


Pembelajaran Mesin: Jangan memandang rendah kuasa model pokok

Disebabkan kerumitannya, rangkaian saraf sering dianggap sebagai "holy grail" untuk menyelesaikan semua masalah pembelajaran mesin. Kaedah berasaskan pokok, sebaliknya, tidak mendapat perhatian yang sama, terutamanya disebabkan oleh kesederhanaan yang jelas bagi algoritma tersebut. Walau bagaimanapun, kedua-dua algoritma ini mungkin kelihatan berbeza, tetapi ia seperti dua sisi syiling yang sama, kedua-duanya adalah penting.

Model Pokok VS Rangkaian Neural
Kaedah berasaskan pokok biasanya lebih baik daripada rangkaian saraf. Pada asasnya, kaedah berasaskan pokok dan kaedah berasaskan rangkaian saraf diletakkan dalam kategori yang sama kerana kedua-duanya mendekati masalah melalui penyahbinaan langkah demi langkah, dan bukannya memisahkan keseluruhan set data melalui sempadan kompleks seperti mesin vektor sokongan atau regresi logistik. .
Jelas sekali, kaedah berasaskan pokok secara beransur-ansur membahagikan ruang ciri di sepanjang ciri yang berbeza untuk mengoptimumkan perolehan maklumat. Apa yang kurang jelas ialah rangkaian saraf juga mendekati tugas dengan cara yang sama. Setiap neuron memantau bahagian tertentu ruang ciri (dengan pelbagai pertindihan). Apabila input memasuki ruang ini, neuron tertentu diaktifkan.
Rangkaian saraf melihat model sekeping demi sekeping ini sesuai dari perspektif kebarangkalian, manakala kaedah berasaskan pokok mengambil perspektif deterministik. Walau apa pun, prestasi kedua-duanya bergantung pada kedalaman model, kerana komponennya dikaitkan dengan pelbagai bahagian ruang ciri.
Model dengan terlalu banyak komponen (nod untuk model pokok, neuron untuk rangkaian saraf) akan terlampau muat, manakala model dengan terlalu sedikit komponen tidak akan memberikan ramalan Bermakna. (Kedua-duanya bermula dengan menghafal titik data, dan bukannya belajar untuk membuat generalisasi.)
Untuk memahami dengan lebih intuitif bagaimana rangkaian saraf membahagikan ruang ciri, anda boleh membaca artikel pengenalan ini mengenai Penghampiran Universal Teorem: https://medium.com/analytics-vidhya/you-dont-understand-neural-networks-until-you-understand-the-universal-approximation-theory-85b3e7677126.
Walaupun terdapat banyak varian berkuasa pepohon keputusan seperti Random Forest, Gradient Boosting, AdaBoost dan Deep Forest, secara amnya, kaedah berasaskan pokok pada asasnya adalah penyederhanaan versi rangkaian saraf.
Kaedah berasaskan pokok menyelesaikan masalah sekeping demi sekeping melalui garisan menegak dan mendatar untuk meminimumkan entropi (pengoptimum dan kerugian). Rangkaian saraf menggunakan fungsi pengaktifan untuk menyelesaikan masalah sekeping demi sekeping.
Kaedah berasaskan pokok adalah bersifat deterministik dan bukannya probabilistik. Ini membawa beberapa pemudahan yang bagus seperti pemilihan ciri automatik.
Nod keadaan yang diaktifkan dalam pepohon keputusan adalah serupa dengan neuron yang diaktifkan (aliran maklumat) dalam rangkaian saraf.
Rangkaian saraf mengubah input melalui parameter pemasangan dan secara tidak langsung membimbing pengaktifan neuron seterusnya. Pokok keputusan secara eksplisit sesuai dengan parameter untuk membimbing aliran maklumat. (Ini adalah hasil daripada deterministik lawan probabilistik.)
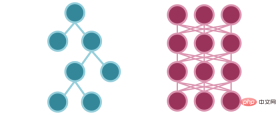
Aliran maklumat adalah serupa dalam kedua-dua model, hanya dalam model pokok Aliran kaedah lebih mudah.
Pemilihan 1 dan 0 dalam model pokok VS Pemilihan kemungkinan rangkaian neural
Sudah tentu, ini adalah kesimpulan abstrak, dan mungkin terdapat malah menjadi Kontroversial. Memang, terdapat banyak halangan untuk membuat hubungan ini. Walau apa pun, ini adalah bahagian penting dalam memahami bila dan mengapa kaedah berasaskan pokok lebih baik daripada rangkaian saraf.
Adalah lumrah bagi pepohon keputusan untuk berfungsi dengan data berstruktur dalam bentuk jadual atau jadual. Kebanyakan orang bersetuju bahawa menggunakan rangkaian saraf untuk melakukan regresi dan ramalan pada data jadual adalah berlebihan, jadi beberapa pemudahan dibuat di sini. Pilihan 1s dan 0s, bukannya kebarangkalian, adalah sumber utama perbezaan antara kedua-dua algoritma. Oleh itu, kaedah berasaskan pokok boleh berjaya digunakan pada situasi di mana kebarangkalian tidak diperlukan, seperti data berstruktur.
Sebagai contoh, kaedah berasaskan pokok menunjukkan prestasi yang baik pada set data MNIST kerana setiap nombor mempunyai beberapa ciri penting. Tidak perlu mengira kebarangkalian dan masalahnya tidak begitu rumit, itulah sebabnya model ensembel pokok yang direka dengan baik boleh berprestasi sebaik atau lebih baik daripada rangkaian saraf konvolusi moden.
Secara amnya, orang ramai cenderung untuk mengatakan bahawa "kaedah berasaskan pokok hanya ingat peraturan", yang betul. Rangkaian saraf adalah sama, kecuali mereka boleh mengingati peraturan berasaskan kebarangkalian yang lebih kompleks. Daripada memberikan ramalan benar/salah secara eksplisit untuk keadaan seperti x>3, rangkaian saraf menguatkan input kepada nilai yang sangat tinggi, menghasilkan nilai sigmoid 1 atau menjana ungkapan berterusan.
Sebaliknya, memandangkan rangkaian saraf sangat kompleks, terdapat banyak perkara yang boleh dilakukan dengannya. Kedua-dua lapisan konvolusi dan berulang adalah varian rangkaian saraf yang luar biasa kerana data yang diproses selalunya memerlukan nuansa pengiraan kebarangkalian.
Terdapat sangat sedikit imej yang boleh dimodelkan dengan satu dan sifar. Nilai pepohon keputusan tidak dapat mengendalikan set data dengan banyak nilai perantaraan (mis. 0.5) sebab itu ia berfungsi dengan baik pada set data MNIST di mana nilai piksel hampir semuanya hitam atau putih tetapi piksel set data lain Nilainya bukan (cth. ImageNet) . Begitu juga, teks mempunyai terlalu banyak maklumat dan terlalu banyak anomali untuk dinyatakan dalam istilah yang pasti.
Ini juga merupakan sebab mengapa rangkaian saraf digunakan terutamanya dalam bidang ini, dan juga sebab mengapa penyelidikan rangkaian saraf terbantut pada hari-hari awal (sebelum permulaan abad ke-21) apabila sejumlah besar data imej dan teks tidak tersedia . Penggunaan biasa rangkaian neural yang lain adalah terhad kepada ramalan berskala besar, seperti algoritma pengesyoran video YouTube, yang sangat besar dan mesti menggunakan kebarangkalian.
Pasukan sains data di mana-mana syarikat mungkin akan menggunakan model berasaskan pokok dan bukannya rangkaian saraf, melainkan mereka membina aplikasi tugas berat seperti mengaburkan latar belakang video Zoom. Tetapi dalam tugas klasifikasi perniagaan harian, kaedah berasaskan pokok menjadikan tugasan ini ringan kerana sifat deterministiknya, dan kaedahnya adalah sama seperti rangkaian saraf.
Dalam banyak situasi praktikal, pemodelan deterministik adalah lebih semula jadi daripada pemodelan probabilistik. Contohnya, untuk meramalkan sama ada pengguna akan membeli item daripada tapak web e-dagang, model pokok ialah pilihan yang baik kerana pengguna secara semula jadi mengikuti proses membuat keputusan berasaskan peraturan. Proses membuat keputusan pengguna mungkin kelihatan seperti ini:
- Adakah saya mempunyai pengalaman membeli-belah yang positif pada platform ini sebelum ini? Jika ya, teruskan.
- Adakah saya memerlukan item ini sekarang? (Sebagai contoh, patutkah saya membeli cermin mata hitam dan seluar renang untuk musim sejuk?) Jika ya, teruskan.
- Berdasarkan demografi pengguna saya, adakah ini produk yang saya akan berminat untuk membeli? Jika ya, teruskan.
- Adakah perkara ini terlalu mahal? Jika tidak, teruskan.
- Adakah pelanggan lain menilai produk ini cukup tinggi untuk saya berasa selesa membelinya? Jika ya, teruskan.
Secara umumnya, manusia mengikut proses membuat keputusan berasaskan peraturan dan tersusun. Dalam kes ini, pemodelan kebarangkalian tidak diperlukan.
Kesimpulan
- Adalah yang terbaik untuk memikirkan kaedah berasaskan pokok sebagai versi rangkaian neural yang diperkecilkan untuk menampilkan ciri dalam cara yang lebih mudah Pengelasan, pengoptimuman, pemindahan aliran maklumat, dsb.
- Perbezaan utama dalam penggunaan antara kaedah berasaskan pokok dan kaedah rangkaian saraf ialah struktur data deterministik (0/1) dan kemungkinan. Data berstruktur (jadual) boleh dimodelkan dengan lebih baik menggunakan model deterministik.
- Jangan memandang rendah kuasa kaedah pokok.
Atas ialah kandungan terperinci Pembelajaran Mesin: Jangan memandang rendah kuasa model pokok. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AM
Skop Gemma: Mikroskop Google ' s untuk mengintip ke proses pemikiran AI 'Apr 17, 2025 am 11:55 AMMeneroka kerja -kerja dalam model bahasa dengan skop Gemma Memahami kerumitan model bahasa AI adalah satu cabaran penting. Pelepasan Google Gemma Skop, Toolkit Komprehensif, menawarkan penyelidik cara yang kuat untuk menyelidiki
 Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AM
Siapa penganalisis perisikan perniagaan dan bagaimana menjadi satu?Apr 17, 2025 am 11:44 AMMembuka Kejayaan Perniagaan: Panduan untuk Menjadi Penganalisis Perisikan Perniagaan Bayangkan mengubah data mentah ke dalam pandangan yang boleh dilakukan yang mendorong pertumbuhan organisasi. Ini adalah kuasa penganalisis Perniagaan Perniagaan (BI) - peranan penting dalam GU
 Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics VidhyaApr 17, 2025 am 11:43 AMPernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AM
Penganalisis Perniagaan vs Penganalisis DataApr 17, 2025 am 11:38 AMPengenalan Bayangkan pejabat yang sibuk di mana dua profesional bekerjasama dalam projek kritikal. Penganalisis perniagaan memberi tumpuan kepada objektif syarikat, mengenal pasti bidang penambahbaikan, dan memastikan penjajaran strategik dengan trend pasaran. Simu
 Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Apakah Count dan Counta dalam Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMPengiraan dan Analisis Data Excel: Penjelasan terperinci mengenai fungsi Count dan Counta Pengiraan dan analisis data yang tepat adalah kritikal dalam Excel, terutamanya apabila bekerja dengan set data yang besar. Excel menyediakan pelbagai fungsi untuk mencapai matlamat ini, dengan fungsi Count dan CountA menjadi alat utama untuk mengira bilangan sel di bawah keadaan yang berbeza. Walaupun kedua -dua fungsi digunakan untuk mengira sel, sasaran reka bentuk mereka disasarkan pada jenis data yang berbeza. Mari menggali butiran khusus fungsi Count dan Counta, menyerlahkan ciri dan perbezaan unik mereka, dan belajar cara menerapkannya dalam analisis data. Gambaran keseluruhan perkara utama Memahami kiraan dan cou
 Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AM
Chrome ada di sini dengan AI: mengalami sesuatu yang baru setiap hari !!Apr 17, 2025 am 11:29 AMRevolusi AI Google Chrome: Pengalaman melayari yang diperibadikan dan cekap Kecerdasan Buatan (AI) dengan cepat mengubah kehidupan seharian kita, dan Google Chrome mengetuai pertuduhan di arena pelayaran web. Artikel ini meneroka exciti
 Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AM
Sisi Manusia Ai ' s: Kesejahteraan dan garis bawah empat kali gandaApr 17, 2025 am 11:28 AMImpak Reimagining: garis bawah empat kali ganda Selama terlalu lama, perbualan telah dikuasai oleh pandangan sempit kesan AI, terutama memberi tumpuan kepada keuntungan bawah. Walau bagaimanapun, pendekatan yang lebih holistik mengiktiraf kesalinghubungan BU
 5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AM
5 Kes Pengkomputeran Kuantum Mengubah Permainan Yang Harus Anda KetahuiApr 17, 2025 am 11:24 AMPerkara bergerak terus ke arah itu. Pelaburan yang dicurahkan ke dalam penyedia perkhidmatan kuantum dan permulaan menunjukkan bahawa industri memahami kepentingannya. Dan semakin banyak kes penggunaan dunia nyata muncul untuk menunjukkan nilainya


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

