
Rumah >Peranti teknologi >AI >Biarkan kuasa pengkomputeran tidak lagi menjadi halangan, pembelajaran mesin Xiaohongshu kaedah pengoptimuman inferens perkakasan heterogen
Biarkan kuasa pengkomputeran tidak lagi menjadi halangan, pembelajaran mesin Xiaohongshu kaedah pengoptimuman inferens perkakasan heterogen

- PHPzke hadapan
- 2023-09-08 12:33:061640semak imbas

Banyak syarikat menggabungkan pembangunan kuasa pengkomputeran GPU untuk meneroka penyelesaian kepada masalah pembelajaran mesin yang sesuai untuk mereka. Sebagai contoh, Xiaohongshu akan memulakan transformasi berasaskan GPU bagi model carian promosi pada tahun 2021 untuk meningkatkan prestasi dan kecekapan inferens. Semasa proses penghijrahan, kami juga menghadapi beberapa kesukaran, seperti cara berhijrah dengan lancar kepada perkakasan heterogen, cara membangunkan penyelesaian kami sendiri berdasarkan senario perniagaan Xiaohongshu dan seni bina dalam talian, dsb. Di bawah trend global pengurangan kos dan peningkatan kecekapan, pengkomputeran heterogen telah menjadi arah yang menjanjikan, yang boleh meningkatkan prestasi pengkomputeran dengan menggabungkan pelbagai jenis pemproses (seperti CPU, GPU, FPGA, dll.) untuk mencapai kecekapan yang lebih baik dan kos yang lebih rendah.
1. Latar Belakang
Perkhidmatan model pengesyoran, pengiklanan, carian dan senario utama yang lain secara seragam dibawa oleh seni bina inferens peringkat pertengahan. Dengan perkembangan berterusan perniagaan Xiaohongshu, skala model untuk senario seperti carian promosi juga meningkat. Mengambil model utama senario pengesyoran yang diperhalusi sebagai contoh, sejak awal tahun 2020, algoritma telah melancarkan pemodelan penuh minat dan purata panjang rekod gelagat sejarah pengguna telah berkembang kira-kira 100 kali ganda. Struktur model juga telah melalui beberapa pusingan lelaran daripada muti-task awal, dan kerumitan struktur model juga terus meningkat Perubahan ini telah menghasilkan peningkatan 30 kali ganda dalam bilangan operasi titik terapung inferens model dan peningkatan kira-kira 5 kali ganda dalam akses memori model.
 Gambar
Gambar
Ciri model: Ambil model utama Xiaohongshu yang disyorkan pada penghujung tahun 2022 sebagai contoh Model ini mempunyai jimat yang mencukupi, dan sebahagian daripada struktur terdiri daripada nilai berterusan Ia terdiri daripada ciri dan operasi matriks, dan terdapat juga parameter jarang berskala besar seperti Ciri-ciri jarang bagi satu model adalah sehingga 1TB pengoptimuman, bahagian padat dikawal dalam 10GB dan boleh diletakkan dalam memori video. Setiap kali pengguna meleret Xiaohongshu, jumlah FLOP yang dikira mencapai 40B, dan tamat masa dikawal dalam 300ms (tidak termasuk pemprosesan ciri, dengan carian).
Rangka kerja inferens: Sebelum 2020, Xiaohongshu menerima pakai rangka kerja TensorFlow Serving sebagai rangka kerja perkhidmatan dalam talian secara beransur-ansur Perkhidmatan Lambda yang dibangunkan sendiri berdasarkan TensorFlowCore. TensorFlow Serving melakukan salinan memori TensorProto -> CTensor sebelum memasukkan graf untuk memastikan ketepatan dan kebolehpercayaan inferens model. Walau bagaimanapun, apabila skala perniagaan berkembang, operasi salinan memori akan memberi kesan kepada prestasi model. Rangka kerja Xiaohongshu yang dibangunkan sendiri menghapuskan penyalinan yang tidak perlu melalui pengoptimuman, sambil mengekalkan ciri masa jalan yang boleh dipasang, keupayaan penjadualan graf dan keupayaan pengoptimuman, dan meletakkan asas untuk penggunaan rangka kerja pengoptimuman yang berbeza seperti TRT, BLADE dan TVM. Kini nampaknya memilih penyelidikan sendiri pada masa yang tepat adalah pilihan yang bijak Pada masa yang sama, untuk meminimumkan kos penghantaran data, rangka kerja inferens juga melaksanakan sebahagian daripada pelaksanaan pengekstrakan dan transformasi ciri masih menganggarkan Storan tepi yang dibangunkan sendiri digunakan pada bahagian berhampiran perkhidmatan, yang menyelesaikan masalah kos menarik data dari jauh.
