

 Technologie-PeripheriegeräteKITeilen der Technologie des Volcano-Engine-Tools: Verwenden Sie KI, um das Data Mining und das SQL-Schreiben ohne Schwellenwert von Null abzuschließen
Technologie-PeripheriegeräteKITeilen der Technologie des Volcano-Engine-Tools: Verwenden Sie KI, um das Data Mining und das SQL-Schreiben ohne Schwellenwert von Null abzuschließen

Beim Einsatz von BI-Tools stoßen wir häufig auf die Frage: „Wie können wir Daten erzeugen und verarbeiten, wenn wir SQL nicht kennen? Können wir Mining-Analysen durchführen, wenn wir keine Algorithmen kennen?“ Ein professionelles Algorithmenteam führt Data Mining durch. Die Datenanalyse und -visualisierung erscheint ebenfalls relativ fragmentiert. Eine optimierte Durchführung der Algorithmenmodellierungs- und Datenanalysearbeiten ist ebenfalls eine gute Möglichkeit, die Effizienz zu verbessern.
Gleichzeitig stehen für professionelle Data-Warehouse-Teams Dateninhalte mit demselben Thema vor dem Problem der „wiederholten Erstellung, relativ verstreuten Verwendung und Verwaltung“ – gibt es eine Möglichkeit, Daten mit demselben Thema und unterschiedlichen Inhalten gleichzeitig zu erstellen? gleichzeitig in einer Aufgabe? Kann der erstellte Datensatz als Eingabe für die erneute Teilnahme an der Datenkonstruktion verwendet werden?
1. Die visuelle Modellierungsfunktion von DataWind ist da
Die von der Volcano Engine eingeführte BI-Plattform DataWind für intelligente Dateneinblicke hat eine neue erweiterte funktionsvisuelle Modellierung eingeführt.
Benutzer können den komplexen Datenverarbeitungs- und Modellierungsprozess durch visuelles Ziehen, Ziehen und Verbinden in einen klaren und leicht verständlichen Canvas-Prozess vereinfachen. Alle Arten von Benutzern können die Datenproduktion und -verarbeitung gemäß der Idee abschließen Was sie wollen, ist, was sie bekommen, wodurch die Datenproduktionsschwelle gesenkt wird.
Canvas unterstützt die gleichzeitige Erstellung mehrerer Canvas-Prozesse, wodurch die Effizienz der Datenkonstruktion verbessert und die Kosten für die Aufgabenverwaltung gesenkt werden können Arten von Datenbereinigungs- und Feature-Engineering-Algorithmen. Sie decken grundlegende bis erweiterte Datenproduktionsfunktionen ab und erfordern keine Codierung, um komplexe Datenfunktionen zu vervollständigen.
2. Null-Schwellen-SQL-Tools
Die Datenproduktion und -verarbeitung ist der erste Schritt zur Datenbeschaffung und -analyse.
Für technisch nicht versierte Benutzer gibt es einen bestimmten Schwellenwert für die Verwendung der SQL-Syntax. Gleichzeitig können lokale Dateien nicht regelmäßig aktualisiert werden, was dazu führt, dass das Dashboard jedes Mal manuell neu erstellt werden muss. Der für die Datenbeschaffung erforderliche technische Arbeitsaufwand muss häufig eingeplant werden, wodurch die Aktualität und Zufriedenheit der Datenerfassung erheblich verringert wird. Daher ist es besonders wichtig, Tools zur Datenkonstruktion ohne Code zu verwenden.
Im Folgenden sind zwei typische Szenarien aufgeführt, wie die nullschwellige Datenverarbeitung am Arbeitsplatz angewendet wird.
2.1 [Szenario 1] Was Sie denken, ist das, was Sie erhalten. Der Datenverarbeitungsprozess wird visuell abgeschlossen werden durch visuelle Modellierung per Drag-and-Drop-Operator konstruiert.
Wenn Sie die Anzahl der Bestellungen und die Bestellmenge nach Datum und Stadtgranularität sowie die Stadtdaten der 10 größten Tagesverbrauchsmengen erhalten möchten, ist der Vorgang wie folgt:
| Visueller Modellierungsprozess|||||
|
|





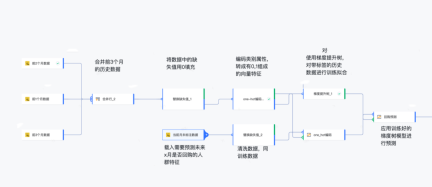 Zeilen zusammenführen: Füge die Ausgabedatentabellen von n Operatoren (Rechtecke im Bild) zu einer Gesamtdatentabelle zusammen, die auf konsistenten Überschriften basiert In den Benutzerverkaufsdaten sind hier keine Änderungen erforderlich.
Zeilen zusammenführen: Füge die Ausgabedatentabellen von n Operatoren (Rechtecke im Bild) zu einer Gesamtdatentabelle zusammen, die auf konsistenten Überschriften basiert In den Benutzerverkaufsdaten sind hier keine Änderungen erforderlich. 


