
Heim >Technologie-Peripheriegeräte >KI >An der Spitze der international anerkannten Liste der semantischen Konversationsanalysen von SParC und CoSQL steht das neue STAR-Interpretationsmodell für mehrstufige Dialogformen vor dem Training
An der Spitze der international anerkannten Liste der semantischen Konversationsanalysen von SParC und CoSQL steht das neue STAR-Interpretationsmodell für mehrstufige Dialogformen vor dem Training

- 王林nach vorne
- 2023-05-18 19:50:581653Durchsuche
In der sich schnell entwickelnden Internet-Ära tauchen ständig verschiedene Arten von Daten auf. Tabellen sind eine Art allgemeiner strukturierter Daten, die wir entsprechend unseren Anforderungen erhalten können Tabellenwissen, erfordert jedoch oft höhere Designkosten und Lernkosten. Zu diesem Zeitpunkt ist die Text-zu-SQL-Analyseaufgabe besonders wichtig. Je nach Dialogszenario wird sie in diesem Artikel hauptsächlich in Einzelrunden-Text-zu-SQL-Analyse unterteilt untersucht die schwierigeren und näheren Mehrere Runden von Text-to-SQL-Parsing-Aufgaben für reale Anwendungen.
Kürzlich haben die Alibaba DAMO Academy und das Shenzhen Institute of Advanced Technology der Chinesischen Akademie der Wissenschaften ein an SQL-Abfrageanweisungen orientiertes Pre-Training-Modell STAR für mehrere Runden der semantischen Text-to-SQL-Analyse vorgeschlagen. Mittlerweile belegt STAR zehn Monate in Folge den ersten Platz auf den SParC- und CoSQL-Listen. Das Forschungspapier wurde von EMNLP 2022 Findings, einer internationalen Konferenz im Bereich der Verarbeitung natürlicher Sprache, angenommen.

- Paper-Adresse: https://arxiv.org/abs/2210.11888
- code Adresse: https://github.com/alibabAresearch/damo-convai/ tree/main/star
STAR ist ein neuartiges und effektives Pre-Training-Sprachmodell für Dialogtabellen mit mehreren Runden. Dieses Modell verwendet hauptsächlich zwei Pre-Training-Ziele, um komplexe kontextuelle Semantik in Dialogen mit mehreren Runden zu verfolgen Die Zustandsverfolgung von Datenbankschemata wird mit dem Ziel modelliert, Abfragen in natürlicher Sprache und die codierte Darstellung von Datenbankschemata in Konversationsflüssen zu verbessern.
Die Forschung wurde auf SParC und CoSQL, den maßgeblichen Listen für konversationssemantisches Parsing, ausgewertet, STAR im Vergleich mit dem bisher besten Multi-Round-Table-Pre-Training-Modell SCoRe auf dem SParC-Datensatz hat sich im CoSQL-Datensatz um 4,6 %/3,3 % und QM/IM deutlich um 7,4 %/8,5 % verbessert. Insbesondere weist CoSQL mehr kontextbezogene Änderungen auf als der SParC-Datensatz, was die Wirksamkeit der in dieser Studie vorgeschlagenen Vortrainingsaufgabe bestätigt.
Hintergrundeinführung
Um Benutzern die Interaktion mit der Datenbank über einen Dialog in natürlicher Sprache zu ermöglichen, auch wenn sie mit der SQL-Syntax nicht vertraut sind, wurden mehrere Runden von Text-zu-SQL-Analyseaufgaben ins Leben gerufen Eine Verbindung zwischen dem Benutzer und der Datenbank. Eine Brücke zwischen Benutzern, die Fragen in natürlicher Sprache in Interaktionen in ausführbare SQL-Abfrageanweisungen umwandelt.
Vorab trainierte Modelle haben in den letzten Jahren bei verschiedenen NLP-Aufgaben glänzt. Aufgrund der inhärenten Unterschiede zwischen Tabellen und natürlichen Sprachen sind jedoch gewöhnliche vorab trainierte Sprachmodelle (wie BERT, RoBERTa) bei dieser Aufgabe unwirksam. Da die optimale Leistung nicht erreicht werden kann, wurde das vorab trainierte tabellarische Modell (TaLM) [1-5] ins Leben gerufen. Im Allgemeinen müssen sich vorab trainierte Tabellenmodelle (TaLM) mit zwei Kernproblemen befassen, darunter der Modellierung komplexer Abhängigkeiten (Referenzen, Absichtsversätze) zwischen kontextbezogenen Abfragen und der effektiven Nutzung historisch generierter SQL-Ergebnisse. Um die beiden oben genannten Kernprobleme zu lösen, weisen bestehende vorab trainierte Tabellenmodelle die folgenden Mängel auf:
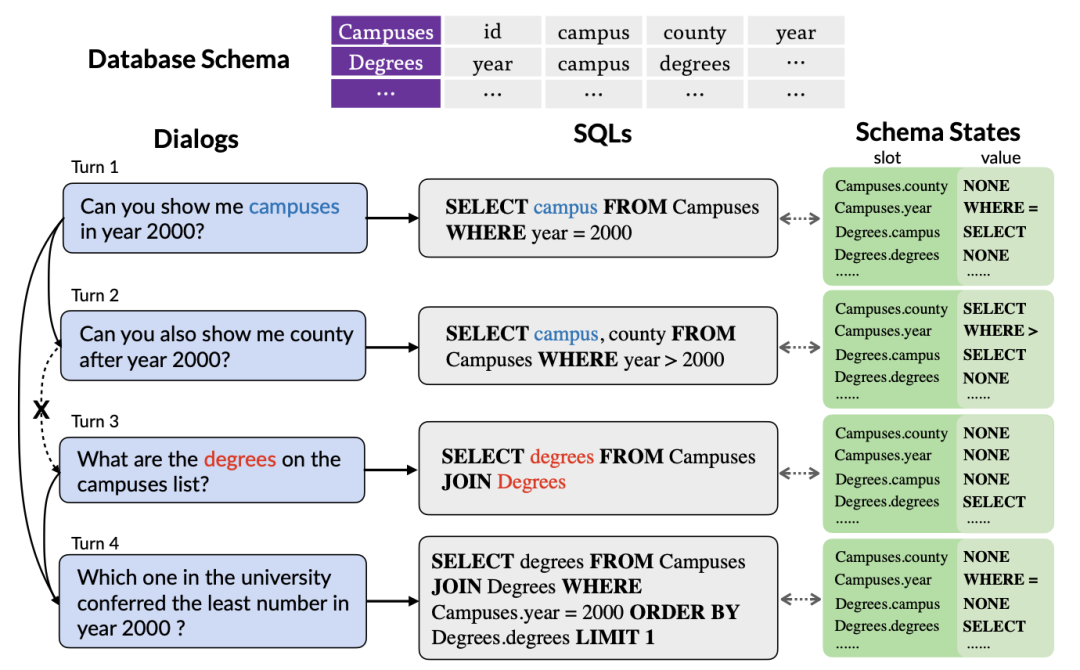
Abbildung 1. Ein Beispiel für kontextabhängige mehrrunde Text-zu-SQL-Analyse.
