
Rumah >Peranti teknologi >AI >Penjanaan video dengan masa dan ruang yang boleh dikawal telah menjadi kenyataan, dan VideoComposer model berskala besar baru Alibaba telah menjadi popular
Penjanaan video dengan masa dan ruang yang boleh dikawal telah menjadi kenyataan, dan VideoComposer model berskala besar baru Alibaba telah menjadi popular

- 王林ke hadapan
- 2023-06-15 08:28:341347semak imbas
Dalam bidang lukisan AI, Komposer yang dicadangkan oleh Alibaba dan ControlNet berdasarkan penyebaran Stable yang dicadangkan oleh Stanford telah mengetuai pembangunan teori penjanaan imej yang boleh dikawal. Walau bagaimanapun, penerokaan industri penjanaan video terkawal masih agak kosong.
Berbanding dengan penjanaan imej, video boleh dikawal adalah lebih kompleks, kerana selain kebolehkawalan ruang kandungan video, ia juga perlu memenuhi kebolehkawalan dimensi masa. Berdasarkan ini, pasukan penyelidik Alibaba dan Ant Group memimpin dalam membuat percubaan dan mencadangkan VideoComposer, yang secara serentak mencapai kebolehkawalan video dalam kedua-dua dimensi masa dan ruang melalui paradigma penjanaan gabungan.

- Alamat kertas: https://arxiv.org/abs/2306.02018
- Laman utama projek: https://videocomposer.github.io
Beberapa masa lalu, Alibaba Model video Wensheng adalah rendah dan sumber terbuka dalam Komuniti Ajaib dan Wajah Pelukan Ia secara tidak dijangka menarik perhatian meluas daripada pembangun di dalam dan di luar negara malah mendapat sambutan daripada Musk sendiri selama beberapa hari berturut-turut di Komuniti Sihir Berpuluh-puluh ribu lawatan antarabangsa setiap hari.
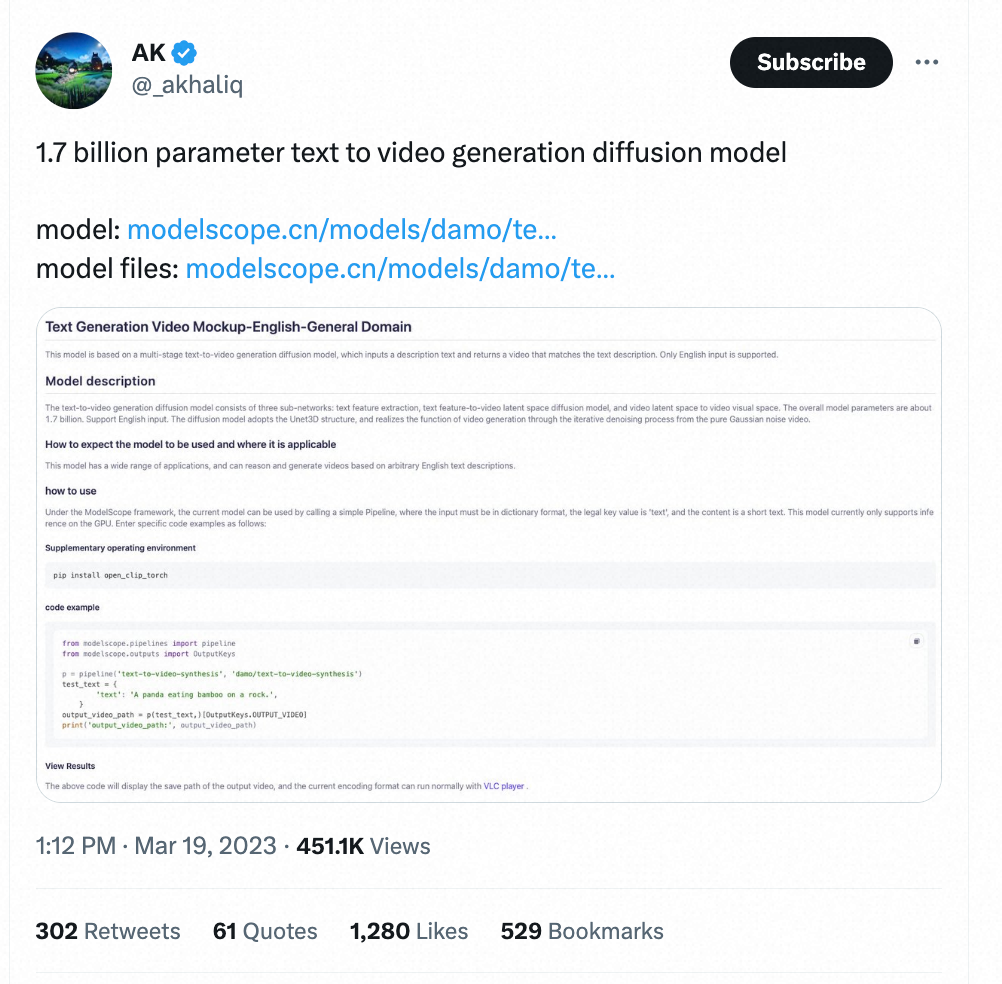
Text-to-Video di Twitter
VideoComposer, sebagai pencapaian terbaru pasukan penyelidik, sekali lagi telah diterima secara meluas oleh tumpuan masyarakat antarabangsa.


VideoKomposer di Twitter
Malah, kebolehkawalan telah menjadi penanda aras yang lebih tinggi untuk penciptaan kandungan visual, yang telah mencapai kemajuan yang ketara dalam penjanaan imej tersuai, tetapi masih terdapat tiga masalah dalam bidang penjanaan video :
- Struktur data yang kompleks, video yang dihasilkan perlu memenuhi kedua-dua kepelbagaian perubahan dinamik dalam dimensi masa dan konsistensi kandungan dalam dimensi spatio-temporal
- Syarat Panduan Kompleks, penjanaan video boleh dikawal sedia ada memerlukan keadaan kompleks yang tidak boleh dibina secara manual. Contohnya, Gen-1/2 yang dicadangkan oleh Runway perlu bergantung pada jujukan kedalaman sebagai syarat, yang boleh mencapai pemindahan struktur antara video dengan lebih baik, tetapi tidak dapat menyelesaikan masalah kebolehkawalan dengan baik
- Kekurangan kebolehkawalan gerakan adalah sifat yang kompleks dan abstrak bagi video.
Sebelum ini, Komposer yang dicadangkan oleh Alibaba telah membuktikan bahawa komposisi amat membantu dalam meningkatkan kebolehkawalan penjanaan imej, dan kajian VideoComposer ini juga Berdasarkan generasi gabungan paradigma, ia meningkatkan fleksibiliti penjanaan video sambil menyelesaikan tiga cabaran utama di atas. Secara khusus, video diuraikan kepada tiga syarat panduan, iaitu keadaan teks, keadaan ruang dan keadaan pemasaan khusus video, dan kemudian Video LDM (Model Resapan Terpendam Video) dilatih berdasarkan ini. Khususnya, ia menggunakan Vektor Gerakan yang cekap sebagai syarat pemasaan eksplisit yang penting untuk mempelajari corak gerakan video, dan mereka bentuk pengekod keadaan spatiotemporal yang mudah dan berkesan STC-pengekod untuk memastikan kesinambungan spatiotemporal video dipacu keadaan. Dalam peringkat inferens, keadaan yang berbeza boleh digabungkan secara rawak untuk mengawal kandungan video.
