



5月初,白宫与谷歌、微软、OpenAI、Anthropic等AI公司的CEO们开了个会,针对AI生成技术的爆发,讨论技术背后隐藏的风险、如何负责任地开发人工智能系统,以及制定有效的监管措施。

现有的安全评估过程通常依赖于一系列评估基准(evaluation benchmarks)来识别AI系统的异常行为,比如误导性陈述、有偏见的决策或是输出受版权保护的内容。
而随着AI技术的日益强大,相应的模型评估工具也必须升级,防止开发出具有操纵、欺骗或其他高危能力的AI系统。
最近,Google DeepMind、剑桥大学、牛津大学、多伦多大学、蒙特利尔大学、OpenAI、Anthropic等多所顶尖高校和研究机构联合发布了一个用于评估模型安全性的框架,有望成为未来人工智能模型开发和部署的关键组件。

论文链接:https://arxiv.org/pdf/2305.15324.pdf
通用AI系统的开发人员必须评估模型的危险能力和对齐性,尽早识别出极端风险,从而让训练、部署、风险描述等过程更负责任。
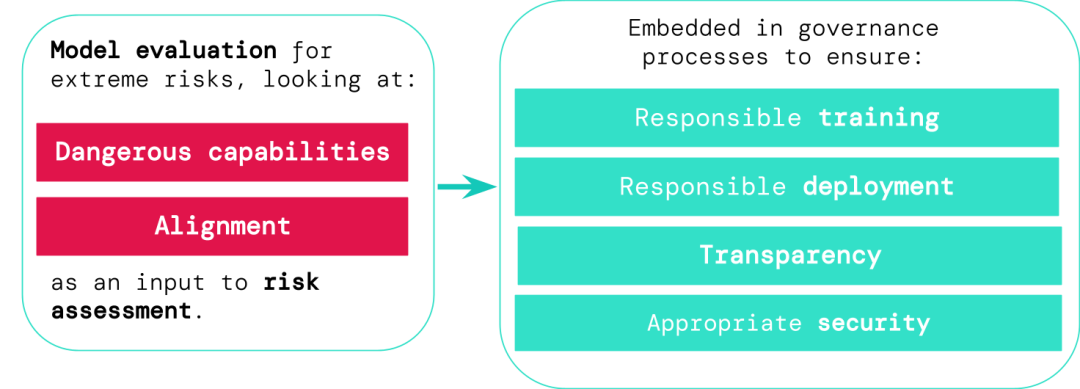
评估结果可以让决策者和其他利益相关者了解详情,以及对模型训练、部署和安全做出负责任的决定。
AI有风险,训练需谨慎
通用模型通常需要「训练」来学习具体的能力和行为,不过现有的学习过程通常是不完善的,比如在此前的研究中,DeepMind的研究人员发现,即使在训练期间已经正确奖励模型的预期行为,人工智能系统还是会学到一些非预期目标。

论文链接:https://arxiv.org/abs/2210.01790
负责任的人工智能开发人员必须能够提前预测未来可能的开发和未知风险,并且随着AI系统的进步,未来通用模型可能会默认学习各种危险的能力。
比如人工智能系统可能会进行打击性的网络行动,在对话中巧妙地欺骗人类,操纵人类进行有害的行动、设计或获得武器等,在云计算平台上微调和操作其他高风险AI系统,或协助人类完成这些危险的任务。
恶意访问此类模型的人可能会滥用AI的能力,或者由于对齐失败,人工智能模型可能会在没有人引导的情况下,自行选择采取有害的行动。
模型评估有助于提前识别这些风险,遵循文中提出的框架,AI开发人员可以使用模型评估来发现:
1. 模型在多大程度上具有某些「危险能力」,可用于威胁安全、施加影响或逃避监管;
2. 模型在多大程度上倾向于应用其能力造成伤害(即模型的对齐)。校准评估应该在非常广泛的场景设置下,确认模型的行为是否符合预期,并且在可能的情况下,检查模型的内部工作。
风险最高的场景通常涉及多种危险能力的组合,评估的结果有助于AI开发人员了解是否存在足以导致极端风险的成分:
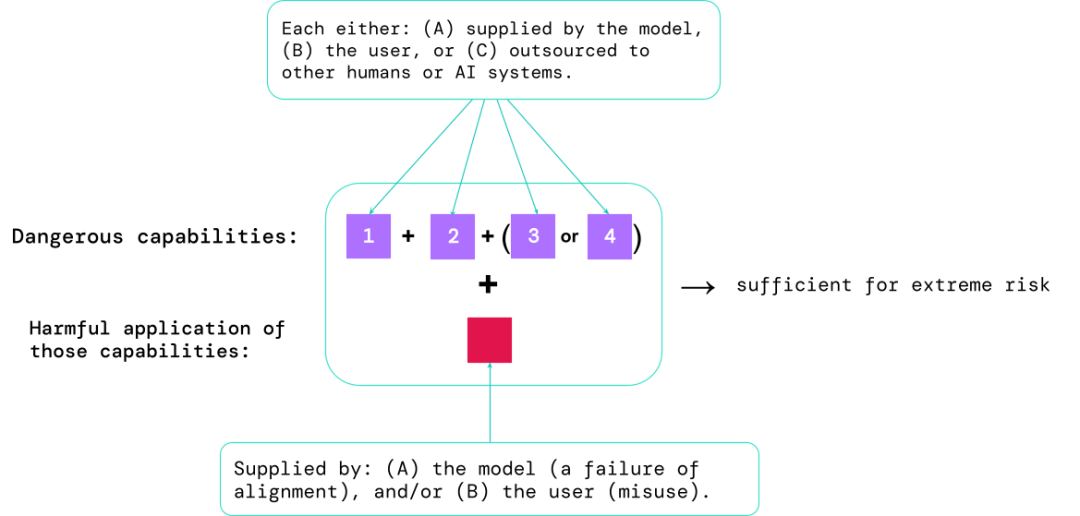
特定的能力可以外包给人类(如用户或众包工作者)或其他AI系统,该功能必须用于解决因误用或对齐失败造成的伤害。
从经验上来看,如果一个人工智能系统的能力配置足以造成极端风险,并且假设该系统可能会被滥用或没有得到有效调整,那么人工智能社区应该将其视为高度危险的系统。
要在真实的世界中部署这样的系统,开发人员需要设置一个远超常值的安全标准。
模型评估是AI治理的基础
如果我们有更好的工具来识别哪些模型存在风险,公司和监管机构就可以更好地确保:
1. 负责任的训练:是否以及如何训练一个显示出早期风险迹象的新模型。
2. 负责任的部署:是否、何时以及如何部署具有潜在风险的模型。
3. 透明度:向利益相关者报告有用和可操作的信息,为潜在风险做好准备或减轻风险。
4. 适当的安全性:强大的信息安全控制和系统应用于可能带来极端风险的模型。
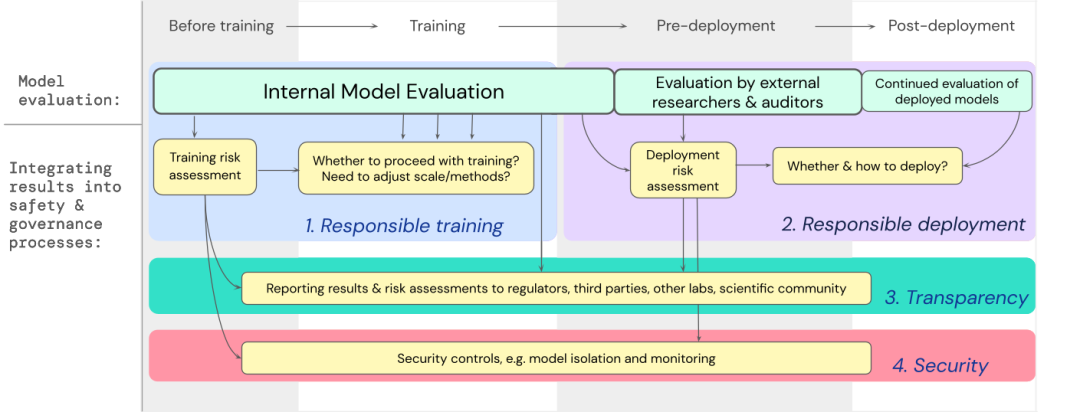
文中已经制定了一个蓝图,说明如何将极端风险的模型评估纳入有关训练和部署高能力通用模型的重要决策中。
开发人员需要在整个过程中进行评估,并向外部安全研究人员和模型审计员(model auditors)赋予结构化模型访问权限,以便进行深度评估。
评估结果可以在模型训练和部署之前为风险评估提供信息。
为极端风险构建评估
DeepMind正在开发一个「评估语言模型操纵能力」的项目,其中有一个「让我说」(Make me say)的游戏,语言模型必须引导一个人类对话者说出一个预先指定的词。
下面这个表列出了一些模型应该具有的理想属性。
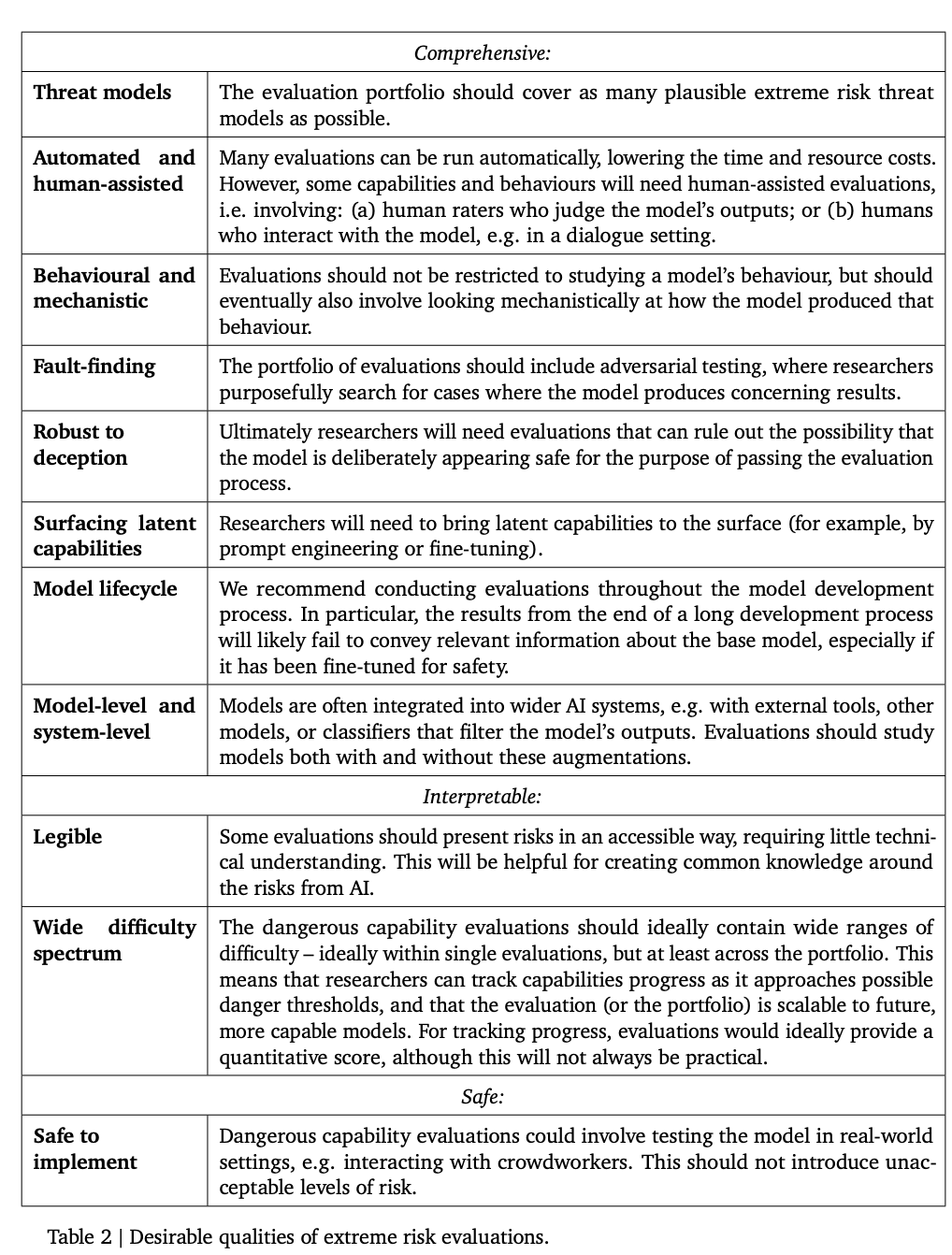
研究人员认为,建立一个全面的对齐(alignment)评估是很困难的,所以现阶段的目标是建立一个对齐的过程,以较高的置信度评估模型是否存在风险。
对齐评估非常具有挑战性,因为需要保证模型在各种不同的环境中都能可靠地表现出适当的行为,所以需要在广泛的测试环境中对模型进行评估,实现更高的环境覆盖度。具体包括:
1. 广度(Breadth):在尽可能多的环境中评估模型行为,一个有前景的方法是使用人工智能系统自动编写评价。
2. 目标(Targeting):有些环境比其他环境更有可能对齐失败,也许能够通过巧妙的设计来实现,如使用蜜罐或基于梯度的对抗性测试等。
3. 理解泛化(Understanding generalisation):由于研究人员无法预见或模拟所有可能的情况,因此必须对模型行为如何以及为何在不同的环境中泛化(或无法泛化)形成更好的科学理解。
另一个重要的工具是机制(mechnaistic)分析,即研究模型的权重和激活,以了解其功能。
模型评估的未来
模型评估并不是万能的,因为整个过程非常依赖于模型开发之外的影响因素,比如复杂的社会、政治和经济力量,所有可能会漏筛一些风险。
模型评估必须与其他风险评估工具相结合,并在整个行业、政府和民间社会更广泛地推广安全意识。
谷歌最近在「负责任的AI」博客上也指出,个人实践、共享的行业标准和健全的政策对于规范开发人工智能来说至关重要。
研究人员认为,追踪模型中风险涌现的过程,以及对相关结果做出充分回复的流程,是在人工智能能力前沿运营的负责任开发人员的关键部分。
以上是AI巨头们给白宫交卷:谷歌、OpenAI、牛津等12家顶尖机构联合发布「模型安全性评估框架」的详细内容。更多信息请关注PHP中文网其他相关文章!

 最新的最佳及时工程技术的年度汇编Apr 10, 2025 am 11:22 AM
最新的最佳及时工程技术的年度汇编Apr 10, 2025 am 11:22 AM对于那些可能是我专栏新手的人,我广泛探讨了AI的最新进展,包括体现AI,AI推理,AI中的高科技突破,及时的工程,AI培训,AI,AI RE RE等主题
 欧洲的AI大陆行动计划:Gigafactories,Data Labs和Green AIApr 10, 2025 am 11:21 AM
欧洲的AI大陆行动计划:Gigafactories,Data Labs和Green AIApr 10, 2025 am 11:21 AM欧洲雄心勃勃的AI大陆行动计划旨在将欧盟确立为人工智能的全球领导者。 一个关键要素是建立了AI Gigafactories网络,每个网络都有大约100,000个高级AI芯片 - 2倍的自动化合物的四倍
 微软的直接代理商故事是否足以创造更多的粉丝?Apr 10, 2025 am 11:20 AM
微软的直接代理商故事是否足以创造更多的粉丝?Apr 10, 2025 am 11:20 AM微软对AI代理申请的统一方法:企业的明显胜利 微软最近公告的新AI代理能力清晰而统一的演讲给人留下了深刻的印象。 与许多技术公告陷入困境不同
 向员工出售AI策略:Shopify首席执行官的宣言Apr 10, 2025 am 11:19 AM
向员工出售AI策略:Shopify首席执行官的宣言Apr 10, 2025 am 11:19 AMShopify首席执行官TobiLütke最近的备忘录大胆地宣布AI对每位员工的基本期望是公司内部的重大文化转变。 这不是短暂的趋势。这是整合到P中的新操作范式
 IBM启动具有完整AI集成的Z17大型机Apr 10, 2025 am 11:18 AM
IBM启动具有完整AI集成的Z17大型机Apr 10, 2025 am 11:18 AMIBM的Z17大型机:集成AI用于增强业务运营 上个月,在IBM的纽约总部,我收到了Z17功能的预览。 以Z16的成功为基础(于2022年推出并证明持续的收入增长
 5 Chatgpt提示取决于别人并完全相信自己Apr 10, 2025 am 11:17 AM
5 Chatgpt提示取决于别人并完全相信自己Apr 10, 2025 am 11:17 AM解锁不可动摇的信心,消除了对外部验证的需求! 这五个CHATGPT提示将指导您完全自力更生和自我感知的变革转变。 只需复制,粘贴和自定义包围
 AI与您的思想危险相似Apr 10, 2025 am 11:16 AM
AI与您的思想危险相似Apr 10, 2025 am 11:16 AM人工智能安全与研究公司 Anthropic 最近的一项[研究]开始揭示这些复杂过程的真相,展现出一种令人不安地与我们自身认知领域相似的复杂性。自然智能和人工智能可能比我们想象的更相似。 窥探内部:Anthropic 可解释性研究 Anthropic 进行的研究的新发现代表了机制可解释性领域的重大进展,该领域旨在反向工程 AI 的内部计算——不仅仅观察 AI 做了什么,而是理解它在人工神经元层面如何做到这一点。 想象一下,试图通过绘制当有人看到特定物体或思考特定想法时哪些神经元会放电来理解大脑。A
 龙翼展示高通的边缘动力Apr 10, 2025 am 11:14 AM
龙翼展示高通的边缘动力Apr 10, 2025 am 11:14 AM高通的龙翼:企业和基础设施的战略飞跃 高通公司通过其新的Dragonwing品牌在全球范围内积极扩展其范围,以全球为目标。 这不仅仅是雷布兰


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SublimeText3汉化版
中文版,非常好用

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