Ciri model: Xiaohongshu tidak mempunyai bilik komputer yang dibina sendiri, dan semua mesin dibeli daripada vendor awan model yang berbeza Keputusan bergantung pada jenis mesin yang boleh dibeli. Pengiraan inferens model bukan pengiraan GPU tulen Untuk mencari nisbah perkakasan yang munasabah, selain mempertimbangkan GPUCPU, ia juga melibatkan isu seperti lebar jalur, lebar jalur memori dan kelewatan komunikasi silang-numa.
Gambar 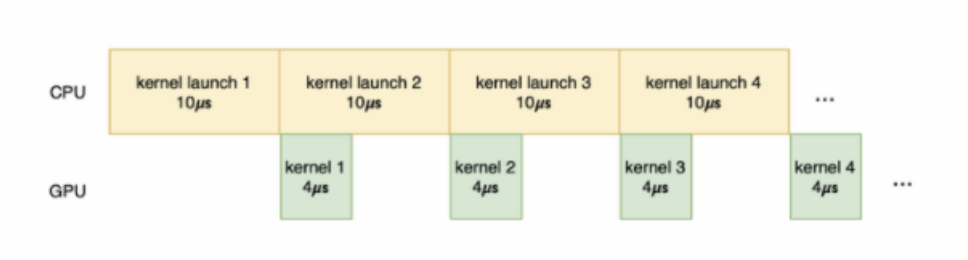 Ciri GPU
Ciri GPU
#🎜🎜🎜##🎜🎜
Di sini, Xiaohongshu dan syarikat lain menghadapi masalah yang sama Pelaksanaan kernel GPU boleh dibahagikan kepada peringkat berikut: penghantaran data, permulaan kernel, pengiraan kernel dan penghantaran hasil. Antaranya, penghantaran data adalah untuk memindahkan data dari memori hos ke memori GPU adalah untuk memindahkan kod kernel dari bahagian hos ke bahagian GPU, dan memulakan pengiraan kernel pada GPU sebenarnya; hasil pengiraan kod kernel; penghantaran hasil adalah kepada Hasil pengiraan dipindahkan dari memori GPU kembali ke memori hos. Jika sejumlah besar masa dibelanjakan untuk penghantaran data dan permulaan kernel, dan kerja yang dihantar ke kernel untuk pengiraan tidak berat, dan masa pengiraan sebenar adalah sangat singkat, penggunaan GPU tidak akan bertambah baik, malah berjalan kosong akan berlaku. Gambar
3.1.1 Mesin fizikal Dari segi pengoptimuman mesin fizikal, beberapa idea pengoptimuman konvensional boleh diguna pakai Tujuan utama sistem lain adalah untuk mengurangkan overhed selain daripada GPU , mengurangkan orang tengah virtualisasi untuk membuat keuntungan. Secara umumnya, satu set pengoptimuman sistem boleh meningkatkan prestasi sebanyak 1%-2%. Daripada amalan kami, pengoptimuman perlu digabungkan dengan keupayaan sebenar vendor awan. ● Pengasingan Gangguan: Asingkan gangguan GPU untuk mengelakkan gangguan daripada peranti lain yang menjejaskan prestasi pengkomputeran GPU. ● Peningkatan versi kernel: Tingkatkan kestabilan dan keselamatan sistem, tingkatkan keserasian dan prestasi pemacu GPU. ● Arahan penghantaran telus: Hantar secara telus arahan GPU terus ke peranti fizikal untuk mempercepatkan kelajuan pengkomputeran GPU. 3.1.2 Maya dan Bekas Dalam situasi berbilang kad, ikat satu pod pada nod NUMA tertentu, dengan itu meningkatkan kelajuan pemindahan data antara CPU dan GPU. ● CPU NUMA Affinity, afiniti merujuk kepada akses memori yang lebih pantas dan mempunyai kependaman yang lebih rendah dari perspektif CPU. Seperti yang dinyatakan sebelum ini, memori tempatan yang disambungkan terus ke CPU adalah lebih pantas. Oleh itu, sistem pengendalian boleh memperuntukkan memori tempatan mengikut CPU di mana tugas itu terletak untuk meningkatkan kelajuan