
Rumah >Peranti teknologi >AI >Apakah kaedah yang berkesan dan kaedah Pangkalan biasa untuk ramalan trajektori pejalan kaki? Perkongsian kertas persidangan teratas!
Apakah kaedah yang berkesan dan kaedah Pangkalan biasa untuk ramalan trajektori pejalan kaki? Perkongsian kertas persidangan teratas!

- 王林ke hadapan
- 2023-10-17 11:13:012064semak imbas
Ramalan trajektori telah menjadi tumpuan sejak dua tahun lalu, tetapi kebanyakannya memfokuskan pada arah ramalan trajektori kenderaan Hari ini, Jantung Pemanduan Autonomi akan berkongsi dengan anda algoritma untuk ramalan trajektori pejalan kaki pada NeurIPS - SHENet, pergerakan manusia. corak dalam adegan terhad Biasanya mematuhi undang-undang terhad pada tahap tertentu. Berdasarkan andaian ini, SHENet meramalkan trajektori masa depan seseorang dengan mempelajari peraturan adegan tersirat. Artikel itu telah dibenarkan untuk menjadi asli oleh Autonomous Driving Heart!
Pemahaman peribadi pengarang
Disebabkan oleh rawak dan subjektiviti pergerakan manusia, meramalkan trajektori masa depan seseorang pada masa ini masih menjadi masalah yang mencabar. Walau bagaimanapun, disebabkan oleh kekangan pemandangan (seperti pelan lantai, jalan raya dan halangan) dan interaktiviti manusia-ke-manusia atau manusia-ke-objek, corak pergerakan manusia dalam adegan terhalang biasanya mematuhi undang-undang terhad pada tahap tertentu. Oleh itu, dalam kes ini, trajektori individu juga harus mengikut salah satu undang-undang ini. Dalam erti kata lain, trajektori seterusnya seseorang mungkin telah dilalui oleh orang lain. Berdasarkan andaian ini, algoritma artikel ini (SHENet) meramalkan trajektori masa depan seseorang dengan mempelajari peraturan adegan tersirat. Secara khusus, kami merujuk kepada ketetapan yang wujud dalam dinamik masa lalu orang dan persekitaran dalam adegan sebagai sejarah adegan. Maklumat sejarah tempat kejadian kemudiannya dibahagikan kepada dua kategori: trajektori kumpulan sejarah dan interaksi antara individu dan persekitaran. Untuk mengeksploitasi kedua-dua jenis maklumat ini untuk ramalan trajektori, kertas kerja ini mencadangkan rangka kerja novel Rangkaian Perlombongan Sejarah Scene (SHENet), di mana sejarah adegan dieksploitasi dengan cara yang mudah dan berkesan. Khususnya, dua komponen reka bentuk ialah: modul perpustakaan trajektori kumpulan, yang digunakan untuk mengekstrak trajektori kumpulan wakil sebagai calon untuk laluan masa hadapan dan modul interaksi rentas modal, yang digunakan untuk memodelkan interaksi antara trajektori masa lalu individu dan persekitaran sekelilingnya, untuk penghalusan trajektori. Di samping itu, untuk mengurangkan ketidakpastian trajektori sebenar yang disebabkan oleh rawak dan subjektiviti pergerakan manusia yang dinyatakan di atas, SHENet menggabungkan kelancaran ke dalam proses latihan dan penunjuk penilaian. Akhir sekali, kami mengesahkannya pada set data eksperimen yang berbeza dan menunjukkan prestasi cemerlang berbanding dengan kaedah SOTA.
Pengenalan
Human Trajectory Prediction (HTP) bertujuan untuk meramalkan laluan masa depan seseorang sasaran daripada klip video. Ini penting untuk pengangkutan pintar kerana ia membolehkan kenderaan mengesan status pejalan kaki lebih awal, dengan itu mengelakkan kemungkinan perlanggaran. Sistem pemantauan dengan fungsi HTP boleh membantu kakitangan keselamatan dalam meramalkan kemungkinan laluan melarikan diri suspek. Walaupun banyak kerja telah dilakukan dalam beberapa tahun kebelakangan ini, hanya sedikit yang cukup dipercayai dan boleh digeneralisasikan untuk aplikasi dalam senario dunia sebenar, terutamanya disebabkan oleh dua cabaran tugas: rawak dan subjektiviti pergerakan manusia. Walau bagaimanapun, dalam senario dunia nyata yang terhad, cabarannya tidak dapat diatasi sepenuhnya. Seperti yang ditunjukkan dalam Rajah 1, memandangkan video yang telah ditangkap sebelum ini dalam adegan ini, trajektori masa depan orang sasaran (kotak merah) menjadi lebih boleh diramal kerana corak pergerakan manusia biasanya mematuhi beberapa undang-undang asas yang akan diikuti oleh orang sasaran dalam adegan ini. Oleh itu, untuk meramalkan trajektori, kita perlu memahami corak ini terlebih dahulu. Kami berpendapat bahawa keteraturan ini secara tersirat dikodkan dalam trajektori sejarah manusia (Rajah 1 kiri), trajektori masa lalu individu, persekitaran sekeliling dan interaksi antara mereka (Rajah 1 kanan), yang kami rujuk sebagai sejarah adegan.

Rajah 1: Gambar rajah skema menggunakan sejarah adegan: trajektori kumpulan sejarah dan interaksi persekitaran individu untuk ramalan trajektori manusia.
