
Heim >Technologie-Peripheriegeräte >KI >Ein Artikel zum Verständnis der Lidar- und visuellen Fusionswahrnehmung des autonomen Fahrens
Ein Artikel zum Verständnis der Lidar- und visuellen Fusionswahrnehmung des autonomen Fahrens

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-16 12:11:451971Durchsuche
2022 ist das Zeitfenster für den Übergang von L2 zu L3/L4. Immer mehr Automobilhersteller haben begonnen, die Massenproduktion von intelligentem Fahren auf höherem Niveau zu planen.
Mit der technischen Verbesserung der Lidar-Hardware, der Massenproduktion auf Fahrzeugebene und der Kostensenkung haben intelligente Fahrfunktionen auf hohem Niveau die Massenproduktion von Lidar im Bereich der Personenkraftwagen vorangetrieben wird dieses Jahr ausgeliefert, und 2022 wird auch als „das erste Jahr von Lidar auf der Straße“ bezeichnet.
01 Lidar-Sensor vs. Bildsensor
Lidar ist ein Sensor, der zur genauen Erfassung der dreidimensionalen Position von Objekten verwendet wird. Es handelt sich im Wesentlichen um eine Lasererkennung und -entfernung. Mit seiner hervorragenden Leistung bei der Zielkonturmessung und der universellen Hinderniserkennung wird es zur Kernkonfiguration des autonomen L4-Fahrens.
Der Reichweitenmessbereich von Lidar (im Allgemeinen etwa 200 Meter, Serienmodelle verschiedener Hersteller haben unterschiedliche Indikatoren) führt jedoch zu einem Wahrnehmungsbereich, der viel kleiner ist als der von Bildsensoren.
Und aufgrund seiner relativ geringen Winkelauflösung (im Allgemeinen 0,1° oder 0,2°) ist die Auflösung der Punktwolke viel kleiner als die des Bildsensors. Bei der Erfassung der auf das Ziel projizierten Punkte aus großer Entfernung kann extrem spärlich sein. Für die Punktwolken-Zielerkennung beträgt die effektive Punktwolkenentfernung, die der Algorithmus wirklich nutzen kann, nur etwa 100 Meter.
Bildsensoren können komplexe Umgebungsinformationen mit hohen Bildraten und hohen Auflösungen erfassen und sind kostengünstig. Für die visuelle Wahrnehmung in unterschiedlichen Entfernungen und Entfernungen können mehrere Sensoren eingesetzt werden.
Der Bildsensor ist jedoch ein passiver Sensor mit unzureichender Tiefenwahrnehmung und schlechter Entfernungsgenauigkeit. Insbesondere in rauen Umgebungen erhöht sich die Schwierigkeit, Erfassungsaufgaben zu erfüllen.
Angesichts von starkem Licht, geringer Beleuchtung in der Nacht, Regen, Schnee, Nebel und anderen Wetter- und Lichtumgebungen stellt intelligentes Fahren hohe Anforderungen an Sensoralgorithmen. Obwohl Lidar nicht empfindlich auf den Einfluss von Umgebungslicht reagiert, wird die Entfernungsmessung durch wassergefüllte Straßen, Glaswände usw. stark beeinträchtigt.
Man erkennt, dass Lidar- und Bildsensoren jeweils ihre eigenen Vor- und Nachteile haben. Die meisten Personenkraftwagen mit intelligentem Fahrverhalten auf hohem Niveau entscheiden sich für die Integration verschiedener Sensoren, um die Vorteile der anderen zu ergänzen und redundant zu integrieren.
Eine solche Fused-Sensing-Lösung ist auch zu einer der Schlüsseltechnologien für autonomes Fahren auf hohem Niveau geworden.
02 Punktwolken- und Bildfusionswahrnehmung basierend auf Deep Learning
Die Fusion von Punktwolke und Bild gehört zum technischen Bereich der Multisensorfusion (MSF). Es gibt traditionelle Zufallsmethoden und Deep-Learning-Methoden. Entsprechend der Abstraktionsebene der Informationsverarbeitung im Fusionssystem ist sie hauptsächlich in drei Ebenen unterteilt:
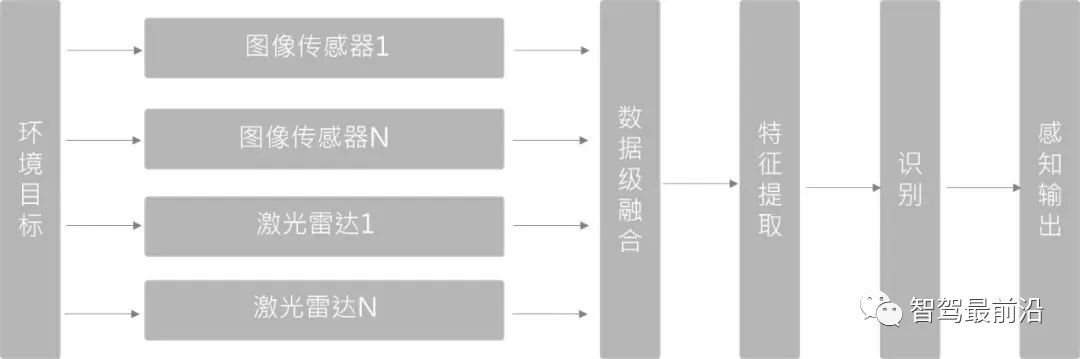
Datenschichtfusion (frühe Fusion)
Zuerst werden die Sensorbeobachtungsdaten fusioniert und Anschließend werden aus den fusionierten Daten Merkmale zur Identifizierung extrahiert. Bei der 3D-Zielerkennung übernimmt PointPainting (CVPR20) diese Methode. Die PointPainting-Methode führt zunächst eine semantische Segmentierung des Bildes durch, ordnet die segmentierten Merkmale der Punktwolke über eine Punkt-zu-Bild-Pixelmatrix zu und „zeichnet dann den Punkt“. Die Punktwolke wird an den 3D-Punktwolkendetektor gesendet, um eine Regression für die Zielbox durchzuführen.
