
Rumah >Peranti teknologi >AI >Apabila Sora meletupkan penjanaan video, Meta mula menggunakan Agent untuk memotong video secara automatik, diketuai oleh pengarang Cina
Apabila Sora meletupkan penjanaan video, Meta mula menggunakan Agent untuk memotong video secara automatik, diketuai oleh pengarang Cina

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-20 15:50:03760semak imbas
Baru-baru ini, bidang teknologi video AI telah menarik perhatian ramai, terutamanya model besar generasi video Sora yang dilancarkan oleh OpenAI, yang telah menyebabkan perbincangan meluas. Pada masa yang sama, dalam bidang penyuntingan video, model AI berskala besar seperti Agent juga telah menunjukkan kekuatan yang kukuh.
Walaupun bahasa semula jadi digunakan untuk mengendalikan tugasan penyuntingan video, pengguna boleh terus menyatakan hasrat mereka tanpa operasi manual. Walau bagaimanapun, kebanyakan alat penyuntingan video semasa masih memerlukan banyak operasi manual dan kekurangan sokongan kontekstual yang diperibadikan. Ini menyebabkan pengguna perlu menyelesaikan masalah penyuntingan video yang rumit sendiri.
Kuncinya ialah bagaimana untuk mereka bentuk alat penyuntingan video yang boleh bertindak sebagai kolaborator dan membantu pengguna secara berterusan semasa proses penyuntingan? Dalam artikel ini, penyelidik dari University of Toronto, Meta (Reality Labs Research), dan University of California, San Diego mencadangkan untuk menggunakan keupayaan bahasa pelbagai fungsi model bahasa besar (LLM) untuk penyuntingan video dan meneroka masa depan paradigma penyuntingan video, dengan itu Mengurangkan kekecewaan dengan proses penyuntingan video manual. . Penyelidikan Penulis membangunkan alat penyuntingan video yang dipanggil LAVE, yang mengintegrasikan pelbagai fungsi peningkatan bahasa yang disediakan oleh LLM. LAVE memperkenalkan sistem perancangan dan pelaksanaan pintar berdasarkan LLM, yang boleh mentafsir arahan bahasa bentuk bebas pengguna, merancang dan melaksanakan operasi berkaitan untuk mencapai matlamat penyuntingan video pengguna. Sistem pintar ini menyediakan bantuan konsep, seperti sumbangsaran kreatif dan gambaran keseluruhan rakaman video, serta bantuan operasi, termasuk pengambilan video berasaskan semantik, papan cerita dan pemangkasan klip.
 Untuk mengendalikan ejen ini dengan lancar, LAVE menggunakan model bahasa visual (VLM) untuk menjana penerangan bahasa secara automatik bagi kesan visual video. Naratif visual ini membolehkan LLM memahami kandungan video dan menggunakan keupayaan bahasa mereka untuk membantu pengguna mengedit. Selain itu, LAVE menyediakan dua mod penyuntingan video interaktif iaitu bantuan ejen dan operasi terus. Mod dwi ini memberikan pengguna fleksibiliti yang lebih besar untuk meningkatkan operasi ejen mengikut keperluan.
Untuk mengendalikan ejen ini dengan lancar, LAVE menggunakan model bahasa visual (VLM) untuk menjana penerangan bahasa secara automatik bagi kesan visual video. Naratif visual ini membolehkan LLM memahami kandungan video dan menggunakan keupayaan bahasa mereka untuk membantu pengguna mengedit. Selain itu, LAVE menyediakan dua mod penyuntingan video interaktif iaitu bantuan ejen dan operasi terus. Mod dwi ini memberikan pengguna fleksibiliti yang lebih besar untuk meningkatkan operasi ejen mengikut keperluan.
- Adapun kesan penyuntingan LAVE? Para penyelidik menjalankan kajian pengguna dengan 8 peserta, termasuk editor baru dan berpengalaman, dan keputusan menunjukkan bahawa peserta boleh menggunakan LAVE untuk mencipta video kolaboratif AI yang memuaskan.