akses dan prestasi Ini berdasarkan pertimbangan CPU NUMA Affinity dan cuba menjalankan tugas dalam Nod NUMA tempatan. Dalam senario Xiaohongshu, overhed akses memori pada CPU bukanlah kecil. Membenarkan CPU menyambung terus ke memori tempatan boleh menjimatkan banyak masa yang dibelanjakan untuk pelaksanaan kernel pada CPU, meninggalkan ruang yang cukup untuk GPU. ● Dengan mengawal penggunaan CPU pada 70%, kelewatan boleh dikurangkan daripada 200ms -> 150ms. 3.1.3 Cermin Pengoptimuman kompilasi. CPU yang berbeza mempunyai keupayaan sokongan yang berbeza untuk tahap arahan, dan model yang dibeli oleh vendor awan yang berbeza juga berbeza. Idea yang agak mudah adalah untuk menyusun imej dengan set arahan yang berbeza dalam senario perkakasan yang berbeza. Apabila melaksanakan pengendali, sebilangan besar operator sudah mempunyai arahan seperti AVX512. Mengambil model Intel(R) Xeon(R) Platinum 8163 + 2 A10 Alibaba Cloud sebagai contoh, kami menyusun, mengoptimumkan dan melaraskan set arahan yang sesuai berdasarkan ciri model dan set arahan yang disokong Secara keseluruhannya, berbanding tidak berprestasi Dengan pengoptimuman arahan, daya pemprosesan CPU pada model ini meningkat sebanyak 10%. 3.2.1 Gunakan sepenuhnya kuasa pengkomputeran ● Pengoptimuman pengkomputeran, anda perlu memahami sepenuhnya prestasi perkakasan dan memahaminya dengan sepenuhnya. Dalam senario Xiaohongshu, seperti yang ditunjukkan dalam rajah di bawah, kami menghadapi dua masalah teras: 1 Terdapat banyak akses memori pada CPU, dan kekerapan kerosakan halaman memori adalah tinggi, mengakibatkan pembaziran sumber CPU dan tinggi. kependaman permintaan. 2. Dalam perkhidmatan inferens dalam talian, pengiraan biasanya mempunyai dua ciri: saiz kumpulan permintaan tunggal adalah kecil dan skala serentak bagi satu perkhidmatan adalah besar. Saiz kelompok yang kecil akan menyebabkan kernel tidak dapat menggunakan sepenuhnya kuasa pengkomputeran GPU. Masa pelaksanaan kernel GPU biasanya lebih pendek, yang tidak dapat menutup sepenuhnya overhed pelancaran kernel, malah masa pelancaran kernel lebih lama daripada masa pelaksanaan kernel. Dalam TensorFlow, satu kernel pelancaran Cuda Stream menjadi hambatan, menghasilkan hanya 50% penggunaan GPU dalam senario inferens. Di samping itu, untuk senario model kecil (rangkaian padat ringkas), ia tidak menjimatkan kos untuk menggantikan CPU dengan GPU, yang mengehadkan kerumitan model. ● Untuk menyelesaikan dua masalah di atas, kami telah mengambil langkah berikut: 1 Untuk menangani masalah kekerapan kerosakan halaman memori yang tinggi, kami menggunakan perpustakaan jemalloc mekanisme dan dayakan ciri halaman besar telus sistem pengendalian. Di samping itu, untuk