
Heim >Backend-Entwicklung >Python-Tutorial >Python-Automatisierungspraxis für das Screening von Lebensläufen
Python-Automatisierungspraxis für das Screening von Lebensläufen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-06-07 18:59:263651Durchsuche
Dieser Artikel bringt Ihnen relevantes Wissen über Python, in dem hauptsächlich Probleme im Zusammenhang mit der Lebenslaufprüfung vorgestellt werden, einschließlich der Definition der ReadDoc-Klasse zum Lesen von Word-Dateien und der Definition der search_word-Funktion zum Filtern. Schauen wir uns das gemeinsam an, ich hoffe, das wird der Fall sein allen hilfreich sein. Y Empfohlenes Lernen: tPython-Video-Tutorial
 Lebenslauf-Screening
Lebenslauf-Screening
Lebenslauf Zugehörige Informationen lauten wie folgt:
Definieren Sie die Readdoc-Klasse zum Lesen von Word-Dateien Kenntnis der Bedingungen:
Kenntnis der Bedingungen:
.
Um Lebensläufe zu finden, die bestimmte Schlüsselwörter enthalten (z. B. Python, Java)
Implementierungsidee:
Lesen Sie jede Wortdatei stapelweise (Wortinformationen über Glob erhalten), erhalten Sie den gesamten lesbaren Inhalt und übergeben Sie den Schlüsselwortfilter nach Methode zum Abrufen der Ziel-Lebenslaufadresse.
这里有个需要注意的地方就是,并不是所有的 "简历" 都是以段落的形式呈现的,比如从 "猎聘" 网下载下来的简历就是 "表格形式" 的,而 "boss" 上下载的简历就是 "段落形式" 的,这里再进行读取的时候需要注意下,我们做的演示脚本练习就是 "表格形式" 的。
这里的话,我们就可以专门定义一个 "ReadDoc" 的类,里面定义两个函数,分别用于读取 "段落" 和 "表格" 。
实操案例脚本如下:
# coding:utf-8from docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件 def __init__(self, path): # 构造函数默认传入读取 word 文件的路径 self.doc = Document(path) self.p_text = '' self.table_text = '' self.get_para() self.get_table() def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落 for p in self.doc.paragraphs: self.p_text += p.text + '\n' # 读取的段落内容进行换行 print(self.p_text) def get_table(self): # 定义 get_table 函数循环读取表格内容 for table in self.doc.tables: for row in table.rows: _cell_str = '' # 获取每一行的完整信息 for cell in row.cells: _cell_str += cell.text + ',' # 每一行加一个 "," 隔开 self.table_text += _cell_str + '\n' # 读取的表格内容进行换行 print(self.table_text)if __name__ == '__main__': path = glob.os.path.join(glob.os.getcwd(), 'test_file/简历1.docx') doc = ReadDoc(path) print(doc)
看一下 ReadDoc
Hier ist zu beachten, dass nicht alle „Lebensläufe“ in Form von Absätzen dargestellt werden. Beispielsweise liegt der von der „Liepin“-Website heruntergeladene Lebenslauf in „Tabellenform“ vor und der heruntergeladene Lebenslauf von „Chef“ liegt in „Absatzform“ vor. Wenn Sie es hier lesen, müssen Sie darauf achten, dass die Demonstrationsskriptübung in „Tabellenform“ vorliegt. 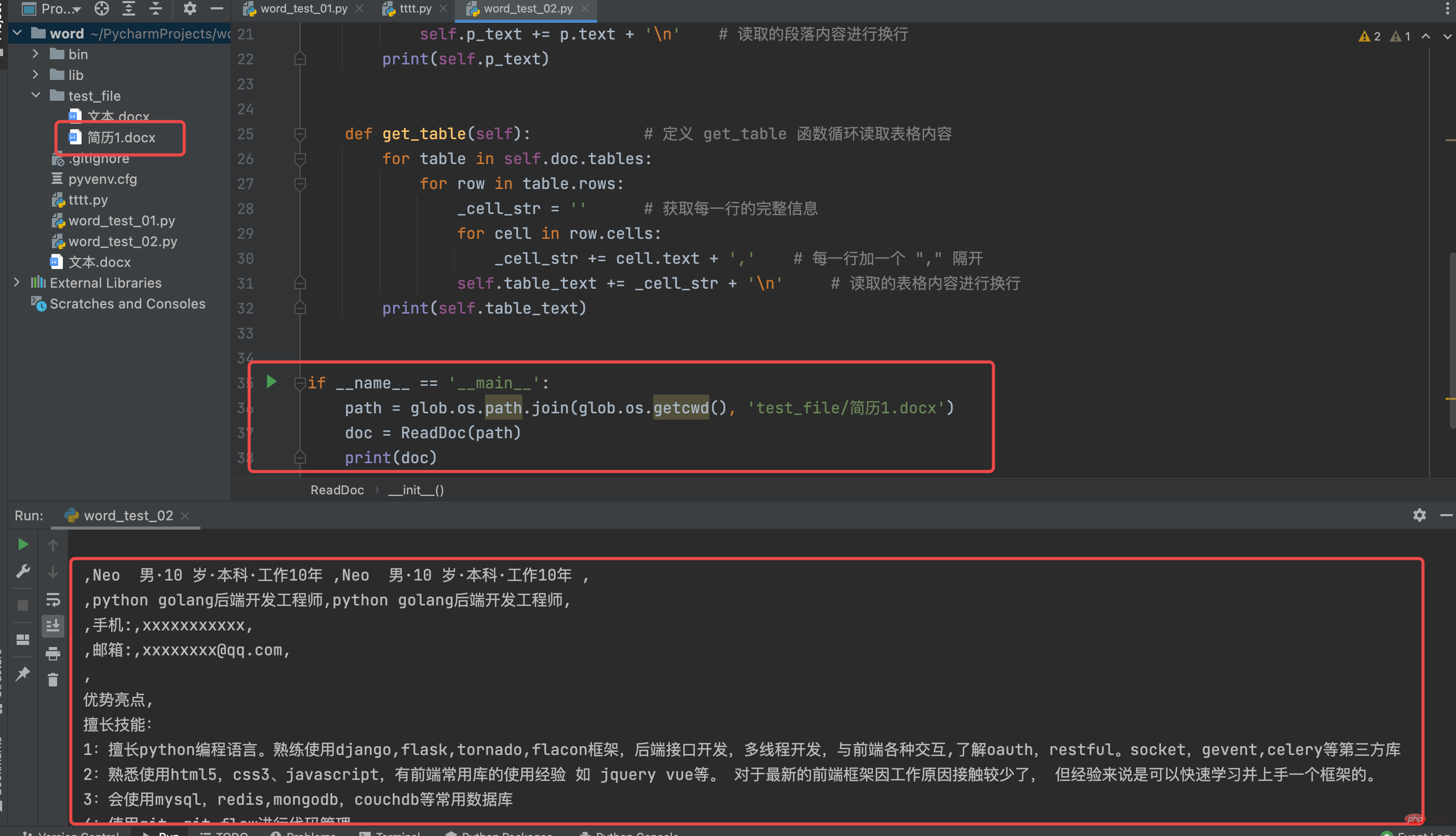
Hier können wir speziell eine „ReadDoc“-Klasse definieren, die zwei Funktionen zum Lesen von „Absätzen“ und „Tabellen“ definiert. Das praktische Fallskript lautet wie folgt:
# coding:utf-8import globfrom docx import Documentclass ReadDoc(object): # 定义一个 ReadDoc ,用以读取 word 文件
def __init__(self, path): # 构造函数默认传入读取 word 文件的路径
self.doc = Document(path)
self.p_text = ''
self.table_text = ''
self.get_para()
self.get_table()
def get_para(self): # 定义 get_para 函数用以读取 word 文件的段落
for p in self.doc.paragraphs:
self.p_text += p.text + '\n' # 读取的段落内容进行换行
# print(self.p_text) # 调试打印输出 word 文件的段落内容
def get_table(self): # 定义 get_table 函数循环读取表格内容
for table in self.doc.tables:
for row in table.rows:
_cell_str = '' # 获取每一行的完整信息
for cell in row.cells:
_cell_str += cell.text + ',' # 每一行加一个 "," 隔开
self.table_text += _cell_str + '\n' # 读取的表格内容进行换行
# print(self.table_text) # 调试打印输出 word 文件的表格内容def search_word(path, targets): # 定义 search_word 用以筛选符合内容的简历;传入 path 与 targets(targets 为列表)
result = glob.glob(path)
final_result = [] # 定义一个空列表,用以后续存储文件的信息
for i in result: # for 循环获取 result 内容
isuse = True # 是否可用
if glob.os.path.isfile(i): # 判断是否是文件
if i.endswith('.docx'): # 判断文件后缀是否是 "docx" ,若是,则利用 ReadDoc类 实例化该文件对象
doc = ReadDoc(i)
p_text = doc.p_text # 获取 word 文件内容
table_text = doc.table_text
all_text = p_text + table_text for target in targets: # for 循环判断关键字信息内容是否存在
if target not in all_text:
isuse = False
break
if not isuse:
continue
final_result.append(i)
return final_resultif __name__ == '__main__':
path = glob.os.path.join(glob.os.getcwd(), '*')
result = search_word(path, ['python', 'golang', 'react', '埋点']) # 埋点是为了演示效果,故意在 "简历1.docx" 加上的
print(result)
Sehen Sie sich die laufenden Ergebnisse der Klasse ReadDoc an
Definieren Sie die Funktion „search_word“ zum Filtern Der Inhalt der Word-Dateien, die mit dem gewünschten Lebenslauf übereinstimmen 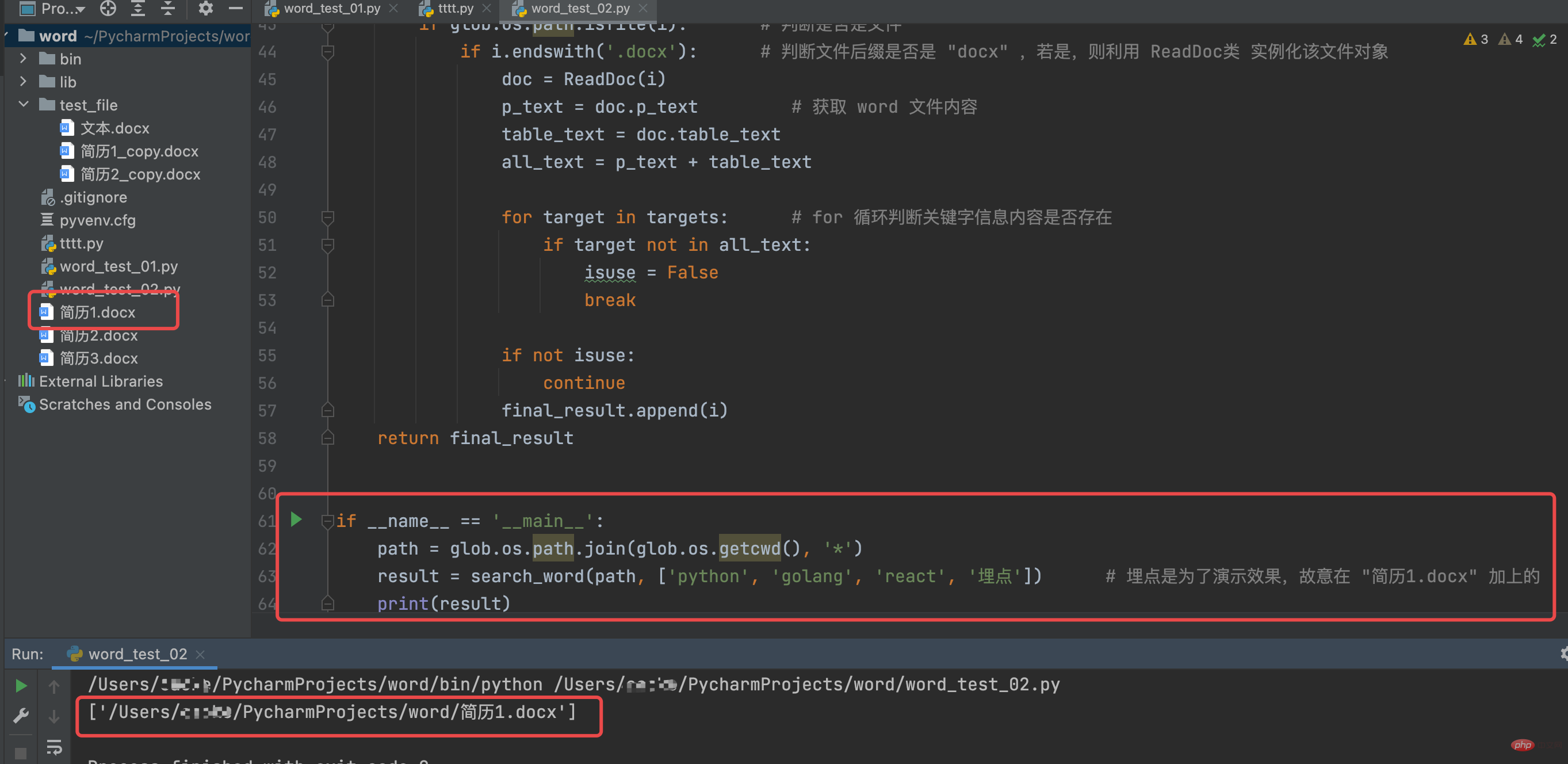
Das praktische Fallskript lautet wie folgt: rrreeeDie laufenden Ergebnisse lauten wie folgt:
🎜🎜🎜🎜🎜🎜Empfohlenes Lernen: 🎜Python-Video-Tutorial🎜🎜Das obige ist der detaillierte Inhalt vonPython-Automatisierungspraxis für das Screening von Lebensläufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Einführung in das Numpy-Modul von Python
- Wir stellen sechs super einfach zu verwendende integrierte Python-Funktionen vor
- Detaillierte grafische Erklärung, wie man Python zum Zeichnen dynamischer Visualisierungsdiagramme verwendet
- Python-Zeichen und -Listen einfach lernen (detaillierte Beispiele)
- Detaillierte Beispiele der vier objektorientierten Funktionen von Python