



- 此論文研究方向涉及視覺語言預訓練(VLP)、跨模態圖文檢索(CMITR)等領域。此次入選標誌著網易伏羲實驗室多模態能力再受國際認可,目前相關技術已應用至網易伏羲自研多模態智能體助手「丹青約」。
- ACM MM由國際電腦協會(ACM)發起,是多媒體處理、分析與運算領域最具影響力的國際頂尖會議,也是中國電腦學會推薦的多媒體領域A類國際學術會議。作為領域內的頂級會議,ACM MM 受到國內外知名廠商和學者廣泛關注。本屆ACM MM共收到有效稿件4,385篇,其中1149篇由大會接收,接收率為26.20%。
作為國內領先的人工智慧研究機構,網易伏羲在大規模模型研究領域已有近六年的深厚積累,具備豐富的演算法和工程經驗,先後打造了數十個文本和多模態預訓練模型,包括文字理解和生成大模型、圖文理解大模型、圖文生成大模型等。這些成果不僅有效地推動了大模型在遊戲領域的應用,也為跨模態理解能力的發展奠定了堅實的基礎。跨模態理解能力有助於更好地融合多種領域知識,並對齊豐富的資料模態及資訊。

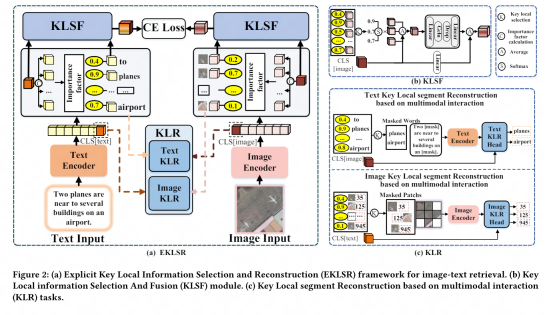
在此基礎上,網易伏羲基於圖文理解大模型進一步創新,提出一種基於關鍵局部信息的選取與重建的跨模態檢索方法,為多模態智能體解決特定領域下的圖像文本互動問題奠定技術基礎。
以下為本次入選論文概要:
《Selection and Reconstruction of Key Locals: A Novel Specific Domain Image-Text Retrieval Method》
關鍵局部資訊的選取與重建:一種新穎的特定領域圖文檢索方法
關鍵字:關鍵局部訊息,細微,可解釋
涉及領域:視覺語言預訓練(VLP),跨模態圖文檢索(CMITR)
近年來,隨著視覺語言預訓練(Vision- Language Pretraining, VLP) 模型的興起,跨模態影像文字檢索(Cross-Modal Image-Text Retrieval, CMITR) 領域取得了顯著進展。儘管像 CLIP 這樣的 VLP 模型在一般領域的 CMITR 任務中表現出色,但在特定領域影像文字擷取 (Specific Domain Image-Text Retrieval, SDITR) 中,其效能往往會不足。這是因為特定領域通常具有獨特的資料特徵,這些特徵區別於一般領域。
在特定領域內,圖像之間可能展現出高度的視覺相似性,而語義差異則往往集中在關鍵的局部細節上,例如圖像中的特定對象區域或文本中含義豐富的詞彙。即使是這些局部片段的細微變化也可能對整個內容產生顯著影響,從而凸顯了這些關鍵局部訊息的重要性。因此,SDITR 要求模型專注於關鍵的局部資訊片段,以增強影像與文字特徵在共享表示空間中的表達,進而改善影像與文字之間的對齊精確度。
本主題透過探討視覺語言預訓練模型在特定領域圖像-文字檢索任務中的應用,研究了特定領域圖像-文字檢索任務中的局部特徵利用問題。主要貢獻在於提出了一種利用具有判別性的細粒度局部資訊的方法,優化圖像與文字在共享表示空間中的對齊。
為此,我們設計了顯式關鍵局部資訊選擇和重建框架和基於多模態交互的關鍵局部段重構策略,這些方法有效地利用了具有判別性的細粒度局部信息,從而顯著提升了圖像與文本在共享空間中的對齊質量,廣泛和充分的實驗證明了所提出策略的先進性和有效性。
在此特別感謝西安電子科技大學IPIU實驗室對本論文的大力支持與重要研究貢獻。
現在、NetEase Fuxi のマルチモーダル理解機能は、NetEase Leihuo、NetEase Cloud Music、NetEase Yuanqi などを含む NetEase グループの複数の事業部門で広く使用されています。これらのアプリケーションは、ゲーム内の革新的なテキストベースの顔をつまむゲームプレイ、クロスモーダル リソース検索、パーソナライズされたコンテンツの推奨など、さまざまなシナリオをカバーしており、大きなビジネス価値を実証しています。
将来的には、研究の深化と技術の進歩に伴い、この成果により、教育、医療、電子商取引、その他の業界における人工知能技術の広範な適用が促進され、よりパーソナライズされたインテリジェントなサービス体験がユーザーに提供されることが期待されます。 NetEase Fuxiはまた、国内外のトップ学術機関との交流と協力を深め、より最先端の研究分野での深い探求を実施し、人工知能技術の開発を共同で推進し、より効率的でスマートな社会の構築に貢献していきます。社会。
下のQRコードをスキャンして「写真アポイントメント」をすぐに体験し、「よりよく理解できる」写真とテキストによるマルチモーダルなインタラクティブ体験をお楽しみください。

以上是ACM MM2024 | 網易伏羲多模態研究再獲國際認可,推動特定領域跨模態理解新突破的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 擁抱面部是否7B型號奧林匹克賽車擊敗克勞德3.7?Apr 23, 2025 am 11:49 AM
擁抱面部是否7B型號奧林匹克賽車擊敗克勞德3.7?Apr 23, 2025 am 11:49 AM擁抱Face的OlympicCoder-7B:強大的開源代碼推理模型 開發以代碼為中心的語言模型的競賽正在加劇,擁抱面孔與強大的競爭者一起參加了比賽:OlympicCoder-7B,一種產品
 4個新的雙子座功能您可以錯過Apr 23, 2025 am 11:48 AM
4個新的雙子座功能您可以錯過Apr 23, 2025 am 11:48 AM你們當中有多少人希望AI可以做更多的事情,而不僅僅是回答問題?我知道我有,最近,我對它的變化感到驚訝。 AI聊天機器人不僅要聊天,還關心創建,研究
 Camunda為經紀人AI編排編寫了新的分數Apr 23, 2025 am 11:46 AM
Camunda為經紀人AI編排編寫了新的分數Apr 23, 2025 am 11:46 AM隨著智能AI開始融入企業軟件平台和應用程序的各個層面(我們必須強調的是,既有強大的核心工具,也有一些不太可靠的模擬工具),我們需要一套新的基礎設施能力來管理這些智能體。 總部位於德國柏林的流程編排公司Camunda認為,它可以幫助智能AI發揮其應有的作用,並與新的數字工作場所中的準確業務目標和規則保持一致。該公司目前提供智能編排功能,旨在幫助組織建模、部署和管理AI智能體。 從實際的軟件工程角度來看,這意味著什麼? 確定性與非確定性流程的融合 該公司表示,關鍵在於允許用戶(通常是數據科學家、軟件
 策劃的企業AI體驗是否有價值?Apr 23, 2025 am 11:45 AM
策劃的企業AI體驗是否有價值?Apr 23, 2025 am 11:45 AM參加Google Cloud Next '25,我渴望看到Google如何區分其AI產品。 有關代理空間(此處討論)和客戶體驗套件(此處討論)的最新公告很有希望,強調了商業價值
 如何為抹布找到最佳的多語言嵌入模型?Apr 23, 2025 am 11:44 AM
如何為抹布找到最佳的多語言嵌入模型?Apr 23, 2025 am 11:44 AM為您的檢索增強發電(RAG)系統選擇最佳的多語言嵌入模型 在當今的相互聯繫的世界中,建立有效的多語言AI系統至關重要。 強大的多語言嵌入模型對於RE至關重要
 麝香:奧斯汀的機器人需要每10,000英里進行干預Apr 23, 2025 am 11:42 AM
麝香:奧斯汀的機器人需要每10,000英里進行干預Apr 23, 2025 am 11:42 AM特斯拉的Austin Robotaxi發射:仔細觀察Musk的主張 埃隆·馬斯克(Elon Musk)最近宣布,特斯拉即將在德克薩斯州奧斯汀推出的Robotaxi發射,最初出於安全原因部署了一支小型10-20輛汽車,並有快速擴張的計劃。 h
 AI震驚的樞軸:從工作工具到數字治療師和生活教練Apr 23, 2025 am 11:41 AM
AI震驚的樞軸:從工作工具到數字治療師和生活教練Apr 23, 2025 am 11:41 AM人工智能的應用方式可能出乎意料。最初,我們很多人可能認為它主要用於代勞創意和技術任務,例如編寫代碼和創作內容。 然而,哈佛商業評論最近報導的一項調查表明情況並非如此。大多數用戶尋求人工智能的並非是代勞工作,而是支持、組織,甚至是友誼! 報告稱,人工智能應用案例的首位是治療和陪伴。這表明其全天候可用性以及提供匿名、誠實建議和反饋的能力非常有價值。 另一方面,營銷任務(例如撰寫博客、創建社交媒體帖子或廣告文案)在流行用途列表中的排名要低得多。 這是為什麼呢?讓我們看看研究結果及其對我們人類如何繼續將



熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

禪工作室 13.0.1
強大的PHP整合開發環境