Kami membahagikan maklumat sejarah kepada dua kategori: trajektori kumpulan sejarah (HGT) dan interaksi individu-persekitaran (ISI). HGT merujuk kepada perwakilan kumpulan semua trajektori sejarah dalam adegan. Sebab untuk menggunakan HGT ialah, memandangkan orang sasaran baharu dalam tempat kejadian, laluannya lebih berkemungkinan mempunyai lebih banyak persamaan, subjektiviti dan keteraturan kepada salah satu trajektori kumpulan berbanding mana-mana satu trajektori sejarah disebabkan oleh rawak yang disebutkan di atas. Walau bagaimanapun, trajektori kumpulan kurang relevan dengan keadaan lalu individu dan persekitaran yang sepadan, dan juga boleh menjejaskan trajektori masa depan individu. ISI perlu menggunakan maklumat sejarah dengan lebih sepenuhnya dengan mengekstrak maklumat kontekstual. Kaedah sedia ada jarang mempertimbangkan persamaan antara trajektori lampau individu dan trajektori sejarah. Kebanyakan percubaan hanya meneroka interaksi antara individu dan persekitaran, di mana banyak usaha dibelanjakan untuk memodelkan trajektori individu, maklumat semantik persekitaran, dan hubungan antara mereka. Walaupun MANTRA menggunakan pengekod yang dilatih dalam cara pembinaan semula untuk memodelkan persamaan, dan MemoNet memudahkan persamaan dengan menyimpan niat trajektori sejarah, kedua-duanya melakukan pengiraan persamaan pada peringkat contoh dan bukannya peringkat kumpulan, menjadikan Ia sensitif terhadap keupayaan pengekod terlatih. Berdasarkan analisis di atas, kami mencadangkan rangka kerja yang mudah tetapi berkesan, Scene History Mining Network (SHENet), untuk menggunakan HGT dan ISI secara bersama untuk HTP. Khususnya, rangka kerja ini terdiri daripada dua komponen utama: (i) modul Pangkalan Trajektori Kumpulan (GTB) dan (ii) modul Interaksi Silang Modal (CMI). GTB membina trajektori kumpulan perwakilan daripada semua trajektori individu sejarah dan menyediakan laluan calon untuk ramalan trajektori masa hadapan. CMI mengekod trajektori individu yang diperhatikan dan persekitaran sekeliling secara berasingan dan memodelkan interaksi mereka menggunakan pengubah rentas modal untuk memperhalusi trajektori calon yang dicari.
Selain itu, untuk mengurangkan ketidakpastian dua ciri di atas (iaitu, rawak dan subjektiviti), kami memperkenalkan Curve Smoothing (CS) dalam proses latihan dan metrik penilaian semasa, ralat anjakan purata dan akhir (iaitu, ADE dan FDE), dengan itu memperoleh dua penunjuk baharu CS-ADE dan CS-FDE. Tambahan pula, untuk memudahkan pembangunan penyelidikan HTP, kami mengumpul set data mencabar baharu dengan corak pergerakan berbeza yang dinamakan PAV. Set data ini diperoleh dengan memilih video dengan paparan kamera tetap dan gerakan manusia yang kompleks daripada set data MOT15.
Sumbangan kerja ini boleh diringkaskan seperti berikut: 1) Kami memperkenalkan sejarah kumpulan untuk mencari trajektori individu HTP. 2) Kami mencadangkan rangka kerja yang mudah tetapi berkesan, SHENet, yang secara bersama-sama menggunakan dua jenis sejarah adegan (iaitu, trajektori kumpulan sejarah dan interaksi individu-persekitaran) untuk HTP. 3) Kami membina PAV set data baharu yang mencabar. Selain itu, mempertimbangkan kerawak dan subjektiviti corak pergerakan manusia, fungsi kehilangan baru dan dua penunjuk baharu telah dicadangkan untuk mencapai prestasi HTTP Baseline yang lebih baik. 4) Kami menjalankan eksperimen komprehensif pada ETH, UCY dan PAV untuk menunjukkan prestasi unggul SHENet dan keberkesanan setiap komponen.
Kerja berkaitan
Kaedah unimodalKaedah unimodal bergantung pada pembelajaran keteraturan pergerakan individu dari trajektori masa lalu untuk meramal trajektori masa depan. Sebagai contoh, LSTM Sosial memodelkan interaksi antara trajektori individu melalui modul pengumpulan sosial. STGAT menggunakan modul perhatian untuk mempelajari interaksi spatial dan memberikan kepentingan yang munasabah kepada jiran. PIE menggunakan modul perhatian temporal untuk mengira kepentingan trajektori yang diperhatikan pada setiap langkah masa.
Kaedah multimodalSelain itu, kaedah multimodal juga mengkaji kesan maklumat alam sekitar terhadap HTP. SS-LSTM mencadangkan modul interaksi adegan untuk menangkap maklumat global tempat kejadian. Trajectron++ menggunakan struktur graf untuk memodelkan trajektori dan berinteraksi dengan maklumat alam sekitar dan individu lain. MANTRA memanfaatkan memori luaran untuk memodelkan kebergantungan jangka panjang. Ia menyimpan trajektori ejen tunggal sejarah dalam ingatan dan mengekod maklumat alam sekitar untuk memperhalusi trajektori yang dicari daripada ingatan ini.
