
Heim >Technologie-Peripheriegeräte >KI >Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.
Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.

- 王林nach vorne
- 2023-11-26 20:22:581694Durchsuche
Welche Erfahrung wird es mit sich bringen, wenn visuelle Eingabeaufforderungen verwendet werden?
Zeichnen Sie einfach eine zufällige Skizze in das Bild und die gleiche Kategorie wird sofort markiert!

Sogar der Link zur Kornzählung ist für GPT-4V schwer zu handhaben. Sie müssen nur manuell an der Kiste ziehen, um alle Reiskörner zu finden.

Mit einem neuen Objekterkennungsparadigma!
Auf der gerade zu Ende gegangenen IDEA-Jahreskonferenz präsentierte Shen Xiangyang, Gründungsvorsitzender des IDEA-Instituts und ausländischer Akademiker der National Academy of Engineering, die neuesten Forschungsergebnisse –
Der Inhalt von T-Rex basiert auf dem Visual Prompt-Modell muss neu geschrieben werden

Der gesamte Prozess ist interaktiv, sofort einsatzbereit und kann in nur wenigen Schritten abgeschlossen werden.
Zuvor segmentierte Metas Open-Source-SAM alle Modelle, was den GPT-3-Moment im Lebenslaufbereich direkt einleitete. Es basierte jedoch immer noch auf dem Text-Prompt-Paradigma, das mit einigen komplexen und seltenen Modellen schwieriger zu handhaben war Szenarien.
Jetzt können Sie das Problem ganz einfach lösen, indem Sie Bilder ändern.
Darüber hinaus ist die gesamte Konferenz auch voller nützlicher Informationen, wie zum Beispiel das wissensgesteuerte Großmodell Think-on-Graph, die Entwicklerplattform MoonBit, das wissenschaftliche KI-Forschungsartefakt ReadPaper Update 2.0, der SPU Confidential Computing Co-Prozessor und das steuerbare Porträtvideo Generationsplattform HiveNet und so weiter.
Schließlich teilte Shun Xiangyang auch das Projekt mit, dem er in den letzten Jahren die meiste Zeit gewidmet hat: Wirtschaft in geringer Höhe.
Ich glaube, wenn die Tieflandwirtschaft relativ ausgereift ist, werden jeden Tag 100.000 Drohnen am Himmel von Shenzhen fliegen und jeden Tag Millionen von Drohnen starten
Verwenden Sie Vision, um Aufforderungen zu geben
T -In Zusätzlich zur grundlegenden Einzelrunden-Eingabeaufforderungsfunktion unterstützt Rex auch drei erweiterte Modi
- Mehrrunden-Positivmodus
Dies ähnelt dem Mehrrundendialog, der genauere Ergebnisse liefern und verpasste Erkennungen vermeiden kann
- Positiv + Der Negativmodus
eignet sich für Szenarien, in denen visuelle Hinweise mehrdeutig sind und zu Fehlerkennungen führen.
Mit dem Kreuzdiagrammmodus können Sie Diagramme neu gestalten und anordnen, um Daten und Informationen einfach zu visualisieren.
Durch die Verwendung eines Referenzdiagramms zur Erkennung anderer Bilder.