Hasil eksperimen menunjukkan bahawa VideoComposer boleh mengawal corak masa dan ruang video secara fleksibel, seperti menjana video tertentu melalui gambar tunggal, lukisan tangan, dsb., malah boleh digunakan dengan mudah. arahan mudah yang dilukis dengan tangan. Kawal gaya pergerakan sasaran. Kajian ini secara langsung menguji prestasi VideoComposer pada 9 tugas klasik yang berbeza, dan kesemuanya mencapai keputusan yang memuaskan, membuktikan kepelbagaian VideoComposer.
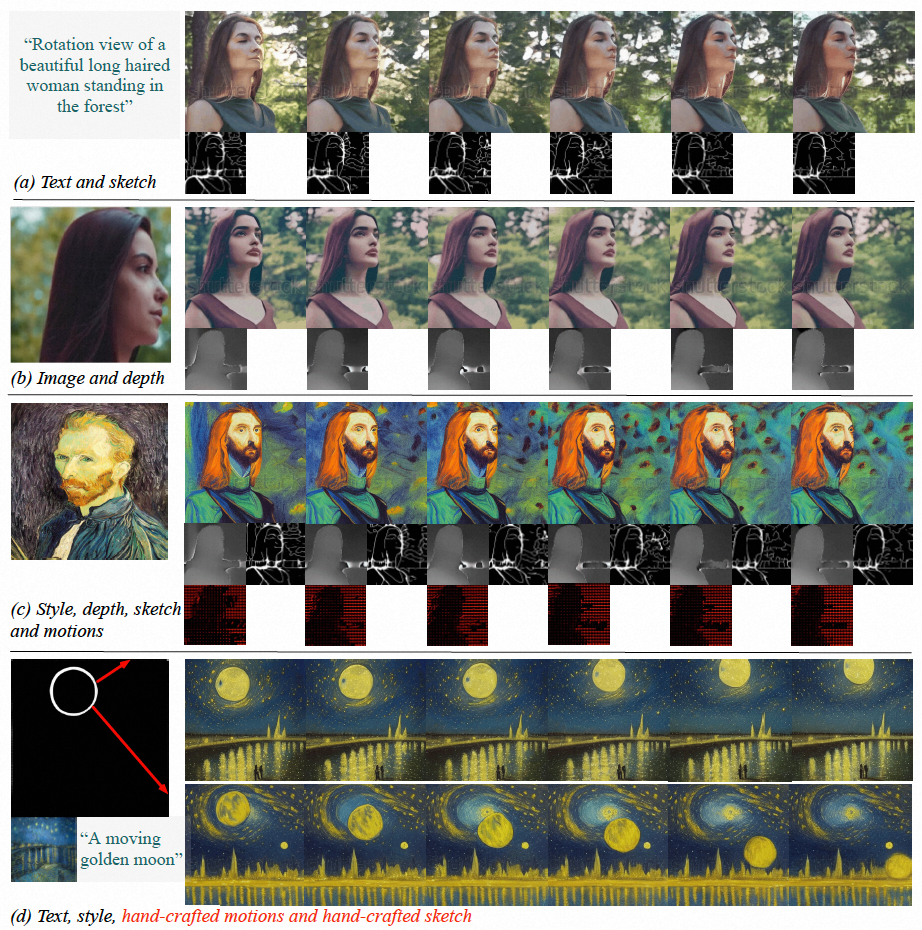
Rajah (a-c) VideoComposer dapat menghasilkan video yang memenuhi teks, keadaan ruang dan temporal atau subset daripadanya; (d ) VideoComposer boleh menggunakan hanya dua pukulan untuk menghasilkan video yang memenuhi gaya Van Gogh, sambil memenuhi corak pergerakan yang dijangkakan (strok merah) dan corak bentuk (strok putih)
Pengenalan kaedah
Video LDM Ruang tersembunyi. Video LDM mula-mula memperkenalkan pengekod pra-latihan untuk memetakan video input . Kemudian, gunakan penyahkod terlatih D untuk memetakan ruang terpendam ke ruang piksel Model resapan. Untuk mempelajari pengedaran kandungan video sebenar , model resapan belajar untuk secara beransur-ansur denoise daripada hingar taburan normal untuk memulihkan kandungan visual sebenar Proses ini sebenarnya mensimulasikan rantai Markov boleh balik dengan panjang T=1000. Untuk melakukan proses boleh balik dalam ruang terpendam, Video LDM menyuntik hingar ke dalam 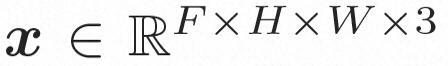
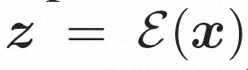 kepada perwakilan ruang terpendam, di mana
kepada perwakilan ruang terpendam, di mana 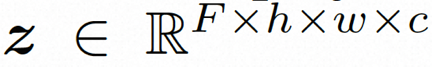
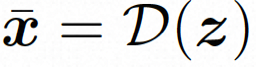 . Dalam VideoComposer, tetapan parameter ialah