- Perlu diperhatikan bahawa 5 daripada enam pengarang kajian ini adalah orang Cina, termasuk Yi Zuo, Bryan Wang, pelajar kedoktoran dalam sains komputer di Universiti Toronto, saintis penyelidikan Meta Yuliang Li, Zhaoyang Lv dan Yan Xu , Universiti California, San Diego Penolong Profesor Haijun Xia.
LAVE User Interface (UI)
Mari kita lihat dahulu reka bentuk sistem LAVE, seperti yang ditunjukkan dalam Rajah 1 di bawah.
Antara muka pengguna LAVE terdiri daripada tiga komponen utama, seperti berikut:
Pustaka video yang dipertingkatkan bahasa, yang memaparkan klip video dengan penerangan bahasa yang dijana secara automatik
, termasuk keratan video berdasarkan garis masa utama; garis masa klip;Ejen Klip Video membolehkan pengguna berinteraksi dan mendapatkan bantuan daripada ejen perbualan.
Logik reka bentuk adalah ini: apabila pengguna berinteraksi dengan ejen, pertukaran mesej akan dipaparkan dalam UI sembang. Apabila berbuat demikian, ejen membuat perubahan pada pustaka video dan garis masa klip. Di samping itu, pengguna boleh terus mengendalikan pustaka video dan garis masa menggunakan kursor, sama seperti antara muka penyuntingan tradisional.
- Perpustakaan Video Peningkatan Bahasa
- Fungsi perpustakaan video peningkatan bahasa ditunjukkan dalam Rajah 3 di bawah.
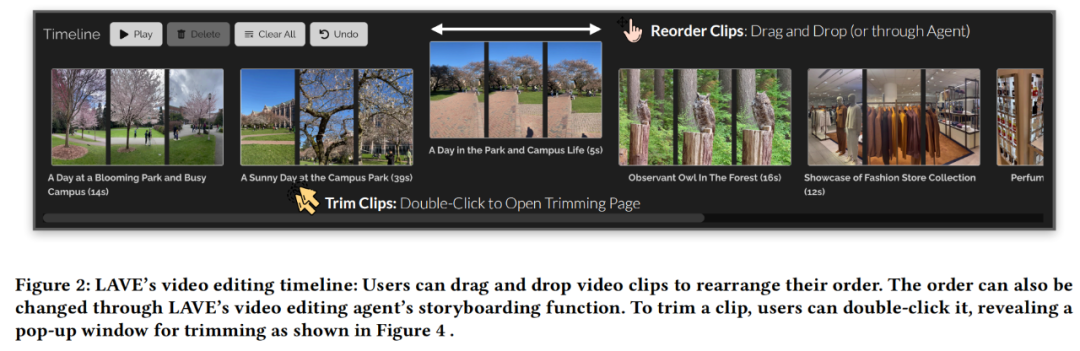
Selain itu, LAVE membolehkan pengguna mencari video menggunakan pertanyaan bahasa semantik, dan video yang diambil dipaparkan dalam pustaka video dan diisih mengikut kaitan. Fungsi ini mesti dilakukan oleh Agen Klip. Garis Masa Klip Video Selepas memilih video daripada pustaka video dan menambahkannya pada garis masa klip, ia akan dipaparkan pada garis masa klip video di bahagian bawah antara muka, seperti yang ditunjukkan dalam Rajah 2 di bawah . Setiap klip pada garis masa diwakili oleh kotak dan memaparkan tiga bingkai lakaran kecil: bingkai permulaan, bingkai tengah dan bingkai akhir. Dalam sistem LAVE, setiap bingkai