
Rumah >Peranti teknologi >AI >Senarai teratas antarabangsa yang berwibawa bagi penghuraian semantik perbualan SParC dan CoSQL, model pra-latihan pengetahuan meja dialog pelbagai pusingan baharu tafsiran STAR
Senarai teratas antarabangsa yang berwibawa bagi penghuraian semantik perbualan SParC dan CoSQL, model pra-latihan pengetahuan meja dialog pelbagai pusingan baharu tafsiran STAR

- 王林ke hadapan
- 2023-05-18 19:50:581612semak imbas
Dalam era Internet yang sedang berkembang pesat, pelbagai jenis data sentiasa muncul Antaranya, data jadual adalah yang paling biasa digunakan adalah sejenis data berstruktur umum Pernyataan untuk mendapatkan pengetahuan dalam jadual, tetapi selalunya memerlukan kos reka bentuk dan kos pembelajaran yang lebih tinggi. Pada masa ini, tugas penghuraian Text-to-SQL adalah sangat penting Mengikut senario dialog yang berbeza, ia juga dibahagikan kepada penghuraian Teks-ke-SQL pusingan tunggal dan penghuraian Teks-ke-SQL berbilang pusingan Artikel ini mengkaji Pusingan berbilang tugasan penghuraian Teks-ke-SQL yang lebih sukar dan lebih dekat untuk aplikasi dunia sebenar.
Baru-baru ini, Alibaba Damo Academy dan Shenzhen Institute of Advanced Technology of the Chinese Academy of Sciences mencadangkan model pra-latihan berorientasikan pertanyaan SQL STAR untuk beberapa pusingan Text-to- Penghuraian semantik SQL. Setakat ini, STAR telah menduduki tempat pertama dalam senarai SParC dan CoSQL selama 10 bulan berturut-turut. Kertas penyelidikan itu telah diterima oleh Penemuan EMNLP 2022, persidangan antarabangsa dalam bidang pemprosesan bahasa semula jadi.

- Alamat kertas: https://arxiv.org/abs/2210.11888
- Alamat kod: https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/star
STAR ialah model bahasa pra-latihan pengetahuan jadual dialog pelbagai pusingan yang berkesan dan berkesan Model ini menggunakan dua objektif pra-latihan untuk menjejaki semantik kontekstual dan corak pangkalan data dalam dialog berbilang pusingan. Penjejakan negeri dimodelkan dengan matlamat untuk mempertingkatkan perwakilan pengekodan pertanyaan bahasa semula jadi dan skema pangkalan data dalam aliran perbualan.
Penyelidikan telah dinilai pada SParC dan CoSQL, senarai penghuraian semantik perbualan yang berwibawa Di bawah perbandingan model hiliran yang adil, STAR berbanding dengan prapemprosesan meja berbilang bulat terbaik sebelum ini Untuk model latihan SCoRe, QM/IM bertambah baik sebanyak 4.6%/3.3% pada set data SParC dan QM/IM meningkat dengan ketara sebanyak 7.4%/8.5% pada set data CoSQL. Khususnya, CoSQL mempunyai lebih banyak perubahan kontekstual daripada dataset SParC, yang mengesahkan keberkesanan tugas pra-latihan yang dicadangkan dalam kajian ini.
Pengenalan latar belakang
Untuk membolehkan pengguna berinteraksi dengan pangkalan data melalui dialog bahasa semula jadi walaupun mereka tidak biasa dengan sintaks SQL, beberapa pusingan Text-to -SQL parsing Tugas itu wujud, yang bertindak sebagai jambatan antara pengguna dan pangkalan data, menukar soalan bahasa semula jadi dalam interaksi kepada penyataan pertanyaan SQL boleh laku.
Model pra-latihan telah menyinari pelbagai tugas NLP sejak beberapa tahun kebelakangan ini, tetapi disebabkan perbezaan yang wujud antara jadual dan bahasa semula jadi, model bahasa pra-latihan biasa (seperti BERT, RoBERTa ) tidak dapat mencapai prestasi optimum pada tugasan ini, jadi model jadual terlatih (TaLM) [1-5] telah wujud. Secara amnya, model jadual terlatih (TaLM) perlu menangani dua isu teras, termasuk cara memodelkan kebergantungan kompleks (rujukan, mengimbangi niat) antara pertanyaan kontekstual dan cara menggunakan hasil SQL yang dijana mengikut sejarah dengan berkesan. Untuk menangani dua isu teras di atas, model jadual pra-latihan sedia ada mempunyai kelemahan berikut:
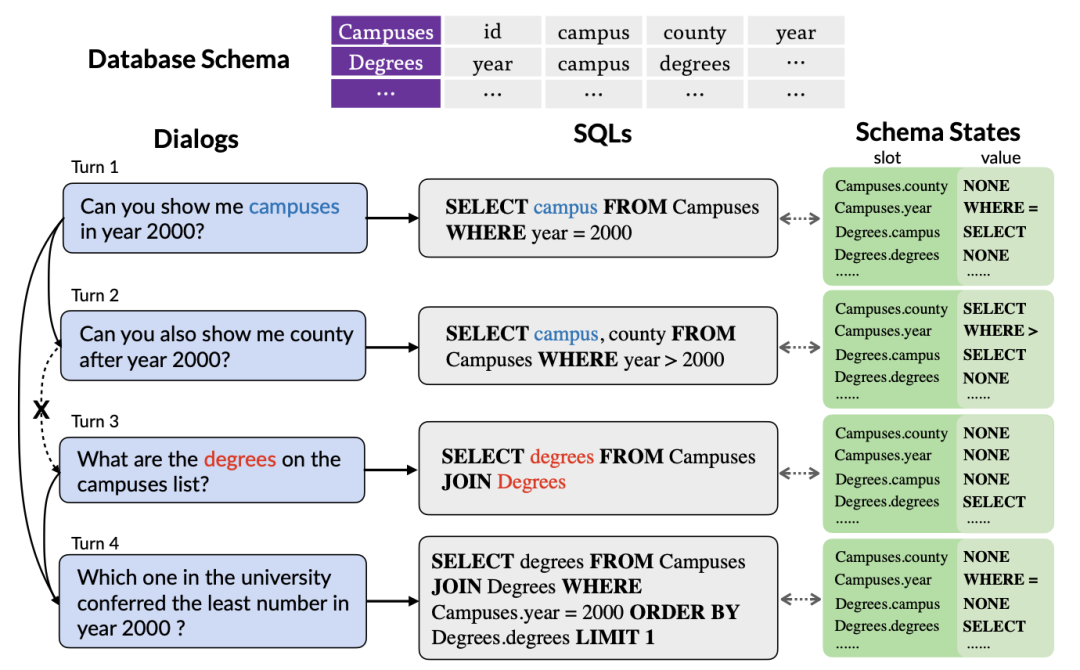
Rajah 1. A konteks Contoh penghuraian Teks-ke-SQL berbilang pusingan bergantung.