Perbezaan daripada kerja sebelumnya Kedua-dua pendekatan modal tunggal dan pelbagai modal menggunakan aspek tunggal atau separa sejarah adegan, mengabaikan trajektori kumpulan sejarah. Dalam kerja kami, kami menyepadukan maklumat sejarah adegan dengan cara yang lebih komprehensif dan mencadangkan modul khusus untuk mengendalikan jenis maklumat yang berbeza masing-masing. Perbezaan utama antara kaedah kami dan kerja terdahulu, terutamanya kaedah berasaskan ingatan dan kaedah berasaskan kluster adalah seperti berikut: i) MANTRA dan MemoNet mempertimbangkan trajektori individu sejarah, manakala SHENet yang dicadangkan kami memfokuskan pada trajektori kumpulan sejarah, yang dalam berbeza Lebih universal dalam senario. ii) Terdapat juga beberapa karya yang mengelompokkan orang-jiran untuk ramalan trajektori ke dalam bilangan kategori tetap untuk pengelasan trajektori SHENet kami menjana trajektori perwakilan sebagai rujukan untuk ramalan trajektori individu.
Kaedah
Pengenalan keseluruhan
Seni bina rangkaian perlombongan sejarah adegan yang dicadangkan (SHENet) ditunjukkan dalam Rajah 2. Ia terdiri daripada dua komponen utama: modul perpustakaan trajektori kumpulan (GTB) dan modul interaksi silang mod (CMI). Secara rasmi, memandangkan semua trajektori , imej adegan dalam video yang diperhatikan tempat kejadian dan trajektori masa lalu orang sasaran dalam langkah masa terakhir, di mana mewakili kedudukan orang ke-p pada langkah masa t , SHENet diperlukan untuk meramalkan Kedudukan masa depan pejalan kaki dalam bingkai seterusnya adalah sedekat mungkin dengan trajektori kebenaran tanah. GTB yang dicadangkan terlebih dahulu memampatkan ke dalam trajektori kumpulan yang mewakili. Kemudian, gunakan trajektori yang diperhatikan sebagai kunci untuk mencari trajektori kumpulan wakil terdekat sebagai trajektori masa depan calon . Pada masa yang sama, imej trajektori dan pemandangan lalu dihantar ke pengekod trajektori dan pengekod adegan masing-masing untuk menjana ciri trajektori dan ciri pemandangan. Ciri yang dikodkan dimasukkan ke dalam pengubah mod silang untuk mempelajari offset dari trajektori kebenaran tanah. Dengan menambahkan kepada , kita mendapat ramalan akhir . Semasa fasa latihan, jika jarak ke lebih tinggi daripada ambang, trajektori orang itu (iaitu, dan ) akan ditambahkan pada pustaka trajektori. Selepas latihan selesai, bank ditetapkan untuk inferens.
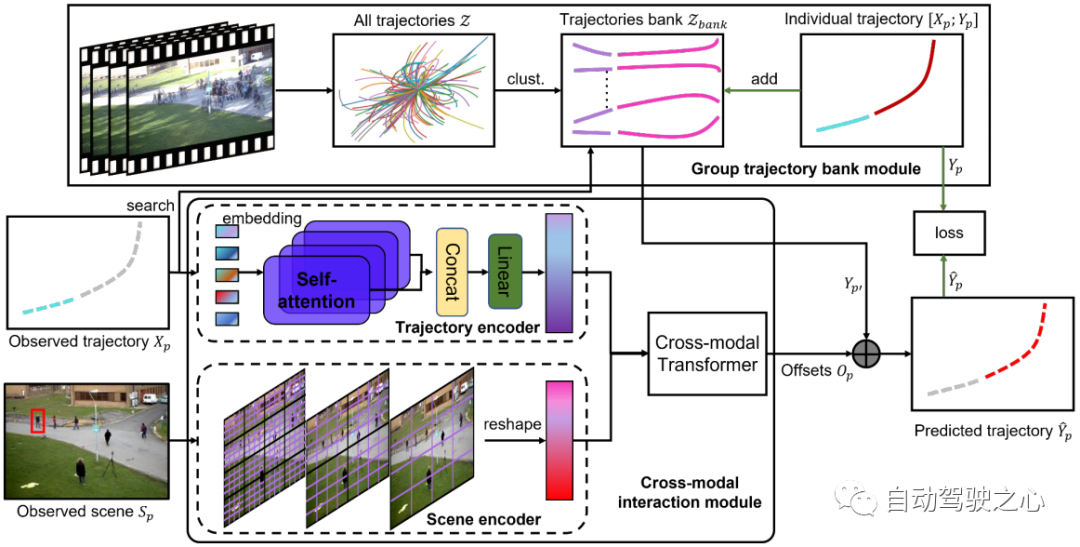
Rajah 2: Seni bina SHENet terdiri daripada dua komponen: modul Pustaka Trajektori Kumpulan (GTB) dan Modul Interaksi Cross-Modal (CMI). GTB mengelompokkan semua trajektori sejarah ke dalam set trajektori kumpulan perwakilan dan menyediakan calon untuk ramalan trajektori akhir. Semasa fasa latihan, GTB boleh menggabungkan trajektori orang sasaran ke dalam pustaka trajektori kumpulan berdasarkan ralat trajektori yang diramalkan untuk mengembangkan keupayaan ekspresi. CMI mengambil trajektori masa lalu orang sasaran dan pemandangan yang diperhatikan sebagai input pengekod trajektori dan pengekod pemandangan masing-masing untuk pengekstrakan ciri, dan kemudian secara berkesan memodelkan interaksi antara trajektori lalu dan persekitaran sekelilingnya melalui penukar mod silang dan Penapisan dilakukan untuk menyediakan trajektori calon.