lakaran kecil mewakili satu saat bahan dalam klip. Seperti galeri video, tajuk dan penerangan disediakan untuk setiap klip. Garis masa klip dalam LAVE mempunyai dua ciri utama, pengisihan dan pemangkasan klip. Menjujukan klip pada garis masa ialah tugas biasa dalam penyuntingan video dan penting untuk mencipta naratif yang koheren. LAVE menyokong dua kaedah pengisihan Satu ialah pengisihan berasaskan LLM, yang menggunakan fungsi papan cerita bagi ejen klip video, yang diisih mengikut operasi pengguna langsung untuk menetapkan susunannya klip muncul. Pemangkasan juga penting dalam penyuntingan video untuk menyerlahkan segmen utama dan mengalih keluar kandungan berlebihan. Semasa memangkas, pengguna mengklik dua kali pada klip dalam garis masa, yang membuka tetingkap pop timbul yang menunjukkan bingkai satu saat, seperti yang ditunjukkan dalam Rajah 4 di bawah. Ejen Klip Video LAVE adalah komponen berasaskan sembang yang memudahkan interaksi antara pengguna dan ejen berasaskan LLM. Tidak seperti alat baris arahan, pengguna boleh berinteraksi dengan ejen menggunakan bahasa bentuk bebas. Ejen itu memanfaatkan kecerdasan linguistik LLM untuk menyediakan bantuan penyuntingan video dan memberikan respons khusus untuk membimbing dan membantu pengguna sepanjang proses penyuntingan. Fungsi bantuan ejen LAVE disediakan melalui operasi ejen, setiap satunya melibatkan melaksanakan fungsi penyuntingan yang disokong sistem. Sistem backendKajian ini menggunakan GPT-4 OpenAI untuk menggambarkan reka bentuk sistem backend LAVE, yang terutamanya merangkumi dua aspek: reka bentuk ejen dan pelaksanaan fungsi penyuntingan yang didorong oleh LLM. Reka Bentuk Ejen
Ejen LAVE mempunyai dua keadaan: perancangan dan pelaksanaan. Persediaan ini mempunyai dua faedah utama: membolehkan pengguna menetapkan matlamat peringkat tinggi yang mengandungi berbilang tindakan, menghapuskan keperluan untuk memperincikan setiap tindakan individu seperti alatan baris arahan tradisional.