Pertama, model pra-latihan jadual sedia ada hanya meneroka maklumat kontekstual pertanyaan bahasa semula jadi tanpa mengambil kira interaksi yang terkandung dalam pernyataan pertanyaan SQL sejarah, yang sering meringkaskan niat pengguna dalam bentuk yang lebih tepat dan padat. Oleh itu, pemodelan dan penjejakan maklumat SQL sejarah boleh menangkap maksud pusingan pertanyaan semasa dengan lebih baik, dengan itu menjana pernyataan pertanyaan SQL yang sepadan dengan lebih tepat. Seperti yang ditunjukkan dalam Rajah 1, memandangkan nama jadual "Kompus" disebut dalam pusingan pertama pertanyaan SQL, jadual mungkin akan dipilih semula dalam pusingan kedua pertanyaan SQL, jadi adalah penting untuk menjejaki status nama jadual "Kompus" penting.
Kedua, memandangkan pengguna mungkin mengabaikan entiti yang disebut dalam sejarah perbualan atau memperkenalkan beberapa rujukan, mengakibatkan kekurangan maklumat dialog dalam pusingan semasa, tugas penghuraian Teks-ke-SQL berbilang pusingan perlu memodelkan kontekstual dengan berkesan maklumat Untuk menghuraikan dengan lebih baik pusingan semasa dialog bahasa semula jadi. Seperti yang ditunjukkan dalam Rajah 1, pusingan kedua dialog telah meninggalkan "kampus pada tahun 2000" yang disebut dalam pusingan pertama dialog. Walau bagaimanapun, kebanyakan model jadual pra-latihan sedia ada tidak mempertimbangkan maklumat kontekstual, tetapi model setiap pusingan dialog bahasa semula jadi secara berasingan. Walaupun SCoRe [1] memodelkan maklumat suis konteks dengan meramalkan label suis konteks antara dua pusingan dialog bersebelahan, ia mengabaikan maklumat konteks yang lebih kompleks dan tidak dapat menjejaki maklumat pergantungan antara dialog jarak jauh. Sebagai contoh, dalam Rajah 1, disebabkan penukaran konteks antara pusingan kedua dan ketiga dialog, SCoRe tidak dapat menangkap maklumat pergantungan jarak jauh antara pusingan pertama dan keempat dialog.
Diinspirasikan oleh tugas penjejakan keadaan perbualan dalam perbualan berbilang pusingan, penyelidikan ini mencadangkan sasaran pra-latihan penjejakan keadaan corak untuk menjejak keadaan pola konteks SQL untuk dialog berbilang pusingan Masalah kebergantungan semantik yang kompleks antara soalan dalam dialog Penyelidikan ini mencadangkan kaedah penjejakan ketergantungan dialog untuk menangkap kebergantungan semantik yang kompleks antara pelbagai pusingan dialog, dan mencadangkan kaedah pembelajaran kontrastif berasaskan berat untuk memodelkan contoh positif antara dialog dan negatif perhubungan.
Definisi Masalah
Kajian ini mula-mula memberikan tatatanda dan definisi masalah yang terlibat dalam berbilang pusingan tugas penghuraian Teks-ke-SQL. 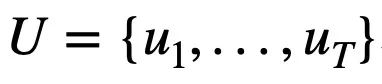 mewakili pusingan T pertanyaan bahasa semula jadi, berbilang pusingan interaksi dialog Teks-ke-SQL pertanyaan, dengan
mewakili pusingan T pertanyaan bahasa semula jadi, berbilang pusingan interaksi dialog Teks-ke-SQL pertanyaan, dengan 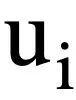 mewakili pusingan ke-i bahasa semula jadi soalan, setiap pusingan Perbualan bahasa semula jadi
mewakili pusingan ke-i bahasa semula jadi soalan, setiap pusingan Perbualan bahasa semula jadi 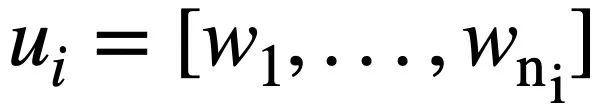 mengandungi
mengandungi 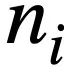 token. Selain itu, terdapat pangkalan data interaktif s, yang mengandungi N jadual
token. Selain itu, terdapat pangkalan data interaktif s, yang mengandungi N jadual 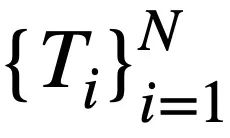 , dan semua jadual mengandungi m nama jadual dan nama lajur,
, dan semua jadual mengandungi m nama jadual dan nama lajur, 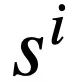 mewakili skema pangkalan data The ith nama jadual atau nama lajur dalam s. Dengan mengandaikan bahawa pusingan semasa ialah pusingan ke-t, tujuan tugas penghuraian Text-to-SQL adalah untuk berdasarkan pusingan semasa pertanyaan bahasa semula jadi
mewakili skema pangkalan data The ith nama jadual atau nama lajur dalam s. Dengan mengandaikan bahawa pusingan semasa ialah pusingan ke-t, tujuan tugas penghuraian Text-to-SQL adalah untuk berdasarkan pusingan semasa pertanyaan bahasa semula jadi 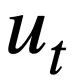 , pertanyaan sejarah
, pertanyaan sejarah  , skema pangkalan data dan Pernyataan pertanyaan SQL
, skema pangkalan data dan Pernyataan pertanyaan SQL 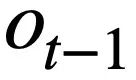 yang diramalkan dalam pusingan sebelumnya menjana pernyataan pertanyaan SQL
yang diramalkan dalam pusingan sebelumnya menjana pernyataan pertanyaan SQL 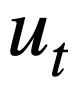 sepadan dengan pertanyaan bahasa semula jadi
sepadan dengan pertanyaan bahasa semula jadi 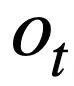 dalam pusingan semasa.
dalam pusingan semasa.