Erstens untersucht das vorhandene Tabellen-Pre-Training-Modell nur die Kontextinformationen von Abfragen in natürlicher Sprache, ohne die in historischen SQL-Abfrageanweisungen enthaltenen interaktiven Statusinformationen zu berücksichtigen. Diese Informationen können häufig genauer verwendet werden. Fassen Sie die Absicht des Benutzers in einer genauen und kompakten Form zusammen. Daher kann die Modellierung und Verfolgung historischer SQL-Informationen die Absicht der aktuellen Abfragerunde besser erfassen und dadurch entsprechende SQL-Abfrageanweisungen genauer generieren. Wie in Abbildung 1 dargestellt, wird die Tabelle wahrscheinlich in der zweiten Runde der SQL-Abfragen erneut ausgewählt, da der Tabellenname „Compuses“ in der ersten Runde der SQL-Abfragen erwähnt wird. Daher ist es besonders wichtig, den Status der Tabelle zu verfolgen Tabellenname „Compuses“ wichtig.
Zweitens: Da der Benutzer möglicherweise im Konversationsverlauf erwähnte Entitäten ignoriert oder einige Referenzen einführt, was zu einem Mangel an Dialoginformationen in der aktuellen Runde führt, müssen mehrrunde Text-to-SQL-Parsing-Aufgaben kontextbezogene Informationen effektiv modellieren, um sie besser zu verbessern Analysieren Sie die aktuelle Runde des Dialogs in natürlicher Sprache. Wie in Abbildung 1 dargestellt, wurden in der zweiten Dialogrunde die in der ersten Dialogrunde erwähnten „Campusse im Jahr 2000“ weggelassen. Die meisten vorhandenen vorab trainierten Tabellenmodelle berücksichtigen jedoch keine Kontextinformationen, sondern modellieren jede Runde des Dialogs in natürlicher Sprache separat. Obwohl SCoRe [1] Kontextwechselinformationen modelliert, indem es Kontextwechselbezeichnungen zwischen zwei benachbarten Dialogrunden vorhersagt, ignoriert es komplexere Kontextinformationen und kann keine Abhängigkeitsinformationen zwischen Ferndialogen verfolgen. Beispielsweise kann SCoRe in Abbildung 1 aufgrund des Kontextwechsels zwischen der zweiten und dritten Dialogrunde die Fernabhängigkeitsinformationen zwischen der ersten und vierten Dialogrunde nicht erfassen.
Inspiriert durch die Konversationsstatus-Tracking-Aufgabe in Multi-Turn-Dialogen schlägt diese Forschung ein Pre-Training-Ziel vor, das auf der Musterstatus-Tracking basiert, um den Musterstatus von kontextuellem SQL zu verfolgen, das auf das Problem komplexer semantischer Abhängigkeiten zwischen Fragen abzielt Bei Dialogen mit mehreren Runden schlägt diese Forschung eine Methode zur Verfolgung von Dialogabhängigkeiten vor, um die komplexen semantischen Abhängigkeiten zwischen mehreren Dialogrunden zu erfassen, und schlägt eine gewichtungsbasierte kontrastive Lernmethode vor, um die positiven und negativen Beispielbeziehungen zwischen Dialogen besser zu modellieren.
Problemdefinition
Diese Studie gibt zunächst die Notationen und Problemdefinitionen an, die in mehreren Runden von Text-zu-SQL-Analyseaufgaben enthalten sind. 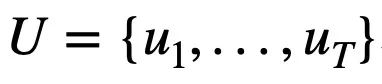 stellt T-Runden natürlichsprachlicher Abfragen, mehrere Runden der Text-zu-SQL-Dialoginteraktion der Abfrage dar, wobei
stellt T-Runden natürlichsprachlicher Abfragen, mehrere Runden der Text-zu-SQL-Dialoginteraktion der Abfrage dar, wobei 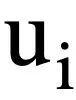 die i-te Runde natürlichsprachlicher Fragen und jede Runde natürlichsprachlicher Dialoge
die i-te Runde natürlichsprachlicher Fragen und jede Runde natürlichsprachlicher Dialoge 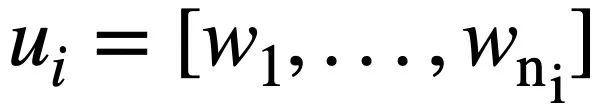 darstellt enthält
darstellt enthält 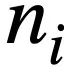 Token. Darüber hinaus gibt es eine interaktive Datenbank s, die N Tabellen
Token. Darüber hinaus gibt es eine interaktive Datenbank s, die N Tabellen 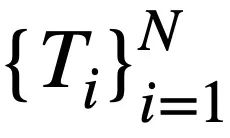 enthält, und alle Tabellen enthalten m Tabellennamen und Spaltennamen,
enthält, und alle Tabellen enthalten m Tabellennamen und Spaltennamen, 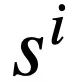 stellt den i-ten Tabellennamen oder Spaltennamen im Datenbankschema s dar. Unter der Annahme, dass es sich bei der aktuellen Runde um die t-te Runde handelt, besteht der Zweck der Text-zu-SQL-Analyseaufgabe darin, auf der aktuellen Runde natürlichsprachlicher Abfragen
stellt den i-ten Tabellennamen oder Spaltennamen im Datenbankschema s dar. Unter der Annahme, dass es sich bei der aktuellen Runde um die t-te Runde handelt, besteht der Zweck der Text-zu-SQL-Analyseaufgabe darin, auf der aktuellen Runde natürlichsprachlicher Abfragen 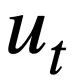 , historischen Abfragen
, historischen Abfragen  , Datenbankschemata und der vorhergesagten SQL-Abfrage zu basieren Anweisung der vorherigen Runde
, Datenbankschemata und der vorhergesagten SQL-Abfrage zu basieren Anweisung der vorherigen Runde 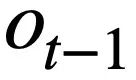 , Generieren Sie die SQL-Abfrageanweisung
, Generieren Sie die SQL-Abfrageanweisung 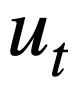 entsprechend der aktuellen Runde der natürlichsprachlichen Abfrage
entsprechend der aktuellen Runde der natürlichsprachlichen Abfrage 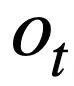 .
.
Methodenbeschreibung
Wie in Abbildung 2 dargestellt, schlägt diese Studie ein auf SQL-Anleitungen basierendes Multi-Round-Table-Pre-Training-Framework vor, das die strukturierten Informationen von historischem SQL vollständig nutzt, um die Dialogdarstellung zu bereichern und diese dann komplexer zu gestalten Kontextinformationen effektiv modellieren.
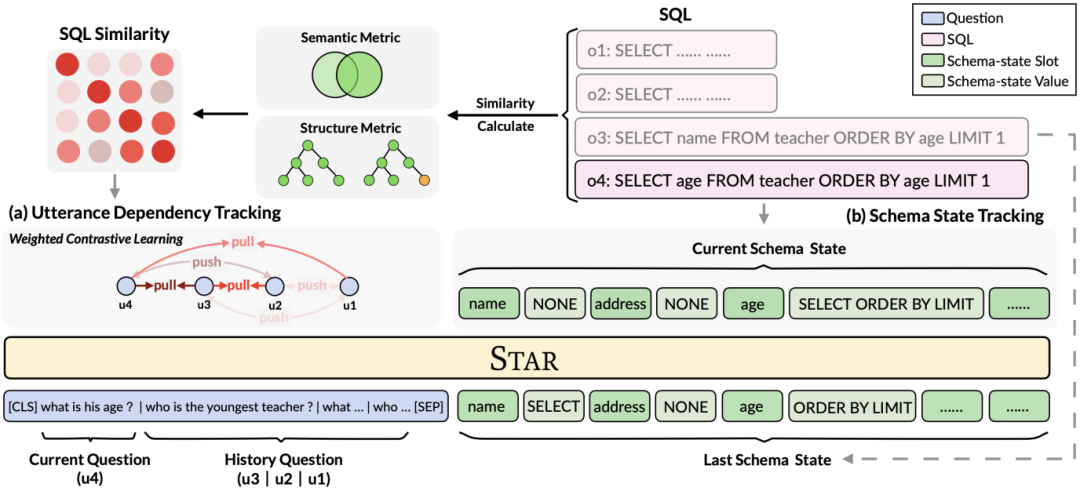
Abbildung 2. Modellrahmen von STAR.
Konkret schlägt diese Forschung Tabellenvortrainingsziele vor, die auf der Verfolgung des Schemastatus und der Verfolgung der Dialogabhängigkeit basieren und jeweils SQL-Abfrageanweisungen und die Absicht von Fragen in natürlicher Sprache in mehreren Interaktionsrunden verfolgen. (1) In einer Dialogsituation mit mehreren Runden hängt die SQL-Abfrage des aktuellen Dialogs von den kontextuellen SQL-Informationen ab. Daher schlägt diese Forschung, inspiriert von der Aufgabe zur Dialogstatusverfolgung in Dialogen mit mehreren Runden, eine auf der Schemastatusverfolgung basierende Methode vor Das Tabellenvortrainingsziel von .SST verfolgt den Schemastatus kontextsensitiver SQL-Abfrageanweisungen (oder Benutzeranforderungen) auf selbstüberwachte Weise. (2) Für das Problem komplexer semantischer Abhängigkeiten zwischen Fragen in natürlicher Sprache in Dialogen mit mehreren Runden wird ein auf Utterance Dependency Tracking (UDT) basierendes Tabellen-Pre-Training-Ziel vorgeschlagen und eine gewichtsbasierte kontrastive Lernmethode verwendet, um besser zu lernen Merkmalsdarstellung für Abfragen in natürlicher Sprache. Im Folgenden werden die beiden Tabellenziele vor dem Training im Detail beschrieben.