Das obige ist der detaillierte Inhalt vonTeilen der Technologie des Volcano-Engine-Tools: Verwenden Sie KI, um das Data Mining und das SQL-Schreiben ohne Schwellenwert von Null abzuschließen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Sie müssen KI am Arbeitsplatz hinter einem Schleier der Unwissenheit bauenApr 29, 2025 am 11:15 AM
Sie müssen KI am Arbeitsplatz hinter einem Schleier der Unwissenheit bauenApr 29, 2025 am 11:15 AMIn John Rawls 'wegweisendem Buch von 1971 schlug er ein Gedankenexperiment vor, das wir als Kern des heutigen KI-Designs und der Entscheidungsfindung verwenden sollten: den Schleier der Unwissenheit. Diese Philosophie bietet ein einfaches Instrument zum Verständnis von Eigenkapital und bietet auch eine Entwurf für Führungskräfte, um dieses Verständnis zu nutzen, um KI auf gerechte Weise zu entwerfen und umzusetzen. Stellen Sie sich vor, Sie treffen Regeln für eine neue Gesellschaft. Aber es gibt eine Prämisse: Sie wissen nicht im Voraus, welche Rolle Sie in dieser Gesellschaft spielen werden. Möglicherweise sind Sie reich oder arm, gesund oder behindert, gehören einer Mehrheit oder einer marginalen Minderheit. Der Betrieb unter diesem "Schleier der Unwissenheit" verhindert, dass Regelmacher Entscheidungen treffen, die selbst zugute kommen. Im Gegenteil, die Menschen werden motivierter sein, die Öffentlichkeit zu formulieren
 Entscheidungen, Entscheidungen… nächste Schritte für die praktische angewandte KIApr 29, 2025 am 11:14 AM
Entscheidungen, Entscheidungen… nächste Schritte für die praktische angewandte KIApr 29, 2025 am 11:14 AMZahlreiche Unternehmen sind auf Roboterprozessautomatisierung (RPA) spezialisiert und bieten Bots, um sich wiederholende Aufgaben zu automatisieren - Uipath, Automatisierung überall, blaues Prisma und andere. In der Zwischenzeit verarbeiten Sie Mining, Orchestrierung und intelligente Dokumentenverarbeitung Speciali
 Die Agenten kommen - mehr darüber, was wir neben AI -Partnern tun werdenApr 29, 2025 am 11:13 AM
Die Agenten kommen - mehr darüber, was wir neben AI -Partnern tun werdenApr 29, 2025 am 11:13 AMDie Zukunft der KI bewegt sich über die einfache Wortvorhersage und die Konversationsimulation hinaus. KI -Agenten sind aufgetaucht, in der Lage, unabhängige Handlungen und Aufgabenabschluss zu erledigen. Diese Verschiebung zeigt sich bereits in Tools wie dem Claude von Anthropic. KI -Agenten: Forschung a
 Warum Empathie wichtiger ist als die Kontrolle für Führungskräfte in einer KI-gesteuerten ZukunftApr 29, 2025 am 11:12 AM
Warum Empathie wichtiger ist als die Kontrolle für Führungskräfte in einer KI-gesteuerten ZukunftApr 29, 2025 am 11:12 AMSchnelle technologische Fortschritte erfordern eine zukunftsweisende Perspektive auf die Zukunft der Arbeit. Was passiert, wenn die KI nur die Produktivitätsverstärkung überschreitet und unsere gesellschaftlichen Strukturen prägt? Topher McDougals bevorstehendes Buch Gaia Wakes:
 KI für die Produktklassifizierung: Können Maschinen das Steuergesetz meistern?Apr 29, 2025 am 11:11 AM
KI für die Produktklassifizierung: Können Maschinen das Steuergesetz meistern?Apr 29, 2025 am 11:11 AMDie Produktklassifizierung, die häufig komplexe Codes wie "HS 8471.30" aus Systemen wie dem harmonisierten System (HS) umfasst, ist für den internationalen Handel und den Inlandsumsatz von entscheidender Bedeutung. Diese Codes gewährleisten den korrekten Steuerantrag und wirken sich auf jeden Inv aus