ciri capaian memori khas lambda, kami mereka bentuk struktur data khas dan mengoptimumkan strategi peruntukan memori untuk mengelakkan pemecahan memori sebanyak mungkin. Pada masa yang sama, kami terus memintas antara muka tf_serving dan terus dipanggil TensorFlow, yang mengurangkan pensirilan dan penyahserilan data. Pengoptimuman ini telah meningkatkan daya pengeluaran sebanyak 10+% dalam halaman utama dan senario penalaan halus dalam strim serta mengurangkan kependaman sebanyak 50% dalam kebanyakan senario pengiklanan. serasi dengan tensorflow::Tensor format, dan disalin sifar sebelum menghantar ciri kepada tensorflow::SessionRun 2. Sebagai tindak balas kepada masalah Aliran Cuda tunggal TensorFlow, kami menyokong fungsi Berbilang Aliran dan Berbilang Konteks, mengelakkan kesesakan prestasi yang disebabkan oleh kunci mutex, dan berjaya meningkatkan penggunaan GPU kepada 90+%. Pada masa yang sama, kami menggunakan fungsi Cuda MPS yang disediakan oleh Nvidia untuk merealisasikan pemultipleksan pembahagian ruang bagi GPU (menyokong pelaksanaan berbilang kernel pada masa yang sama), meningkatkan lagi penggunaan GPU. Berdasarkan ini, model kedudukan Carian telah berjaya dilaksanakan pada GPU. Selain itu, kami juga telah berjaya melaksanakannya dalam barisan perniagaan lain, termasuk susun atur halaman utama, pengiklanan, dsb. Jadual berikut ialah situasi pengoptimuman dalam senario kedudukan carian. 3. Teknologi gabungan Op/Kernel: Menjana pengendali Tensorflow berprestasi tinggi melalui tulisan tangan atau kompilasi graf dan alatan pengoptimuman, menggunakan sepenuhnya Cache CPU dan Memori Dikongsi GPU untuk meningkatkan daya pemprosesan sistem. Dalam senario aliran masuk, pengendali digabungkan, dan anda boleh melihat bahawa satu panggilan ialah 12ms -> 5ms 3.2.2 Mengelakkan pembaziran kuasa pengkomputeran.🜎 a Pengiraan awal: Apabila memproses pengiraan berkaitan sisi pengguna, pengisihan awal perlu mengira sejumlah besar nota Sebagai contoh, mengambil aliran keluar sebagai contoh, kira-kira 5,000 nota perlu dikira , dan lambda mempunyai pemprosesan penghirisan untuk mereka. Untuk mengelakkan pengiraan berulang, pengiraan sisi pengguna bagi baris awal dialihkan selari dengan fasa ingat semula, supaya pengiraan vektor pengguna dikurangkan daripada berbilang ulangan kepada satu masa sahaja, 40% daripada mesin dioptimumkan dalam senario baris kasar. a Pra-pemprosesan pengiraan: Sebahagian daripada pengiraan boleh diproses terlebih dahulu melalui pembekuan graf. Apabila membuat penaakulan, tidak perlu mengulang pengiraan. b. Pengoptimuman pembekuan model output: Apabila model dikeluarkan, semua parameter dijana bersama dengan graf itu sendiri untuk menghasilkan graf beku (graf beku) dan melakukan pengiraan prapemprosesan Banyak operator Pembolehubah prakira boleh ditukar kepada operator Const ( GPU penggunaan berkurangan sebanyak 12%) c. Pengiraan gabungan dalam senario inferens: Setiap kumpulan hanya mengandungi satu pengguna, iaitu, terdapat sejumlah besar pengiraan berulang pada bahagian pengguna, dengan kemungkinan menggabungkan CPU/. Pemisahan operator GPU : Alihkan semua operator selepas mencari ke GPU, mengelakkan salinan data antara CPU dan GPU e GPU ke salinan data CPU: Pek data dan salin sekali f pelaksanaan sub-GPU cuda. Percepatkan pengiraan melalui GPU untuk meningkatkan prestasi g Pengendali separa berasaskan GPU: tinggalkan CPU -> salinan GPU j: Dengan melaksanakan lapisan MLP baharu, mengikut matlamat, kurangkan bilangan kali memasuki GPU (N -> 1), tingkatkan jumlah pengiraan untuk satu pengiraan (guna semula keupayaan konkurensi teras kecil GPU) Gambar ● Penurunan taraf pengkomputeran dinamik meningkatkan kecekapan penggunaan sumber sepanjang hari, dan secara automatik melaraskan beban lambda dengan maklum balas negatif pada tahap kedua untuk mencapai ujian tekanan zon tunggal Tidak perlu menyediakan secara manual untuk penurunan taraf sebelum ini. ● Senario perniagaan utama seperti kedudukan diperhalusi keluar, pengisihan awal keluar, pengisihan halus masuk, pengisihan awal aliran masuk dalaman dan carian semuanya telah dilancarkan. ● Menyelesaikan masalah kapasiti dalam berbilang bidang perniagaan, mengurangkan peningkatan linear dalam sumber yang disebabkan oleh pertumbuhan perniagaan dengan berkesan, dan meningkatkan keteguhan sistem dengan berkesan. Dalam bidang perniagaan selepas fungsi itu dilancarkan, tiada kemalangan P3 atau lebih tinggi yang disebabkan oleh penurunan mendadak dalam kadar kejayaan serta-merta. ● Sangat meningkatkan kecekapan penggunaan sumber sepanjang hari dengan mengambil penalaan halus dalam strim sebagai contoh (seperti yang ditunjukkan dalam rajah di bawah), bilangan teras CPU yang digunakan semasa cuti Hari Mei tiga hari dari jam 10:00 hingga. 24:00 mengekalkan garisan rata 50 teras (Dithering sepadan dengan versi keluaran) Pictures Prestasi GPU ialah 1.5. GPU T4 Pada masa yang sama, model A10 dilengkapi dengan CPU ( icelake , 10nm) adalah generasi yang lebih baru daripada model T4 (skylake, 14nm), dan harganya hanya 1.2 kali ganda daripada model T4. . Kami juga akan mempertimbangkan untuk menggunakan model seperti A30 dalam talian pada masa hadapan. 3.3 Pengoptimuman gambar Gambar ● BladeDISC ialah pengkompil pembelajaran mendalam bentuk dinamik sumber terbuka terbaru Alibaba berdasarkan bahagian pengoptimuman graf automatik Xiaohongshu berasal daripada rangka kerja ini (Pustaka pecutan inferens Blade ialah sumber terbuka Apache 2.0, boleh digunakan merentasi mana-mana awan dan tidak mempunyai hak harta intelek. risiko). Rangka kerja ini menyediakan pengoptimuman penyusunan graf TF (termasuk Pengkompil Bentuk Dinamik, pengoptimuman subgraf jarang), dan juga boleh menindih pengoptimuman pengendali tersuai kami sendiri, yang boleh menyesuaikan diri dengan lebih baik kepada senario perniagaan kami. Dalam inferens mesin tunggal ujian tekanan, QPS boleh ditingkatkan sebanyak 20%. ● Teknologi utama rangka kerja ini (1) Infrastruktur MLIR MLIR, Perwakilan Perantaraan Berbilang Peringkat (Perwakilan Perantaraan Berbilang Peringkat), ialah projek sumber terbuka yang dimulakan oleh Google. Tujuannya adalah untuk menyediakan infrastruktur IR berbilang peringkat dan perpustakaan utiliti pengkompil yang fleksibel dan boleh diperluas, menyediakan rangka kerja bersatu untuk pemaju alat pengkompil dan bahasa. Reka bentuk MLIR dipengaruhi oleh LLVM, tetapi tidak seperti LLVM, MLIR tertumpu terutamanya pada reka bentuk dan lanjutan perwakilan perantaraan (IR). MLIR menyediakan reka bentuk IR berbilang peringkat yang boleh menyokong proses penyusunan daripada bahasa peringkat tinggi kepada perkakasan peringkat rendah, dan menyediakan sokongan infrastruktur yang kaya dan seni bina reka bentuk modular, membolehkan pembangun mengembangkan fungsi MLIR dengan mudah. Selain itu, MLIR juga mempunyai keupayaan gam yang kuat dan boleh disepadukan dengan bahasa pengaturcaraan dan alat yang berbeza. MLIR ialah infrastruktur pengkompil yang berkuasa dan perpustakaan alat yang menyediakan pembangun penyusun dan alatan bahasa dengan bahasa perwakilan perantaraan yang bersatu dan fleksibel yang boleh memudahkan pengoptimuman kompilasi dan penjanaan kod. (2) Penyusunan bentuk dinamik Keterbatasan bentuk statik bermakna bentuk setiap input dan output perlu ditentukan terlebih dahulu semasa menulis model pembelajaran mendalam, dan ia tidak boleh diubah semasa masa jalan. Ini mengehadkan fleksibiliti dan skalabiliti model pembelajaran mendalam, justeru memerlukan pengkompil pembelajaran mendalam yang menyokong bentuk dinamik. 3.3.2 Pelarasan Ketepatan ● Salah satu cara untuk mencapai kuantisasi adalah untuk menggunakan pengoptimuman pengiraan FP16 Dalam proses melaraskan FP16, memilih kaedah kotak putih untuk pengoptimuman ketepatan bermakna kita boleh mengawal dengan lebih halus lapisan mana yang menggunakan pengiraan ketepatan rendah, dan boleh terus melaras dan mengoptimumkan berdasarkan pengalaman. Kaedah ini memerlukan pemahaman dan analisis yang agak mendalam tentang struktur model, dan pelarasan yang disasarkan boleh dibuat berdasarkan ciri-ciri dan keperluan pengiraan