Penerangan Kaedah
Seperti yang ditunjukkan dalam Rajah 2, kajian ini mencadangkan rangka kerja pra-latihan jadual berbilang bulat berdasarkan panduan SQL, yang menggunakan sepenuhnya maklumat berstruktur SQL sejarah untuk memperkaya perwakilan dialog Oleh itu, maklumat kontekstual yang kompleks boleh dimodelkan dengan lebih berkesan.
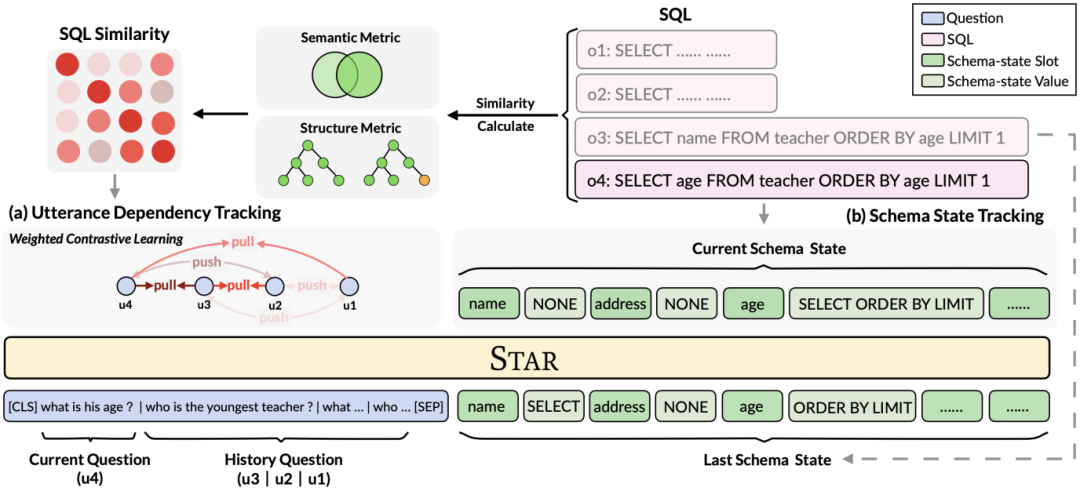
Rajah 2. Rangka kerja model STAR.
Secara khusus, kajian ini mencadangkan matlamat pra-latihan jadual berdasarkan penjejakan status mod dan penjejakan pergantungan dialog, masing-masing, untuk pernyataan pertanyaan SQL dalam berbilang pusingan interaksi. dan menjejaki kehendak soalan bahasa semula jadi. (1) Dalam situasi dialog berbilang pusingan, pertanyaan SQL bagi dialog semasa bergantung pada maklumat SQL kontekstual Oleh itu, diilhamkan oleh tugas penjejakan keadaan perbualan dalam dialog berbilang giliran, penyelidikan ini mencadangkan Penjejakan Negeri Skema (Keadaan Skema. Objektif pra-latihan jadual Tracking, SST menjejaki keadaan skema pernyataan pertanyaan SQL sensitif konteks (atau permintaan pengguna) dengan cara yang diselia sendiri. (2) Untuk masalah kebergantungan semantik yang kompleks antara soalan bahasa semula jadi dalam dialog berbilang giliran, matlamat pra-latihan jadual berdasarkan Penjejakan Ketergantungan Ujaran (UDT) dicadangkan, dan kaedah pembelajaran kontrastif berasaskan berat digunakan untuk belajar dengan lebih baik. Perwakilan ciri untuk pertanyaan bahasa semula jadi. Berikut menerangkan dua jadual matlamat pra-latihan secara terperinci.
Jadualkan sasaran pralatihan berdasarkan penjejakan keadaan corak
Penyelidikan ini mencadangkan objektif pra-latihan jadual berdasarkan penjejakan keadaan skema, yang menjejaki keadaan skema (atau permintaan pengguna) pernyataan pertanyaan SQL sensitif konteks dengan cara yang diselia sendiri, dengan tujuan meramal nilai slot skema. Secara khusus, kajian menjejaki keadaan interaksi sesi Teks-ke-SQL dalam bentuk keadaan skema, di mana slot ialah skema pangkalan data (iaitu, nama lajur semua jadual) dan nilai slot yang sepadan ialah kata kunci SQL. Mengambil pertanyaan SQL dalam Rajah 3 sebagai contoh, nilai slot mod "[car_data]" ialah kata kunci SQL "[SELECT]". Pertama, kajian menukar pernyataan pertanyaan SQL 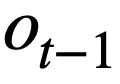 yang diramalkan dalam pusingan t - 1 ke dalam bentuk set keadaan corak. Memandangkan slot status skema ialah nama lajur semua jadual dalam pangkalan data, nilai yang tidak muncul dalam status skema yang sepadan dengan pernyataan pertanyaan SQL
yang diramalkan dalam pusingan t - 1 ke dalam bentuk set keadaan corak. Memandangkan slot status skema ialah nama lajur semua jadual dalam pangkalan data, nilai yang tidak muncul dalam status skema yang sepadan dengan pernyataan pertanyaan SQL 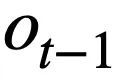 ditetapkan kepada [TIADA] . Seperti yang ditunjukkan dalam Rajah 3, kajian ini menggunakan keadaan mod m
ditetapkan kepada [TIADA] . Seperti yang ditunjukkan dalam Rajah 3, kajian ini menggunakan keadaan mod m 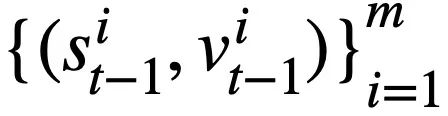 untuk mewakili pernyataan pertanyaan SQL
untuk mewakili pernyataan pertanyaan SQL 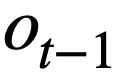 , dengan
, dengan 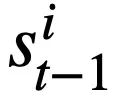 mewakili i -th Slot keadaan mod,
mewakili i -th Slot keadaan mod, 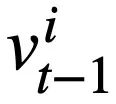 mewakili nilai keadaan mod. Untuk pusingan ke-3, matlamat penjejakan keadaan corak adalah untuk menjejaki semua soalan bahasa semula jadi sejarah
