

 Peranti teknologiAIPerkongsian teknologi alat enjin gunung berapi: gunakan AI untuk melengkapkan perlombongan data dan melengkapkan penulisan SQL dengan ambang sifar
Peranti teknologiAIPerkongsian teknologi alat enjin gunung berapi: gunakan AI untuk melengkapkan perlombongan data dan melengkapkan penulisan SQL dengan ambang sifarPerkongsian teknologi alat enjin gunung berapi: gunakan AI untuk melengkapkan perlombongan data dan melengkapkan penulisan SQL dengan ambang sifar


Apabila menggunakan alat BI, soalan yang sering dihadapi ialah: "Bagaimana kita boleh menghasilkan dan memproses data jika kita tidak tahu SQL? Bolehkah kita melakukan analisis perlombongan jika kita tidak tahu algoritma ?"
Apabila pasukan algoritma profesional melakukan perlombongan data, analisis data dan visualisasi juga akan kelihatan agak berpecah-belah. Menyelesaikan kerja pemodelan algoritma dan analisis data dengan cara yang diperkemas juga merupakan cara yang baik untuk meningkatkan kecekapan.
Pada masa yang sama, untuk pasukan gudang data profesional, kandungan data dengan tema yang sama menghadapi masalah "pembinaan berulang, penggunaan dan pengurusan yang agak berselerak" - adakah terdapat cara untuk menghasilkannya pada masa yang sama dalam satu tugasan, dengan tema yang sama? Bolehkah set data yang dihasilkan digunakan sebagai input untuk mengambil bahagian semula dalam pembinaan data?
1. Keupayaan pemodelan visual DataWind ada di sini
DataWind, cerapan data pintar platform BI yang dilancarkan oleh Volcano Engine, telah melancarkan ciri lanjutan baharu - pemodelan visual.
Pengguna boleh memudahkan proses pemprosesan dan pemodelan data yang kompleks menjadi proses kanvas yang jelas dan mudah difahami melalui operasi menyeret, menarik dan menyambung secara visual Semua jenis pengguna boleh melengkapkan pengeluaran dan pemprosesan data mengikut idea tentang apa yang mereka fikir adalah apa yang mereka dapat dengan itu menurunkan ambang untuk pengeluaran dan pemerolehan data.
Kanvas menyokong membina beberapa set proses kanvas pada masa yang sama Satu gambar boleh merealisasikan pembinaan pelbagai tugas pemodelan data, meningkatkan kecekapan pembinaan data dan mengurangkan kos pengurusan tugasan, di samping itu, lebih daripada 40 jenis pembersihan data disepadukan dan dibungkus dalam kanvas , pengendali kejuruteraan ciri, meliputi keupayaan pengeluaran data peringkat tinggi, tanpa memerlukan pengekodan untuk melengkapkan keupayaan data yang kompleks.
2. Alat SQL ambang sifar
Penghasilan dan pemprosesan data ialah langkah pertama untuk mendapatkan dan menganalisis data.
Untuk pengguna bukan teknikal, terdapat ambang tertentu untuk menggunakan sintaks SQL Pada masa yang sama, fail tempatan tidak boleh dikemas kini dengan kerap, menyebabkan keperluan untuk membuat semula papan pemuka secara manual setiap kali. Tenaga kerja teknikal yang diperlukan untuk mendapatkan data selalunya perlu dijadualkan, dan ketepatan masa dan kepuasan pemerolehan data sangat dikurangkan Oleh itu, adalah penting untuk menggunakan alat pembinaan data kod sifar.
Dua senario biasa disenaraikan di bawah untuk menunjukkan cara pemprosesan data ambang sifar digunakan dalam kerja.
2.1 [Senario 1] Perkara yang anda fikir adalah apa yang anda perolehi dan proses pemprosesan data diselesaikan secara visual
Apabila lelaran operasi produk memerlukan maklum balas input tepat pada masanya bagi data yang berbeza, proses pemprosesan data boleh diabstrak dan dibina melalui visualisasi Operator seret modular membina proses pemprosesan data.
Untuk mendapatkan bilangan pesanan dan jumlah pesanan mengikut tarikh dan butiran bandar, dan untuk mendapatkan data bandar bagi 10 data jumlah penggunaan harian teratas, operasi adalah seperti berikut:
Aliran pemprosesan data am |
Proses pemodelan visual |
|
|

