
Heim >Technologie-Peripheriegeräte >KI >Mit dem 8-Milliarden-Parameter OtterHD vermittelt Ihnen das chinesische Team der Nanyang Polytechnic die Erfahrung des Kamelzählens in „Entlang des Flusses während des Qingming-Festivals'.
Mit dem 8-Milliarden-Parameter OtterHD vermittelt Ihnen das chinesische Team der Nanyang Polytechnic die Erfahrung des Kamelzählens in „Entlang des Flusses während des Qingming-Festivals'.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-27 14:49:151072Durchsuche
Möchten Sie wissen, wie viele Kamele es in „Entlang des Flusses während des Qingming-Festivals“ gibt? Werfen wir einen Blick auf dieses multimodale Modell, das UHD-Eingabe unterstützt.
Kürzlich hat ein chinesisches Team von der Nanyang Polytechnic das multimodale Großmodell OtterHD mit 8 Milliarden Parametern auf Basis von Fuyu-8B gebaut.

Papieradresse: https://arxiv.org/abs/2311.04219
Im Gegensatz zu herkömmlichen Modellen, die auf visuelle Encoder mit fester Größe beschränkt sind, ist OtterHD-8B in der Lage, flexible Eingabegrößen zu verarbeiten. Dies gewährleistet seine Vielseitigkeit bei unterschiedlichen Argumentationsanforderungen.
Gleichzeitig schlug das Team auch einen neuen Benchmark-Test MagnifierBench vor, mit dem die Fähigkeit von LLM, kleinste Details und räumliche Beziehungen von Objekten in großformatigen Bildern zu unterscheiden, sorgfältig bewertet werden kann.
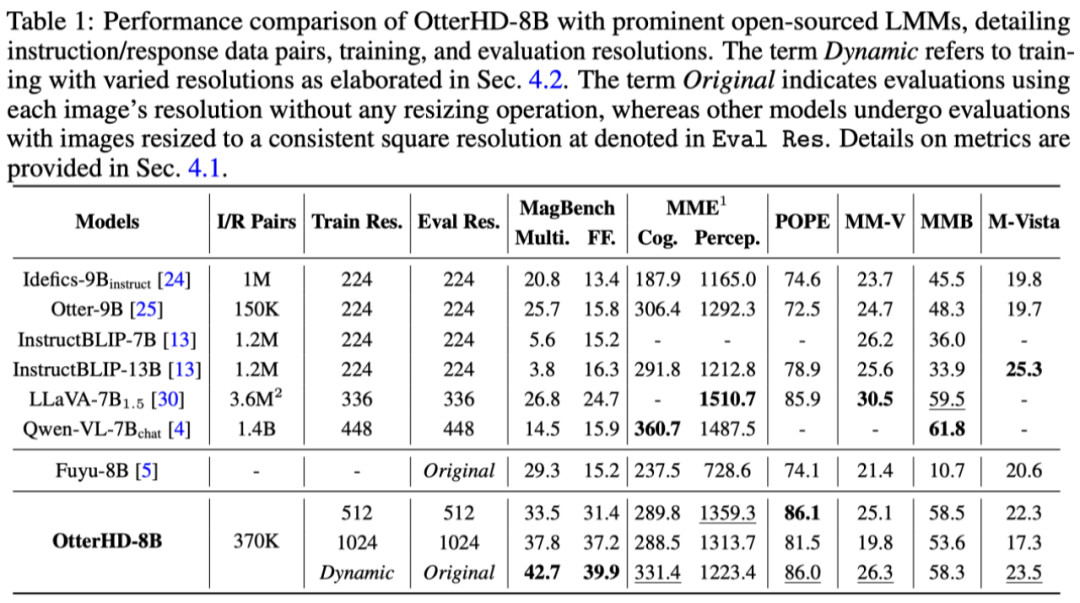
Experimentelle Ergebnisse zeigen, dass die Leistung von OtterHD-8B bei der direkten Verarbeitung hochauflösender Eingaben deutlich besser ist als bei ähnlichen Modellen Qingming-Fest (Wie viele Kamele gibt es in diesem Teil), die Bildeingabe erreicht 2446 x 1766 Pixel und das Modell kann die Frage erfolgreich beantworten.
Angesichts des Apfelzählproblems, das GPT4-V einst verwirrte, berechnete das Modell erfolgreich, dass es 11 Äpfel enthielt
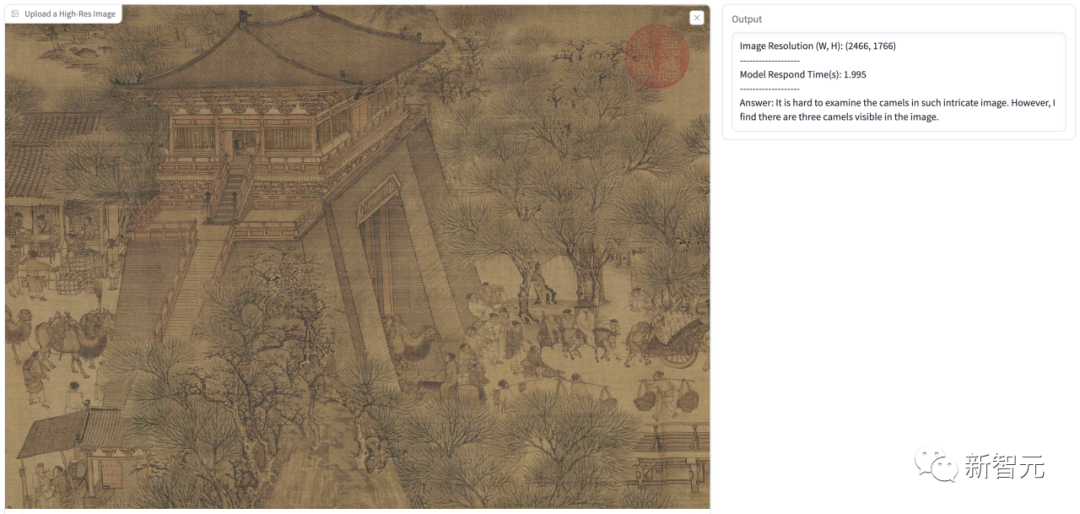
Zusätzlich zu der angezeigten hochauflösenden Eingabe Im Artikel haben wir beispielsweise auch einige Tests durchgeführt. In der folgenden Abbildung lassen wir das Modell davon ausgehen, dass der Benutzer ein Doktortitel der Universität Cambridge ist, und erklären, was diese Zahl bedeutet.
Die Antwort des Modells identifizierte die Informationen zum Schwarzen Loch und zum Weißen Loch im Bild genau, identifizierte es als tunnelartige Struktur und gab dann eine detaillierte Erklärung. 
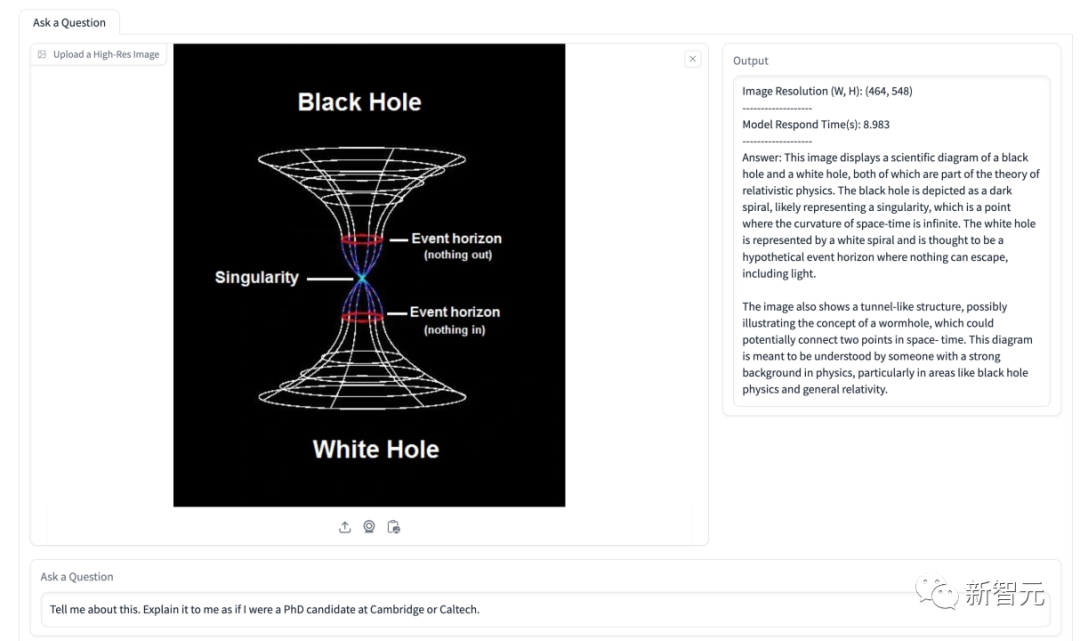
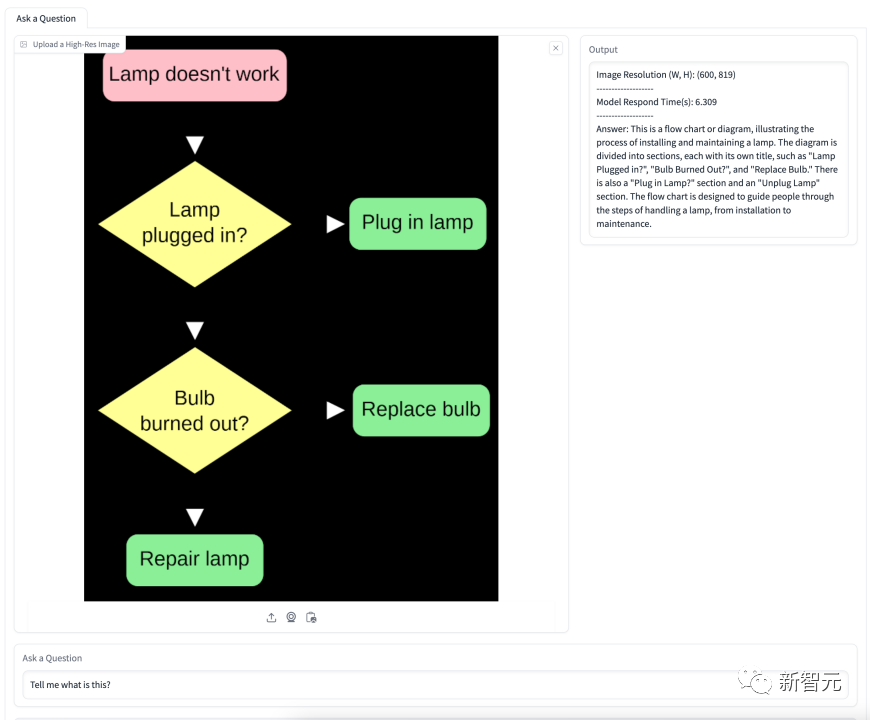
In der folgenden Tabelle wird das Modell gebeten, die Situation bezüglich des Energieanteils zu erläutern. Das Modell hat mehrere im Bild gezeigte Energiearten erfolgreich identifiziert und ihre Proportionen im Zeitverlauf genau dargestellt. Das folgende Flussdiagramm handelt vom Auswechseln einer Glühbirne. Schritt-für-Schritt-Anleitung. OtterHD-8B von Fuyu-8B Es lohnt sich Hinweis
Darüber hinaus kann es während der Inferenz weiter auf größere Auflösungen (z. B. 1440 × 1440) erweitert werden.
In Um diese Probleme zu lösen, führte das Team eine Feinabstimmung der Anweisungen durch, passte das Fuyu-Modell basierend auf 370.000 gemischten Daten an und verwies auf die ähnliche Anweisungsvorlage von LLaVA-1.5, um das Format der Modellantworten zu standardisieren
In der Schulung In dieser Phase werden alle Datensätze in Befehls-/Antwortpaaren organisiert, in einem einheitlichen Datenlader zusammengefasst und einheitlich abgetastet, um repräsentative Integrität sicherzustellen.
Um die Leistung des Modellierungscodes zu verbessern, übernahm das Team FlashAttention-2 und die Operator-Fusion-Technologie in der FlashAttention-Ressourcenbibliothek.
Mit Hilfe der vereinfachten Architektur von Fuyu, wie in Abbildung 2 dargestellt, wurden diese Änderungen erheblich vorgenommen verbessert Verbesserte GPU-Auslastung und -Durchsatz
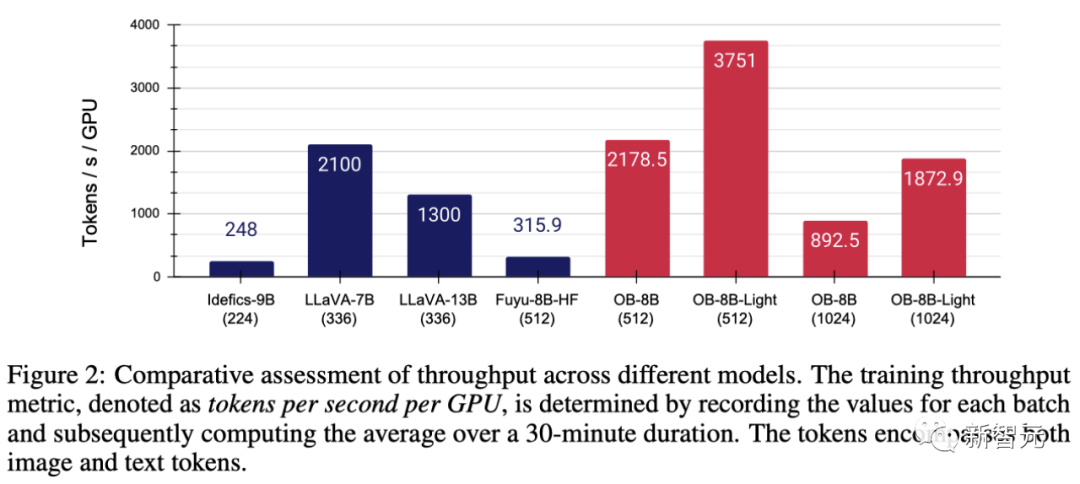
Konkret kann die vom Team vorgeschlagene Methode ein Vollparameter-Training mit einer Geschwindigkeit von 3 Stunden/Epoche auf einer 8×A100-GPU abschließen, während jede Epoche nur 1 Stunde benötigt.
Beim Training des Modells mit dem AdamW-Optimierer beträgt die Stapelgröße 64, die Lernrate ist auf 1×10^-5 eingestellt und der Gewichtsabfall beträgt 0,1.
Ultrafeiner Bewertungs-Benchmark MagnifierBench
Das menschliche visuelle System kann auf natürliche Weise die Details von Objekten im Sichtfeld wahrnehmen, aber die aktuellen Benchmarks, die zum Testen von LMMs verwendet werden, konzentrieren sich nicht speziell auf die Bewertung dieser Fähigkeit.
Mit der Einführung der Fuyu- und OtterHD-Modelle erweitern wir erstmals die Auflösung der Eingabebilder auf einen größeren Bereich.
Zu diesem Zweck erstellte das Team einen neuen Test-Benchmark MagnifierBench, der 166 Bilder und insgesamt 283 Fragensätze auf der Grundlage des Panoptic Scene Graph Generation (PVSG)-Datensatzes abdeckt.
Der PVSG-Datensatz besteht aus Videodaten, die eine große Anzahl komplexer und chaotischer Szenen enthalten, insbesondere Hausarbeitsvideos aus der ersten Person.
Während der Annotationsphase untersuchte das Team jedes Frage-Antwort-Paar im Datensatz sorgfältig und eliminierte diejenigen, bei denen es sich um große Objekte handelte oder die mit gesundem Menschenverstand leicht zu beantworten waren. Beispielsweise sind die meisten Fernbedienungen schwarz, was leicht zu erraten ist, aber Farben wie Rot und Gelb sind in dieser Liste nicht enthalten.
Wie in Abbildung 3 dargestellt, umfassen die von MagnifierBench entwickelten Fragetypen Erkennungs-, Zahlen- und farbbezogene Fragen usw. Ein wichtiges Kriterium für diesen Datensatz ist, dass die Fragen so komplex sein müssen, dass sich sogar der Annotator im Vollbildmodus befinden und sogar in das Bild hineinzoomen muss, um genau zu antworten.

LMM eignet sich besser für Konversationsantworten als für kurze Antwortumgebung zum Generieren erweiterter Antworten.
- Multiple-Choice-Fragen
Das Problem bei diesem Modell besteht darin, dass mehrere Optionen zur Auswahl stehen. Um das Modell bei der Auswahl eines Buchstabens (z. B. A, B, C) als Antwort anzuleiten, stellte das Team der Frage als Aufforderung einen Buchstaben aus einer bestimmten Auswahl voran. In diesem Fall gilt nur die Antwort als richtige Antwort, die genau mit der richtigen Option übereinstimmt
- Offene Frage
Mehrere Optionen vereinfachen die Aufgabe, da zufälliges Raten eine Chance von 25 % hat, richtig zu sein . Darüber hinaus spiegelt dies nicht die realen Szenarien wider, mit denen Chat-Assistenten konfrontiert sind, da Benutzer dem Modell normalerweise keine vordefinierten Optionen zur Verfügung stellen. Um diese potenzielle Verzerrung zu beseitigen, stellte das Team den Modellfragen außerdem auf unkomplizierte, offene Weise und ohne Eingabeaufforderungen.
Experimentelle Analyse
Forschungsergebnisse zeigen, dass viele Modelle zwar bei etablierten Benchmarks wie MME und POPE hohe Werte erzielen, ihre Leistung bei MagnifierBench jedoch oft unbefriedigend ist. Der OtterHD-8B hingegen schnitt beim MagnifierBench gut ab.
Um den Effekt einer Erhöhung der Auflösung weiter zu untersuchen und die Generalisierungsfähigkeit von OtterHD bei verschiedenen, möglicherweise höheren Auflösungen zu testen, trainierte das Team Otter8B mit festen oder dynamischen Auflösungen
x-Achse. Es zeigt, dass mit zunehmender Auflösung Es werden mehr Bild-Tokens an den Sprachdecoder gesendet, wodurch mehr Bilddetails bereitgestellt werden.
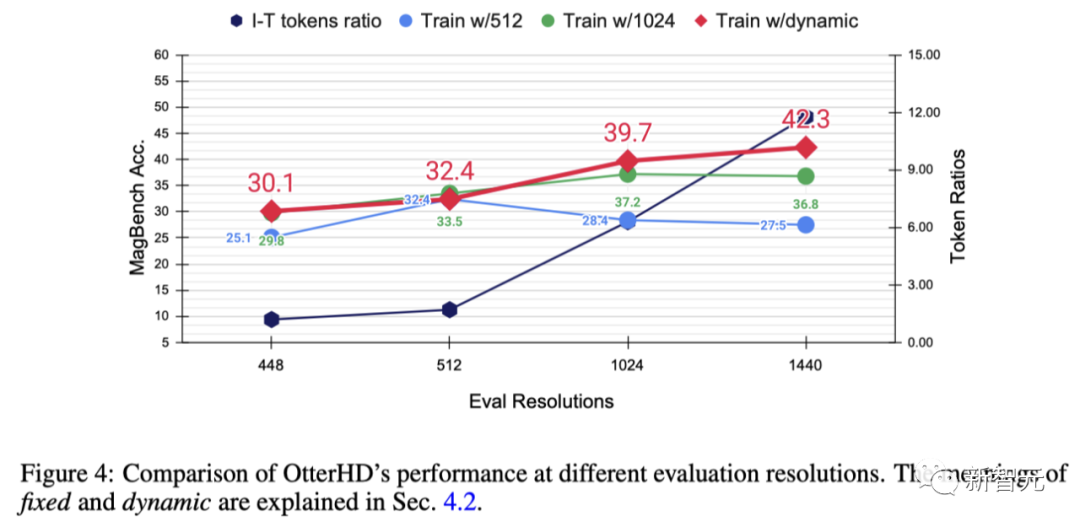
Experimentelle Ergebnisse zeigen, dass sich mit zunehmender Auflösung auch die Leistung von MagnifierBench entsprechend verbessert
Mit zunehmender Auflösung nimmt das Verhältnis von Bildern zu Text allmählich zu. Dies liegt daran, dass die durchschnittliche Anzahl der Text-Tokens gleich bleibt
Diese Änderung unterstreicht die Bedeutung der LMM-Auflösung, insbesondere für Aufgaben, die komplexe visuelle Assoziationen erfordern.

Darüber hinaus verdeutlicht der Leistungsunterschied zwischen festen und dynamischen Trainingsmethoden die Vorteile der dynamischen Größenänderung, insbesondere bei der Verhinderung einer Überanpassung bei bestimmten Auflösungen.
Ein weiterer Vorteil der dynamischen Strategie besteht darin, dass sie es dem Modell ermöglicht, sich an höhere Auflösungen (1440) anzupassen, auch wenn dies während des Trainings nicht gesehen wurde
Einige Vergleiche




Fazit
Basierend auf der innovativen Architektur von Fuyu-8B schlug das Forschungsteam das OtterHD-8B-Modell vor, das Bilder verschiedener Auflösungen effektiv verarbeiten und die meisten davon entfernen kann LMM-Probleme Einschränkungen bei Eingaben mit fester Auflösung
Mittlerweile zeichnet sich der OtterHD-8B durch die Verarbeitung hochauflösender Bilder aus
Dies wird insbesondere im neuen MagnifierBench-Benchmark deutlich. Der Zweck dieses Benchmarks besteht darin, die Fähigkeit des LMM zu bewerten, Details in komplexen Szenen zu erkennen, und die Bedeutung einer flexibleren Unterstützung für verschiedene Auflösungen hervorzuheben
Das obige ist der detaillierte Inhalt vonMit dem 8-Milliarden-Parameter OtterHD vermittelt Ihnen das chinesische Team der Nanyang Polytechnic die Erfahrung des Kamelzählens in „Entlang des Flusses während des Qingming-Festivals'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierter Code für Schulungsfragen zur Grundanweisung der MySQL-Datenbank
- Detaillierte Erläuterung des PyTorch-Batch-Trainings und des Optimierervergleichs
- Was ist ein KI-Trainingscluster?
- Was sind die vier Grundmerkmale von Big Data?
- Bard wurde auf ChatGPT-Daten geschult? Die Top-Wissenschaftler von Google protestierten erfolglos und verließen OpenAI