mewakili nilai keadaan mod. Untuk pusingan ke-3, matlamat penjejakan keadaan corak adalah untuk menjejaki semua soalan bahasa semula jadi sejarah 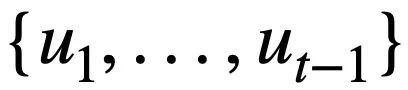 , soalan semasa
, soalan semasa 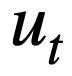 dan pusingan sebelumnya pernyataan pertanyaan SQL Dalam kes status mod
dan pusingan sebelumnya pernyataan pertanyaan SQL Dalam kes status mod 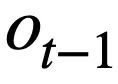 daripada
daripada 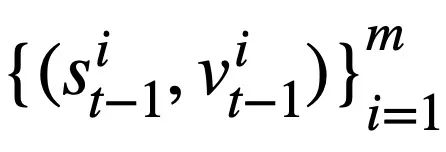 , ramalkan nilai setiap slot status mod
, ramalkan nilai setiap slot status mod 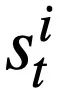 pusingan ke-t daripada pernyataan pertanyaan SQL
pusingan ke-t daripada pernyataan pertanyaan SQL 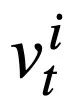 . Maksudnya, pada pusingan t, input sasaran pra-latihan pengesanan keadaan mod
. Maksudnya, pada pusingan t, input sasaran pra-latihan pengesanan keadaan mod 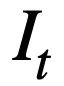 ialah:
ialah:
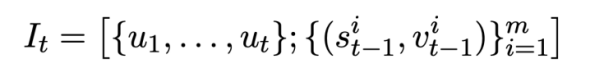
Memandangkan setiap keadaan corak 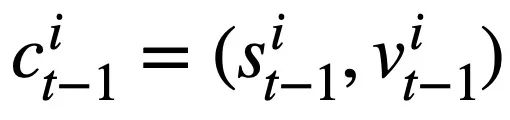 mengandungi berbilang perkataan, lapisan perhatian digunakan untuk mendapatkan perwakilan
mengandungi berbilang perkataan, lapisan perhatian digunakan untuk mendapatkan perwakilan 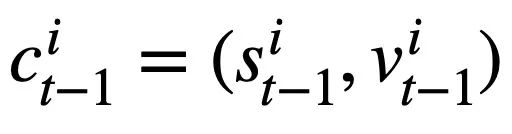 . Khususnya, memandangkan perwakilan kontekstual output
. Khususnya, memandangkan perwakilan kontekstual output  ( l ialah indeks permulaan
( l ialah indeks permulaan 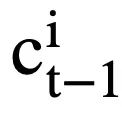 ). Untuk setiap keadaan mod
). Untuk setiap keadaan mod 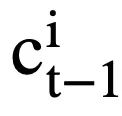 , perwakilan keadaan mod yang sedar perhatian
, perwakilan keadaan mod yang sedar perhatian 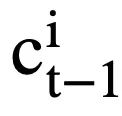
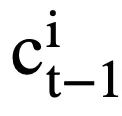 boleh dikira sebagai:
boleh dikira sebagai:
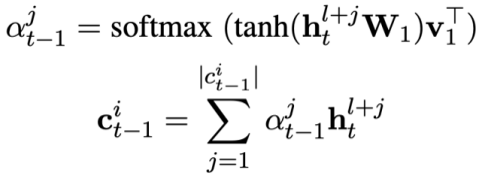
Kemudian ramalkan status mod masalah semasa:
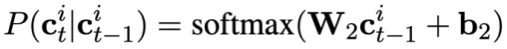
Akhir sekali, tukar status mod Fungsi kehilangan pra-latihan penjejakan boleh ditakrifkan sebagai:
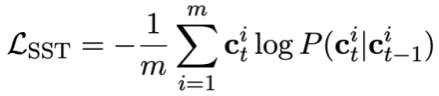
Objektif pra-latihan jadual berdasarkan penjejakan ketergantungan dialog
Kajian ini mencadangkan objektif pra-latihan untuk penjejakan kebergantungan ujaran, menggunakan kaedah pembelajaran kontrastif berasaskan berat untuk menangkap kebergantungan semantik yang kompleks antara soalan bahasa semula jadi dalam setiap Text-to -Hubungan sebutan SQL. Cabaran utama dalam pembelajaran kontrastif berasaskan berat ialah cara membina label contoh positif dan negatif yang sesuai dengan cara yang diselia sendiri Secara intuitif, pasangan contoh negatif boleh dibina dengan memilih soalan bahasa semula jadi daripada perbualan yang berbeza. Walau bagaimanapun, membina pasangan soalan positif bukanlah perkara remeh kerana soalan semasa mungkin tidak berkaitan dengan soalan sejarah di mana peralihan topik berlaku, seperti ujaran kedua dan ketiga yang ditunjukkan dalam Rajah 1. Oleh itu, kajian ini menangani soalan bahasa semula jadi dalam perbualan yang sama sebagai pasangan contoh positif dan memberikan mereka skor persamaan yang berbeza. SQL ialah petunjuk sebutan pengguna yang sangat berstruktur Oleh itu, dengan mengukur persamaan antara SQL semasa dan SQL sejarah, kita boleh mendapatkan label pseudo-label soalan bahasa semula jadi untuk mendapatkan skor persamaan untuk pembinaan pernyataan yang berbeza, dengan itu membimbing pembinaan konteks. Kajian ini mencadangkan kaedah untuk mengukur persamaan SQL dari kedua-dua perspektif semantik dan struktur. Seperti yang ditunjukkan dalam Rajah 3:

Rajah 3. Dua kaedah mengira persamaan pernyataan SQL.