model untuk mencapai prestasi kos yang lebih tinggi. Infrastruktur sangat kritikal untuk menyokong aplikasi AI. Xiaohongshu boleh mempertimbangkan untuk melabur lebih lanjut dalam pembinaan infrastruktur, termasuk keupayaan pengkomputeran dan storan, pusat data dan seni bina rangkaian. Selain itu, ia juga sangat penting untuk meningkatkan keupayaan pemprosesan data untuk menyokong pembelajaran mesin dan aplikasi sains data dengan lebih baik. Pasukan pembelajaran mesin yang cemerlang memerlukan bakat dengan kemahiran dan latar belakang yang berbeza, termasuk saintis data, jurutera algoritma, jurutera perisian, dll., mengoptimumkan struktur organisasi juga boleh membantu meningkatkan kecekapan pasukan dan keupayaan inovasi. Xiaohongshu terus bekerjasama dengan syarikat lain, institusi akademik dan komuniti sumber terbuka untuk bersama-sama mempromosikan pembangunan teknologi AI, yang membantu Xiaohongshu memperoleh lebih banyak sumber dan pengetahuan serta menjadi organisasi yang lebih terbuka dan inovatif. Penyelesaian ini membawa seni bina pembelajaran mesin Xiaohongshu ke peringkat teratas dalam industri. Pada masa hadapan, kami akan terus mempromosikan peningkatan enjin, mengurangkan kos dan meningkatkan kecekapan, memperkenalkan teknologi baharu untuk meningkatkan produktiviti pembelajaran mesin Xiaohongshu, dan seterusnya menyepadukan senario perniagaan sebenar Xiaohongshu, menaik taraf daripada pengoptimuman modul tunggal kepada pengoptimuman sistem penuh, dan seterusnya Memperkenalkan ciri pembezaan yang diperibadikan bagi trafik sebelah perniagaan untuk mencapai pengurangan kos dan peningkatan kecekapan yang muktamad. Kami menantikan orang yang mempunyai cita-cita tinggi untuk menyertai kami! Zhang Chulan (Du Zeyu): Jabatan Teknologi Perniagaan lulus dari East China Normal University, ketua pasukan enjin pengkomersialan, yang bertanggungjawab terutamanya untuk membina perkhidmatan dalam talian yang dikomersialkan. Lu Guang (Peng Peng): Jabatan Pengedaran Pintar berkelulusan dari Universiti Shanghai Jiao Tong, jurutera enjin pembelajaran mesin, yang bertanggungjawab terutamanya untuk pengoptimuman GPU Lambda. Ian (Chen Jianxin): Jabatan Pengedaran Pintar lulus dari Universiti Pos dan Telekomunikasi Beijing, jurutera enjin pembelajaran mesin, yang bertanggungjawab terutamanya untuk pelayan parameter Lambda dan pengoptimuman GPU. Aka Yu (Liu Zhaoyu): Jabatan Pengedaran Pintar lulus dari Universiti Tsinghua dan merupakan seorang jurutera enjin pembelajaran mesin Dia bertanggungjawab terutamanya untuk penyelidikan dan penerokaan berkaitan ke arah enjin ciri. Terima kasih khas kepada: Semua pelajar di Jabatan Pengedaran Pintar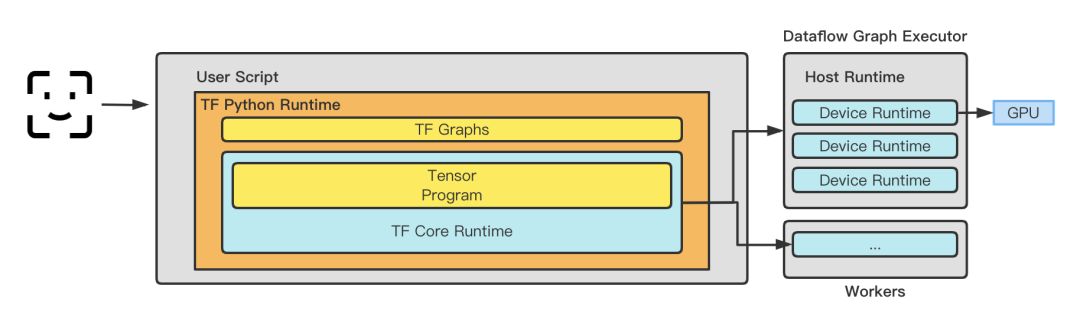 Anggaran Rangka Kerja Perkhidmatan
Anggaran Rangka Kerja Perkhidmatan3.Amalan pengoptimuman GPU
3.1 Pengoptimuman sistem
# Intel(R) Xeon(R) Platinum 8163 for ali intelbuild:intel --copt=-march=skylake-avx512 --copt=-mmmx --copt=-mno-3dnow --copt=-mssebuild:intel --copt=-msse2 --copt=-msse3 --copt=-mssse3 --copt=-mno-sse4a --copt=-mcx16build:intel --copt=-msahf --copt=-mmovbe --copt=-maes --copt=-mno-sha --copt=-mpclmulbuild:intel --copt=-mpopcnt --copt=-mabm --copt=-mno-lwp --copt=-mfma --copt=-mno-fma4build:intel --copt=-mno-xop --copt=-mbmi --copt=-mno-sgx --copt=-mbmi2 --copt=-mno-pconfigbuild:intel --copt=-mno-wbnoinvd --copt=-mno-tbm --copt=-mavx --copt=-mavx2 --copt=-msse4.2build:intel --copt=-msse4.1 --copt=-mlzcnt --copt=-mrtm --copt=-mhle --copt=-mrdrnd --copt=-mf16cbuild:intel --copt=-mfsgsbase --copt=-mrdseed --copt=-mprfchw --copt=-madx --copt=-mfxsrbuild:intel --copt=-mxsave --copt=-mxsaveopt --copt=-mavx512f --copt=-mno-avx512erbuild:intel --copt=-mavx512cd --copt=-mno-avx512pf --copt=-mno-prefetchwt1build:intel --copt=-mno-clflushopt --copt=-mxsavec --copt=-mxsavesbuild:intel --copt=-mavx512dq --copt=-mavx512bw --copt=-mavx512vl --copt=-mno-avx512ifmabuild:intel --copt=-mno-avx512vbmi --copt=-mno-avx5124fmaps --copt=-mno-avx5124vnniwbuild:intel --copt=-mno-clwb --copt=-mno-mwaitx --copt=-mno-clzero --copt=-mno-pkubuild:intel --copt=-mno-rdpid --copt=-mno-gfni --copt=-mno-shstk --copt=-mno-avx512vbmi2build:intel --copt=-mavx512vnni --copt=-mno-vaes --copt=-mno-vpclmulqdq --copt=-mno-avx512bitalgbuild:intel --copt=-mno-movdiri --copt=-mno-movdir64b --copt=-mtune=skylake-avx512
3.2 Pengoptimuman pengkomputeran
 Gambar
Gambar Imej
Imej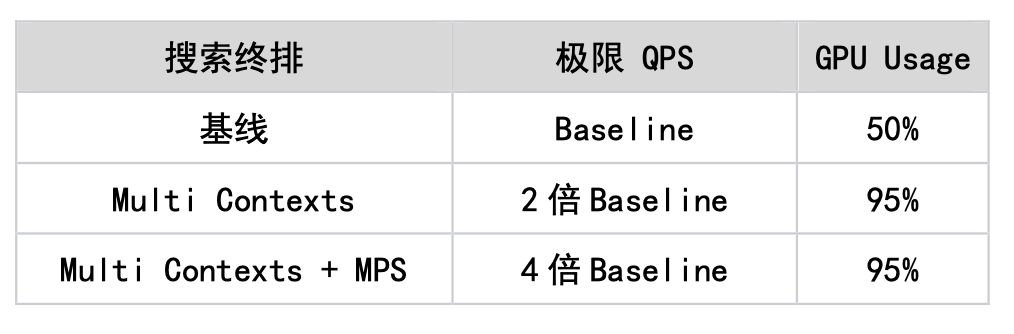 Pictures
Pictures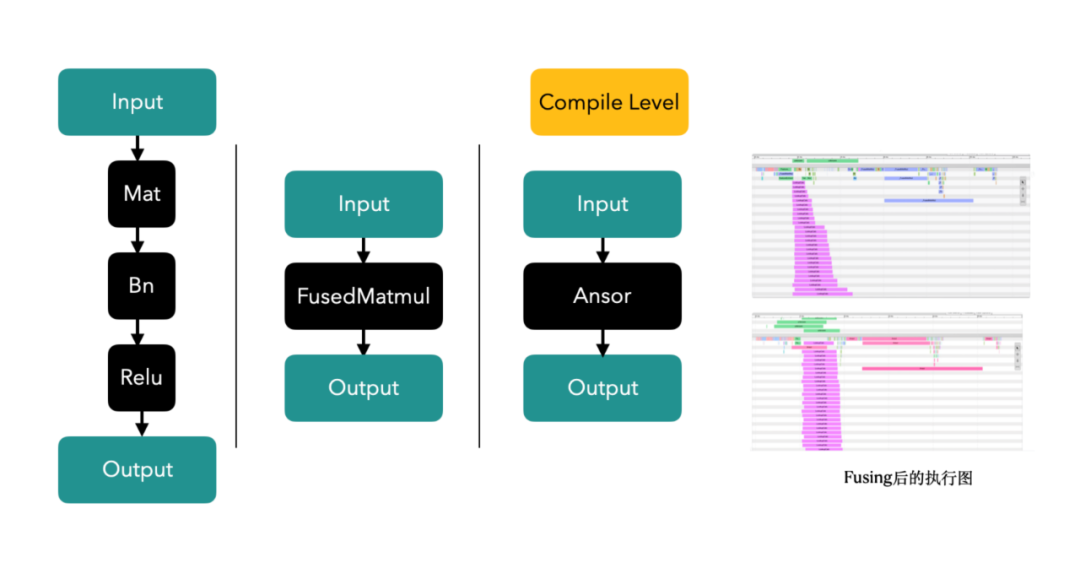 Gambar
Gambar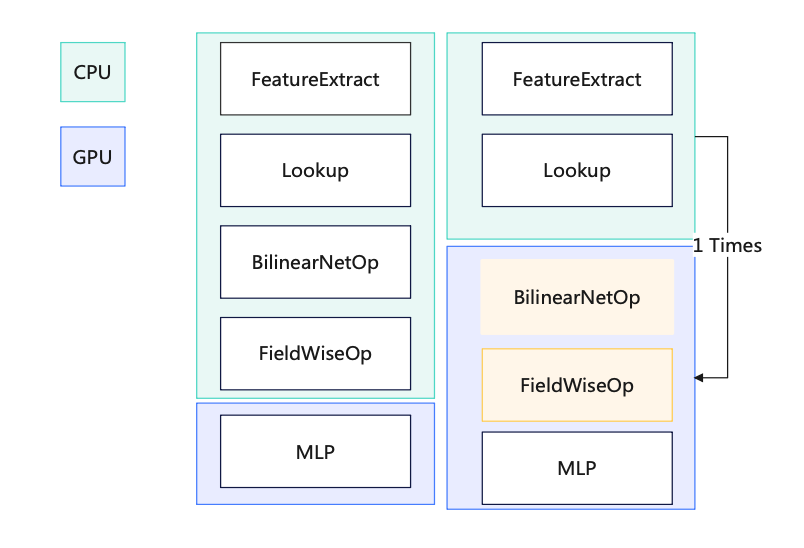 3.2.3 Kuasa pengkomputeran dinamik sepanjang hari
3.2.3 Kuasa pengkomputeran dinamik sepanjang hari 3.2.4 Tukar kepada perkakasan yang lebih baik
3.2.4 Tukar kepada perkakasan yang lebih baik 3.3.1 Pengoptimuman kompilasi automatik tindanan DL
3.3.1 Pengoptimuman kompilasi automatik tindanan DL5. Team
Atas ialah kandungan terperinci Biarkan kuasa pengkomputeran tidak lagi menjadi halangan, pembelajaran mesin Xiaohongshu kaedah pengoptimuman inferens perkakasan heterogen. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 看看pyhton的sklearn机器学习算法
- Bagaimanakah pembelajaran mesin tanpa pengawasan boleh memberi manfaat kepada automasi industri?
- Cara menggunakan pembelajaran mesin untuk menganalisis sentimen
- Pembelajaran Mesin: Jangan memandang rendah kuasa model pokok
- Kaedah konfigurasi untuk menggunakan RStudio untuk pembangunan model pembelajaran mesin pada sistem Linux