Table Pre-Training-Ziel basierend auf der Musterstatusverfolgung
Diese Forschung schlägt ein Tabellen-Pre-Training-Ziel vor, das auf der Schema-Statusverfolgung basiert und den Schemastatus (oder die Benutzeranforderung) von kontextsensitiven SQL-Abfrageanweisungen (oder Benutzeranforderungen) auf selbstüberwachte Weise verfolgt, mit dem Ziel, Vorhersage des Werts des Schema-Slots. Insbesondere verfolgt die Studie den Interaktionsstatus einer Text-to-SQL-Sitzung in Form eines Schemastatus, wobei der Slot das Datenbankschema (d. h. die Spaltennamen aller Tabellen) und der entsprechende Slotwert das SQL-Schlüsselwort ist. Am Beispiel der SQL-Abfrage in Abbildung 3 ist der Wert des Modus-Slots „[car_data]“ das SQL-Schlüsselwort „[SELECT]“. Zunächst wandelt die Studie die in Runde t - 1 vorhergesagte SQL-Abfrageanweisung 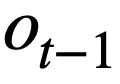 in die Form einer Reihe von Musterzuständen um. Da es sich bei den Schemastatus-Slots um die Spaltennamen aller Tabellen in der Datenbank handelt, werden Werte, die nicht im Schemastatus entsprechend der SQL-Abfrageanweisung
in die Form einer Reihe von Musterzuständen um. Da es sich bei den Schemastatus-Slots um die Spaltennamen aller Tabellen in der Datenbank handelt, werden Werte, die nicht im Schemastatus entsprechend der SQL-Abfrageanweisung 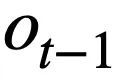 erscheinen, auf [NONE] gesetzt. Wie in Abbildung 3 dargestellt, verwendet diese Studie m Moduszustände
erscheinen, auf [NONE] gesetzt. Wie in Abbildung 3 dargestellt, verwendet diese Studie m Moduszustände 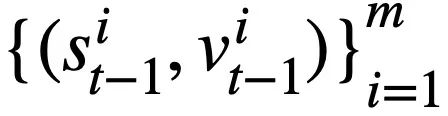 , um die SQL-Abfrageanweisung
, um die SQL-Abfrageanweisung 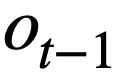 darzustellen, wobei
darzustellen, wobei 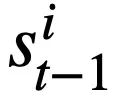 den Slot des i-ten Moduszustands und
den Slot des i-ten Moduszustands und 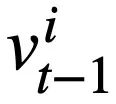 den Wert des Modus darstellt Zustand. Für Runde t besteht das Ziel der Musterstatusverfolgung darin, den Musterstatus
den Wert des Modus darstellt Zustand. Für Runde t besteht das Ziel der Musterstatusverfolgung darin, den Musterstatus 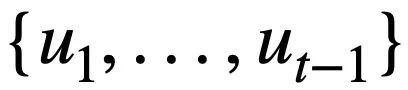 von Runde t anhand aller historischen Fragen in natürlicher Sprache
von Runde t anhand aller historischen Fragen in natürlicher Sprache 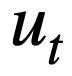 , der aktuellen Frage
, der aktuellen Frage 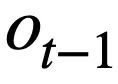 und der vorherigen Runde von SQL-Abfrageanweisungen
und der vorherigen Runde von SQL-Abfrageanweisungen 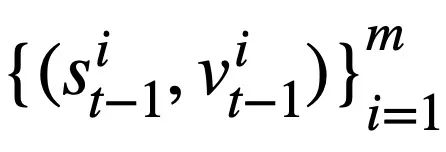 vorherzusagen Wert
vorherzusagen Wert 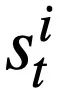 jedes Modusstatus-Slots
jedes Modusstatus-Slots 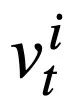 der T-Round-SQL-Abfrageanweisung. Das heißt, in Runde t lautet die Eingabe
der T-Round-SQL-Abfrageanweisung. Das heißt, in Runde t lautet die Eingabe 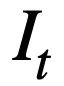 für das Vortrainingsziel für die Musterzustandsverfolgung:
für das Vortrainingsziel für die Musterzustandsverfolgung:
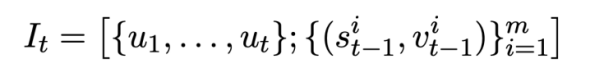
Da jeder Musterzustand 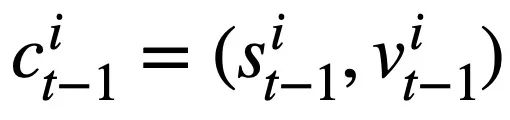 mehrere Wörter enthält, wird eine Aufmerksamkeitsebene angewendet, um
mehrere Wörter enthält, wird eine Aufmerksamkeitsebene angewendet, um 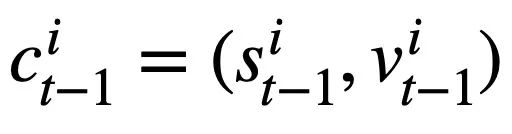 auszudrücken. Insbesondere angesichts der kontextualisierten Ausgabedarstellung
auszudrücken. Insbesondere angesichts der kontextualisierten Ausgabedarstellung  ( l ist der Anfangsindex von
( l ist der Anfangsindex von 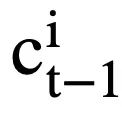 ). Für jeden Moduszustand
). Für jeden Moduszustand 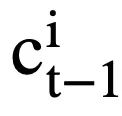 die aufmerksamkeitsbewusste Darstellung des Moduszustands
die aufmerksamkeitsbewusste Darstellung des Moduszustands 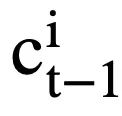
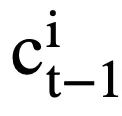 Es kann wie folgt berechnet werden:
Es kann wie folgt berechnet werden:
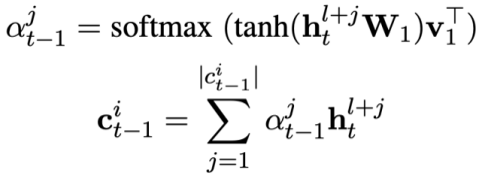
und dann den Modusstatus des aktuellen Problems vorhersagen: # 🎜🎜##🎜 🎜#
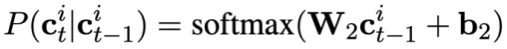
#🎜 🎜#
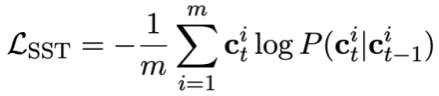
#🎜 🎜#Die Studie schlägt vor: Das Pre-Training-Ziel für die Verfolgung von Äußerungsabhängigkeiten nutzt eine gewichtungsbasierte kontrastive Lernmethode, um die komplexen semantischen Abhängigkeiten zwischen Fragen in natürlicher Sprache in jeder Text-to-SQL-Äußerung zu erfassen. Eine zentrale Herausforderung beim gewichtungsbasierten kontrastiven Lernen besteht darin, geeignete positive und negative Beispielbezeichnungen auf selbstüberwachte Weise zu konstruieren. Negative Beispielpaare können intuitiv durch die Auswahl natürlichsprachlicher Fragen aus verschiedenen Gesprächen erstellt werden. Das Konstruieren positiver Fragenpaare ist jedoch nicht trivial, da die aktuellen Fragen möglicherweise nicht mit den historischen Fragen in Zusammenhang stehen, bei denen der Themenwechsel stattgefunden hat, wie beispielsweise der zweiten und dritten Äußerung in Abbildung 1. Daher behandelt diese Studie Fragen in natürlicher Sprache im selben Gespräch als Paare positiver Beispiele und weist ihnen unterschiedliche Ähnlichkeitswerte zu. SQL ist eine hochstrukturierte Benutzeräußerungsanzeige. Durch die Messung der Ähnlichkeit zwischen aktuellem SQL und historischem SQL können wir daher semantisch abhängige Pseudobezeichnungen für Fragen in natürlicher Sprache erhalten, um Ähnlichkeitswerte für verschiedene Anweisungskonstruktionen zu erhalten und so die Kontextkonstruktion zu steuern. Diese Studie schlägt eine Methode zur Messung der SQL-Ähnlichkeit sowohl aus semantischer als auch aus struktureller Sicht vor. Wie in Abbildung 3 dargestellt:

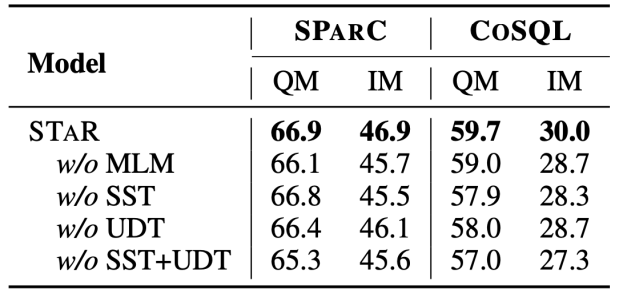
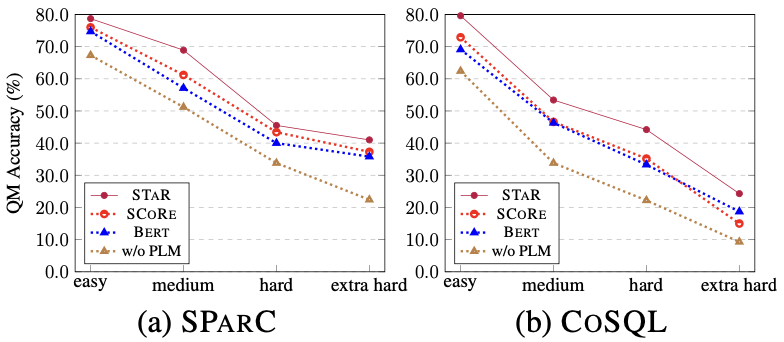
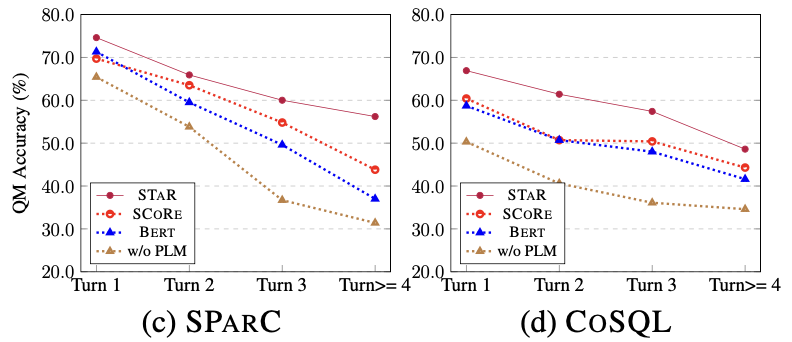
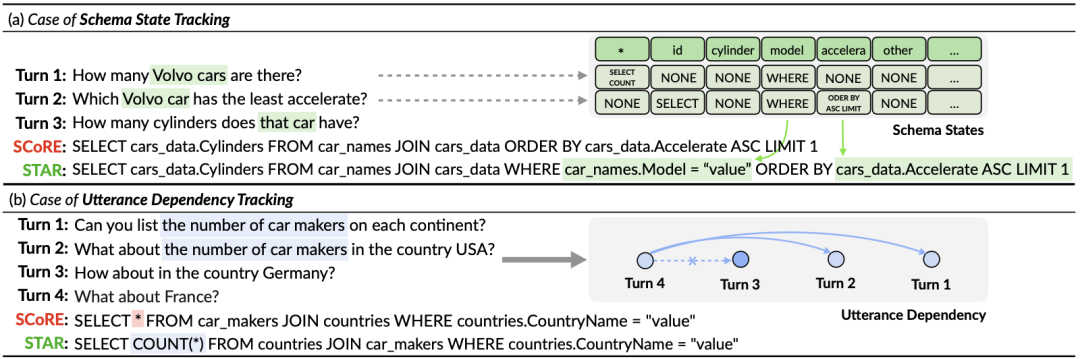
Semantikbasierte SQL-Ähnlichkeitsberechnung Diese Forschung misst die semantische Ähnlichkeit zwischen zwei SQL-Abfrageanweisungen, indem sie die Ähnlichkeit der ihnen entsprechenden Schemazustände berechnet. Wie in Abbildung 3 dargestellt, erhält diese Methode insbesondere den Modusstatus wobei Strukturbasierte SQL-Ähnlichkeitsberechnung Um die Baumstruktur von SQL-Abfrageanweisungen zu nutzen, analysiert diese Studie zunächst jede SQL-Abfrage Zusammenfassend definiert diese Studie zwei SQL-Abfrageanweisungen Gewicht -basierter kontrastiver Verlust Nach Erhalt der SQL-Ähnlichkeit verwendet diese Studie gewichtetes kontrastives Lernen, um die Darstellung semantisch ähnlicher Fragen in natürlicher Sprache im Gespräch näher zu bringen und die Semantik zu verbessern Repräsentations-Pushback für unterschiedliche natürliche Sprachprobleme. Konkret verwendet die Studie zunächst einen Aufmerksamkeitsmechanismus, um die Eingabedarstellung zu lernen 🎜# Anschließend minimiert die Studie die gewichtete Kontrastverlustfunktion, um das gesamte Netzwerk zu optimieren: Schließlich wird das Erlernen von Abfragen in natürlicher Sprache und der Darstellung von Datenbankschemata auf der Grundlage des gesamten Netzwerks durchgeführt Im Kontext verwendet diese Studie auch ein Vortrainingsziel, das auf der semantischen Maskenmodellierung basiert, und die Verlustfunktion wird ausgedrückt als. Basierend auf den oben genannten drei Trainingszielen definiert diese Studie eine auf Homoskedastizität basierende Gelenkverlustfunktion: 🎜🎜# Benchmark-Modell In Bezug auf das Basismodell wurden in der Studie die folgenden Methoden verglichen: (1) GAZP [6], das den Dialog in natürlicher Sprache synthetisiert, indem es ein Vorwärts-Semantik-Parsing-Modell und ein Rückwärts-Dialoggenerierungsmodell kombiniert – Trainingsdaten von SQL-Abfrageanweisungspaaren und schließlich Auswahl von Daten mit Zykluskonsistenz, die zum Vorwärtssemantikanalysemodell passen. (2) EditSQL [7] berücksichtigt die Informationen zum Interaktionsverlauf und verbessert die SQL-Generierungsqualität der aktuellen Dialogrunde, indem es SQL-Abfrageanweisungen zum Zeitpunkt vor der Bearbeitung