Pengiraan persamaan SQL berasaskan semantik Kajian ini mengukur kesamaan antara dua pernyataan pertanyaan SQL dengan mengira kesamaan antara keduanya mereka. Khususnya, seperti yang ditunjukkan dalam Rajah 3, kaedah ini akan memperoleh status mod 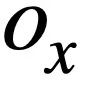
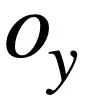 dan
dan 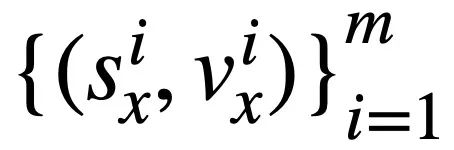 dan masing-masing. 🎜>
dan masing-masing. 🎜>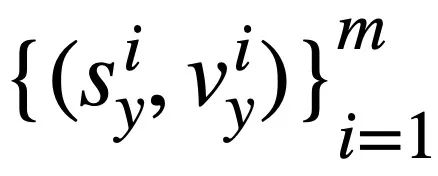 . Kemudian, kajian itu menggunakan persamaan Jaccard untuk mengira persamaan semantik antara mereka
. Kemudian, kajian itu menggunakan persamaan Jaccard untuk mengira persamaan semantik antara mereka 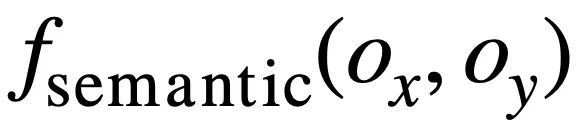 :
:
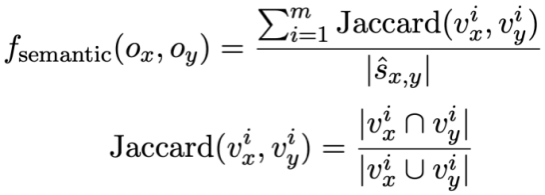
di mana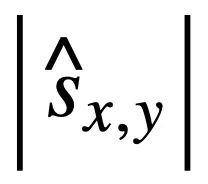 mewakili bilangan keadaan mod tidak berulang di mana nilai keadaan mod sepadan bukan [TIADA].
mewakili bilangan keadaan mod tidak berulang di mana nilai keadaan mod sepadan bukan [TIADA]. 
Untuk menggunakan SQL pertanyaan Struktur penyataan pepohon, kajian ini terlebih dahulu menghuraikan setiap pertanyaan SQL ke dalam pepohon SQL , seperti yang ditunjukkan dalam Rajah 3. Dua pokok SQL 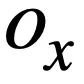 dan
dan 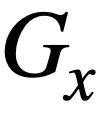 diberikan pertanyaan SQL
diberikan pertanyaan SQL 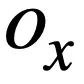 dan
dan 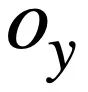 , kajian ini menggunakan algoritma Weisfeiler-Lehman untuk mengira skor persamaan struktur
, kajian ini menggunakan algoritma Weisfeiler-Lehman untuk mengira skor persamaan struktur
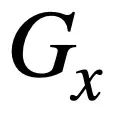 , formulanya adalah seperti berikut:
, formulanya adalah seperti berikut:
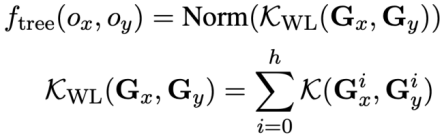
Ringkasnya, kajian ini mentakrifkan persamaan dua pernyataan pertanyaan SQL 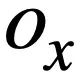 dan
dan 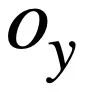 Markahnya adalah seperti berikut:
Markahnya adalah seperti berikut:
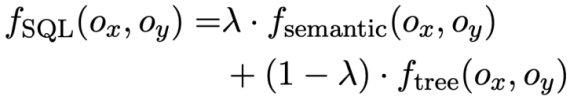
Kehilangan kontrastif berasaskan berat Selepas mendapat SQL Selepas persamaan, kajian ini menggunakan pembelajaran kontrastif berwajaran untuk mendekatkan representasi soalan bahasa tabii yang serupa secara semantik dalam perbualan dan menolak perwakilan soalan bahasa tabii yang tidak serupa secara semantik. Secara khusus, kajian pertama kali menggunakan mekanisme perhatian untuk mempelajari perwakilan input 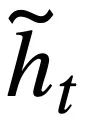 :
:
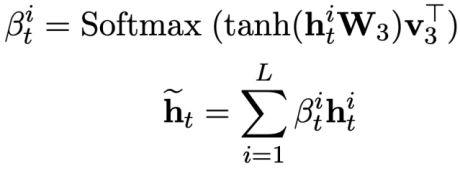
Kemudian, kajian Minimumkan fungsi kehilangan kontrastif berwajaran untuk mengoptimumkan rangkaian keseluruhan:
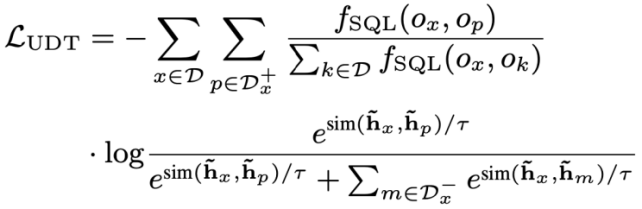
Akhir sekali, untuk mempelajari pertanyaan bahasa semula jadi berasaskan konteks dan perwakilan skema pangkalan data, Kajian ini juga mengamalkan objektif pra-latihan berdasarkan pemodelan semantik topeng, dan fungsi kehilangan dinyatakan sebagai. Berdasarkan tiga objektif latihan di atas, kajian ini mentakrifkan fungsi kehilangan sendi berdasarkan homoskedastisitas:
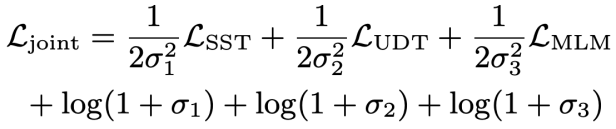
di mana, 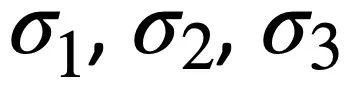 ialah parameter yang boleh dilatih.
ialah parameter yang boleh dilatih.