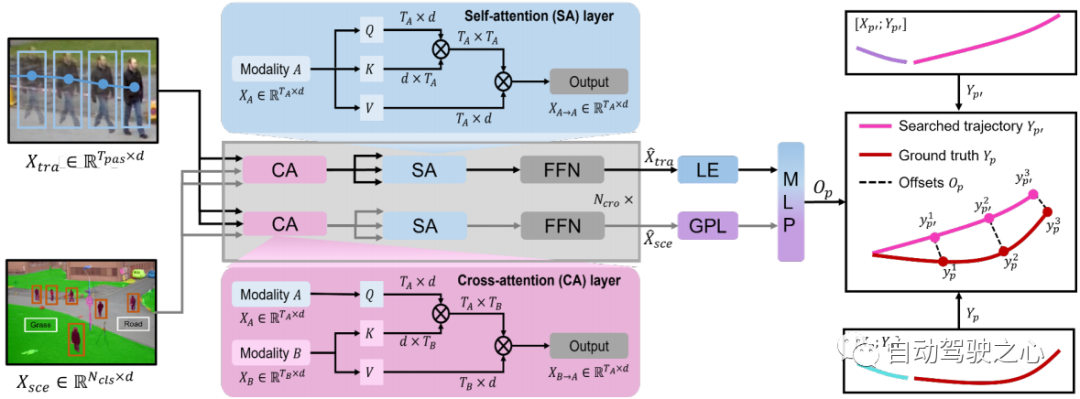
Rajah 3: Ilustrasi pengubah mod silang. Ciri trajektori dan ciri pemandangan dimasukkan ke dalam pengubah mod silang untuk mempelajari pengimbangan antara trajektori carian dan trajektori kebenaran tanah.
Modul perpustakaan trajektori kumpulan
Modul perpustakaan trajektori kumpulan (GTB) digunakan untuk membina trajektori kumpulan perwakilan di tempat kejadian. Fungsi teras GTB ialah pemulaan bank, carian trajektori dan kemas kini trajektori.
Pengamatan pustaka trajektoriDisebabkan lebihan sejumlah besar trajektori yang direkodkan, kami tidak hanya menggunakannya, tetapi menjana satu set trajektori yang jarang dan mewakili sebagai nilai awal pustaka trajektori. Secara khusus, kami mewakili trajektori dalam data latihan sebagai dan membahagikan setiap kepada sepasang trajektori pemerhatian dan trajektori masa depan , dengan itu membahagikan kepada set ke dalam set pemerhatian 🜎 dan . Kemudian, kami mengira jarak Euclidean antara setiap pasangan trajektori dalam , dan mendapatkan kelompok trajektori melalui algoritma pengelompokan K-medoids. Ahli awal ialah purata trajektori yang tergolong dalam kelompok yang sama (lihat Algoritma 1, langkah 1). Setiap trajektori dalam mewakili corak pergerakan sekumpulan manusia.
Pencarian dan Kemas Kini TrajektoriDalam pustaka trajektori kumpulan, setiap trajektori boleh dilihat sebagai pasangan masa depan masa lalu. Secara berangka, , di mana mewakili gabungan trajektori lalu dan trajektori masa depan, dan ialah bilangan pasangan masa depan masa lalu dalam . Memandangkan trajektori , kami menggunakan yang diperhatikan sebagai kunci untuk mengira skor persamaannya dengan trajektori yang lalu dalam dan cari trajektori perwakilan mengikut skor kesamaan maksimum 1, step2hms score). Fungsi persamaan boleh dinyatakan sebagai:
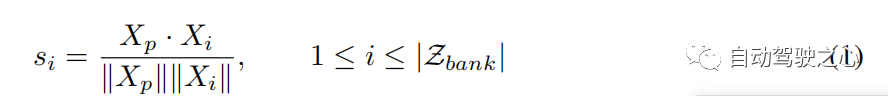
(lihat Persamaan 2) ke trajektori perwakilan , kita memperoleh trajektori yang diramalkan pemerhati 2 (lihat Rajah 2). Walaupun pustaka trajektori awal berfungsi dengan baik dalam kebanyakan kes, untuk meningkatkan generalisasi perpustakaan (lihat Algoritma 1, langkah 3), kami memutuskan sama ada untuk mengemas kini berdasarkan ambang jarak θ.
Modul interaksi silang mod
Modul ini memfokuskan pada interaksi antara trajektori lalu individu dan maklumat alam sekitar. Ia terdiri daripada dua pengekod mod tunggal untuk mempelajari gerakan manusia dan maklumat adegan masing-masing, dan pengubah rentas mod untuk memodelkan interaksi mereka.
Pengekod Trajektori Pengekod trajektori menggunakan struktur perhatian berbilang kepala daripada rangkaian Transformer, yang mempunyai #🎜🎜🎜🎜🎜🎜 # Lapisan perhatian diri (SA). Lapisan SA menangkap gerakan manusia pada langkah masa yang berbeza dengan saiz , dan menayangkan ciri gerakan daripada dimensi hingga , di mana #🎜 🎜# ialah dimensi benam pengekod trajektori. Oleh itu, kami menggunakan pengekod trajektori untuk mendapatkan perwakilan gerakan manusia: . Pengekod Adegan
Memandangkan Swin Transformer yang telah terlatih mempunyai prestasi yang menarik dalam perwakilan ciri, kami mengguna pakainya sebagai peranti pengekod adegan. Ia mengekstrak ciri semantik adegan bersaiz , dengan ( dalam pengekod adegan pra-latihan) ialah bilangan kelas semantik, e.g. Orang ramai dan jalan raya, dan ialah resolusi spatial. Untuk membolehkan modul seterusnya menggabungkan maklumat perwakilan gerakan dan persekitaran dengan mudah, kami menukar semula ciri semantik daripada saiz () kepada () dan menayangkannya daripada dimensi () kepada () melalui lapisan persepsi berbilang lapisan. Hasilnya, kami menggunakan pengekod pemandangan untuk mendapatkan perwakilan pemandangan . Cross-modal Transformer
Pengekod mod tunggal mengekstrak ciri daripada modalitinya sendiri, mengabaikan hubungan antara pergerakan manusia dan interaksi persekitaran . Transformer rentas mod dengan lapisan bertujuan untuk memperhalusi trajektori calon dengan mempelajari interaksi ini (lihat Bahagian 3.2). Kami menggunakan struktur dua aliran: satu digunakan untuk menangkap gerakan manusia yang penting yang dikekang oleh maklumat alam sekitar, dan satu lagi digunakan untuk memilih maklumat alam sekitar yang berkaitan dengan gerakan manusia. Lapisan perhatian silang (CA) dan lapisan perhatian diri (SA) adalah komponen utama penukar mod silang (lihat Rajah 3). Untuk menangkap pergerakan penting manusia yang terjejas oleh persekitaran dan mendapatkan maklumat persekitaran berkaitan pergerakan, lapisan CA menganggap satu modaliti sebagai pertanyaan dan modaliti lain sebagai kunci dan nilai yang berinteraksi dengan dua modaliti. Lapisan SA digunakan untuk menggalakkan sambungan dalaman yang lebih baik dan mengira persamaan antara elemen (pertanyaan) dan elemen lain (kunci) dalam gerakan kekangan pemandangan atau maklumat persekitaran berkaitan gerakan. Oleh itu, kami memperoleh perwakilan multimodal () melalui pengubah mod silang . Untuk meramalkan offset antara trajektori carian dan trajektori sebenar , kami menggunakan yang terakhir daripada # 🎜🎜# Elemen (LE) dan output daripada selepas lapisan pengumpulan global (GPL). Offset boleh dinyatakan seperti berikut:
di mana [ ] mewakili gabungan vektor, dan MLP ialah gabungan berbilang lapisan lapisan persepsi.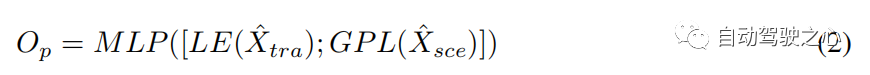 Kami melatih keseluruhan rangka kerja SHENet hujung ke hujung untuk meminimumkan fungsi objektif. Semasa latihan, memandangkan pengekod pemandangan telah dilatih terlebih dahulu pada ADE20K, kami membekukan bahagian pembahagiannya dan mengemas kini parameter kepala MLP (lihat Bahagian 3.3). Berikutan kerja sedia ada, kami mengira ralat min kuasa dua (MSE) antara trajektori yang diramalkan dan trajektori kebenaran tanah pada set data ETH/UCY:
Kami melatih keseluruhan rangka kerja SHENet hujung ke hujung untuk meminimumkan fungsi objektif. Semasa latihan, memandangkan pengekod pemandangan telah dilatih terlebih dahulu pada ADE20K, kami membekukan bahagian pembahagiannya dan mengemas kini parameter kepala MLP (lihat Bahagian 3.3). Berikutan kerja sedia ada, kami mengira ralat min kuasa dua (MSE) antara trajektori yang diramalkan dan trajektori kebenaran tanah pada set data ETH/UCY:
.
Dalam set data PAV yang lebih mencabar, kami menggunakan kehilangan regresi pelicinan lengkung (CS), yang membantu mengurangkan kesan berat sebelah individu. Ia mengira MSE selepas melicinkan trajektori. Kehilangan CS boleh dinyatakan seperti berikut: di mana CS mewakili fungsi melicinkan lengkung [2].
Eksperimen
Persediaan Eksperimen#🎜🎜🎜🎜🎜🎜 #Dataset
Kami menilai kaedah kami pada set data ETH, UCY, PAV dan Stanford Drone Dataset (SDD). Kaedah modal tunggal hanya menumpukan pada data trajektori, namun, kaedah berbilang modal perlu mempertimbangkan maklumat adegan. Berbanding dengan set data ETH/UCY, PAV lebih mencabar dengan berbilang mod gerakan, termasuk PETS09-S2L1 (PETS), ADL-Rundle-6 (ADL) dan Venice-2 ( VENICE), ini data ditangkap daripada kamera statik dan menyediakan trajektori yang mencukupi untuk tugasan HTP. Kami membahagikan video kepada set latihan (80%) dan set ujian (20%), dan PETS/ADL/VENICE masing-masing mengandungi 2,370/2,935/4,200 urutan latihan dan 664/306/650. Kami menggunakanbingkai pemerhatian untuk meramal masa depan bingkai supaya kami boleh membandingkan hasil ramalan jangka panjang kaedah yang berbeza.
Tidak seperti set data ETH/UCY dan PAV, SDD ialah set data berskala besar yang ditangkap dari pandangan mata kampus universiti. Ia terdiri daripada berbilang ejen berinteraksi (cth. pejalan kaki, penunggang basikal dan kereta) dan senario yang berbeza (cth. kaki lima dan persimpangan). Berikutan kerja sebelumnya, kami menggunakan 8 bingkai yang lalu untuk meramalkan 12 bingkai yang akan datang.
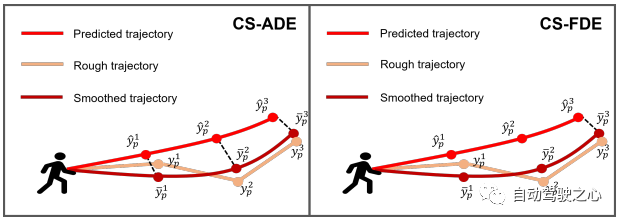
Rajah 4: Ilustrasi metrik cadangan kami CS-ADE dan CS-FDE.

Rajah 5: Visualisasi beberapa sampel selepas licin lengkung.
Metrik Penilaian Untuk set data ETH dan UCY, kami menggunakan metrik standard HTP: ralat anjakan purata (ADE) dan ralat anjakan akhir (FDE). ADE ialah ralat purata antara trajektori yang diramalkan dan trajektori sebenar pada setiap langkah masa, dan FDE ialah ralat antara trajektori yang diramalkan dan trajektori sebenar pada langkah masa akhir. Trajektori dalam PAV mempunyai sedikit kegelisahan (cth. selekoh tajam). Oleh itu, ramalan yang munasabah mungkin menghasilkan lebih kurang ralat yang sama seperti ramalan tidak realistik menggunakan metrik tradisional ADE dan FDE (lihat Rajah 7(a)). Untuk memberi tumpuan kepada corak dan bentuk trajektori itu sendiri dan mengurangkan kesan rawak dan subjektiviti, kami mencadangkan CS-Metric: CS-ADE dan CS-FDE (ditunjukkan dalam Rajah 4). CS-ADE dikira seperti berikut:
di mana CS ialah fungsi pelicinan lengkung, ditakrifkan sama seperti Lcs dalam Bahagian 3.4. Sama seperti CS-ADE, CS-FDE mengira ralat anjakan terakhir selepas pelicinan trajektori: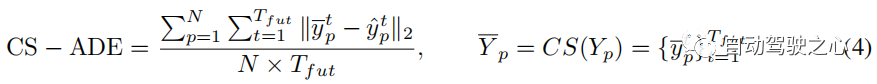
Dalam SHENet, saiz awal pustaka trajektori kumpulan ditetapkan kepada. Kedua-dua pengekod trajektori dan pengekod pemandangan mempunyai 4 lapisan perhatian kendiri (SA). Transformer rentas modal mempunyai 6 lapisan SA dan lapisan Perhatian Silang (CA). Kami menetapkan semua dimensi benam kepada 512. Untuk pengekod trajektori, ia mempelajari maklumat pergerakan manusia bersaiz ( dalam ETH/UCY, dalam PAV). Untuk pengekod pemandangan, ia mengeluarkan ciri semantik bersaiz 150 × 56 × 56. Kami menukar saiz daripada 150 × 56 × 56 kepada 150 × 3136 dan menayangkannya daripada dimensi 150 × 3136 kepada 150 × 512. Kami melatih model untuk 100 zaman pada 4 NVIDIA Quadro RTX 6000 GPU dan menggunakan pengoptimum Adam dengan kadar pembelajaran tetap 1e − 5. Eksperimen AblasiDalam Jadual 1, kami menilai setiap komponen SHENet, termasuk modul Group Trajectory Library (GTB) dan modul Cross-Modal Interaction (CMI), yang mengandungi pengekod trajektori (TE), pengekodan pemandangan Pelayan ( SE) dan modul interaksi silang modal (CMI).
Impak GTB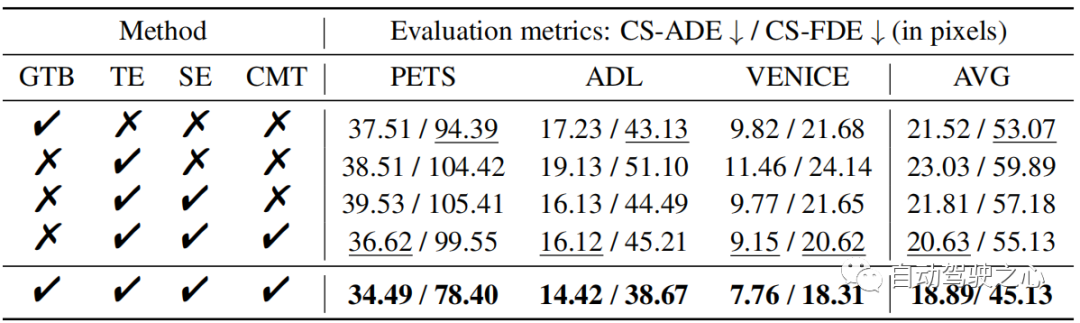
Kita kaji dulu prestasi GTB. Berbanding dengan CMI (iaitu, TE, SE dan CMT), GTB meningkatkan FDE pada PETS sebanyak 21.2%, yang merupakan peningkatan yang ketara dan menggambarkan kepentingan GTB. Walau bagaimanapun, GTB sahaja (Jadual 1 baris 1) tidak mencukupi malah prestasinya lebih teruk sedikit daripada CMI. Oleh itu, kami meneroka peranan pelbagai bahagian dalam modul CMI. Pengaruh TE dan SE Untuk menilai prestasi TE dan SE, kami menggabungkan ciri trajektori yang diekstrak daripada TE dan ciri pemandangan yang diekstrak daripada SE (baris 3 dalam Jadual 1), dan membandingkan Gerakan kecil meningkatkan prestasi ADL dan VENICE (berbanding dengan menggunakan TE sahaja. Ini menunjukkan bahawa memasukkan maklumat persekitaran ke dalam ramalan trajektori boleh meningkatkan ketepatan keputusan. Kesan CMT Berbanding dengan baris ketiga Jadual 1, CMT (Jadual 1) boleh meningkatkan dengan ketara Prestasi model yang ketara, ia mengatasi prestasi TE dan SE dalam siri pada PETS, dengan ADE meningkat secara purata sebanyak 7.4% berbanding dengan GTB sahaja.
Perbandingan dengan SOTA
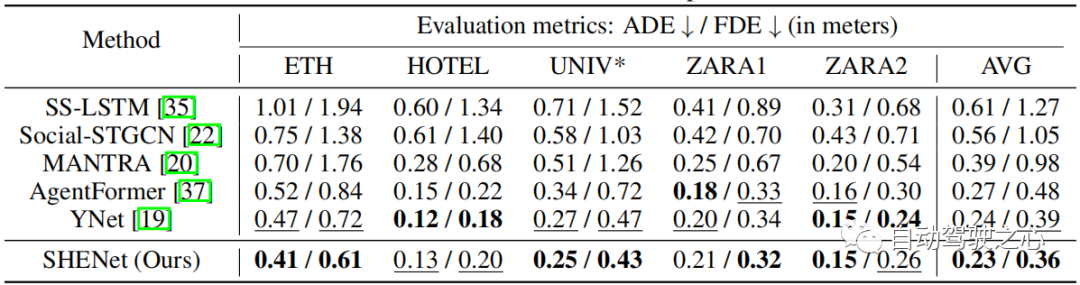
Pada set data ETH/UCY, model kami dibandingkan dengan kaedah terkini: SS-LSTM, Social-STGCN, MANTRA, AgentFormer, YNet. Keputusan diringkaskan dalam Jadual 2. Model kami mengurangkan purata FDE daripada 0.39 kepada 0.36, peningkatan sebanyak 7.7% berbanding kaedah terkini YNet. Khususnya, apabila trajektori mengalami pergerakan yang besar, model kami dengan ketara mengatasi kaedah sebelumnya pada ETH, meningkatkan ADE dan FDE masing-masing sebanyak 12.8% dan 15.3%.
Jadual 2: Perbandingan kaedah terkini (SOTA) pada set data ETH/UCY. * menunjukkan bahawa kita menggunakan set yang lebih kecil daripada pendekatan unimodal. Nilaikan menggunakan yang terbaik daripada 20 teratas.
Jadual 3: Perbandingan dengan kaedah SOTA pada set data PAV.
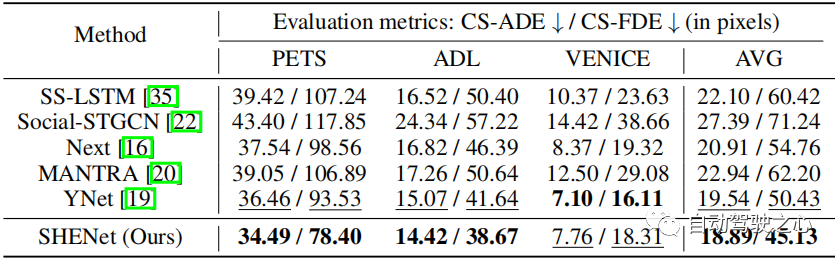
Untuk menilai prestasi model kami dalam ramalan jangka panjang, kami menjalankan eksperimen pada PAV, di mana setiap trajektori #🎜 🎜# bingkai pemerhatian, bingkai masa hadapan. Jadual 3 menunjukkan perbandingan prestasi dengan kaedah HTP sebelumnya: SS-LSTM, Social-STGCN, Next, MANTRA, YNet. Berbanding dengan keputusan terkini YNet, SHENet CS-ADE dan CS-FDE yang dicadangkan masing-masing mencapai peningkatan purata 3.3% dan 10.5%. Memandangkan YNet meramalkan peta haba bagi trajektori, ia berprestasi lebih baik apabila trajektori mempunyai pergerakan kecil (seperti VENICE). Walau bagaimanapun, kaedah kami masih kompetitif di VENICE dan jauh lebih baik daripada kaedah lain pada PETS dengan gerakan dan persimpangan yang lebih besar. Khususnya, kaedah kami meningkatkan CS-FDE sebanyak 16.2% pada PETS berbanding YNet. Kami juga telah membuat kemajuan besar dalam metrik ADE/FDE tradisional.
AnalisisAmbang jarak θ θ digunakan untuk menentukan kemas kini pustaka. Nilai biasa untuk θ ditetapkan berdasarkan panjang trajektori. Nilai mutlak ralat ramalan biasanya lebih besar apabila trajektori kebenaran tanah lebih panjang dalam piksel. Walau bagaimanapun, kesilapan relatif mereka adalah setanding. Oleh itu, apabila ralat menumpu, θ ditetapkan kepada 75% daripada ralat latihan. Dalam eksperimen, kami menetapkan θ = 25 dalam PETS dan θ = 6 dalam ADL. "75% ralat latihan" diperoleh daripada keputusan eksperimen, seperti ditunjukkan dalam Jadual 4.
Jadual 4: Perbandingan parameter berbeza θ pada set data PAV. Keputusan adalah purata bagi tiga kes.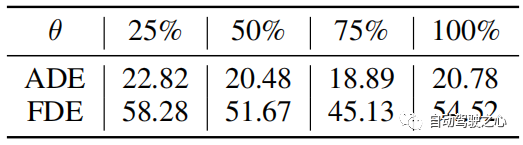

K Bilangan gugusan di titik tengah Kami mempelajari tetapan nombor yang berbeza Kesan kelompok awal K ditunjukkan dalam Jadual 5. Kita dapat perhatikan bahawa bilangan awal kluster tidak sensitif kepada keputusan ramalan, terutamanya apabila bilangan awal kluster ialah 24-36. Oleh itu, kita boleh menetapkan K kepada 32 dalam eksperimen.
Analisis kerumitan bank Kerumitan masa carian dan kemas kini ialah O(N) dan O(1) masing-masing. Kerumitan ruang mereka ialah O(N). Bilangan trajektori kumpulan N≤1000. Kerumitan masa proses pengelompokan ialah ββ, dan kerumitan ruang ialah ββ. β ialah bilangan trajektori pengelompokan. ialah bilangan kelompok, ialah bilangan lelaran kaedah pengelompokan.


Keputusan kualitatif
Rajah 6 menunjukkan keputusan kualitatif SHENet dan kaedah lain. Sebaliknya, kami terkejut apabila menyedari bahawa dalam kes yang sangat mencabar di mana seseorang berjalan ke tepi jalan dan kemudian berpatah balik (lengkung hijau), semua kaedah lain tidak mengendalikannya dengan baik, sementara SHENet yang kami cadangkan masih boleh Menanganinya. Ini harus dikaitkan dengan peranan modul perpustakaan trajektori kumpulan sejarah kami yang direka khas. Tambahan pula, berbeza dengan kaedah berasaskan memori MANTRA [20], kami mencari trajektori kumpulan, bukan hanya individu. Ini lebih serba boleh dan boleh digunakan pada senario yang lebih mencabar. Rajah 7 termasuk keputusan kualitatif untuk YNet dan SHENet kami tanpa/dengan Curve Smoothing (CS). Baris pertama menunjukkan keputusan menggunakan kehilangan MSE . Dijejaskan oleh trajektori lalu dengan sedikit hingar (seperti selekoh mengejut dan tajam), titik trajektori yang diramalkan YNet dikelompokkan bersama dan tidak dapat menunjukkan arah yang jelas, manakala kaedah kami boleh menyediakan laluan berpotensi berdasarkan trajektori kumpulan sejarah. Kedua-dua ramalan adalah berbeza secara visual, tetapi ralat berangka (ADE/FDE) adalah lebih kurang sama. Sebaliknya, keputusan kualitatif kehilangan CS kami yang dicadangkan ditunjukkan dalam baris kedua Rajah 7. Ia dapat dilihat bahawa CS yang dicadangkan dengan ketara mengurangkan kesan rawak dan subjektiviti dan menghasilkan ramalan yang munasabah melalui YNet dan kaedah kami.
Kesimpulan
Kertas kerja ini mencadangkan SHENet, pendekatan baru yang mengeksploitasi sepenuhnya sejarah senario HTP. SHENet termasuk modul GTB untuk membina perpustakaan trajektori kumpulan berdasarkan semua trajektori sejarah dan mendapatkan semula trajektori wakil orang yang diperhatikan daripada perpustakaan ia juga termasuk modul CMI (interaksi antara pergerakan manusia dan maklumat alam sekitar) untuk Memperhalusi trajektori perwakilan ini. Kami mencapai prestasi SOTA pada penanda aras HTP, dan pendekatan kami menunjukkan peningkatan yang ketara dan umum dalam senario yang mencabar. Walau bagaimanapun, masih terdapat beberapa aspek yang belum diterokai dalam rangka kerja semasa, seperti proses pembinaan bank pada masa ini hanya memfokuskan kepada gerakan manusia. Kerja masa depan termasuk meneroka perpustakaan trajektori dengan lebih lanjut menggunakan maklumat interaktif (gerakan manusia dan maklumat adegan).

Pautan asal: https://mp.weixin.qq.com/s/GE-t4LarwXJu2MC9njBInQ
Atas ialah kandungan terperinci Apakah kaedah yang berkesan dan kaedah Pangkalan biasa untuk ramalan trajektori pejalan kaki? Perkongsian kertas persidangan teratas!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!