
Rumah >Peranti teknologi >AI >Teras Apple menjalankan model besar tanpa mengurangkan ketepatan pengiraan Pensampelan spekulatif juga digunakan.
Teras Apple menjalankan model besar tanpa mengurangkan ketepatan pengiraan Pensampelan spekulatif juga digunakan.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-09-08 11:25:08847semak imbas
Sebaik sahaja Code Llama keluar, semua orang menjangkakan seseorang akan meneruskan pelangsingan secara kuantitatif Mujurlah ia boleh dijalankan secara tempatan
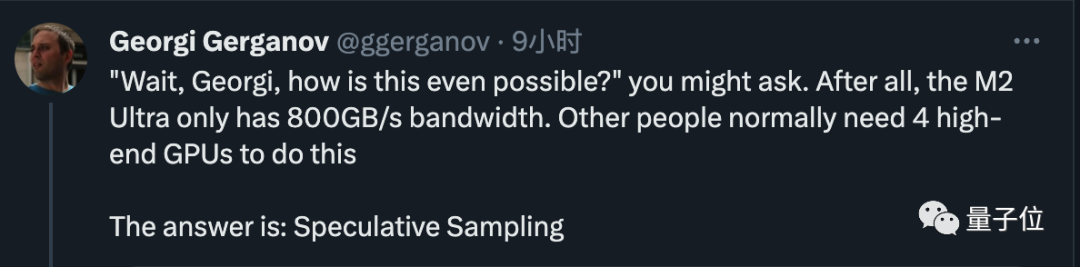
Seperti yang dijangka, Georgi Gerganov, pengarang llama.cpp, yang mengambil tindakan, tetapi kali ini dia melakukannya. tidak mengikut rutin:
Tidak meneruskan Dikuantisasi, kod 34B Kod LLama boleh dijalankan pada komputer Apple walaupun dengan ketepatan FP16, dan kelajuan inferens melebihi 20 token sesaat
 Gambar
Gambar
M2 Ultra boleh menyelesaikan tugasan yang asalnya memerlukan 4 GPU mewah, dan kelajuan menulis kod juga sangat pantas
Orang tua itu kemudian mendedahkan rahsianya, iaitu pensampelan/penyahkodan spekulatif
 . Gambar
. Gambar
mencetuskan perhatian banyak gergasi industri
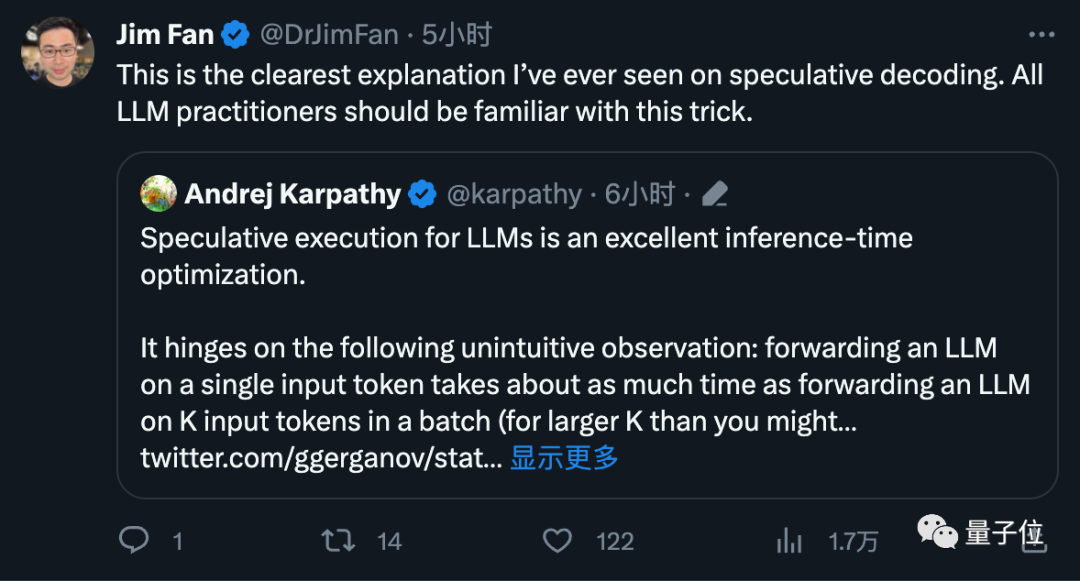
Ahli pengasas OpenAI Andrej Karpathy mengulas bahawa ini adalah pengoptimuman masa inferens yang sangat baik dan memberikan penjelasan yang lebih teknikal.
Fan Linxi, seorang saintis NVIDIA, juga percaya bahawa ini adalah teknik yang semua orang yang bekerja pada model besar harus biasa dengan
 Gambar
Gambar
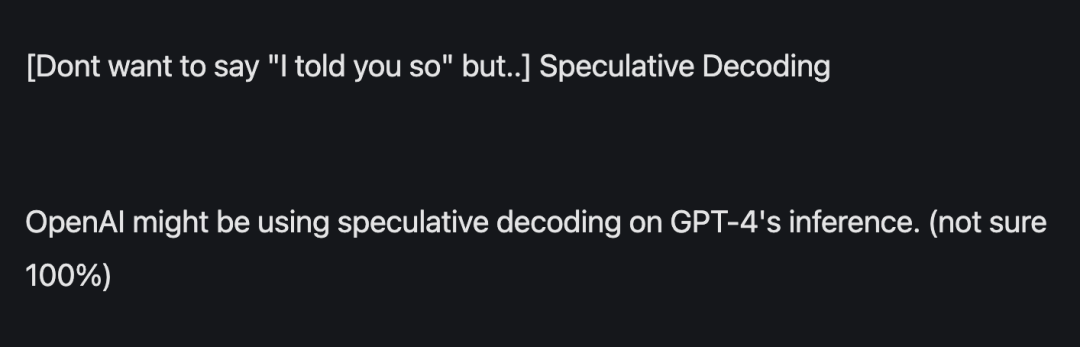
GPT-4 juga menggunakan kaedah ini
Mereka yang menggunakan spekulatif Ia tidak terhad kepada mereka yang menjalankan model besar secara tempatan, tetapi gergasi super seperti Google dan OpenAI juga menggunakan teknologi ini
Menurut maklumat yang bocor sebelum ini, GPT-4 menggunakan kaedah ini untuk mengurangkan kos inferens, jika tidak, ia tidak boleh mampu membakar wang tersebut.
 Pictures
Pictures
Berita terkini menunjukkan bahawa model besar generasi seterusnya Gemini yang dibangunkan bersama oleh Google DeepMind berkemungkinan akan digunakan.
Walaupun kaedah khusus OpenAI adalah sulit, pasukan Google telah mengeluarkan kertas berkaitan dan kertas itu telah dipilih untuk laporan lisan ICML 2023
 Gambar
Gambar
Kaedahnya mudah, mula-mula latih model yang adalah serupa dengan model besar dan lebih murah Untuk model kecil, biarkan model kecil menjana token K dahulu, dan kemudian biarkan model besar membuat penilaian.
Model besar boleh terus menggunakan bahagian yang diterima dan mengubah suai bahagian yang tidak diterima oleh model besar
Dalam penyelidikan asal, model T5-XXL digunakan untuk demonstrasi, dan sambil mengekalkan hasil yang dijana tidak berubah,
 picture
picture
Andjrey Karpathy menyamakan kaedah ini dengan "biarkan model kecil merangka dahulu".
Beliau menjelaskan bahawa kunci kepada keberkesanan kaedah ini ialah apabila model besar dimasukkan ke dalam token dan kumpulan token, masa yang diperlukan untuk meramalkan token seterusnya adalah hampir sama
Setiap token bergantung pada yang sebelumnya. token, jadi dalam keadaan biasa, adalah mustahil untuk mencuba berbilang token pada masa yang sama
Walaupun model kecil mempunyai keupayaan yang lemah, banyak bahagian apabila sebenarnya menghasilkan ayat adalah sangat mudah, dan model kecil juga boleh melakukan kerja itu. Hanya apabila menghadapi bahagian yang sukar, biarkan model yang besar itu terus sahaja.
Kertas asal menunjukkan bahawa model matang sedia ada boleh dipercepatkan secara langsung tanpa mengubah struktur atau latihan semula
Hujah matematik untuk fakta bahawa ketepatan tidak akan dikurangkan juga diberikan dalam lampiran kertas.
 Gambar
Gambar
Sekarang kita faham prinsipnya, mari kita lihat tetapan khusus Georgi Gerganov kali ini.
Dia menggunakan model 7B terkuantisasi 4-bit sebagai model "draf", yang boleh menjana kira-kira 80 token sesaat.
Apabila digunakan secara bersendirian, model 34B dengan ketepatan FP16 hanya boleh menjana 10 token sesaat
Selepas menggunakan kaedah pensampelan spekulatif, kami memperoleh kesan pecutan 2x, yang konsisten dengan data dalam kertas asal

 Gambar
Gambar
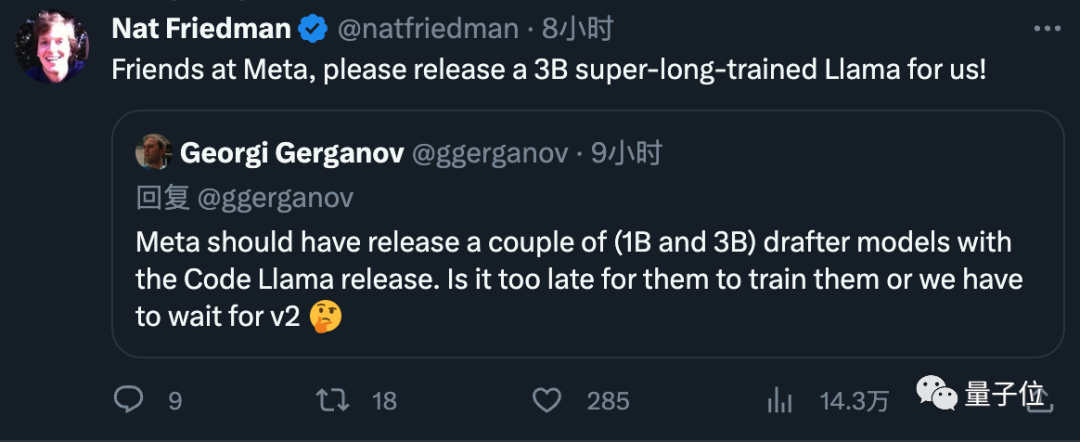
Akhirnya, dia juga mencadangkan Meta terus memasukkan model draf kecil semasa mengeluarkan model pada masa hadapan, yang diterima baik oleh semua orang.
 Pictures
Pictures
Pengarang telah memulakan perniagaan
Georgi Gerganov ialah pengarang Dia memindahkan generasi pertama LlaMA ke C++ pada Mac tahun ini. Projek sumber terbukanya llama.cpp telah menerima hampir 40,000 bintang
 gambar
gambar
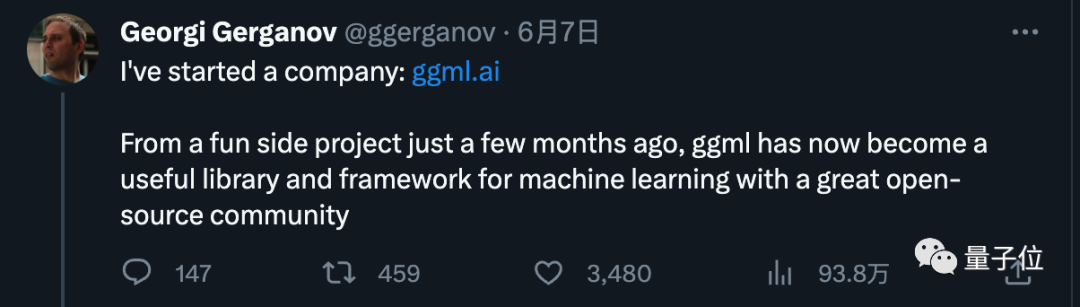
Dia pada mulanya hanya menganggap ini sebagai hobi sampingan, tetapi disebabkan sambutan yang menggalakkan, dia mengumumkan permulaannya pada bulan Jun
syarikat baharu ggml. ai didedikasikan untuk menjalankan AI pada peranti edge. Produk utama syarikat ialah rangka kerja pembelajaran mesin bahasa C di belakang llama.cpp
 Picture
Picture
Pada hari-hari awal permulaan, kami berjaya memperoleh pembiayaan pra-benih daripada bekas CEO GitHub Nat Friedman dan rakan kongsi Y Combinator Daniel Gross Pelaburan
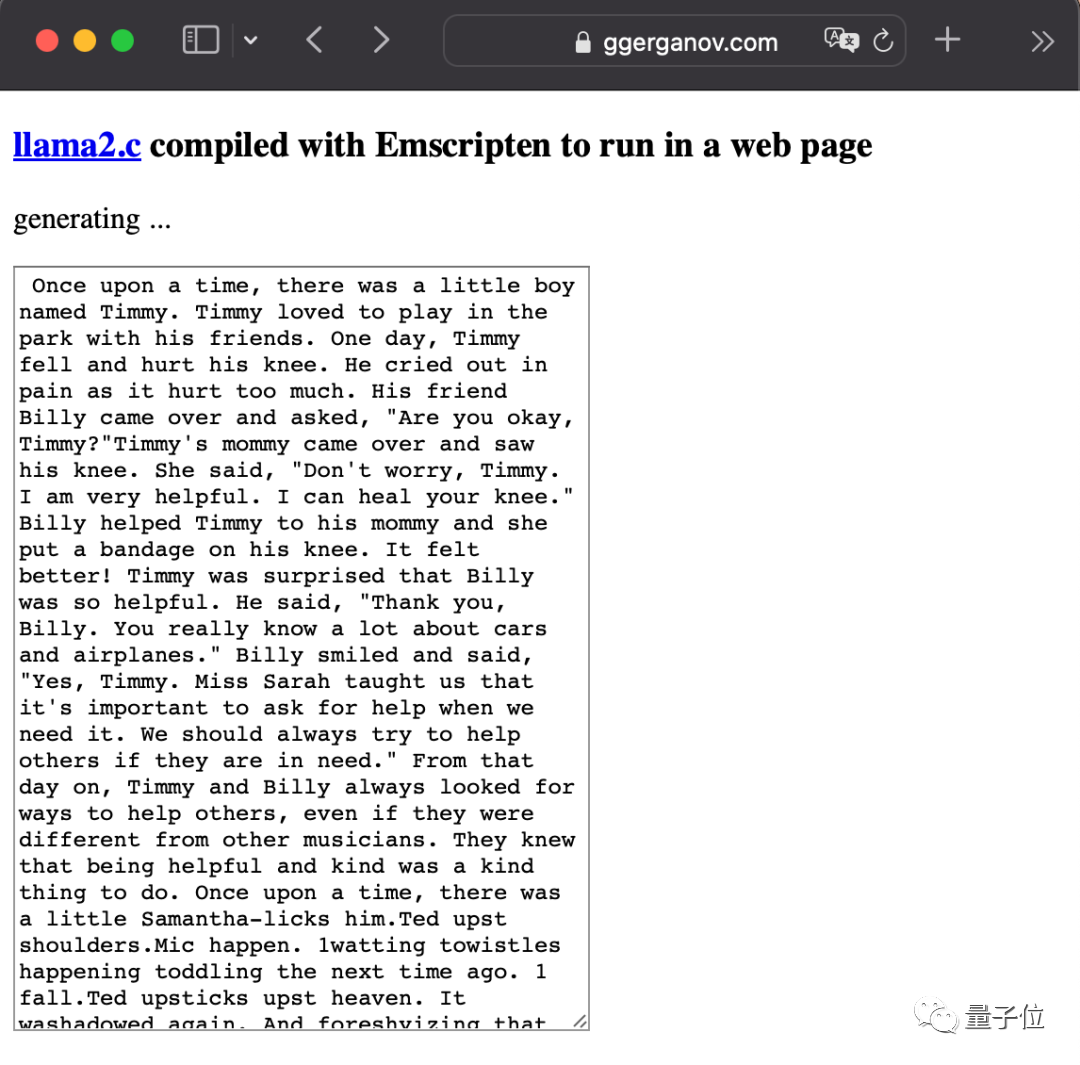
Dia juga sangat aktif selepas keluaran LlaMA2 Yang paling kejam adalah memasukkan model besar terus ke dalam pelayar.
 Gambar
Gambar
Sila lihat kertas pensampelan spekulatif Google: https://arxiv.org/abs/2211.17192
Pautan rujukan: [1]https://x.com/1709718us ]https://x.com/karpathy/status/1697318534555336961
Atas ialah kandungan terperinci Teras Apple menjalankan model besar tanpa mengurangkan ketepatan pengiraan Pensampelan spekulatif juga digunakan.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- switch错误代码2110-2003
- Apakah kapasiti bateri Apple X?
- Berapa banyak iPhone boleh digunakan dengan satu ID?
- ChatGPT tiba-tiba melancarkan APP! iPhone tersedia dan lebih pantas, had penggunaan GPT-4 disyaki akan ditarik balik
- 'Guru Sosial' GPT-4! Tahu cara mentafsir ungkapan dan membuat spekulasi tentang psikologi