. Dalam VideoComposer, tetapan parameter ialah 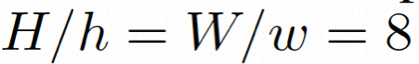
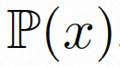
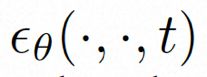
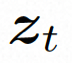
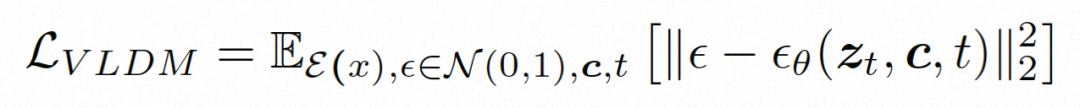
Untuk meneroka sepenuhnya penggunaan bias induktif tempatan secara spasial dan jujukan bias induktif temporal untuk denoising, VideoComposer akan 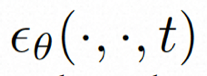
VideoKomposer
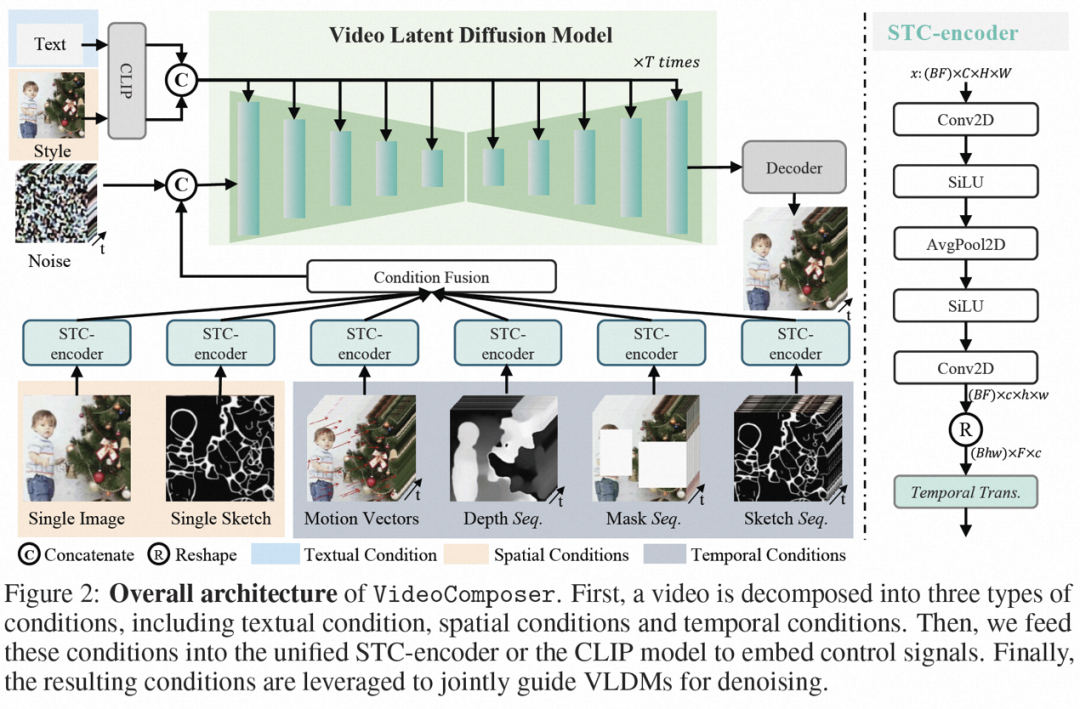
Kompos syarat. VideoComposer menguraikan video kepada tiga jenis keadaan berbeza, iaitu keadaan teks, keadaan spatial dan keadaan pemasaan kritikal, yang bersama-sama menentukan corak ruang dan temporal dalam video. VideoComposer ialah rangka kerja penjanaan video boleh gubah umum, jadi lebih banyak syarat tersuai boleh dimasukkan ke dalam VideoComposer berdasarkan aplikasi hiliran, tidak terhad kepada yang disenaraikan di bawah:
- Syarat teks: Teks penerangan menyediakan arahan visual video dari segi kandungan visual kasar dan gerakan, yang juga merupakan keadaan yang biasa digunakan untuk T2V; Keadaan ruang:
Imej Tunggal, pilih bingkai pertama video yang diberikan sebagai keadaan spatial untuk menjana imej kepada video , untuk menyatakan kandungan dan struktur video
- Lakaran Tunggal, gunakan PiDiNet untuk mengekstrak lakaran bingkai video pertama sebagai keadaan spatial kedua; untuk memindahkan lagi gaya satu imej ke video yang disintesis, pilih pembenaman imej sebagai panduan gaya;
- Syarat masa:
- Vektor Pergerakan (Vektor Pergerakan), vektor gerakan diwakili sebagai vektor dua dimensi sebagai elemen unik video, iaitu arah mendatar dan menegak. Ia secara eksplisit mengekod pergerakan piksel demi piksel antara dua bingkai bersebelahan. Disebabkan oleh sifat semula jadi vektor gerakan, keadaan ini dianggap sebagai isyarat kawalan gerakan tersintesis sementara, yang mengekstrak vektor gerakan dalam format MPEG-4 standard daripada video mampat
- urutan kedalaman ( Jujukan Kedalaman), untuk memperkenalkan maklumat kedalaman peringkat video, gunakan model pra-latihan dalam PiDiNet untuk mengekstrak peta kedalaman bingkai video; ), memperkenalkan topeng tiub untuk menutup kandungan spatiotemporal tempatan dan memaksa model untuk meramalkan kawasan bertopeng berdasarkan maklumat yang boleh diperhatikan; menyediakan Lebih kawalan ke atas butiran untuk gubahan tersuai yang tepat.
- Pengekod bersyarat spatio-temporal.
- Syarat jujukan mengandungi kebergantungan spatiotemporal yang kaya dan kompleks, yang menimbulkan cabaran yang lebih besar kepada arahan yang boleh dikawal. Untuk meningkatkan persepsi temporal keadaan input, kajian ini mereka bentuk pengekod keadaan spatiotemporal (STC-encoder) untuk menggabungkan hubungan ruang-masa. Khususnya, struktur spatial ringan digunakan pertama kali, termasuk dua lilitan 2D dan avgPooling, untuk mengekstrak maklumat spatial setempat, dan kemudian jujukan keadaan yang terhasil adalah input kepada lapisan Transformer temporal untuk pemodelan temporal. Dengan cara ini, pengekod STC boleh memudahkan pembenaman eksplisit isyarat temporal dan menyediakan kemasukan bersatu untuk pembenaman bersyarat untuk input yang pelbagai, dengan itu meningkatkan ketekalan antara bingkai. Di samping itu, kajian itu mengulangi keadaan spatial imej tunggal dan lakaran tunggal dalam dimensi temporal untuk memastikan konsistensinya dengan keadaan temporal, sekali gus memudahkan proses pemasukan keadaan.
Selepas memproses syarat melalui pengekod STC, urutan akhir keadaan mempunyai bentuk spatial yang sama seperti , dan kemudian digabungkan dengan penambahan mengikut unsur. Akhirnya, jujukan bersyarat yang digabungkan disatukan di sepanjang dimensi saluran sebagai isyarat kawalan. Untuk keadaan teks dan gaya, mekanisme perhatian silang digunakan untuk menyuntik teks dan panduan gaya. Latihan dan inferens
Strategi latihan dua peringkat.
Walaupun VideoComposer boleh dimulakan melalui pra-latihan imej LDM, yang boleh mengurangkan kesukaran latihan pada tahap tertentu, adalah sukar bagi model untuk mempunyai keupayaan untuk melihat dinamik temporal dan keupayaan untuk menjana berbilang keadaan pada masa yang sama, ini akan meningkatkan kesukaran melatih penjanaan video gabungan. Oleh itu, kajian ini menggunakan strategi pengoptimuman dua peringkat Pada peringkat pertama, model pada mulanya dilengkapi dengan keupayaan pemodelan masa melalui latihan T2V pada peringkat kedua, VideoComposer telah dioptimumkan melalui latihan gabungan untuk mencapai prestasi yang lebih baik.Penaakulan.
Semasa proses inferens, DDIM digunakan untuk meningkatkan kecekapan inferens. Dan gunakan panduan tanpa pengelas untuk memastikan hasil yang dihasilkan memenuhi syarat yang ditetapkan. Proses penjanaan boleh diformalkan seperti berikut:di mana ω ialah nisbah panduan c1 dan c2 ialah dua set syarat. Mekanisme panduan ini menilai set dua keadaan dan boleh memberikan model kawalan yang lebih fleksibel melalui kawalan intensiti.
Hasil eksperimen
Dalam penerokaan eksperimen, kajian ini membuktikan bahawa VideoComposer mempunyai rangka kerja generatif universal sebagai model bersatu dan mengesahkan keupayaan VideoComposer pada 9 tugasan klasik.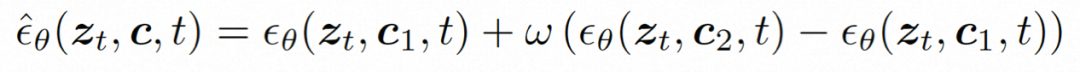
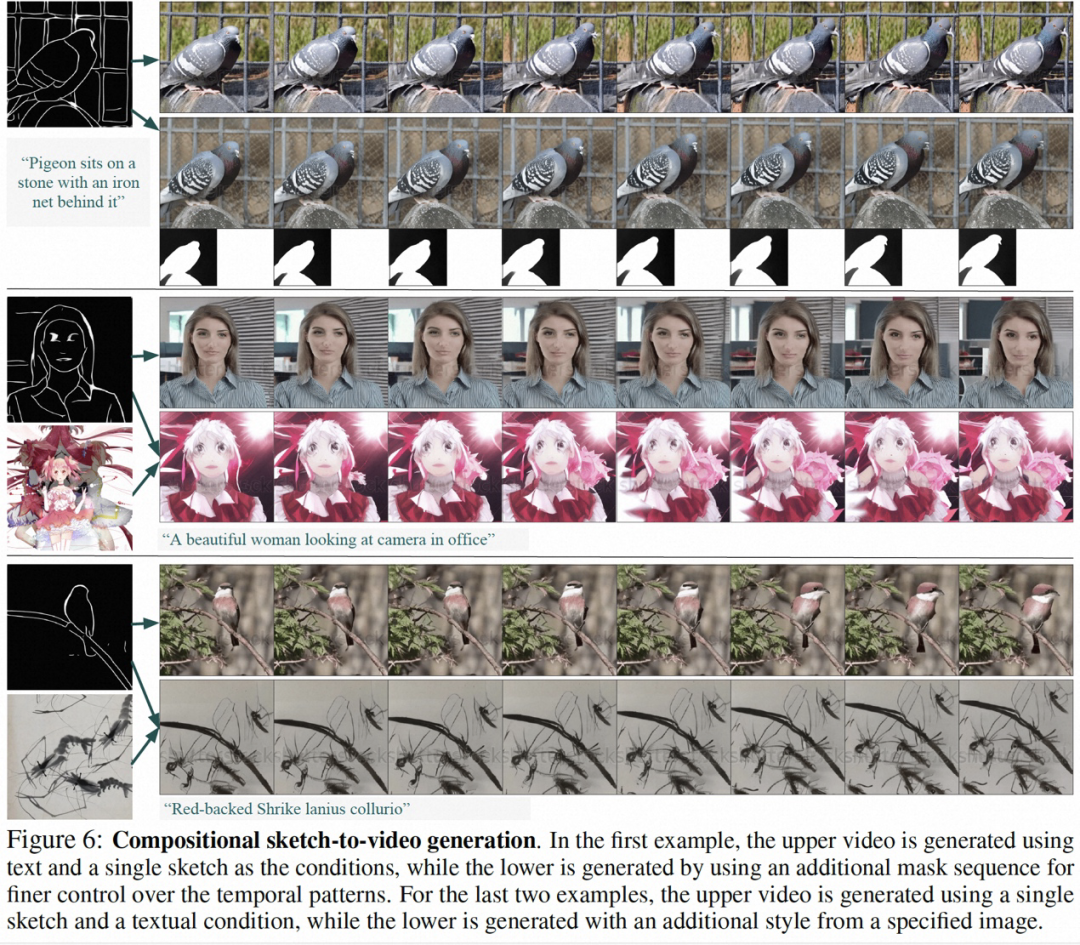
Sebahagian daripada hasil penyelidikan ini adalah seperti berikut, dalam penjanaan gambar statik kepada video (Rajah 4), Inpainting video (Rajah 5), penjanaan lakaran statik kepada video (Rajah 6) , Video kawalan gerakan yang dilukis dengan tangan (Rajah 8) dan pemindahan gerakan (Rajah A12) boleh mencerminkan kelebihan penjanaan video yang boleh dikawal.


Pengenalan pasukan
Maklumat awam menunjukkan bahawa penyelidikan Alibaba tentang model asas visual tertumpu terutamanya pada penyelidikan model perwakilan visual besar, model besar generatif visual dan aplikasi hilirannya menerbitkan lebih daripada 60 kertas CCF-A dalam bidang berkaitan dan memenangi lebih daripada 10 kejohanan antarabangsa dalam pelbagai pertandingan industri, seperti kaedah penjanaan imej terkawal Komposer, kaedah pra-latihan imej dan teks RA-CLIP dan RLEG, dan panjang yang tidak dipotong. Video pembelajaran penyeliaan sendiri HiCo/HiCo++, kaedah penjanaan muka bercakap LipFormer, dsb. semuanya datang daripada pasukan ini.
Atas ialah kandungan terperinci Penjanaan video dengan masa dan ruang yang boleh dikawal telah menjadi kenyataan, dan VideoComposer model berskala besar baru Alibaba telah menjadi popular. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Dengan ChatGPT pemalam, ia adalah nod, tetapi bukan pusat
- CV membuka era model besar! Google mengeluarkan ViT terbesar dalam sejarah: 22 bilion parameter, persepsi visual hampir dengan manusia
- Nature mengeluarkan artikel: Kepantasan inovasi saintifik asas telah perlahan dan telah memasuki 'era tambahan'
- Teknologi AI terkini secara tidak invasif menyahkod 'bahasa otak' dengan ketepatan 73%
- AI bertindak sebagai mesin maya Linux dan boleh mengurus fail, program, membuka pelayar dan berbual dengan 'matryoshka' sendiri