Hasil eksperimen
Dataset Penyelidikan ini berwibawa dalam dua penghuraian semantik perbualan Keberkesanan daripada model STAR telah disahkan menggunakan set data SParC dan CoSQL. Antaranya, SParC ialah set data penghuraian Teks-ke-SQL berbilang domain merentas domain, mengandungi kira-kira 4,300 interaksi berbilang pusingan dan lebih daripada 12,000 pasangan pernyataan pertanyaan-SQL bahasa semula jadi CoSQL ialah teks perbualan merentas domain; set data penghuraian ke-SQL ke set data penghuraian SQL, mengandungi kira-kira 3,000 interaksi perbualan dan lebih daripada 10,000 pasangan pernyataan pertanyaan-SQL bahasa semula jadi. Berbanding dengan SParC, konteks perbualan CoSQL adalah lebih relevan dari segi semantik, dan sintaks pernyataan pertanyaan SQL adalah lebih kompleks.
Model Penanda Aras Dari segi model penanda aras, kajian membandingkan kaedah berikut: (1) GAZP [6], dengan menggabungkan satu hadapan Model penghuraian semantik ke hadapan dan model penjanaan dialog ke belakang mensintesis data latihan pasangan pernyataan pertanyaan dialog-SQL bahasa semula jadi, dan akhirnya pilih data dengan ketekalan kitaran agar sesuai dengan model penghuraian semantik ke hadapan. (2) EditSQL [7], dengan mengambil kira maklumat sejarah interaksi, meningkatkan kualiti penjanaan SQL bagi pusingan dialog semasa dengan meramalkan pernyataan pertanyaan SQL pada masa sebelum mengedit. (3) IGSQL [8] mencadangkan model pengekodan graf interaktif skema pangkalan data, yang menggunakan maklumat sejarah skema pangkalan data untuk menangkap maklumat sejarah input bahasa semula jadi, dan memperkenalkan mekanisme gating dalam peringkat penyahkodan. (4) IST-SQL [9], diilhamkan oleh tugas penjejakan keadaan perbualan, mentakrifkan dua keadaan interaktif, keadaan skema dan keadaan SQL, dan mengemas kini keadaan mengikut ramalan pernyataan pertanyaan SQL terakhir dalam setiap pusingan. (5) R2SQL [10] mencadangkan rangka kerja graf dinamik untuk memodelkan interaksi kompleks antara dialog dan skema pangkalan data dalam aliran dialog, dan memperkayakan perwakilan kontekstual dialog dan skema pangkalan data melalui mekanisme pereputan memori dinamik. (6) PICARD [11] mencadangkan penghuraian semantik tambahan untuk mengekang model penyahkodan autoregresif model bahasa Dalam setiap langkah penyahkodan, ia mencari jujukan keluaran yang sah dengan mengekang kebolehterimaan hasil penyahkodan. (7) DELTA [12], mula-mula menggunakan model penulisan semula dialog untuk menyelesaikan masalah integriti konteks dialog, dan kemudian memasukkan dialog lengkap ke dalam model penghuraian semantik Teks-ke-SQL pusingan tunggal untuk mendapatkan pernyataan pertanyaan SQL akhir. (8) HIE-SQL [13], dari perspektif multimodal, memperlakukan bahasa semula jadi dan SQL sebagai dua modaliti, meneroka maklumat kebergantungan konteks antara semua perbualan sejarah dan pernyataan pertanyaan SQL yang diramalkan oleh ayat sebelumnya, dan mencadangkan A bimodal pra- model terlatih dan mereka bentuk graf pautan modal antara perbualan dan pernyataan pertanyaan SQL.
Keputusan eksperimen keseluruhan Seperti yang ditunjukkan dalam Rajah 4, dapat dilihat daripada keputusan eksperimen bahawa STAR model mempunyai prestasi terbaik dalam SParC Kesan pada dua set data CoSQL dan CoSQL adalah jauh lebih baik daripada kaedah perbandingan lain. Dari segi perbandingan model pra-latihan, model STAR jauh melebihi model pra-latihan yang lain (seperti BERT, RoBERTa, GRAPPA, SCoRe Pada set data pembangun CoSQL, berbanding dengan model SCoRE, skor QM meningkat sebanyak 7.4). % dan skor IM meningkat sebanyak 7.5%. Dari segi perbandingan model Teks-ke-SQL hiliran, model LGESQL menggunakan STAR sebagai asas model pra-latihan adalah jauh lebih baik daripada kaedah hiliran yang menggunakan model bahasa pra-terlatih lain sebagai asas model LGESQL berprestasi terbaik menggunakan GRAPPA sebagai model HIE-SQL.
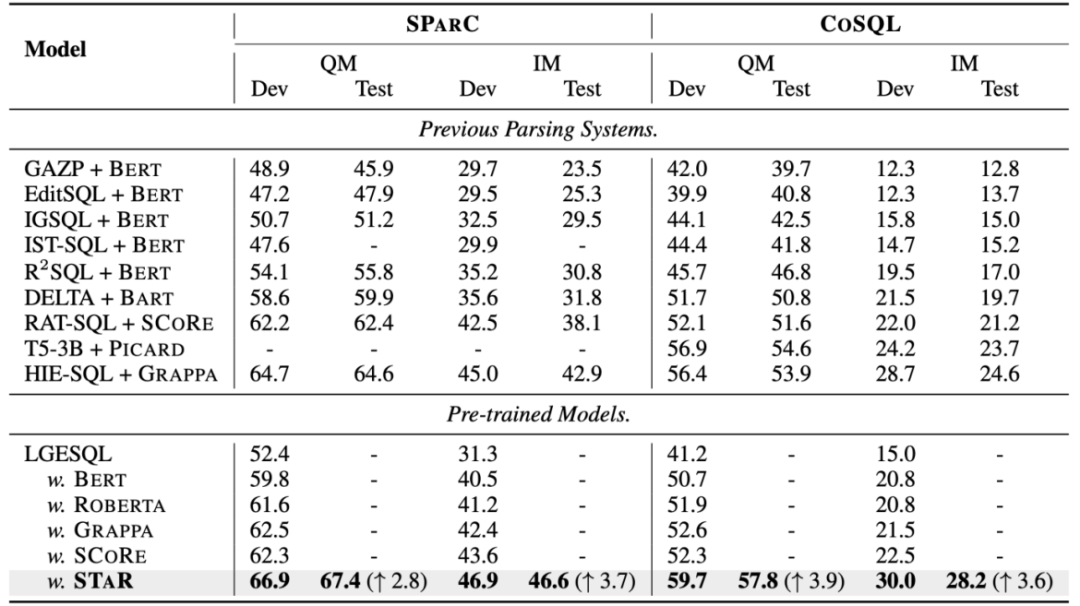
Rajah 4. Keputusan percubaan pada set data SParC dan CoSQL
Hasil Eksperimen Ablasi Artikel ini juga menambah eksperimen ablasi lengkap untuk menggambarkan keberkesanan setiap modul dalam model STAR. Keputusan eksperimen ablasi ditunjukkan dalam Rajah 5. Apabila sasaran pra-latihan SST atau UDT dialih keluar, kesannya akan menurun dengan ketara Walau bagaimanapun, keputusan eksperimen yang menggabungkan semua sasaran pra-latihan telah mencapai keputusan terbaik pada semua set data , yang menggambarkan bahawa kesahan SST dan UDT. Di samping itu, kajian ini menjalankan eksperimen lanjut ke atas dua kaedah pengiraan persamaan SQL dalam UDT Seperti yang dapat dilihat dari Rajah 6, kedua-dua kaedah pengiraan persamaan SQL boleh meningkatkan kesan model STAR, dan kesan gabungan adalah yang terbaik.
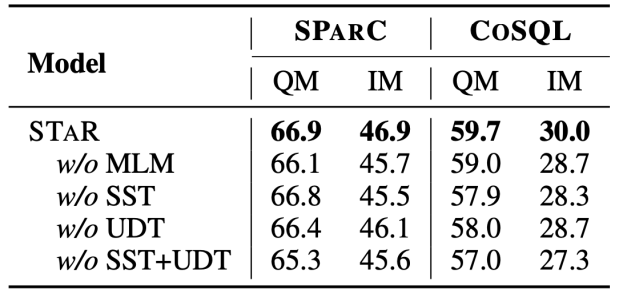
Rajah 5. Keputusan percubaan ablasi untuk sasaran pra-latihan.
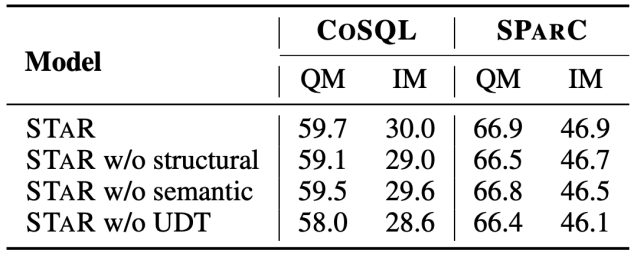
Rajah 6. Pengiraan persamaan untuk SQL Ablation keputusan eksperimen kaedah.
Kesan model pada sampel kesukaran yang berbeza Seperti yang ditunjukkan dalam Rajah 7, daripada keputusan eksperimen sampel kesukaran yang berbeza pada dua set data SParC dan CoSQL, dapat dilihat bahawa model STAR mempunyai ramalan yang jauh lebih baik. keputusan untuk sampel pelbagai kesukaran Lebih baik daripada kaedah perbandingan lain, kesannya adalah luar biasa walaupun dalam sampel yang lebih sukar.
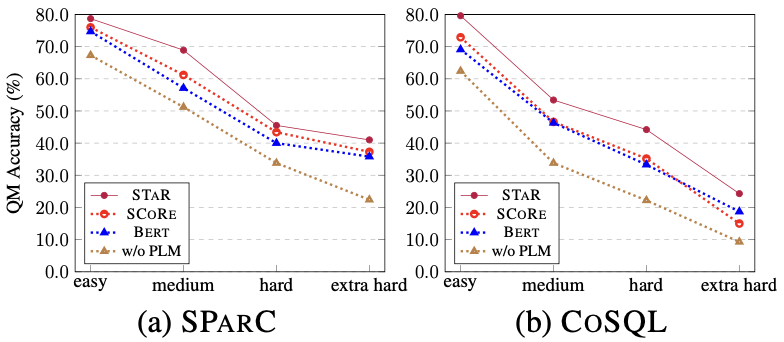
Rajah 7. Hasil percubaan sampel yang berbeza kesukaran pada set data SParC dan CoSQL.
Kesan model pusingan sampel yang berbeza Seperti yang ditunjukkan dalam Rajah 8, daripada Keputusan eksperimen bagi pusingan sampel yang berbeza pada dua set data SParC dan CoSQL dapat dilihat bahawa apabila bilangan pusingan dialog meningkat, indeks QM model garis dasar berkurangan dengan mendadak, manakala model STAR walaupun pada pusingan ketiga dan keempat. pusingan Boleh menunjukkan prestasi yang lebih stabil. Ini menunjukkan bahawa model STAR boleh menjejak dan meneroka keadaan interaksi dengan lebih baik dalam sejarah perbualan untuk membantu model menghuraikan perbualan semasa dengan lebih baik.