2.2 [Senario 2] Gabungkan berbilang jadual dengan pantas untuk menyelesaikan pengiraan perkaitan berbilang data dengan mudah
Semasa proses pemprosesan data, terdapat berbilang sumber data yang perlu digabungkan dan digunakan Secara konvensional, sukar dan memakan masa untuk menguasai Vlookup dan algoritma lain melalui Excel. Pada masa yang sama, apabila jumlah data adalah besar, prestasi komputer mungkin tidak dapat melengkapkan pengiraan gabungan data.
Jika terdapat dua data pesanan besar dan jadual maklumat atribut pelanggan, jumlah keuntungan perlu dikira berdasarkan jumlah bil dan jumlah kos, dan kemudian 100 maklumat pesanan pengguna teratas diambil mengikut keuntungan sumbangan
|
Proses pemprosesan data am
|
Proses pemodelan visual | tr> ||||
|
VloopUp terpakai mencari data pengguna dalam susunan dan data pengguna dalam pelanggan, dan kemudian menggabungkan kedua-dua data untuk menjana data baharu |
|

3 Perlombongan data AI tidak lagi di luar jangkauan
Apabila pembersihan data asas tidak lagi dapat memenuhi pembinaan data dan analisis data, sokongan algoritma AI diperlukan untuk perlombongan. Apabila data mempunyai lebih banyak nilai tersembunyi. Pelajar pasukan algoritma mungkin mengalami ketidakupayaan untuk bekerja dengan baik dengan carta visual, dan tidak dapat menghasilkan data yang baik yang boleh digunakan dengan cepat manakala pengguna biasa mungkin terus ditindas oleh ambang tinggi kod AI untuk menyekat pembangunan algoritma ini - meningkatkan permintaan; tetapi takut permintaan Ia terlalu cetek dan nilainya tidak dapat dinilai dengan baik Pada masa ini, perlombongan algoritma menjadi kemewahan.
Pemodelan visual DataWind merangkumi lebih daripada 30 keupayaan pengendali AI biasa. Pengguna hanya perlu memahami fungsi algoritma dan mengkonfigurasi input dan matlamat latihan operator algoritma melalui konfigurasi untuk melengkapkan latihan model dengan cepat keputusan berdasarkan kandungan data yang dikonfigurasikan lain.
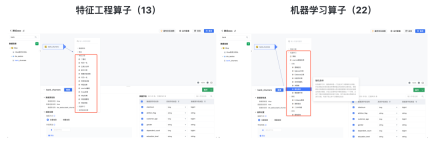


Dua senario biasa akan diambil sebagai contoh di bawah, Bagaimana untuk melengkapkan perlombongan data tanpa mengetahui cara menulis Python.
3.1 [Elementary] Anda boleh melakukan perlombongan data walaupun anda tidak tahu Python
Kerja harian pengguna pada asasnya tidak melibatkan penulisan Python, tetapi terdapat senario permintaan untuk perlombongan data. Dia perlu melakukan perlombongan niat pelanggan berdasarkan sampel pelanggan niat tinggi sedia ada. Pada ketika ini, proses perlombongan data boleh dibina melalui pemodelan visual:
- Seret masuk data sampel dan semua data sebagai input data.
- Seret ke dalam algoritma pengelasan, seperti algoritma XGB untuk latihan model.
- Seret operator ramalan dan bina perhubungan antara model dan semua data untuk ramalan.
- Data sebenar dan hasil ramalan digabungkan dengan set data output untuk menganalisis pengagihan niat semua data pengguna.

3.2 [Tahap lanjutan] Anda boleh membina model algoritma kompleks tanpa menulis Python
Pengguna perlu membina model berdasarkan sedia ada data Model belian semula pengguna. Semasa pembinaan model, adalah perlu untuk menggunakan pepohon penggalak kecerunan untuk membina model ramalan selepas pembersihan data dan penukaran format Pada masa ini, proses model belian semula boleh dibina berdasarkan pemodelan visual:
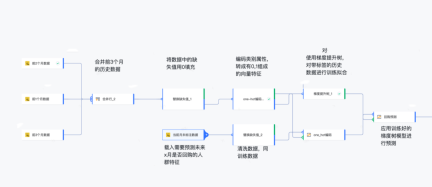 <.>
<.>
- Gabungkan baris: Gabungkan jadual data output bagi n operator (segi empat tepat dalam gambar) ke dalam satu jadual data keseluruhan berdasarkan pengepala yang konsisten Jika data jualan pengguna tidak menambah atau memadam atribut baharu, tiada perubahan diperlukan di sini.
- Penggantian nilai yang tiada: Apabila terdapat nilai nol (null) dalam lajur atribut, ia akan menjejaskan pengiraan model seterusnya Gunakan operator nilai yang hilang untuk menggantikan nilai nol dengan nilai lalai yang ditetapkan data jualan pengguna tidak menambah atau memadam atribut baharu Tiada perubahan diperlukan di sini.
- pengekodan satu panas: Atribut jenis teks tidak boleh digunakan secara langsung dalam latihan model dan perlu dikodkan ke dalam vektor berangka oleh one_hot. Contohnya:

- Pokok penggalak kecerunan: Bertanggungjawab untuk memasang data latihan dan mengeluarkan model yang boleh digunakan untuk ramalan (parameter yang tidak ditandakan dalam rajah tidak perlu diubah suai oleh penyelenggara):

- Aggregation_1: Alih keluar pendua dalam data ramalan dan ambil kebarangkalian maksimum.
- Medan ekstrak: Ekstrak label yang diperlukan dan keluaran nilai kebarangkalian.

4. Pembinaan pelbagai senario dan pelbagai tugas, pengurusan tidak lagi terpencar
Sebagai penganalisis data, anda juga mempunyai banyak kerja harian untuk membina set data dan membina papan pemuka data. Tetapi biasanya jadual bawah yang diperoleh daripada gudang data akan menjadi jadual yang luas Atas dasar ini, tugas set data yang berbeza dibina mengikut keperluan senario yang berbeza.
Dalam penggunaan seterusnya, kami sering menghadapi lebih banyak set data yang serupa, tetapi logik khusus tidak dapat dibandingkan dan disahkan dengan baik. Pada masa ini, adalah bagus jika semua logik set data dikonfigurasikan dan dijana dalam satu set data, dan setiap set data boleh dinilai dan ditakrifkan melalui proses tugasan.
Untuk senario ini, keupayaan pemodelan visual DataWind juga boleh diselesaikan dengan baik. Fungsi pemodelan visual menyokong set data tunggal untuk diproses oleh berbilang proses logik pada masa yang sama untuk menjana berbilang set data. Ambil pemprosesan data pesanan dan data pengguna sebagai contoh:
- Jika pengguna ingin melihat statistik pesanan, maka proses pemprosesan data set data statistik pesanan boleh dibina.
- Terdapat pengguna yang ingin melihat data terperinci, tetapi medan butiran perlu diproses dan dibersihkan Dalam kes ini, aliran pemprosesan Set Data Butiran Pesanan boleh dibina.
- Sesetengah pengguna ingin menggabungkan atribut pengguna untuk mengira pengedaran pesanan pengguna, kemudian membina korelasi berbilang jadual digabungkan dengan pengagregatan penunjuk untuk menjana set data statistik pesanan pengguna.
- Logik yang sama boleh menjana set data butiran pesanan pengguna di bawah perkaitan berbilang jadual.
Oleh itu, penjanaan 4 set data diselesaikan melalui satu tugasan dan dua input data 4 set data boleh membina kawasan subjek data, dan data berkaitan seterusnya boleh digunakan daripada ini titik pada. Output set data mengikut tugasan digunakan.

5 Tentang kami
Volcano Engine Intelligent Data Insight DataWind ialah platform yang dipertingkatkan yang menyokong analisis layan diri secara terperinci. tahap platform ABI data besar. Daripada akses data, penyepaduan data, kepada pertanyaan dan analisis, ia akhirnya dipersembahkan kepada pengguna perniagaan dalam bentuk portal data visual, skrin besar digital, dan kokpit pengurusan, yang membolehkan data menggunakan nilai.
Atas ialah kandungan terperinci Perkongsian teknologi alat enjin gunung berapi: gunakan AI untuk melengkapkan perlombongan data dan melengkapkan penulisan SQL dengan ambang sifar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimana Amazon Alexa berfungsi menggunakan NLPApr 14, 2025 am 10:06 AM
Bagaimana Amazon Alexa berfungsi menggunakan NLPApr 14, 2025 am 10:06 AMPengenalan Duduk di hadapan desktop, jauh dari anda, adalah pembantu peribadi anda sendiri, dia tahu nada suara anda, jawapan kepada soalan anda dan bahkan satu langkah di hadapan anda. Ini adalah keindahan Amazon Alexa, SM
 10 sumber percuma untuk belajar LLMApr 14, 2025 am 10:04 AM
10 sumber percuma untuk belajar LLMApr 14, 2025 am 10:04 AMBuka kunci kekuatan model bahasa besar (LLMS): 10 sumber percuma Memulakan perjalanan ke dunia model bahasa besar (LLMS), daya penggerak di belakang chatbots pintar dan analisis data canggih. Panduan komprehensif ini memperkenalkan sepuluh fr
 Adakah anda membuat kesilapan ini dalam pemodelan klasifikasi?Apr 14, 2025 am 10:02 AM
Adakah anda membuat kesilapan ini dalam pemodelan klasifikasi?Apr 14, 2025 am 10:02 AMPengenalan Menilai model pembelajaran mesin bukan sekadar langkah terakhir -ia adalah kunci kejayaan. Bayangkan membina model canggih yang mempesonakan dengan ketepatan yang tinggi, hanya untuk mendapati ia runtuh di bawah sebenar
 Trocr dan Zhen lateks OcrApr 14, 2025 am 09:59 AM
Trocr dan Zhen lateks OcrApr 14, 2025 am 09:59 AMMeneroka Kekuatan Model-ke-Teks Model: Trocr dan Zhen Latex Ocr Dunia AI bersemangat dengan model bahasa dan aplikasi mereka dalam bantuan maya dan penciptaan kandungan. Walau bagaimanapun, bidang penukaran imej-ke-teks, dikuasakan oleh optik
 Bagaimana untuk memadam baris pendua dalam SQL?Apr 14, 2025 am 09:55 AM
Bagaimana untuk memadam baris pendua dalam SQL?Apr 14, 2025 am 09:55 AMPengenalan Pangkalan data SQL sering mengalami rekod pendua, menghalang analisis data dan kecekapan operasi. Panduan ini menyediakan teknik praktikal untuk membuang penyertaan yang berlebihan ini, sama ada anda bekerja dengan data pelanggan, transaksi
 Master SegormerApr 14, 2025 am 09:46 AM
Master SegormerApr 14, 2025 am 09:46 AMSegormer: menyelam mendalam ke segmentasi imej yang cekap Aplikasi moden menuntut keupayaan pemprosesan imej lanjutan, dan segmentasi imej memainkan peranan penting. Artikel ini meneroka Segormer, model yang kuat yang cemerlang dalam segmen imej
 Apakah rangka kerja di Python?Apr 14, 2025 am 09:41 AM
Apakah rangka kerja di Python?Apr 14, 2025 am 09:41 AMPengenalan Bayangkan anda sedang membina pencakar langit baru. Anda tidak akan bermula tanpa pelan tindakan, bukan? Begitu juga, apabila membangunkan perisian, mempunyai rangka kerja yang betul adalah penting. Di dunia yang luas Python, kerangka AC
 Kursus Kejuruteraan Antropik ' s ini pada tahun 2025Apr 14, 2025 am 09:38 AM
Kursus Kejuruteraan Antropik ' s ini pada tahun 2025Apr 14, 2025 am 09:38 AMPengenalan Kejuruteraan Prompt telah menjadi topik hangat pada tahun 2024, dengan kemajuan pesat generatif AI memandu pelajar untuk kemahiran dalam bidang yang kompetitif ini. Menguasai Kejuruteraan Prompt adalah seperti mempunyai kunci ke Powerf


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver Mac版
Alat pembangunan web visual

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

Dreamweaver CS6
Alat pembangunan web visual

