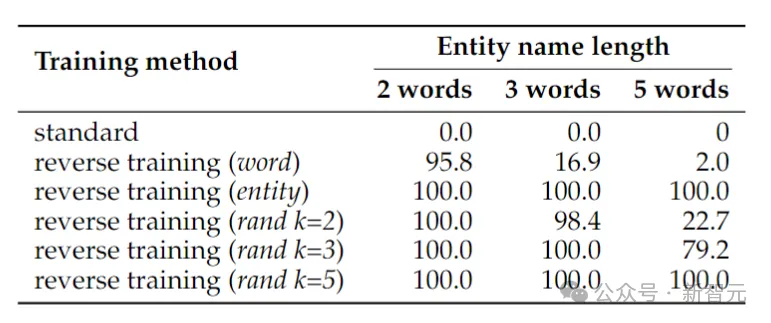
Wiederherstellen der Namen von Personen
Die obige Tabelle zeigt die Umkehraufgabe zur Bestimmung des vollständigen Namens einer Person, wenn zur Bestimmung des Namens einer Person nur das Geburtsdatum angegeben wird Der vollständige Name liegt immer noch nahe bei Null. Dies liegt daran, dass in der in diesem Artikel verwendeten Entitätserkennungsmethode Datumsangaben als drei Entitäten behandelt werden, sodass ihre Reihenfolge bei der Umkehrung nicht erhalten bleibt. Wenn sich die Umkehraufgabe nur auf die Bestimmung des Nachnamens einer Person beschränkt, reicht die Umkehrung auf Wortebene aus.
Ein weiteres Phänomen, das überraschen könnte, ist, dass die Entity-Retention-Methode den vollständigen Namen der Person ermitteln kann, nicht jedoch den Nachnamen der Person. 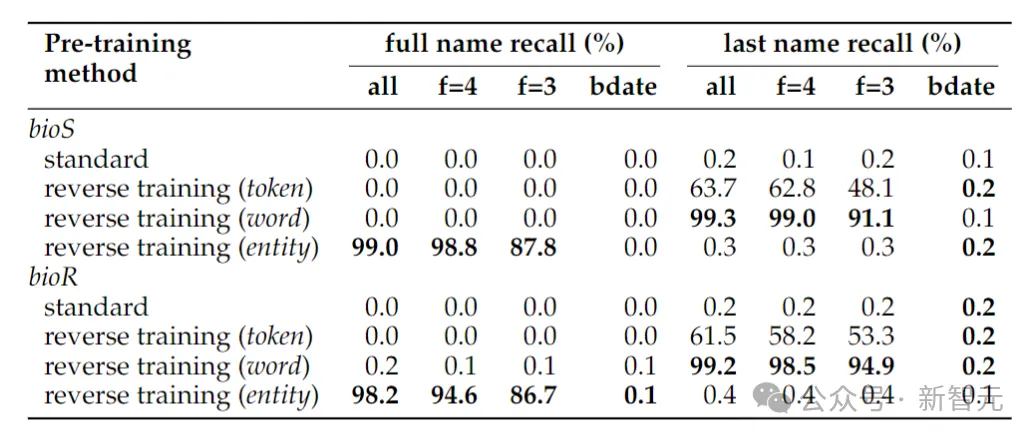
Dies ist ein bekanntes Phänomen: Sprachmodelle sind möglicherweise überhaupt nicht in der Lage, späte Token von Wissensfragmenten (z. B. Nachnamen) abzurufen.
Fakten aus der realen Welt
Hier trainierte der Autor ein Llama-2-Modell mit 1,4 Milliarden Parametern und trainierte ein Basismodell von 2 Billionen Token in der Richtung von links nach rechts.
Im Gegensatz dazu verwendet das inverse Training nur 1 Billion Token, verwendet jedoch dieselbe Datenteilmenge, um in zwei Richtungen zu trainieren, von links nach rechts und von rechts nach links – die beiden Richtungen zusammen ergeben 2 Billionen Token, was Fairness und Gerechtigkeit in Bezug auf die Bedingungen gewährleistet der Rechenressourcen. Um die Umkehrung realer Fakten zu testen, verwendeten die Forscher eine Promi-Aufgabe, die Fragen wie „Wer ist die Mutter einer Berühmtheit?“ sowie anspruchsvollere Umkehrfragen umfasste, zum Beispiel „Wer sind die Kinder einer bestimmten Person?“ Eltern der Berühmtheit?“ Die Ergebnisse sind in der Tabelle oben aufgeführt. Die Forscher untersuchten die Modelle mehrmals für jede Frage und betrachteten es als Erfolg, wenn eines davon die richtige Antwort enthielt. Im Allgemeinen ist die Genauigkeit normalerweise relativ gering, da das Modell hinsichtlich der Anzahl der Parameter klein ist, nur über begrenztes Vortraining verfügt und es an Feinabstimmung mangelt. Das umgekehrte Training schnitt jedoch noch besser ab. 1988 veröffentlichten Fodor und Pylyshyn in der Zeitschrift „Cognition“ einen Artikel über die Systematik des Denkens. Wenn Sie diese Welt wirklich verstehen, sollten Sie in der Lage sein, die Beziehung zwischen a und b und die Beziehung zwischen b und a zu verstehen. Auch nonverbale kognitive Wesen sollten dazu in der Lage sein. 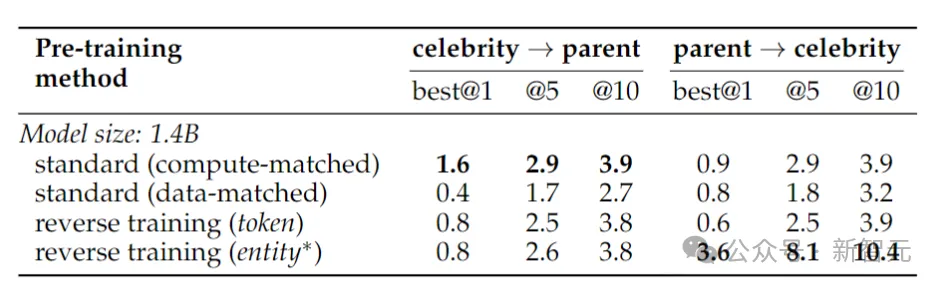
Prophezeiung vor 36 Jahren

Das obige ist der detaillierte Inhalt vonBrechen Sie den Fluch vor 36 Jahren! Meta führt eine Reverse-Training-Methode ein, um den „Umkehrfluch' großer Modelle zu beseitigen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So beantragen Sie eine E-Mail
- Was ist ein KI-Trainingscluster?
- An der Spitze der international anerkannten Liste der semantischen Konversationsanalysen von SParC und CoSQL steht das neue STAR-Interpretationsmodell für mehrstufige Dialogformen vor dem Training
- Die internen Tests von Kimi Chat beginnen, Volcano Engine bietet Beschleunigungslösungen und unterstützt das Training und die Inferenz des Moonshot AI-Großmodelldienstes
- Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.