Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, in dem hauptsächlich Probleme im Zusammenhang mit dem Lesen von PDF-Dateien durch PDFPlumber und dem Schreiben in Excel vorgestellt werden, einschließlich der Installation des PDFPlumber-Moduls, dem Laden von PDF und einigen praktischen Vorgängen usw. Schauen wir uns das gemeinsam an , ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Python-Video-Tutorial
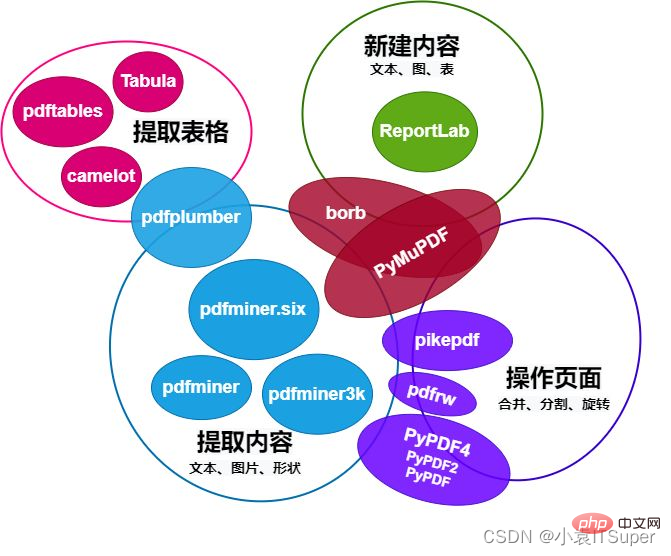
1. Vergleich von 13 wichtigen Bibliotheken für den Betrieb von PDF in Python
PDF (Portable Document Format) ist ein tragbares Dokumentformat, das die Verbreitung von Dokumenten über Betriebssysteme hinweg erleichtert. PDF-Dokumente folgen einem Standardformat, daher gibt es viele Tools, die PDF-Dokumente bearbeiten können, und Python bildet da keine Ausnahme.
Die Vergleichstabelle des Python-Betriebs-PDF-Moduls lautet wie folgt:
Dieser Artikel stellt hauptsächlich pdfplumber vor und konzentriert sich auf die Extraktion von PDF-Inhalten wie Text (Position, Schriftart und Farbe usw.) und Form (Rechteck, gerade Linie, Kurve) sowie die Funktion zum Parsen von Tabellen. pdfplumber专注PDF内容提取,例如文本(位置、字体及颜色等)和形状(矩形、直线、曲线),还有解析表格的功能。
二、pdfplumber模块
其他几个 Python 库帮助用户从 PDF 中提取信息。作为一个广泛的概述,pdfplumber它通过结合以下功能将自己与其他 PDF 处理库区分开来:
- 轻松访问有关每个 PDF 对象的详细信息
- 用于提取文本和表格的更高级别、可自定义的方法
- 紧密集成的可视化调试
- 其他有用的实用功能,例如通过裁剪框过滤对象
1. 安装
cmd控制台输入:
pip install pdfplumber
导包:
import pdfplumber
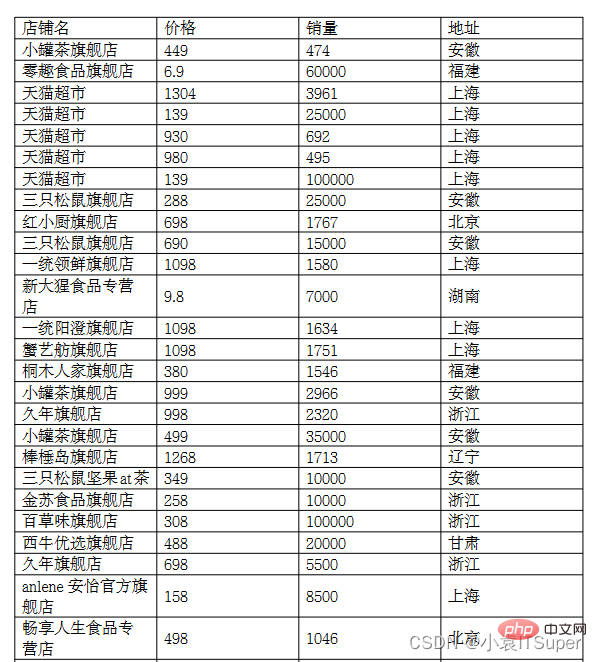
案例PDF截图(两页未截全):
2. 加载PDF
读取PDF代码:pdfplumber.open("路径/文件名.pdf", password = "test", laparams = { "line_overlap": 0.7 })
参数解读:
-
password :要加载受密码保护的 PDF,请传递password关键字参数
-
laparams:要将布局分析参数设置为pdfminer.six的布局引擎,请传递laparams关键字参数
案例代码:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf)
print(type(pdf))
输出结果:
<pdfplumber.pdf.pdf><class></class></pdfplumber.pdf.pdf>
3. pdfplumber.PDF类
pdfplumber.PDF类表示单个 PDF,并具有两个主要属性:
| 属性 |
说明 |
.metadata |
从PDF的Info中获取元数据键 /值对字典。 通常包括“ CreationDate”,“ ModDate”,“ Producer”等。 |
.pages |
返回一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息 |
1. 读取PDF文档信息(.metadata):
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf.metadata)