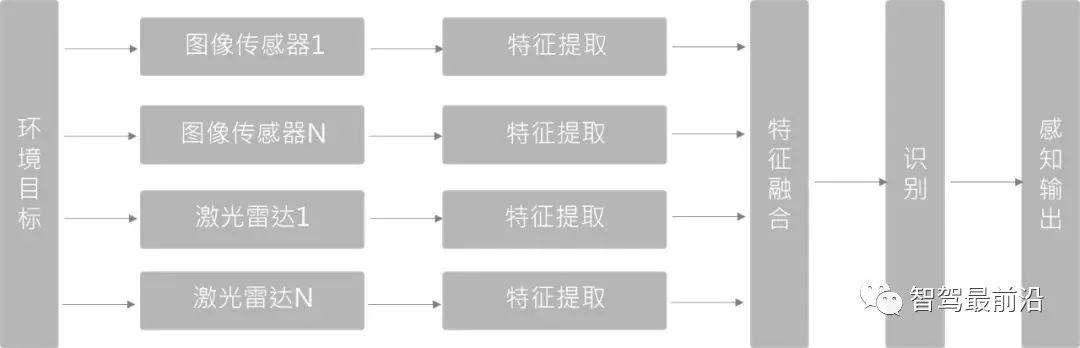
Feature-Layer-Fusion (Deep Fusion)
Extrahieren Sie zunächst natürliche Datenmerkmale aus den von jedem Sensor bereitgestellten Beobachtungsdaten und identifizieren Sie diese Merkmale dann nach der Fusion. Bei der auf Deep Learning basierenden Fusionsmethode verwendet diese Methode Merkmalsextraktoren sowohl für die Punktwolke als auch für den Bildzweig. Die Netzwerke des Bildzweigs und des Punktwolkenzweigs werden in der Vorwärts-Feedback-Ebene semantisch fusioniert, um eine Multifunktionalität zu erreichen. Skaleninformationen.
Die auf Deep Learning basierende Feature-Layer-Fusion-Methode stellt hohe Anforderungen an die räumlich-zeitliche Synchronisation zwischen mehreren Sensoren. Sobald die Synchronisierung nicht gut ist, wirkt sich dies direkt auf die Wirkung der Feature-Fusion aus. Gleichzeitig ist es aufgrund der Unterschiede im Maßstab und Betrachtungswinkel schwierig, den 1+1>2-Effekt der Merkmalsfusion zwischen LiDAR und Bildern zu erreichen.
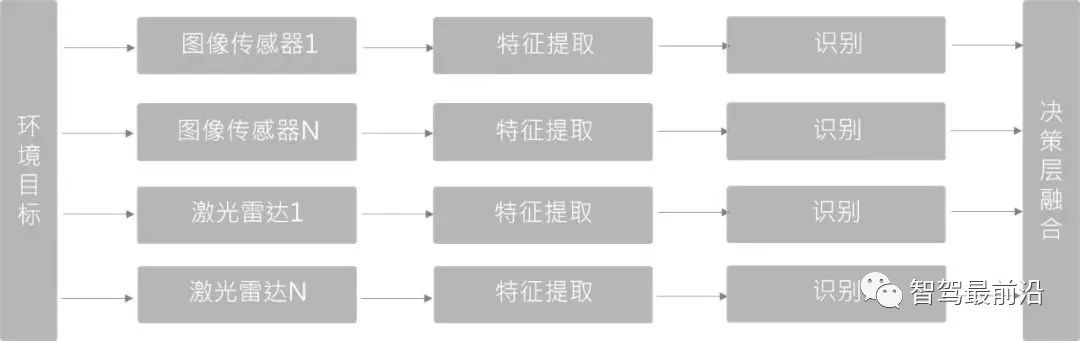
Entscheidende Schichtfusion (Late Fusion)
Im Vergleich zu den ersten beiden ist es die am wenigsten komplexe Fusionsmethode. Es erfolgt keine Fusion auf der Daten- oder Feature-Ebene, sondern es handelt sich um eine Fusion verschiedener Sensornetzwerkstrukturen, die sich gegenseitig nicht beeinflussen und unabhängig voneinander trainiert und kombiniert werden können.
Da die beiden Arten von Sensoren und Detektoren, die auf der Entscheidungsebene verschmolzen sind, unabhängig voneinander sind, kann bei einem Sensorausfall die Sensorredundanzverarbeitung weiterhin durchgeführt werden und die technische Robustheit ist besser.
Mit der kontinuierlichen Iteration der Lidar- und Visual-Fusion-Wahrnehmungstechnologie sowie der kontinuierlichen Anhäufung von Wissensszenarien und -fällen scheinen immer mehr Full-Stack-Fusion-Computing-Lösungen mehr Vorteile für die Autonomie zu bringen Autofahren. Eine sichere Zukunft.
Das obige ist der detaillierte Inhalt vonEin Artikel zum Verständnis der Lidar- und visuellen Fusionswahrnehmung des autonomen Fahrens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr