
Rumah >Peranti teknologi >AI >Apakah penyahkodan spekulatif yang mungkin juga digunakan oleh GPT-4? Artikel yang meringkaskan situasi masa lalu, sekarang dan aplikasi
Apakah penyahkodan spekulatif yang mungkin juga digunakan oleh GPT-4? Artikel yang meringkaskan situasi masa lalu, sekarang dan aplikasi

- 王林ke hadapan
- 2024-02-20 15:45:02912semak imbas
Adalah diketahui umum bahawa inferens model bahasa besar (LLM) biasanya memerlukan penggunaan pensampelan autoregresif, dan proses inferens ini agak perlahan. Untuk menyelesaikan masalah ini, penyahkodan spekulatif telah menjadi kaedah pensampelan baharu untuk inferens LLM. Dalam setiap langkah persampelan, kaedah ini mula-mula akan meramalkan beberapa kemungkinan token dan kemudian mengesahkan sama ada ia adalah tepat selari. Tidak seperti penyahkodan autoregresif, penyahkodan spekulatif boleh menyahkod berbilang token dalam satu langkah, sekali gus mempercepatkan inferens.
Walaupun penyahkodan spekulatif menunjukkan potensi besar dalam banyak aspek, ia juga menimbulkan beberapa isu utama yang memerlukan penyelidikan mendalam. Pertama, kita perlu memikirkan cara memilih atau mereka bentuk model anggaran yang sesuai untuk mencapai keseimbangan antara ketepatan tekaan dan kecekapan penjanaan. Kedua, adalah penting untuk memastikan kriteria penilaian mengekalkan kedua-dua kepelbagaian dan kualiti keputusan yang dihasilkan. Akhir sekali, penjajaran proses inferens antara model anggaran dan model besar sasaran mesti dipertimbangkan dengan teliti untuk meningkatkan ketepatan inferens.
Penyelidik dari Universiti Politeknik Hong Kong, Universiti Peking, MSRA dan Alibaba telah menjalankan penyiasatan menyeluruh mengenai penyahkodan spekulatif, dan Machine Heart telah membuat ringkasan yang komprehensif mengenai perkara ini. U Tajuk tesis: Buka Kunci Kecekapan dalam Model Bahasa Besar Inferens: Satu Tinjauan Komprehensif Penyahkodan Spekulatif
F 
- Evolusi penyahkodan spekulatif awal teknologi spekulatif
- yang pertama dan menunjukkan proses pembangunannya melalui garis masa (lihat Rajah 2).
- Penyahkodan Sekatan ialah kaedah menyepadukan kepala saraf suapan hadapan (FFN) tambahan pada penyahkod Transformer, yang boleh menjana berbilang token dalam satu langkah.
Untuk mengeksploitasi sepenuhnya potensi algoritma pensampelan blok, penyelesaian penyahkodan spekulatif dicadangkan. Algoritma ini merangkumi model anggaran bebas, biasanya menggunakan Transformer bukan autoregresif khusus, yang mampu melaksanakan tugas penjanaan dengan cekap dan tepat.
Selepas kemunculan penyahkodan spekulatif, beberapa sarjana kemudian mencadangkan "Algoritma Pensampelan Spekulatif", yang menambah pensampelan kernel dipercepatkan tanpa kerugian kepada penyahkodan spekulatif.
Secara keseluruhan, percubaan inovatif pada penyahkodan spekulatif ini telah mula mengukuhkan paradigma Draftthen-Verify dan menunjukkan potensi besar dalam pecutan LLM.
Formula dan Definisi
Bahagian ini mula-mula menggariskan secara ringkas kandungan penyahkodan autoregresif standard, dan kemudian menghuraikan tentang penyahkodan spekulatif secara terperinci, termasuk kaedah penyahkodan spekulatif secara mendalam dan butiran algoritma.
Artikel ini mencadangkan rangka kerja organisasi untuk mengklasifikasikan penyelidikan berkaitan, seperti ditunjukkan dalam Rajah 3 di bawah. . ia mula-mula perlu dapat menjana berbilang token yang mungkin, dan kemudian menggunakan model bahasa besar sasaran untuk menilai semua token ini secara selari untuk mempercepatkan inferens. Algoritma Jadual 2 ialah proses penyahkodan spekulatif terperinci. 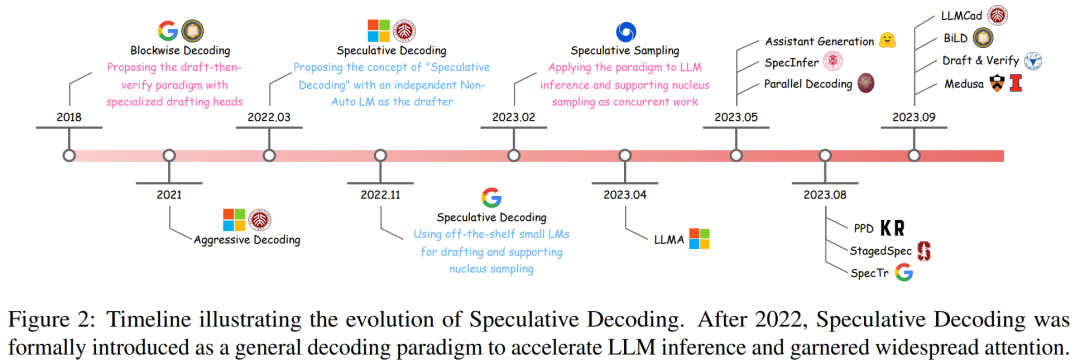
Kemudian, artikel ini menyelidiki dua sub-langkah asas yang penting kepada paradigma ini – penjanaan dan penilaian.
Generation

Pada setiap langkah penyahkodan, algoritma penyahkodan spekulatif mula-mula menjana berbilang token yang mungkin sebagai spekulasi pada kandungan output model bahasa besar sasaran.
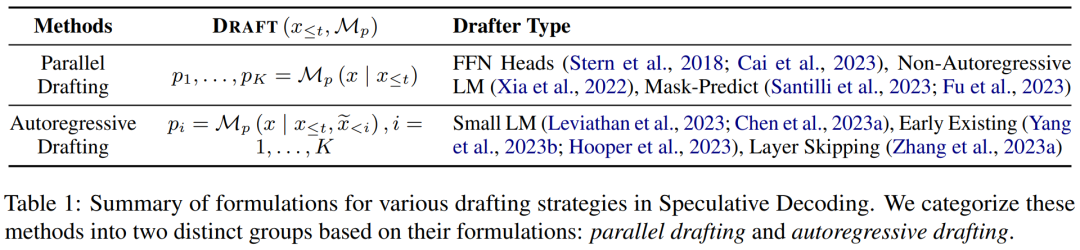
Artikel ini membahagikan kandungan yang dijana kepada dua kategori: penggubalan bebas dan penggubalan sendiri, dan meringkaskan formulanya dalam Jadual 1 di bawah.
Pengesahan
Dalam setiap langkah penyahkodan, token yang dijana oleh model anggaran disahkan secara selari untuk memastikan kualiti output yang besar adalah sangat konsisten dengan kualiti output. Proses ini juga menentukan bilangan token yang dibenarkan pada setiap langkah, faktor penting yang boleh menjejaskan kelajuan.
Ringkasan pelbagai kriteria pengesahan ditunjukkan dalam Jadual 2 di bawah, termasuk yang menyokong penyahkodan tamak dan pensampelan kernel dalam inferens model bahasa besar.

Sub-langkah penjanaan dan pengesahan terus berulang sehingga syarat penamatan dipenuhi, iaitu token [EOS] dinyahkod atau ayat mencapai panjang maksimum.
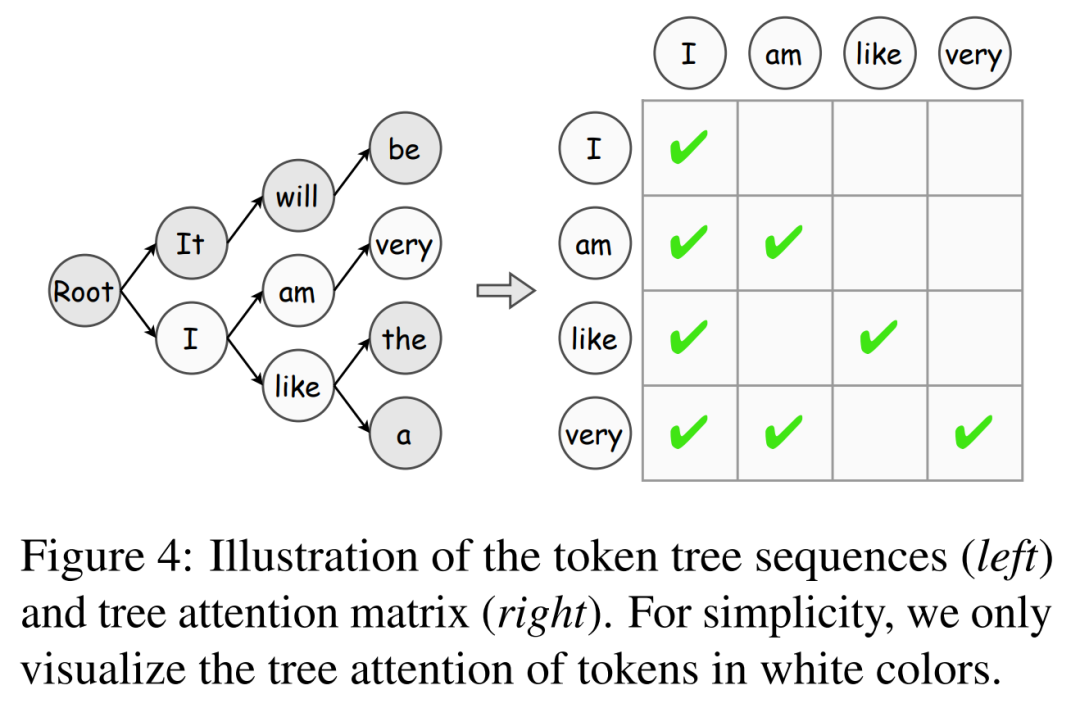
Selain itu, artikel ini memperkenalkan algoritma pengesahan pokok token, yang merupakan strategi berkesan untuk meningkatkan penerimaan token secara beransur-ansur.
Penjajaran Model
Meningkatkan ketepatan spekulasi adalah kunci untuk mempercepatkan penyahkodan spekulatif: semakin dekat anggaran gelagat model yang diramalkan dengan model penerimaan besar yang dijana, semakin tinggi model penerimaan yang dijana. Untuk tujuan ini, kerja sedia ada meneroka pelbagai strategi pengekstrakan pengetahuan (KD) untuk menyelaraskan kandungan output model anggaran dengan model bahasa besar sasaran.
Penyahkodan disekat mula-mula menggunakan pengekstrakan pengetahuan peringkat jujukan (Seq-KD) untuk penjajaran model dan melatih model anggaran dengan ayat yang dijana oleh model bahasa besar sasaran.
Selain itu, Seq-KD juga merupakan strategi yang berkesan untuk meningkatkan kualiti penjanaan penyahkod selari, meningkatkan prestasi penjanaan penyahkod selari.
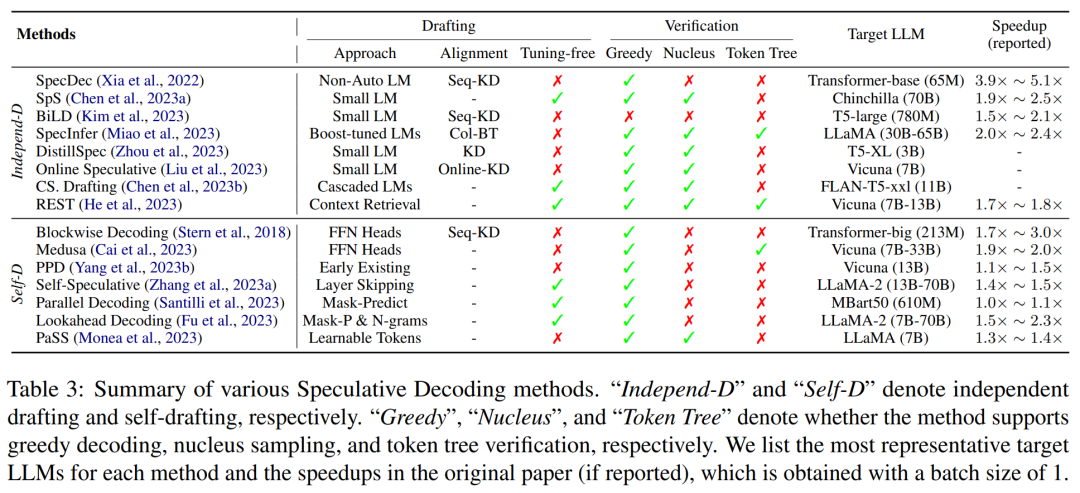
Ciri-ciri utama kaedah penyahkodan spekulatif sedia ada diringkaskan dalam Jadual 3 di bawah, termasuk jenis anggaran model atau strategi penjanaan, kaedah penjajaran model, strategi penilaian yang disokong dan tahap pecutan.
Aplikasi
Selain sebagai paradigma umum, kerja baru-baru ini telah menunjukkan bahawa beberapa varian penyahkodan spekulatif mempamerkan keberkesanan yang luar biasa dalam tugas tertentu. Di samping itu, penyelidikan lain telah menggunakan paradigma ini untuk menyelesaikan isu kependaman yang unik kepada senario aplikasi tertentu, dengan itu mencapai pecutan inferens.
Sebagai contoh, sesetengah sarjana percaya bahawa penyahkodan spekulatif amat sesuai untuk tugasan di mana input dan output model sangat serupa, seperti pembetulan ralat tatabahasa dan penjanaan peningkatan perolehan semula.
Selain karya ini, RaLMSpec (Zhang et al., 2023b) menggunakan penyahkodan spekulatif untuk mempercepatkan mendapatkan semula model bahasa tambahan (RaLMs).
Peluang dan Cabaran
Soalan 1: Bagaimana untuk menimbang ketepatan dan kecekapan penjanaan kandungan yang diramalkan? Walaupun beberapa kemajuan telah dicapai dalam masalah ini, masih terdapat banyak ruang untuk penambahbaikan dalam menjajarkan model anggaran dengan apa yang dijana oleh model bahasa besar sasaran. Selain penjajaran model, faktor lain seperti kualiti penjanaan dan penentuan panjang ramalan juga mempengaruhi ketepatan ramalan dan patut diterokai lebih lanjut.
Soalan 2: Bagaimana untuk menggabungkan penyahkodan spekulatif dengan teknologi terkemuka lain? Sebagai mod penyahkodan umum, penyahkodan spekulatif telah digabungkan dengan teknologi canggih lain untuk menunjukkan potensinya. Selain mempercepatkan model bahasa besar untuk teks biasa, aplikasi penyahkodan spekulatif dalam penaakulan multimodal, seperti sintesis imej, sintesis teks ke pertuturan dan penjanaan video, juga merupakan hala tuju yang menarik dan berharga untuk penyelidikan masa depan.
Sila rujuk kertas asal untuk butiran lanjut.
Atas ialah kandungan terperinci Apakah penyahkodan spekulatif yang mungkin juga digunakan oleh GPT-4? Artikel yang meringkaskan situasi masa lalu, sekarang dan aplikasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- python ipo模型是指什么
- 常见的三种数据库数据模型是什么
- Apakah model OSI
- Bard telah dilatih mengenai data ChatGPT? Para saintis terkemuka Google membantah tidak berjaya dan meninggalkan OpenAI
- Senarai teratas antarabangsa yang berwibawa bagi penghuraian semantik perbualan SParC dan CoSQL, model pra-latihan pengetahuan meja dialog pelbagai pusingan baharu tafsiran STAR