运行结果:
{'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}
2. 输出总页数
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(len(pdf.pages))
运行结果:
2
4. pdfplumber.Page类
pdfplumber.Page类是pdfplumber整个的核心,大多数操作都围绕这个类进行操作,它具有以下几个属性:
| 属性 |
说明 |
.page_number |
顺序页码,从1第一页开始,从第二页开始2,依此类推。 |
.width |
页面的宽度。 |
.height |
页面的高度。 |
.objects/.chars/.lines/.rects/.curves/.figures/.images |
这些属性中的每一个都是一个列表,每个列表包含一个字典,用于嵌入页面上的每个此类对象。有关详细信息,请参阅下面的“对象”。 |
常用方法如下:
| 方法名 |
说明 |
.extract_text() |
用来提页面中的文本,将页面的所有字符对象整理为的那个字符串 |
.extract_words() |
返回的是所有的单词及其相关信息 |
.extract_tables() |
提取页面的表格 |
.to_image() |
用于可视化调试时,返回PageImage类的一个实例 |
.close() | 2. pdfplumber-Modul | Mehrere andere Python-Bibliotheken helfen Benutzern, Informationen aus PDFs zu extrahieren. Im Großen und Ganzen unterscheidet sich pdfplumber von anderen PDF-Verarbeitungsbibliotheken durch die Kombination der folgenden Funktionen:
- Einfacher Zugriff auf detaillierte Informationen zu jedem PDF-Objekt
- Zur Extraktion Höherstufige, anpassbare Ansätze zu Text und Tabellen
- Enge integrierte visuelle Fehlersuche
- Weitere nützliche Hilfsfunktionen, wie zum Beispiel das Filtern von Objekten nach Zuschneidefeldern
ul>
1 cmd-Konsoleneingabe:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
# 查看页码
print('页码:', first_page.page_number)
# 查看页宽
print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)🎜Guide-Paket: 🎜
页码: 1页宽: 595.3页高: 841.9
🎜Fall-PDF-Screenshot (zwei Seiten sind nicht abgeschnitten):

🎜🎜2. PDF laden🎜🎜PDF-Code lesen:
pdfplumber.open(" path/filename.pdf", password = " test", laparams = { "line_overlap": 0.7 })🎜🎜Parameterinterpretation:🎜
-
password : erforderlich Um ein passwortgeschütztes PDF zu laden, übergeben Sie das Passwort Schlüsselwortargument
-
laparams: Um die Layout-Analyseparameter auf die Layout-Engine von pdfminer.six festzulegen, übergeben Sie das Schlüsselwortargument laparams
🎜Fallcode: 🎜
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
text = first_page.extract_text()
print(text)🎜Ausgabeergebnis: 🎜
店铺名 价格 销量 地址
小罐茶旗舰店 449 474 安徽
零趣食品旗舰店 6.9 60000 福建
天猫超市 1304 3961 上海
天猫超市 139 25000 上海
天猫超市 930 692 上海
天猫超市 980 495 上海
天猫超市 139 100000 上海
三只松鼠旗舰店 288 25000 安徽
红小厨旗舰店 698 1767 北京
三只松鼠旗舰店 690 15000 安徽
一统领鲜旗舰店 1098 1580 上海
新大猩食品专营9.8 7000 湖南.......舰店
蟹纳旗舰店 498 1905 上海
三只松鼠坚果at茶 188 35000 安徽
嘉禹沪晓旗舰店 598 1517 上海
🎜3. pdfplumber.PDF-Klasse🎜🎜
pdfplumber.PDF-Klasse stellt ein einzelnes PDF dar und hat zwei Haupteigenschaften: 🎜
| Attribut |
Beschreibung | 🎜
🎜.metadata code>🎜🎜Get metadata <code>key/value Paare-Wörterbuch aus den PDF-Infos. Enthält normalerweise „CreationDate“, „ModDate“, „Produzent“ usw. 🎜🎜
🎜.pages🎜🎜Gibt eine Liste mit pdfplumber.Page-Instanzen zurück. Jede Instanz repräsentiert die Informationen jeder Seite des PDF🎜🎜🎜🎜🎜1 PDF-Dokument lesen Informationen (.metadata): 🎜import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
page_one = pdf.pages[0] # PDF第一页
table_1 = page_one.extract_table() # 读取表格数据
# 1. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 2. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3. 自定义列名
col1 = table_1[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 4. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 5. 将数据写进sheet表单中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 6. 保存文件分两种格式
workbook.save('test.xls')🎜Laufergebnis: 🎜import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
# 1. 把所有页的数据存在一个临时列表中
item = []
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')🎜Gesamtzahl der Seiten ausgeben🎜import pdfplumber
import xlwt
import os
# 一、获取文件下所有pdf文件路径
file_dir = r'E:\Python学习\pdf文件'
file_list = []
for files in os.walk(file_dir):
# print(files)
# ('E:\Python学习\pdf文件', [],
# ['1.pdf', '1的副本.pdf', '1的副本10.pdf', '1的副本11.pdf', '1的副本2.pdf', '1的副本3.pdf', '1的副本4.pdf', '1的副本5.pdf', '1的副本6.pdf',
# '1的副本7.pdf', '1的副本8.pdf', '1的副本9.pdf'])
for file in files[2]:
# 以. 进行分割如果后缀为PDF或pdf就拼接地址存入file_list
if file.split(".")[1] == 'pdf' or file.split(".")[1] == 'PDF':
file_list.append(file_dir + '\' + file)
# 二、存入Excel
# 1. 把所有PDF文件的所有页的数据存在一个临时列表中
item = []
for file_path in file_list:
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')🎜Laufergebnis: 🎜rrreee🎜4 . pdfplumber.Page-Klasse 🎜🎜pdfplumber-Klasse ist der Kern von pdfplumber. Sie hat die folgenden Attribute: 🎜
| Attribut |
Beschreibung | 🎜
🎜.page_number🎜🎜Fortlaufende Seitennummer, beginnend mit 1. Beginnen Sie mit Seite eins, beginnen Sie mit Seite 2 und so weiter. 🎜🎜
🎜.width🎜🎜Die Breite der Seite. 🎜🎜
🎜.height🎜🎜Die Höhe der Seite. 🎜🎜
🎜.objects/.chars/.lines/.rects/.curves/.figures/.images🎜🎜Jede dieser Eigenschaften ist eine Liste, jede Liste enthält ein Wörterbuch für jede Ein solches Objekt ist auf der Seite eingebettet. Einzelheiten finden Sie weiter unten unter „Objekte“. 🎜🎜🎜🎜🎜Häufig verwendete Methoden sind wie folgt: 🎜
| Methodenname |
Beschreibung | 🎜
🎜.extract_text()🎜🎜 wird verwendet, um den Text auf der Seite zu extrahieren und alle Zeichenobjekte auf der Seite in der Zeichenfolge zu organisieren🎜🎜🎜.extract_words()🎜🎜gibt alle Wörter und ihre zugehörigen Informationen zurück🎜🎜
🎜.extract_tables()🎜🎜Extrahieren Sie die Tabelle der Seite🎜🎜
🎜.to_image() 🎜🎜Gibt eine Instanz der PageImage-Klasse zurück, wenn sie zum visuellen Debuggen verwendet wird🎜🎜
🎜.close()🎜🎜Standardmäßig , Seite Ein Objekt speichert sein Layout und seine Objektinformationen zwischen, um eine erneute Verarbeitung zu vermeiden. Allerdings können diese zwischengespeicherten Eigenschaften beim Parsen großer PDF-Dateien viel Speicher beanspruchen. Mit dieser Methode können Sie den Cache leeren und Speicher freigeben. 🎜🎜🎜🎜1. 读取第一页宽度、高度等信息
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
# 查看页码
print('页码:', first_page.page_number)
# 查看页宽
print('页宽:', first_page.width)
# 查看页高
print('页高:', first_page.height)
运行结果:
页码: 1页宽: 595.3页高: 841.9
2. 读取文本第一页
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
first_page = pdf.pages[0] # pdfplumber.Page对象的第一页
text = first_page.extract_text()
print(text)
运行结果:
店铺名 价格 销量 地址
小罐茶旗舰店 449 474 安徽
零趣食品旗舰店 6.9 60000 福建
天猫超市 1304 3961 上海
天猫超市 139 25000 上海
天猫超市 930 692 上海
天猫超市 980 495 上海
天猫超市 139 100000 上海
三只松鼠旗舰店 288 25000 安徽
红小厨旗舰店 698 1767 北京
三只松鼠旗舰店 690 15000 安徽
一统领鲜旗舰店 1098 1580 上海
新大猩食品专营9.8 7000 湖南.......舰店
蟹纳旗舰店 498 1905 上海
三只松鼠坚果at茶 188 35000 安徽
嘉禹沪晓旗舰店 598 1517 上海
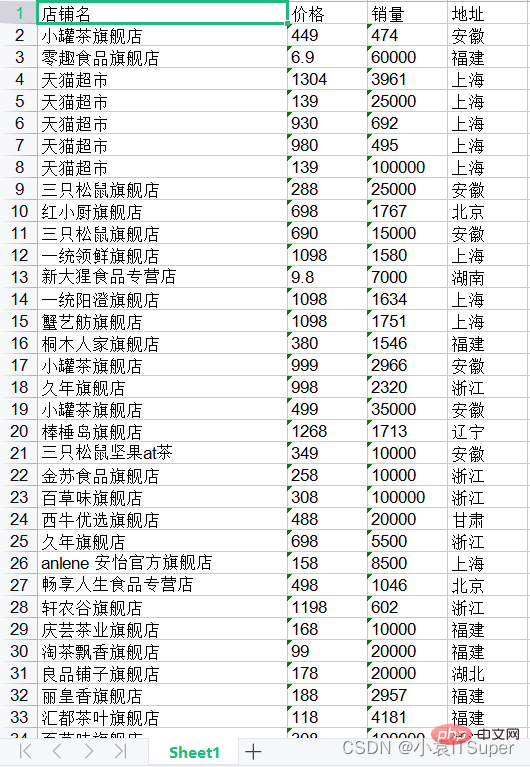
3. 读取表格第一页
import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
page_one = pdf.pages[0] # PDF第一页
table_1 = page_one.extract_table() # 读取表格数据
# 1. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 2. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3. 自定义列名
col1 = table_1[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 4. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 5. 将数据写进sheet表单中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 6. 保存文件分两种格式
workbook.save('test.xls')
运行结果:
三、实战操作
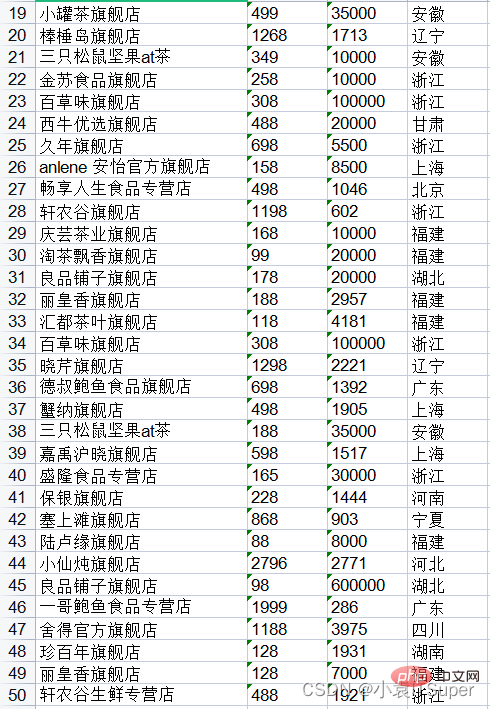
1. 提取单个PDF全部页数
测试代码:
import pdfplumberimport xlwtwith pdfplumber.open("1.pdf") as pdf:
# 1. 把所有页的数据存在一个临时列表中
item = []
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')
运行结果(上面得没截全):
2. 批量提取多个PDF文件
测试代码:
import pdfplumber
import xlwt
import os
# 一、获取文件下所有pdf文件路径
file_dir = r'E:\Python学习\pdf文件'
file_list = []
for files in os.walk(file_dir):
# print(files)
# ('E:\\Python学习\\pdf文件', [],
# ['1.pdf', '1的副本.pdf', '1的副本10.pdf', '1的副本11.pdf', '1的副本2.pdf', '1的副本3.pdf', '1的副本4.pdf', '1的副本5.pdf', '1的副本6.pdf',
# '1的副本7.pdf', '1的副本8.pdf', '1的副本9.pdf'])
for file in files[2]:
# 以. 进行分割如果后缀为PDF或pdf就拼接地址存入file_list
if file.split(".")[1] == 'pdf' or file.split(".")[1] == 'PDF':
file_list.append(file_dir + '\\' + file)
# 二、存入Excel
# 1. 把所有PDF文件的所有页的数据存在一个临时列表中
item = []
for file_path in file_list:
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
text = page.extract_table()
for i in text:
item.append(i)
# 2. 创建Excel表对象
workbook = xlwt.Workbook(encoding='utf8')
# 3. 新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 4. 自定义列名
col1 = item[0]
# print(col1)# ['店铺名', '价格', '销量', '地址']
# 5. 将列属性元组col写进sheet表单中第一行
for i in range(0, len(col1)):
worksheet.write(0, i, col1[i])
# 6. 将数据写进sheet表单中
for i in range(0, len(item[1:])):
data = item[1:][i]
for j in range(0, len(col1)):
worksheet.write(i + 1, j, data[j])
# 7. 保存文件分两种格式
workbook.save('test.xls')
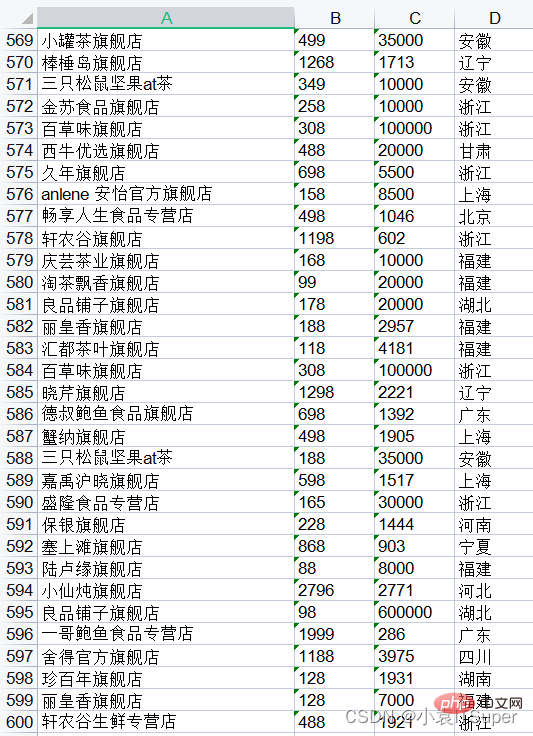
运行结果(12个文件,一个文件50行总共600行):
推荐学习:python视频教程
Das obige ist der detaillierte Inhalt vonPython-Beispiel, ausführliche Erklärung von pdfplumber zum Lesen von PDF-Dateien und zum Schreiben in Excel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