Seperti yang ditunjukkan dalam Rajah 6 di bawah, saluran paip mula-mula mencipta pelan tindakan berdasarkan input pengguna. Pelan itu kemudiannya ditukar daripada penerangan teks kepada panggilan fungsi, dan fungsi yang sepadan kemudiannya dilaksanakan. Ikhtisar bahan empat daripadanya boleh diakses melalui ejen (Rajah 5), The fungsi pemangkasan klip boleh membuka tetingkap pop timbul yang menunjukkan bingkai satu saat dengan mengklik dua kali klip dalam garis masa (Rajah 4). 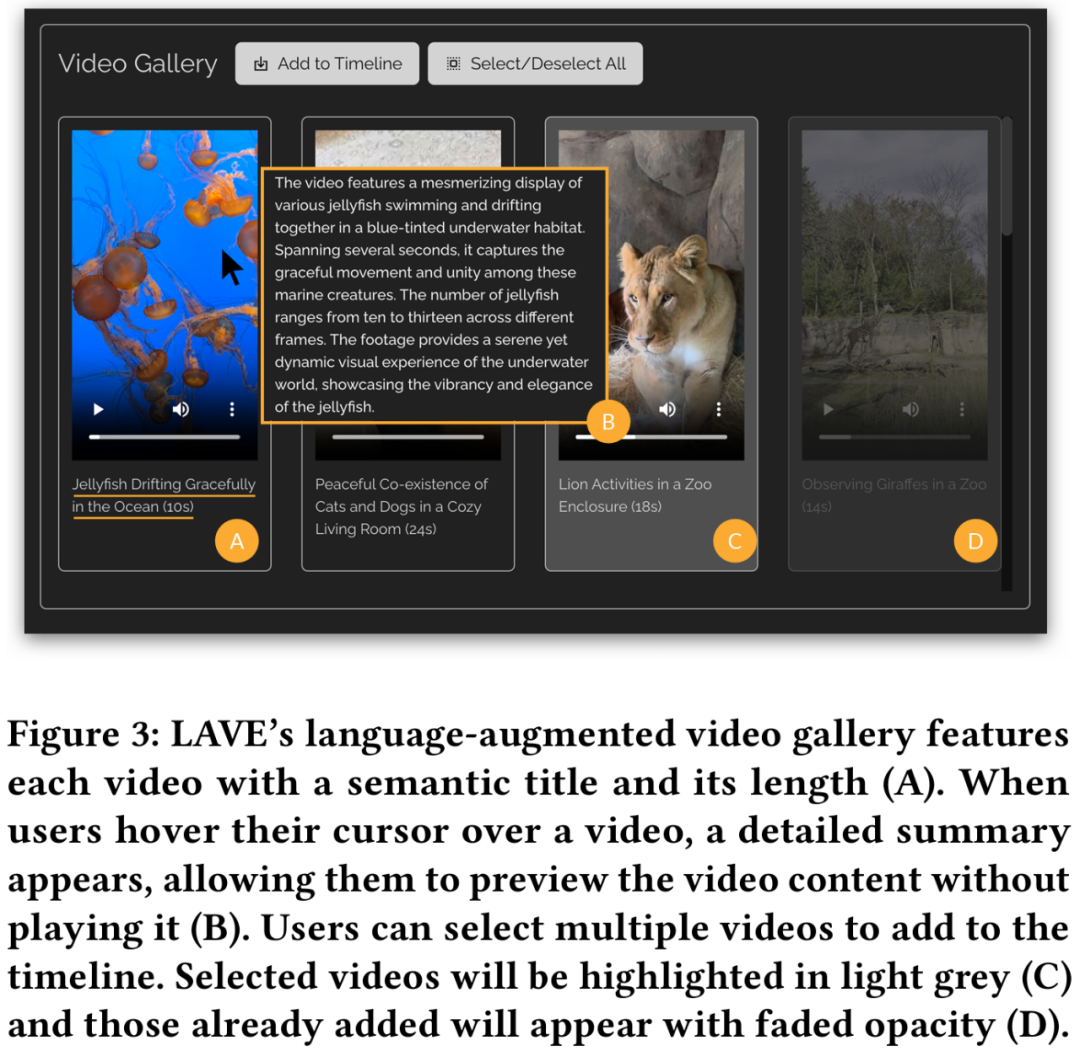
 Secara amnya, LAVE menyediakan ciri yang merangkumi keseluruhan aliran kerja daripada idea dan pra-perancangan kepada operasi penyuntingan sebenar, tetapi sistem tidak mewajibkan aliran kerja yang ketat. Pengguna mempunyai fleksibiliti untuk memanfaatkan subset fungsi yang sepadan dengan matlamat pengeditan mereka. Sebagai contoh, pengguna yang mempunyai visi editorial yang jelas dan jalan cerita yang jelas boleh memintas fasa idea dan terus menyunting.
Secara amnya, LAVE menyediakan ciri yang merangkumi keseluruhan aliran kerja daripada idea dan pra-perancangan kepada operasi penyuntingan sebenar, tetapi sistem tidak mewajibkan aliran kerja yang ketat. Pengguna mempunyai fleksibiliti untuk memanfaatkan subset fungsi yang sepadan dengan matlamat pengeditan mereka. Sebagai contoh, pengguna yang mempunyai visi editorial yang jelas dan jalan cerita yang jelas boleh memintas fasa idea dan terus menyunting. Penyelidikan ini memanfaatkan pelbagai keupayaan bahasa LLM (iaitu GPT-4), termasuk penaakulan, perancangan dan penceritaan, untuk membina ejen LAVE.
Untuk membantu pengguna menyelesaikan tugas penyuntingan video, LAVE terutamanya menyokong lima fungsi dipacu LLM, termasuk:
Atas ialah kandungan terperinci Apabila Sora meletupkan penjanaan video, Meta mula menggunakan Agent untuk memotong video secara automatik, diketuai oleh pengarang Cina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!