vorhersagt. (3) IGSQL [8] schlägt ein interaktives Diagrammkodierungsmodell für Datenbankschemata vor, das die historischen Informationen des Datenbankschemas verwendet, um historische Eingabeinformationen in natürlicher Sprache zu erfassen, und in der Dekodierungsphase einen Gating-Mechanismus einführt. (4) IST-SQL [9] definiert, inspiriert von der Konversationsstatus-Tracking-Aufgabe, zwei interaktive Zustände, den Schemastatus und den SQL-Status, und aktualisiert den Status gemäß der letzten vorhergesagten SQL-Abfrageanweisung in jeder Runde. (5) R2SQL [10] schlägt ein dynamisches Diagramm-Framework vor, um die komplexen Interaktionen zwischen Dialogen und Datenbankschemata in Dialogflüssen zu modellieren, und bereichert die kontextbezogene Darstellung von Dialogen und Datenbankschemata durch einen dynamischen Speicherzerfallsmechanismus. (6) PICARD [11] schlägt eine inkrementelle semantische Analyse vor, um das autoregressive Dekodierungsmodell des Sprachmodells einzuschränken. In jedem Dekodierungsschritt wird nach zulässigen Ausgabesequenzen gesucht, indem die Akzeptanz der Dekodierungsergebnisse eingeschränkt wird. (7) DELTA [12] verwendet zunächst ein Dialog-Umschreibungsmodell, um das Integritätsproblem des Dialogkontexts zu lösen, und gibt dann den gesamten Dialog in ein einrundes semantisches Text-to-SQL-Analysemodell ein, um die endgültige SQL-Abfrageanweisung zu erhalten. (8) HIE-SQL [13] behandelt aus multimodaler Sicht natürliche Sprache und SQL als zwei Modalitäten, untersucht die Kontextabhängigkeitsinformationen zwischen allen historischen Konversationen und der im vorherigen Satz vorhergesagten SQL-Abfrageanweisung und schlägt einen bimodalen Vor- trainiertes Modell und entwarf einen modalen Linkgraphen zwischen Konversationen und SQL-Abfrageanweisungen. Gesamtexperimentelle Ergebnisse Wie in Abbildung 4 dargestellt, ist aus den experimentellen Ergebnissen ersichtlich, dass das STAR-Modell bei den beiden Datensätzen von SParC und CoSQL weitaus besser abschneidet als andere Vergleichsmethoden. Im Vergleich zum Modell vor dem Training übertrifft das STAR-Modell andere Modelle vor dem Training (wie BERT, RoBERTa, GRAPPA, SCoRe) im CoSQL-Entwicklungsdatensatz im Vergleich zum SCoRE-Modell um 7,4 % und der IM-Score stieg um 7,5 %. Im Hinblick auf den Vergleich von Downstream-Text-zu-SQL-Modellen ist das LGESQL-Modell, das STAR als Basis des vorab trainierten Modells verwendet, weitaus besser als die Downstream-Methoden, die beispielsweise andere vorab trainierte Sprachmodelle als Basis verwenden Das leistungsstärkste LGESQL-Modell verwendet GRAPPA als Basis. Abbildung 4: Experimentelle Ergebnisse zu SParC- und CoSQL-Datensätzen . Wirksamkeit jedes Moduls. Die Ergebnisse des Ablationsexperiments sind in Abbildung 5 dargestellt. Wenn die SST- oder UDT-Vortrainingsziele entfernt werden, nimmt der Effekt erheblich ab. Die experimentellen Ergebnisse, die alle Vortrainingsziele kombinieren, haben jedoch bei allen Datensätzen die besten Ergebnisse erzielt , was die Gültigkeit von SST und UDT veranschaulicht. Darüber hinaus wurden in dieser Studie weitere Experimente mit zwei SQL-Ähnlichkeitsberechnungsmethoden in UDT durchgeführt. Wie aus Abbildung 6 ersichtlich ist, können beide SQL-Ähnlichkeitsberechnungsmethoden den Effekt des STAR-Modells verbessern, und der kombinierte Effekt ist der beste. Abbildung 5. Ergebnisse des Ablationsexperiments für Ziele vor dem Training. Abbildung 6. Ablationsversuchsergebnisse für die SQL-Ähnlichkeitsberechnungsmethode. Modelleffekte von Stichproben mit unterschiedlichen Schwierigkeiten Wie in Abbildung 7 gezeigt, ist aus den experimentellen Ergebnissen von Stichproben mit unterschiedlichen Schwierigkeiten in den beiden Datensätzen von SParC und CoSQL ersichtlich, dass der Vorhersageeffekt des STAR-Modells auf Stichproben mit unterschiedlichen Schwierigkeiten zutrifft Schwierigkeiten ist weitaus besser als andere Vergleiche. Die Methode ist selbst bei den schwierigsten extraharten Proben effektiv. Abbildung 7. Experimentelle