 Könnte die Nachfrage des Rechenzentrums einen Klima -Tech -Rebound auslösen?Apr 29, 2025 am 11:10 AM
Könnte die Nachfrage des Rechenzentrums einen Klima -Tech -Rebound auslösen?Apr 29, 2025 am 11:10 AMDie Zukunft des Energieverbrauchs in Rechenzentren und Klimaschutzinvestitionen In diesem Artikel wird der Anstieg des Energieverbrauchs in Rechenzentren untersucht, die von KI und ihren Auswirkungen auf den Klimawandel angetrieben werden, und analysiert innovative Lösungen und politische Empfehlungen, um diese Herausforderung zu befriedigen. Herausforderungen des Energiebedarfs: Zentren im großen und ultra-großen Maßstab verbrauchen enorme Macht, vergleichbar mit der Summe von Hunderttausenden gewöhnlicher nordamerikanischer Familien und aufstrebende AI-Zentren im Bereich Ultra-Large-Scale-Zentren verbrauchen Dutzende von Zeiten mehr mehr Macht als diese. In den ersten acht Monaten des 2024 haben Microsoft, Meta, Google und Amazon rund 125 Milliarden US -Dollar in den Bau und den Betrieb von AI -Rechenzentren investiert (JP Morgan, 2024) (Tabelle 1). Der wachsende Energiebedarf ist sowohl eine Herausforderung als auch eine Chance. Laut Kanarischen Medien der drohende Elektrizität
 AI und Hollywoods nächstes goldenes ZeitalterApr 29, 2025 am 11:09 AM
AI und Hollywoods nächstes goldenes ZeitalterApr 29, 2025 am 11:09 AMGenerative AI revolutioniert die Film- und Fernsehproduktion. Das Ray 2-Modell von Luma sowie das Gen-4 von Runway, Openai von Sora, Google's VEO und andere neue Modelle verbessern die Qualität der generierten Videos mit beispielloser Geschwindigkeit. Diese Modelle können problemlos komplexe Spezialeffekte und realistische Szenen erzeugen, selbst kurze Videoclips und Kameraser-Bewegungseffekte wurden erreicht. Während die Manipulation und Konsistenz dieser Tools noch verbessert werden müssen, ist die Geschwindigkeit des Fortschritts erstaunlich. Generatives Video wird zu einem unabhängigen Medium. Einige Modelle sind gut in der Animationsproduktion, andere sind gut in Live-Action-Bildern. Es ist erwähnenswert, dass Adobe's Firefly und Moonvalleys MA
 Wird Chatgpt langsam AIs größtes Ja-Mann?Apr 29, 2025 am 11:08 AM
Wird Chatgpt langsam AIs größtes Ja-Mann?Apr 29, 2025 am 11:08 AMChatGPT -Benutzererfahrung lehnt ab: Ist es ein Modellverschlechterungs- oder Benutzererwartungen? In jüngster Zeit haben sich eine große Anzahl von ChatGPT bezahlten Nutzern über ihre Leistungsverschlechterung beschwert, die weit verbreitete Aufmerksamkeit erregt hat. Die Benutzer berichteten über langsamere Antworten auf Modelle, kürzere Antworten, mangelnde Hilfe und noch mehr Halluzinationen. Einige Benutzer äußerten Unzufriedenheit in den sozialen Medien und wiesen darauf hin, dass ChatGPT zu „zu schmeichelhaft“ geworden ist, und neigt dazu, Benutzeransichten zu überprüfen, anstatt ein kritisches Feedback zu geben. Dies wirkt sich nicht nur auf die Benutzererfahrung aus, sondern verleiht Unternehmenskunden auch tatsächliche Verluste, wie z. B. reduzierte Produktivität und Rechenressourcenverschwendung. Nachweis der Leistungsverschlechterung Viele Benutzer haben einen signifikanten Verschlechterung der Chatgpt-Leistung gemeldet, insbesondere in älteren Modellen wie GPT-4 (die Ende dieses Monats bald vom Service abgebrochen werden). Das


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