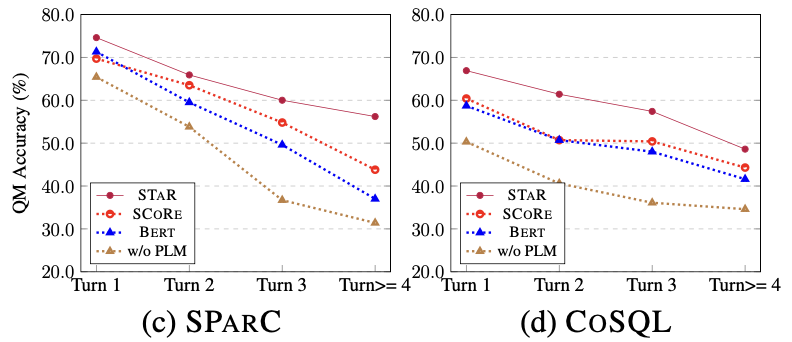
Rajah 8. Hasil eksperimen bagi pusingan sampel yang berbeza pada set data SParC dan CoSQL.
Analisis Kes Untuk menilai kesan sebenar model STAR, kajian ini bermula daripada CoSQL Dua sampel telah dipilih dalam set pengesahan, dan pernyataan pertanyaan SQL yang dihasilkan oleh model SCoRe dan model STAR dibandingkan dalam Rajah 9. Daripada contoh pertama, kita dapat melihat bahawa model STAR boleh menggunakan maklumat keadaan skema SQL sejarah (contohnya, [car_names.Model]), dengan itu menjana pernyataan pertanyaan SQL dengan betul untuk pusingan ketiga dialog, manakala SCoRe model tidak boleh Menjejaki maklumat status mod ini. Dalam contoh kedua, model STAR secara berkesan menjejaki kebergantungan perbualan jangka panjang antara pusingan pertama dan keempat sebutan, dan dengan menjejak dan merujuk "bilangan" mesej dalam pusingan kedua perbualan, dalam kata kunci keempat The SQL [ SELECT COUNT (*)] dijana dengan betul dalam pernyataan pertanyaan SQL bulat. Walau bagaimanapun, model SCoRe tidak dapat menjejaki pergantungan jangka panjang ini dan diganggu oleh pusingan ketiga sebutan untuk menjana pernyataan pertanyaan SQL yang salah.
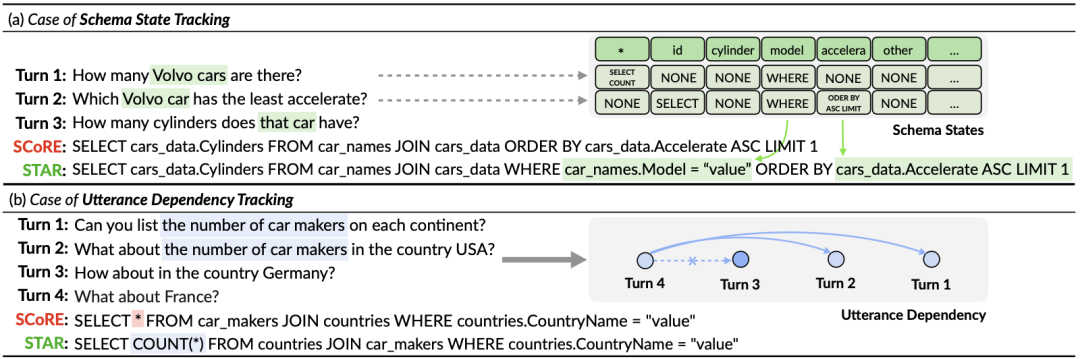
Rajah 9. Contoh analisis.
ModelScope model komuniti sumber terbuka
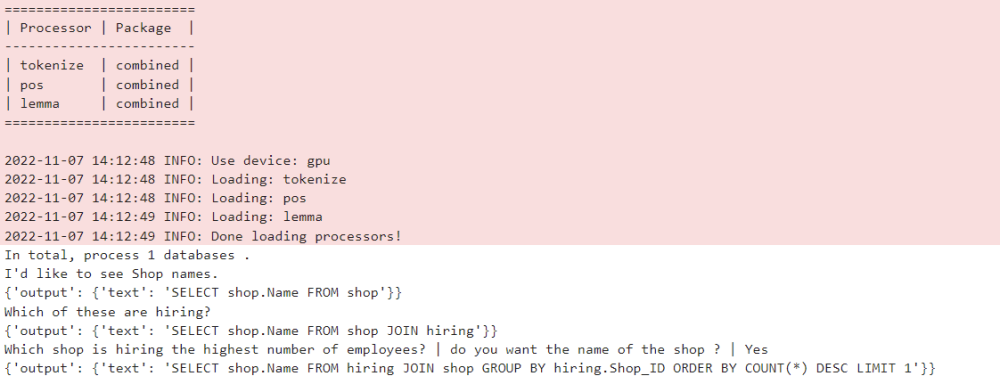
Model yang dilatih dalam artikel ini pada CoSQL set data , telah disepadukan ke dalam komuniti sumber terbuka modelScope. Pembaca boleh terus memilih persekitaran GPU V100 dalam buku nota dan menggunakan model demo untuk berbilang pusingan tugasan penghuraian semantik Teks-ke-SQL melalui saluran paip yang mudah.
Ringkasan
Dalam kertas kerja ini, pasukan penyelidik mencadangkan pelbagai novel dan berkesan - Model pra-latihan pengetahuan meja roda (model STAR). Untuk tugas penghuraian semantik Teks-ke-SQL berbilang pusingan, model STAR mencadangkan matlamat pra-latihan jadual berdasarkan penjejakan keadaan skema dan penjejakan kebergantungan dialog, yang masing-masing menjejaki niat pernyataan pertanyaan SQL dan soalan bahasa semula jadi dalam interaksi berbilang pusingan . Model STAR telah mencapai hasil yang sangat baik dalam dua senarai penghuraian semantik berbilang pusingan yang berwibawa, menduduki tempat pertama dalam senarai selama 10 bulan berturut-turut.
Akhir sekali, pelajar yang berminat dengan kumpulan SIAT-NLP Institut Teknologi Lanjutan Shenzhen, Akademi Sains China dialu-alukan untuk memohon jawatan pasca doktoral/master/magang hantar resume anda ke min.yang @siat.ac.cn.
Atas ialah kandungan terperinci Senarai teratas antarabangsa yang berwibawa bagi penghuraian semantik perbualan SParC dan CoSQL, model pra-latihan pengetahuan meja dialog pelbagai pusingan baharu tafsiran STAR. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI