
 Peranti teknologiAIRangkaian persepsi untuk kedalaman, sikap dan anggaran jalan dalam senario pemanduan bersama
Peranti teknologiAIRangkaian persepsi untuk kedalaman, sikap dan anggaran jalan dalam senario pemanduan bersamaRangkaian persepsi untuk kedalaman, sikap dan anggaran jalan dalam senario pemanduan bersama

Kertas arXiv "JPerceiver: Rangkaian Persepsi Bersama untuk Kedalaman, Pose dan Anggaran Susun Atur dalam Pemandangan Pemanduan", yang dimuat naik pada 22 Julai, melaporkan hasil kerja Profesor Tao Dacheng dari Universiti Sydney, Australia, dan Institut Penyelidikan JD Beijing .

Anggaran kedalaman, visual odometri (VO) dan pandangan mata burung (BEV) anggaran susun atur pemandangan ialah tiga tugas utama untuk memacu persepsi pemandangan, yang merupakan kunci kepada gerakan secara autonomi pemanduan. Asas perancangan dan pelayaran. Walaupun saling melengkapi, mereka biasanya menumpukan pada tugasan yang berasingan dan jarang menangani ketiga-tiganya secara serentak.
Pendekatan mudah ialah melakukannya secara bebas secara berurutan atau selari, tetapi terdapat tiga kelemahan, iaitu 1) kedalaman dan keputusan VO dipengaruhi oleh masalah kekaburan skala yang wujud 2) susun atur BEV biasanya dilakukan menganggarkan jalan dan kenderaan secara bebas sambil mengabaikan perhubungan tindanan-dasar yang jelas 3) Walaupun peta kedalaman adalah petunjuk geometri yang berguna untuk membuat kesimpulan reka letak pemandangan, reka letak BEV sebenarnya diramalkan terus daripada imej pandangan hadapan tanpa menggunakan sebarang maklumat berkaitan kedalaman.
Kertas kerja ini mencadangkan rangka kerja persepsi bersama JPerceiver untuk menyelesaikan masalah ini dan pada masa yang sama menganggarkan kedalaman persepsi skala, reka letak VO dan BEV daripada jujukan video monokular. Gunakan transformasi geometri pandangan silang (CGT) untuk menyebarkan skala mutlak daripada susun atur jalan ke kedalaman dan VO mengikut kehilangan skala yang direka dengan teliti. Pada masa yang sama, modul cross-view and cross-modal transfer (CCT) direka bentuk untuk menggunakan petunjuk kedalaman untuk menaakul tentang susun atur jalan dan kenderaan melalui mekanisme perhatian.
JPerceiver dilatih dalam kaedah pembelajaran berbilang tugas hujung ke hujung, di mana kehilangan skala CGT dan modul CCT menggalakkan pemindahan pengetahuan antara tugas dan memudahkan pembelajaran ciri untuk setiap tugas. Kod dan model boleh dimuat turunhttps://github.com/sunnyHelen/JPerceiver.
Seperti yang ditunjukkan dalam rajah, JPerceiver terdiri daripada tiga rangkaian: kedalaman, sikap dan susun atur jalan, semuanya berdasarkan seni bina pengekod-penyahkod. Rangkaian kedalaman bertujuan untuk meramalkan peta kedalaman Dt bagi bingkai semasa Ia, di mana setiap nilai kedalaman mewakili jarak antara titik 3D dan kamera. Matlamat rangkaian pose adalah untuk meramalkan transformasi pose Tt→t+m antara bingkai semasa It dan bingkai bersebelahan It+m. Matlamat rangkaian susun atur jalan adalah untuk menganggarkan Lt susun atur BEV bagi rangka semasa, iaitu penghunian semantik jalan dan kenderaan dalam pesawat Cartesian pandangan atas. Tiga rangkaian tersebut dioptimumkan bersama semasa latihan.


CCT-CV dan CCT-CM modul cross-view dan modul cross-modal.

Dalam CCT, Ff dan Fd diekstrak oleh pengekod cabang persepsi yang sepadan, manakala Fb diperoleh melalui unjuran pandangan MLP untuk menukar Ff kepada BEV, dan kehilangan kitaran mengekang MLP yang sama untuk menukarnya semula kepada Ff′ .
Dalam CCT-CV, mekanisme perhatian silang digunakan untuk menemui korespondensi geometri antara paparan hadapan dan ciri BEV, dan kemudian membimbing pemurnian maklumat pandangan hadapan dan bersedia untuk inferens BEV. Untuk menggunakan sepenuhnya ciri imej paparan hadapan, Fb dan Ff diunjurkan kepada tampalan: Qbi dan Kbi, sebagai pertanyaan dan kunci masing-masing.
Selain menggunakan ciri pandangan hadapan, CCT-CM juga digunakan untuk mengenakan maklumat geometri 3-D daripada Fd. Memandangkan Fd diekstrak daripada imej paparan hadapan, adalah munasabah untuk menggunakan Ff sebagai jambatan untuk mengurangkan jurang rentas modal dan mempelajari kesesuaian antara Fd dan Fb. Fd memainkan peranan Nilai, dengan itu memperoleh maklumat geometri 3-D yang berharga berkaitan dengan maklumat BEV dan meningkatkan lagi ketepatan anggaran susun atur jalan.
Dalam proses meneroka rangka kerja pembelajaran bersama untuk meramalkan susun atur yang berbeza secara serentak, terdapat perbezaan besar dalam ciri dan pengedaran kategori semantik yang berbeza. Untuk ciri, susun atur jalan dalam senario pemanduan biasanya perlu disambungkan, manakala sasaran kenderaan yang berbeza mesti dibahagikan.
Mengenai pengedaran, lebih banyak adegan jalan lurus diperhatikan daripada adegan berpusing, yang munasabah dalam set data sebenar. Perbezaan dan ketidakseimbangan ini meningkatkan kesukaran pembelajaran susun atur BEV, terutamanya meramalkan kategori yang berbeza secara bersama, kerana kehilangan entropi silang (CE) mudah atau kehilangan L1 gagal dalam kes ini. Beberapa kehilangan segmentasi, termasuk kehilangan CE berasaskan pengedaran, kehilangan IoU berasaskan wilayah dan kehilangan sempadan, digabungkan menjadi kerugian hibrid untuk meramalkan susun atur setiap kategori.
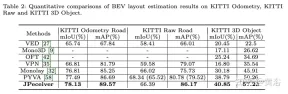
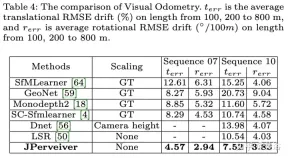
Keputusan percubaan adalah seperti berikut:



Atas ialah kandungan terperinci Rangkaian persepsi untuk kedalaman, sikap dan anggaran jalan dalam senario pemanduan bersama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimana untuk membina permainan dengan Openai O1? - Analytics VidhyaApr 12, 2025 am 10:03 AM
Bagaimana untuk membina permainan dengan Openai O1? - Analytics VidhyaApr 12, 2025 am 10:03 AMPengenalan Keluarga model Openai O1 secara signifikan memajukan kuasa penalaran dan prestasi ekonomi, terutamanya dalam sains, pengekodan, dan penyelesaian masalah. Matlamat Openai adalah untuk mencipta AI yang lebih maju, dan model O1
 Alat ejen LLM yang popular untuk pengurusan pertanyaan pelangganApr 12, 2025 am 10:01 AM
Alat ejen LLM yang popular untuk pengurusan pertanyaan pelangganApr 12, 2025 am 10:01 AMPengenalan Hari ini, dunia pengurusan pertanyaan pelanggan bergerak pada kadar yang tidak pernah berlaku sebelum ini, dengan alat -alat baru membuat tajuk utama setiap hari. Ejen Model Bahasa Besar (LLM) adalah inovasi terkini dalam konteks ini, meningkatkan CU
 Pelan Pelaksanaan AI Generatif 100 Hari untuk PerusahaanApr 12, 2025 am 09:56 AM
Pelan Pelaksanaan AI Generatif 100 Hari untuk PerusahaanApr 12, 2025 am 09:56 AMPengenalan Mengguna pakai AI generatif boleh menjadi perjalanan transformatif untuk mana -mana syarikat. Walau bagaimanapun, proses pelaksanaan GueLy sering boleh menjadi rumit dan mengelirukan. Rajendra Singh Pawar, Pengerusi dan Pengasas Bersama Niit Lim
 Pixtral 12b vs qwen2-vl-72bApr 12, 2025 am 09:52 AM
Pixtral 12b vs qwen2-vl-72bApr 12, 2025 am 09:52 AMPengenalan Revolusi AI telah menimbulkan era kreativiti baru, di mana model teks-ke-imej telah mentakrifkan semula persimpangan seni, reka bentuk, dan teknologi. Pixtral 12b dan qwen2-vl-72b adalah dua pasukan perintis drivin
 Apakah Paperqa dan bagaimana ia membantu dalam penyelidikan saintifik?Apr 12, 2025 am 09:51 AM
Apakah Paperqa dan bagaimana ia membantu dalam penyelidikan saintifik?Apr 12, 2025 am 09:51 AMPengenalan Dengan kemajuan AI, penyelidikan saintifik telah melihat transformasi besar -besaran. Berjuta -juta kertas diterbitkan setiap tahun pada teknologi dan sektor yang berbeza. Tetapi, menavigasi lautan maklumat ini ke geser
 Datagemma: LLM Grounding Against Hallucinations - Analytics VidhyaApr 12, 2025 am 09:46 AM
Datagemma: LLM Grounding Against Hallucinations - Analytics VidhyaApr 12, 2025 am 09:46 AMPengenalan Model bahasa yang besar dengan cepat mengubah industri-hari ini, mereka menguasai segala-galanya dari perkhidmatan pelanggan yang diperibadikan dalam perbankan ke terjemahan bahasa masa nyata dalam komunikasi global. Mereka boleh menjawab usaha
 Bagaimana Membina Sistem Multi-Agen dengan Crewai dan Ollama?Apr 12, 2025 am 09:44 AM
Bagaimana Membina Sistem Multi-Agen dengan Crewai dan Ollama?Apr 12, 2025 am 09:44 AMPengenalan Tidak mahu membelanjakan wang untuk API, atau adakah anda prihatin terhadap privasi? Atau adakah anda hanya mahu menjalankan LLMs secara tempatan? Jangan risau; Panduan ini akan membantu anda membina ejen dan kerangka multi-agen dengan LLMS tempatan t
 AV Bytes: Model Openai 'Apr 12, 2025 am 09:38 AM
AV Bytes: Model Openai 'Apr 12, 2025 am 09:38 AMPengenalan Minggu ini telah dikemas dengan kemas kini utama dalam Dunia Kecerdasan Buatan (AI). Dari model O1 O1 Openai yang mempamerkan penalaran maju ke teknologi kecerdasan visual yang terancam Apple, Tech


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