Ergebnisse von Stichproben unterschiedlicher Schwierigkeit in SParC- und CoSQL-Datensätzen. Modelleffekte verschiedener Stichprobenrunden Wie in Abbildung 8 gezeigt, lässt sich aus den experimentellen Ergebnissen verschiedener Stichprobenrunden für die beiden Datensätze von SParC und CoSQL Folgendes erkennen: Das Gespräch dreht sich. Mit zunehmender Zeit nimmt der QM-Index des Basismodells stark ab, während das STAR-Modell selbst in der dritten und vierten Runde eine stabilere Leistung zeigen kann. Dies zeigt, dass das STAR-Modell Interaktionszustände im Konversationsverlauf besser verfolgen und untersuchen kann, um dem Modell dabei zu helfen, die aktuelle Konversation besser zu analysieren. Abbildung 8. Experimentelle Ergebnisse verschiedener Stichprobenrunden für SParC- und CoSQL-Datensätze. Fallanalyse Um die tatsächliche Wirkung des STAR-Modells zu bewerten, wählte diese Studie zwei Stichproben aus dem CoSQL-Validierungssatz aus und verglich die vom SCoRe-Modell und dem STAR-Modell generierten SQL-Abfragen in Abbildung 9-Anweisung. Aus dem ersten Beispiel können wir ersehen, dass das STAR-Modell die Schemastatusinformationen von historischem SQL (z. B. [car_names.Model]) gut nutzen kann, wodurch die SQL-Abfrageanweisung für die dritte Dialogrunde korrekt generiert wird, während das SCoRe Das Modell kann diese Modusstatusinformationen nicht verfolgen. Im zweiten Beispiel verfolgt das STAR-Modell effektiv die langfristigen Konversationsabhängigkeiten zwischen der ersten und vierten Runde der Äußerungen und durch die Verfolgung und Referenzierung „der Anzahl“ von Nachrichten in der zweiten Runde der Konversationen im vierten Das SQL-Schlüsselwort [ SELECT COUNT (*)] wird in der Round-SQL-Abfrageanweisung korrekt generiert. Das SCoRe-Modell kann diese langfristige Abhängigkeit jedoch nicht verfolgen und wird durch die dritte Runde von Äußerungen gestört, wodurch falsche SQL-Abfrageanweisungen generiert werden. Abbildung 9. Beispielanalyse. ModelScope-Modell-Open-Source-Community Das auf dem CoSQL-Datensatz in diesem Artikel trainierte Modell wurde in die ModelScope-Modell-Open-Source-Community integriert. Leser können die V100-GPU-Umgebung direkt im Notebook auswählen und das Demomodell für mehrere Runden semantischer Text-to-SQL-Analyseaufgaben über eine einfache Pipeline verwenden. In diesem Artikel schlug das Forschungsteam ein neuartiges und effektives Multi-Round-Table-Wissens-Pre-Training-Modell (STAR-Modell) vor. Für semantische Text-to-SQL-Parsing-Aufgaben in mehreren Runden schlägt das STAR-Modell Tabellenvortrainingsziele vor, die auf der Verfolgung des Schemastatus und der Verfolgung von Dialogabhängigkeiten basieren und die Absicht von SQL-Abfrageanweisungen bzw. Fragen in natürlicher Sprache in Interaktionen mit mehreren Runden verfolgen . Das STAR-Modell hat in zwei maßgeblichen semantischen Mehrrunden-Parsing-Listen sehr gute Ergebnisse erzielt und zehn Monate in Folge den ersten Platz auf der Liste belegt. Abschließend können sich Studierende, die sich für die SIAT-NLP-Gruppe der Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences interessieren, für Postdoc-/Doktoranden-/Master-/Praktikumsstellen bewerben. Bitte senden Sie Ihren Lebenslauf an min.yang @siat.ac.cn. 
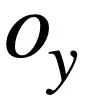 und
und 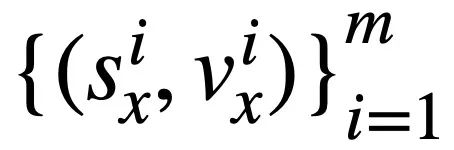 von zwei SQL-Abfrageanweisungen bzw.
von zwei SQL-Abfrageanweisungen bzw. 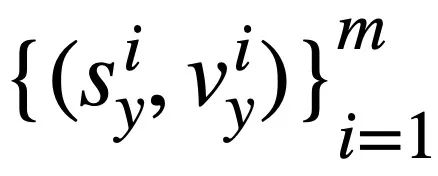 . Dann verwendet die Studie die Jaccard-Ähnlichkeit, um die semantische Ähnlichkeit zwischen ihnen zu berechnen
. Dann verwendet die Studie die Jaccard-Ähnlichkeit, um die semantische Ähnlichkeit zwischen ihnen zu berechnen 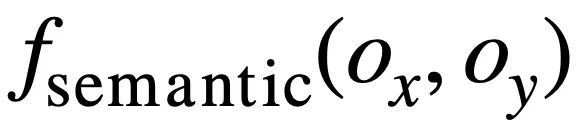 :
: 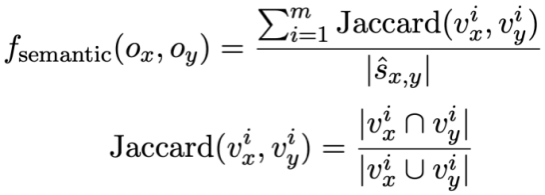
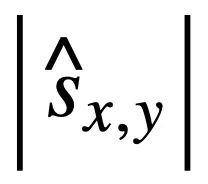 bedeutet, dass der Wert von
bedeutet, dass der Wert von 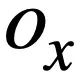 und
und 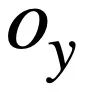 , der dem Modusstatus entspricht, nicht [NONE ] Die Anzahl unterschiedlicher Musterzustände.
, der dem Modusstatus entspricht, nicht [NONE ] Die Anzahl unterschiedlicher Musterzustände. 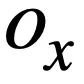 in einen SQL-Baum
in einen SQL-Baum 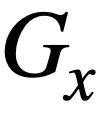 , z wie in Abbildung 3 dargestellt. Bei zwei SQL-Bäumen
, z wie in Abbildung 3 dargestellt. Bei zwei SQL-Bäumen 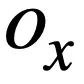
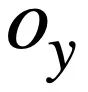 und
und 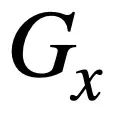 und
und  verwendet diese Studie den Weisfeiler-Lehman-Algorithmus, um den strukturellen Ähnlichkeitswert
verwendet diese Studie den Weisfeiler-Lehman-Algorithmus, um den strukturellen Ähnlichkeitswert 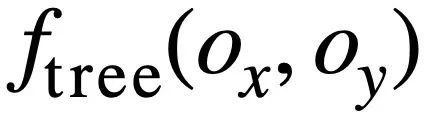 wie folgt zu berechnen:
wie folgt zu berechnen: 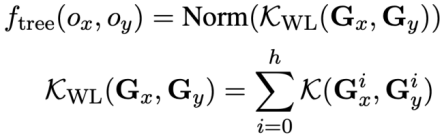
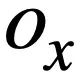 und Die Ähnlichkeitsbewertung von
und Die Ähnlichkeitsbewertung von 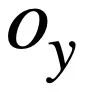 ist wie folgt:
ist wie folgt: 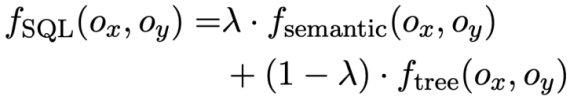
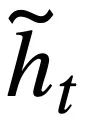 ist ein trainierbarer Parameter. #? 🎜 # Diese Studie verifizierte die Wirksamkeit des STAR-Modells an zwei maßgeblichen Konversations-Semantik-Parsing-Datensätzen, SParC und CoSQL. Unter ihnen ist SParC ein domänenübergreifender Text-zu-SQL-Analysedatensatz mit mehreren Runden, der etwa 4.300 Mehrrunden-Interaktionen und mehr als 12.000 Frage-SQL-Abfrageanweisungspaare in natürlicher Sprache enthält. CoSQL ist ein domänenübergreifender Konversations-Text. To-SQL-Parsing-Datensatz Der To-SQL-Parsing-Datensatz enthält etwa 3.000 Konversationsinteraktionen und mehr als 10.000 Frage-SQL-Abfrageanweisungspaare in natürlicher Sprache. Im Vergleich zu SParC ist der Konversationskontext von CoSQL semantisch relevanter und die Syntax von SQL-Abfrageanweisungen ist komplexer.
ist ein trainierbarer Parameter. #? 🎜 # Diese Studie verifizierte die Wirksamkeit des STAR-Modells an zwei maßgeblichen Konversations-Semantik-Parsing-Datensätzen, SParC und CoSQL. Unter ihnen ist SParC ein domänenübergreifender Text-zu-SQL-Analysedatensatz mit mehreren Runden, der etwa 4.300 Mehrrunden-Interaktionen und mehr als 12.000 Frage-SQL-Abfrageanweisungspaare in natürlicher Sprache enthält. CoSQL ist ein domänenübergreifender Konversations-Text. To-SQL-Parsing-Datensatz Der To-SQL-Parsing-Datensatz enthält etwa 3.000 Konversationsinteraktionen und mehr als 10.000 Frage-SQL-Abfrageanweisungspaare in natürlicher Sprache. Im Vergleich zu SParC ist der Konversationskontext von CoSQL semantisch relevanter und die Syntax von SQL-Abfrageanweisungen ist komplexer. 
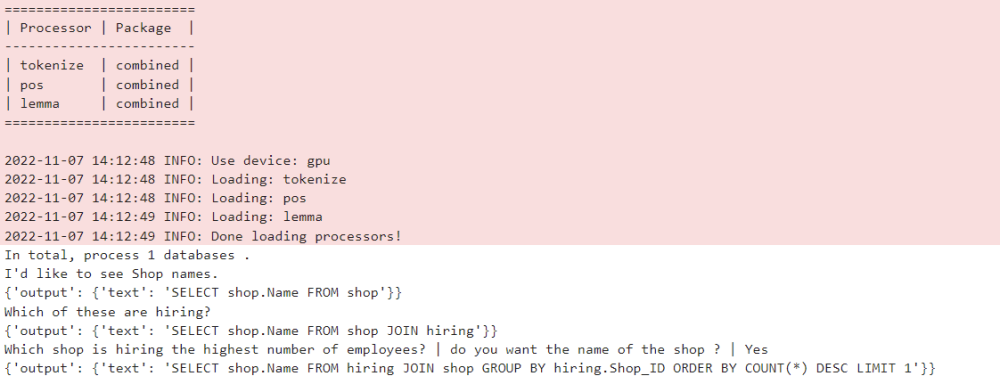
Zusammenfassung
Das obige ist der detaillierte Inhalt vonAn der Spitze der international anerkannten Liste der semantischen Konversationsanalysen von SParC und CoSQL steht das neue STAR-Interpretationsmodell für mehrstufige Dialogformen vor dem Training. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr