



原題: RoadBEV: Road Surface Reconstruction in Bird's Eye View
論文リンク: https://arxiv.org/pdf/2404.06605.pdf
コードリンク: https ://github.com/ztsrxh/RoadBEV
著者の所属: 清華大学、カリフォルニア大学バークレー校

# 論文のアイデア:
路面状況、特に幾何学的輪郭は自動運転車の運転能力に大きく影響します。ビジョンベースのオンライン道路再構築により、道路情報を事前に取得できることが期待されます。単眼奥行き推定や立体視推定などの既存のソリューションには限界があります。最近の鳥瞰図 (BEV) 認識技術は、より信頼性が高く正確な再構成を実現するための大きな動機となります。この論文は、それぞれRoadBEV-monoとRoadBEV-stereoと名付けられた2つの効果的なBEV道路標高再構成モデルを一律に提案するもので、道路標高推定に単眼画像や両眼画像を使用するのとは異なります。前者は 1 つの画像から直接道路の標高を推定しますが、後者は左右の体積ビューを使用して道路の標高を推定します。綿密な分析により、視点との一貫性と相違点が明らかになります。現実世界のデータセットでの実験により、モデルの有効性と優位性が実証されています。 RoadBEV-mono と RoadBEV-stereo の標高誤差はそれぞれ 1.83 メートルと 0.56 メートルです。単眼画像に基づく BEV 推定のパフォーマンスが 50% 向上しました。この記事のモデルは、ビジョンベースの自動運転技術において貴重な参考となることが期待されます。
主な貢献:
本論文は、路面再構築の必要性と優位性を理論面と実験面の両面から鳥瞰的に初めて実証したものである。
この記事では、RoadBEV-mono と RoadBEV-stereo という 2 つのモデルを紹介します。単眼ベースのスキームとステレオベースのスキームについては、この記事でそのメカニズムについて詳しく説明します。
この論文では、提案されたモデルのパフォーマンスを包括的にテストおよび分析し、将来の研究に貴重な洞察と展望を提供します。
ネットワーク設計:
近年、無人地上車両 (UGV) の急速な開発により、車載認識システムに対する要件がさらに高まっています。正確な動作計画と制御には、運転環境と状況をリアルタイムで理解することが不可欠です [1] ~ [3]。車両にとって、道路は物理世界との唯一の接触媒体です。路面状況は、多くの車両特性と操縦性を決定します [4]。図 1(a) に示すように、凹凸や窪みなどの道路の凹凸は、車両の乗り心地を悪化させますが、これは直感的に認識できます。リアルタイムの路面状況の認識、特に幾何学的な高さは、乗り心地の向上に大きく役立ちます [5]、[6]。
無人地上車両 (UGV) におけるセグメンテーションや検出などの他の認識タスクと比較して、路面再構築 (RSR) は最近注目を集めている新興テクノロジーです。既存の認識プロセスと同様に、RSR は通常、オンボード LiDAR とカメラ センサーを利用して路面情報を保持します。 LiDAR は道路等高線を直接スキャンし、点群を導き出します [7]、[8]。複雑なアルゴリズムを使用せずに、車両軌道上の道路の標高を直接抽出できます。ただし、LiDAR センサーはコストが高いため、経済的な量産車両への応用は制限されます。車両や歩行者などの大きな交通物体とは異なり、道路の凹凸は通常、規模が小さいため、点群の精度が重要です。リアルタイムの道路スキャンでは動き補償とフィルタリングが必要であり、さらにセンチメートルレベルでの高精度の測位が必要です。
画像ベースの路面再構成 (RSR) は、3 次元視覚タスクとして、精度と解像度の点で LiDAR よりも有望です。また、路面のテクスチャも保持し、道路の認識をより包括的にします。視覚ベースの道路標高の再構築は、実際には深度推定の問題です。単眼カメラの場合、単一の画像に基づいて単眼奥行き推定を実装することも、奥行きを直接推定するシーケンスに基づいて多視点ステレオ (MVS) を実装することもできます [9]。双眼カメラの場合、両眼マッチングにより視差マップが回帰され、視差マップは深度に変換できます [10]、[11]。カメラ パラメーターが与えられると、カメラ座標系の道路点群を復元できます。事前の後処理プロセスを経て、最終的に道路構造と標高情報が取得されます。グラウンドトゥルース (GT) ラベルの指導のもと、高精度で信頼性の高い RSR を実現できます。
然而,影像視角下的道路表面重建(RSR)存在著固有的缺點。對於特定像素的深度估計實際上是沿著垂直於影像平面方向尋找最優箱體(optimal bins)(如圖1(b)中的橘色點所示)。深度方向與道路表面有一定的角度偏差。道路輪廓特徵的變化和趨勢與搜尋方向上的變化和趨勢不一致。在深度視圖中關於道路高程變化的資訊線索是稀疏的。此外,每個像素的深度搜尋範圍是相同的,導致模型捕捉到的是全域幾何層次結構而不是局部表面結構。由於全局但粗糙的深度搜索,精細的道路高程資訊被破壞。由於本文關注的是垂直方向上的高程,因此在深度方向上所做的努力被浪費了。在透視視圖中,遠距離的紋理細節遺失,這進一步為有效的深度回歸帶來了挑戰,除非進一步引入先驗約束[12]。
從俯視圖(即鳥瞰圖,BEV)估計道路高程是一個自然的想法,因為高程本質上描述了垂直方向的振動。鳥瞰圖是一種有效的範式,用於以統一座標表示多模態和多視圖資料[13],[14]。最近在三維目標檢測和分割任務上取得的 SOTA 性能是透過基於鳥瞰圖的方法實現的[15],這與透視視圖不同,後者透過在視圖轉換的影像特徵上引入估計頭部來進行。圖1展示了本文的動機。與在影像視圖中關注全局結構不同,鳥瞰圖中的重建直接在垂直方向上的一個特定小範圍內識別道路特徵。在鳥瞰圖中投影的道路特徵密集地反映了結構和輪廓變化,有助於進行有效和精細化的搜尋。透視效應的影響也被抑制,因為道路在垂直於觀察角度的平面上被統一表示。基於鳥瞰圖特徵的道路重建有望實現更高的性能。
本文重建了BEV下的道路表面,以解決上述識別出的問題。特別地,本文關注道路幾何,即高程(elevation)。為了利用單眼和雙眼影像,並展示鳥瞰圖感知的廣泛可行性,本文提出了兩個子模型,分別命名為RoadBEV-mono和RoadBEV-stereo。遵循鳥瞰圖的範例,本文定義了覆蓋潛在道路起伏的興趣體素。這些體素透過3D-2D投影查詢像素特徵。對於RoadBEV-mono,本文在重塑的體素特徵上引入了高程估計頭。 RoadBEV-stereo的結構與影像視圖中的雙眼匹配保持一致。基於左右體素特徵,在鳥瞰圖中建構了一個4D代價體積,該體積透過3D卷積進行聚合。高程迴歸被視為對預定義箱體的分類,以實現更有效率的模型學習。本文在本文作者先前發布的真實世界資料集上驗證了這些模型,顯示出它們比傳統的單目深度估計和雙眼匹配方法有著巨大的優勢。
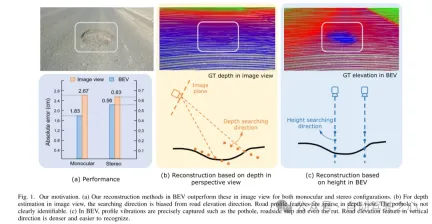
圖1. 本文的動機。 (a)無論是單目或雙目配置,本文在鳥瞰圖(BEV)中的重建方法都優於影像視圖中的方法。 (b)在影像視圖中進行深度估計時,搜尋方向與道路高程方向有偏差。在深度視圖中,道路輪廓特徵是稀疏的。坑洼不容易被識別。 (c)在鳥瞰圖中,能夠精確捕捉到輪廓振動,例如坑洞、路邊階梯甚至車轍。垂直方向上的道路高程特徵較為密集,也較容易辨識。
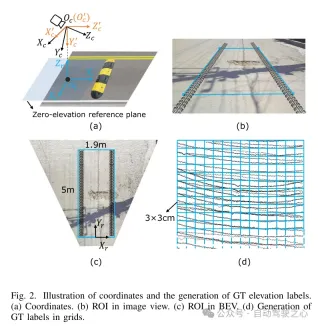
圖2. 座標示意與真值(GT)高程標籤的產生。 (a)座標(b)影像視圖中的興趣區域(ROI)(c)鳥瞰圖中的興趣區域(ROI)(d)在網格中產生真值(GT)標籤

#圖3. 道路影像及真值(GT)高程圖的範例。

圖4. 影像檢視中感興趣的特徵體素。位於相同水平位置的堆疊體素的中心被投影到紅色線段上的像素點。
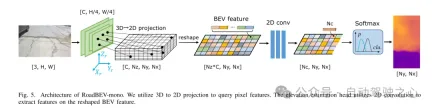
圖5. RoadBEV-mono的架構。本文利用3D到2D的投影來查詢像素特徵。高程估計頭部使用2D卷積在重塑後的鳥瞰圖(BEV)特徵上提取特徵。
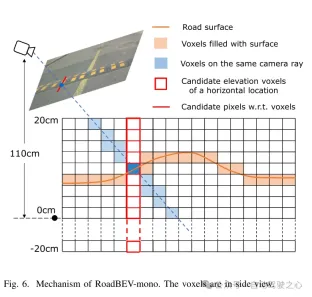
圖6. RoadBEV-mono的機制。體素以側視圖展示。
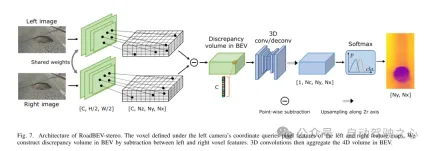
圖7. RoadBEV-stereo的架構。定義在左側相機座標系下的體素查詢左右特徵圖的像素特徵。本文透過左右體素特徵之間的相減,在鳥瞰圖(BEV)中建構差異體積。然後,3D卷積對鳥瞰圖中的4D體積進行聚合。
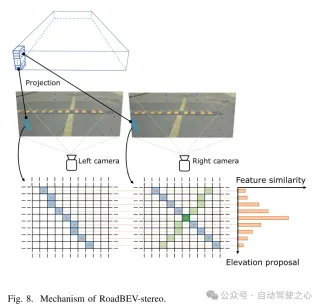
圖8. RoadBEV-stereo的機制。
實驗結果:
圖9. (a) RoadBEV-mono和 (b) RoadBEV-stereo的訓練損失。
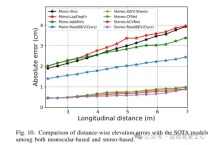
圖10. 在單目與雙眼基礎上,與SOTA模型的距離方向上的高程誤差比較。
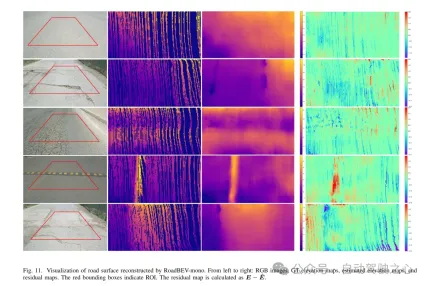
圖11. 由RoadBEV-mono重建的道路表面視覺化。

圖12. 由RoadBEV-stereo重建的道路表面視覺化。

總結:
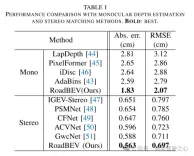
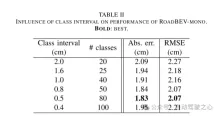
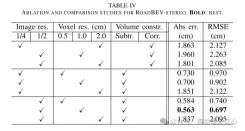
本文首次在鳥瞰圖中重建了道路表面的高程。本文分別提出並分析了基於單眼和雙眼影像的兩種模型,分別命名為RoadBEV-mono和RoadBEV-stereo。本文發現,BEV中的單目估計和雙眼匹配與透視視圖中的機制相同,透過縮小搜尋範圍和直接在高程方向挖掘特徵而得到改善。在真實世界資料集上的全面實驗驗證了所提出的BEV體積、估計頭和參數設定的可行性和優越性。對於單眼相機,在BEV中的重建性能比透視視圖提高了50%。同時,在BEV中,使用雙眼相機的性能是單目的三倍。本文提供了關於模型的深入分析和指導。本文的開創性探索也為與BEV感知、3D重建和3D檢測相關的進一步研究和應用提供了寶貴的參考。
以上是清華最新! RoadBEV:BEV下的道路表面重建如何實現?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 擁抱面部是否7B型號奧林匹克賽車擊敗克勞德3.7?Apr 23, 2025 am 11:49 AM
擁抱面部是否7B型號奧林匹克賽車擊敗克勞德3.7?Apr 23, 2025 am 11:49 AM擁抱Face的OlympicCoder-7B:強大的開源代碼推理模型 開發以代碼為中心的語言模型的競賽正在加劇,擁抱面孔與強大的競爭者一起參加了比賽:OlympicCoder-7B,一種產品
 4個新的雙子座功能您可以錯過Apr 23, 2025 am 11:48 AM
4個新的雙子座功能您可以錯過Apr 23, 2025 am 11:48 AM你們當中有多少人希望AI可以做更多的事情,而不僅僅是回答問題?我知道我有,最近,我對它的變化感到驚訝。 AI聊天機器人不僅要聊天,還關心創建,研究
 Camunda為經紀人AI編排編寫了新的分數Apr 23, 2025 am 11:46 AM
Camunda為經紀人AI編排編寫了新的分數Apr 23, 2025 am 11:46 AM隨著智能AI開始融入企業軟件平台和應用程序的各個層面(我們必須強調的是,既有強大的核心工具,也有一些不太可靠的模擬工具),我們需要一套新的基礎設施能力來管理這些智能體。 總部位於德國柏林的流程編排公司Camunda認為,它可以幫助智能AI發揮其應有的作用,並與新的數字工作場所中的準確業務目標和規則保持一致。該公司目前提供智能編排功能,旨在幫助組織建模、部署和管理AI智能體。 從實際的軟件工程角度來看,這意味著什麼? 確定性與非確定性流程的融合 該公司表示,關鍵在於允許用戶(通常是數據科學家、軟件
 策劃的企業AI體驗是否有價值?Apr 23, 2025 am 11:45 AM
策劃的企業AI體驗是否有價值?Apr 23, 2025 am 11:45 AM參加Google Cloud Next '25,我渴望看到Google如何區分其AI產品。 有關代理空間(此處討論)和客戶體驗套件(此處討論)的最新公告很有希望,強調了商業價值
 如何為抹布找到最佳的多語言嵌入模型?Apr 23, 2025 am 11:44 AM
如何為抹布找到最佳的多語言嵌入模型?Apr 23, 2025 am 11:44 AM為您的檢索增強發電(RAG)系統選擇最佳的多語言嵌入模型 在當今的相互聯繫的世界中,建立有效的多語言AI系統至關重要。 強大的多語言嵌入模型對於RE至關重要
 麝香:奧斯汀的機器人需要每10,000英里進行干預Apr 23, 2025 am 11:42 AM
麝香:奧斯汀的機器人需要每10,000英里進行干預Apr 23, 2025 am 11:42 AM特斯拉的Austin Robotaxi發射:仔細觀察Musk的主張 埃隆·馬斯克(Elon Musk)最近宣布,特斯拉即將在德克薩斯州奧斯汀推出的Robotaxi發射,最初出於安全原因部署了一支小型10-20輛汽車,並有快速擴張的計劃。 h
 AI震驚的樞軸:從工作工具到數字治療師和生活教練Apr 23, 2025 am 11:41 AM
AI震驚的樞軸:從工作工具到數字治療師和生活教練Apr 23, 2025 am 11:41 AM人工智能的應用方式可能出乎意料。最初,我們很多人可能認為它主要用於代勞創意和技術任務,例如編寫代碼和創作內容。 然而,哈佛商業評論最近報導的一項調查表明情況並非如此。大多數用戶尋求人工智能的並非是代勞工作,而是支持、組織,甚至是友誼! 報告稱,人工智能應用案例的首位是治療和陪伴。這表明其全天候可用性以及提供匿名、誠實建議和反饋的能力非常有價值。 另一方面,營銷任務(例如撰寫博客、創建社交媒體帖子或廣告文案)在流行用途列表中的排名要低得多。 這是為什麼呢?讓我們看看研究結果及其對我們人類如何繼續將



熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

WebStorm Mac版
好用的JavaScript開發工具