Berichten zufolge ist T-Rex nicht auf vordefinierte Kategorien beschränkt und kann dies auch tun Anhand visueller Beispiele werden Erkennungsziele spezifiziert, wodurch das Problem gelöst wird, dass sich bestimmte Objekte nur schwer vollständig in Worte fassen lassen, und die Eingabeaufforderungseffizienz verbessert wird. Gerade bei komplexen Bauteilen in manchen Industrieszenarien ist der Effekt besonders offensichtlich
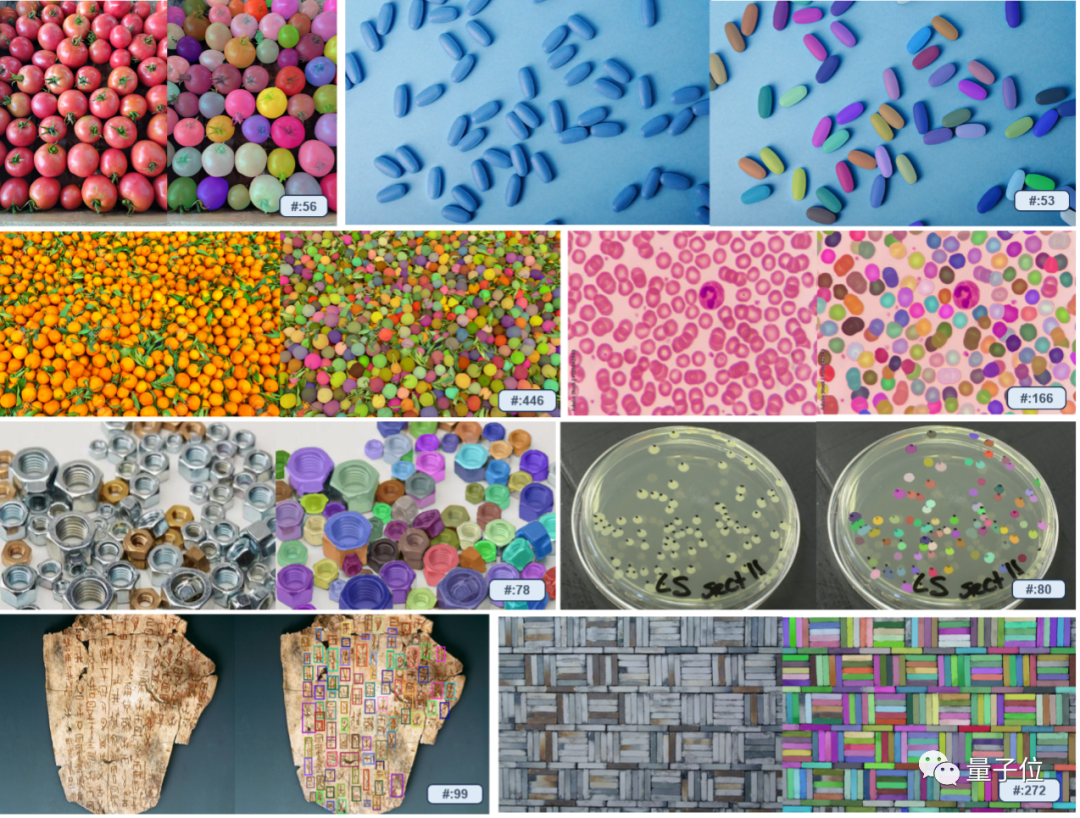
Darüber hinaus können durch die Interaktion mit Benutzern die Erkennungsergebnisse auch jederzeit schnell ausgewertet und Fehlerkorrekturen vorgenommen werden.
T-Rex besteht hauptsächlich aus drei Komponenten: Bild-Encoder, Hinweis-Encoder und Frame-Decoder
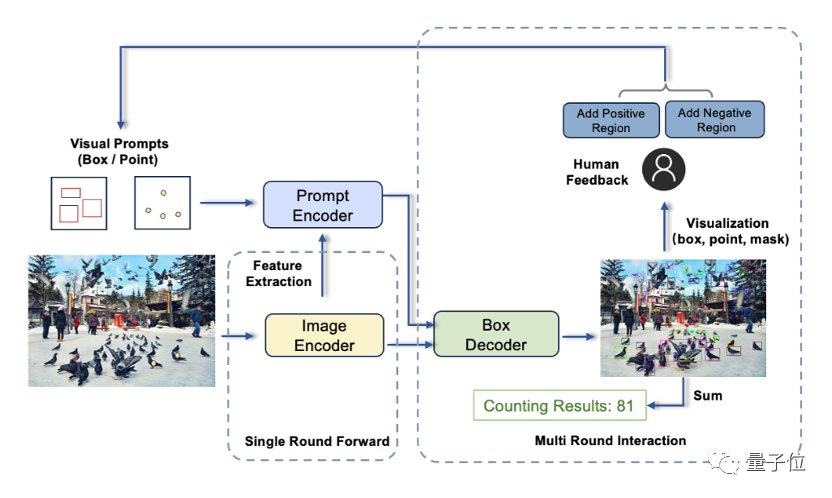
Diese Arbeit stammt vom Computer Vision and Robotics Research Center des IDEA Research Institute.
Das zuvor Open-Source-Zielerkennungsmodell DINO des Teams ist das erste DETR-Modell, das in der COCO-Zielerkennungsliste an erster Stelle steht. Der Zero-Sample-Detektor Grounding DINO ist auf Github sehr beliebt (es hat bisher 11.000 Sterne erhalten) und Geerdetes SAM, das alles erkennen und segmentieren kann. Für weitere technische Details klicken Sie bitte auf den Link am Ende des Artikels.
Die gesamte Konferenz ist voller nützlicher Informationen
Darüber hinaus wurden auf der IDEA-Konferenz auch mehrere Forschungsergebnisse hervorgehoben.
Zum Beispiel kombiniert das Think-on-Graph wissensgesteuerte große Modell, einfach ausgedrückt, große Modelle mit Wissensgraphen.
Große Modelle eignen sich gut für das Verständnis von Absichten und das autonome Lernen, während Wissensgraphen aufgrund ihrer strukturierten Methoden zur Wissensspeicherung besser für das Denken in logischen Ketten geeignet sind.
Think-on-Graph veranlasst den großen Modellagenten dazu, über den Wissensgraphen zu „denken“ und nach und nach die optimale Antwort zu suchen und daraus abzuleiten (suchen und begründen Sie Schritt für Schritt die zugehörigen Entitäten des Wissensgraphen). Bei jedem Schritt des Denkens ist das große Modell persönlich beteiligt und lernt mithilfe des Wissensgraphen von den Stärken und Schwächen des anderen.

MoonBit ist eine von Wasm betriebene Entwicklerplattform, die für Cloud Computing und Edge Computing entwickelt wurde.
Dieses System bietet nicht nur universelles Programmiersprachendesign, sondern integriert auch Compiler, Build-Systeme, integrierte Entwicklungsumgebungen (IDEs), Bereitstellungstools und andere Module, um die Entwicklungserfahrung und -effizienz zu verbessern
Das zuvor veröffentlichte wissenschaftliche Forschungsartefakt ReadPaper Außerdem wurde es auf 2.0 aktualisiert und auf der Pressekonferenz wurden neue Funktionen wie Lese-Copilot und Polier-Copilot demonstriert.

Am Ende der Pressekonferenz veröffentlichte Shen Xiangyang das „Weißbuch zur wirtschaftlichen Entwicklung in geringer Höhe (2.0) – vollständig digitale Lösung“, in dem er den zeitlichen räumlichen Prozess in seinem Smart Integrated Lower Airspace System (SILAS) vorschlug. Prozess) neues Konzept.
T-Rex-Link:
https://trex-counting.github.io/
Das obige ist der detaillierte Inhalt vonNutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was soll ich tun, wenn es beim Erstellen einer neuen Idee keine Servlet-Option gibt?
- Was ist die Tastenkombination, um in Idea zum vorherigen Schritt zurückzukehren?
- Welche Anwendungen gibt es für maschinelles Sehen im industriellen Bereich?
- So laden Sie den Code in der Idee auf Gitlab hoch
- Ein Artikel zum Verständnis der Lidar- und visuellen Fusionswahrnehmung des autonomen Fahrens